百位学者署名的大模型综述研究被质疑「抄袭」,智源研究院官方发布致歉信
机器之心编辑部
智源研究院表示:「对这一情况,研究院立即组织内部调查,确认部分文章存在问题后,已启动邀请第三方专家开展独立审查,并进行相关追责。」
昨天,一则有关综述研究涉嫌「抄袭」的消息引发了海内外学术圈的热议:

宾夕法尼亚大学博士生、谷歌学生研究员 Daphne Ippolito 在推特上表示,智源研究院一篇拥有 100 位作者署名的综述研究《A Roadmap for Big Model》涉嫌抄袭了多篇论文内容,其中就包括自己团队的一项研究《Deduplicating Training Data Makes Language Models Better》,后者此前已被 ACL 2022 接收。
该事件迅速发酵,引起了社区广泛关注与讨论。
针对质疑,4 月 13 日,北京智源人工智能研究院发布了《关于 “A Roadmap for Big Model” 综述报告问题的致歉信》,并表示:「对这一情况,研究院立即组织内部调查,确认部分文章存在问题后,已启动邀请第三方专家开展独立审查,并进行相关追责。」

智源研究院内部调查的初步结果如下:
1. 该报告是一篇大模型领域的综述,希望尽可能涵盖国内外该领域的所有重要文献,由智源研究院牵头,负责框架设计和稿件汇总,并邀请国内外 100 位科研人员分别撰写了 16 篇独立的专题文章,每篇文章分别邀请了一组作者撰写并单独署名,共 200 页。报告发布后,根据反馈持续进行修改完善,到 4 月 2 日在 arXiv 网站上已经更新到第三版。
2. 4 月 13 日,我们获悉谷歌研究员 Nicholas Carlini 在个人博客上指出该报告抄袭了他们论文的数个段落,同时还有其他段落和语句抄袭其他论文。我们对此进行了逐项核查,经查重确认第 2 篇文章的第 3.1 节 179 个词,第 8 篇文章的第 3.1 节 74 个词、第 12 篇文章的第 2.3 节 55 个词、第 14 篇文章的第 2 节 159 个词、第 16 篇文章的第 1 节 146 个词与其他论文重复,应属抄袭。我们决定立即从报告中删除相应内容,报告修订版今天将提交 arXiv 进行更新。目前已通知所有文章的作者对所有内容进行全面审查,后续经严格审核后再发布新版本。
3. 智源作为该报告的组织者,理应对各篇文章的所有内容进行严格审核,出现这样的问题难辞其咎。对此我们深感自责,特别感谢学术界和媒体的朋友们帮助我们发现问题。我们将深刻吸取教训,整改科研管理和论文发表流程,希望各界朋友监督我们工作。
涉嫌抄袭的细节
涉嫌被抄袭论文的作者之一 Nicholas Carlini 表示:「我的一位合著者正在阅读 Big Models 论文,并注意到其中一些文本似乎很熟悉,在快速查看后,我们发现实际上有一堆文本是直接从我们的论文中复制而来的。」
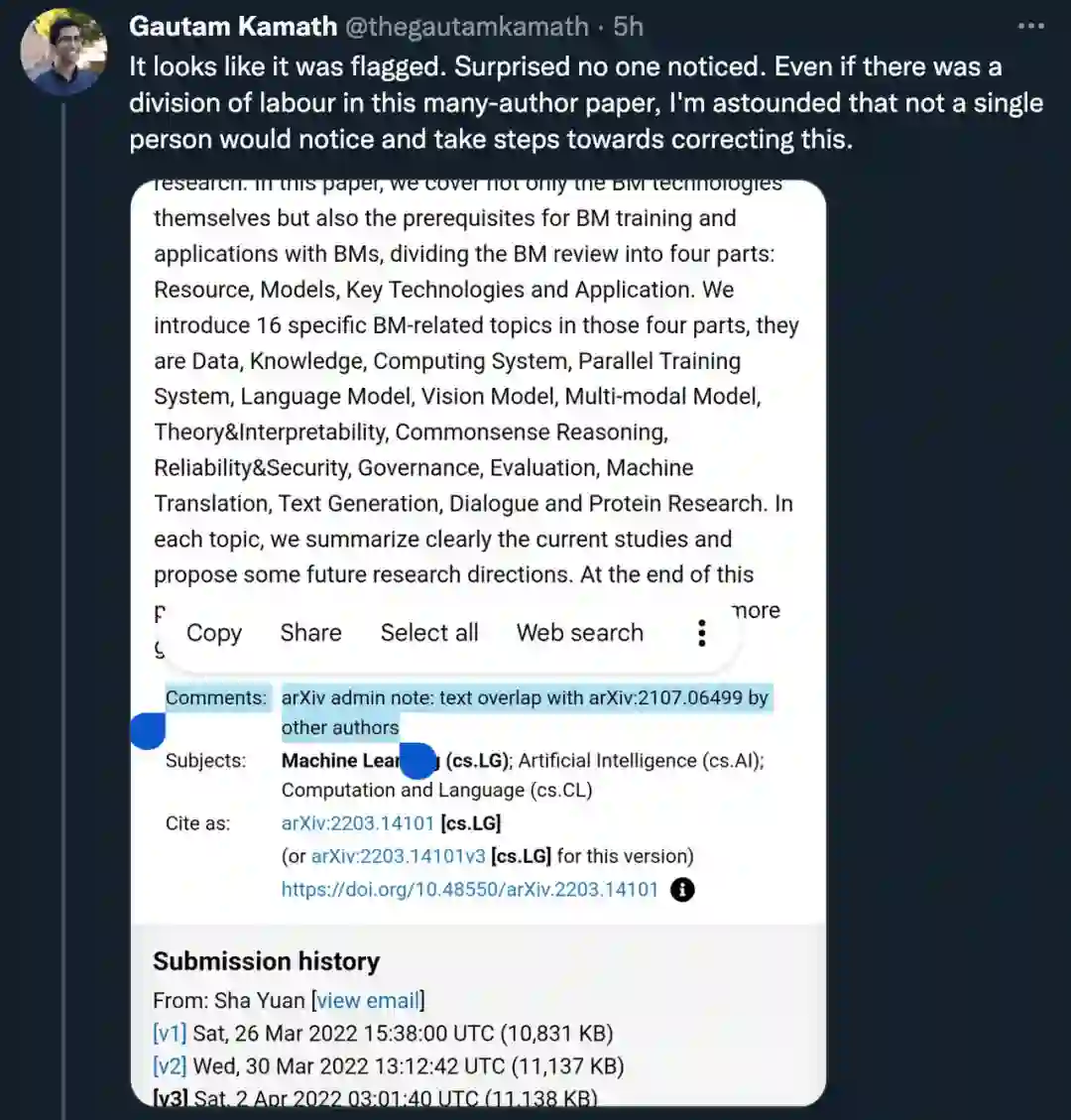
目前,在「Big Model」这篇论文的 arXiv 页面,管理员已经标注了两篇文章具有较高的文本重合度。
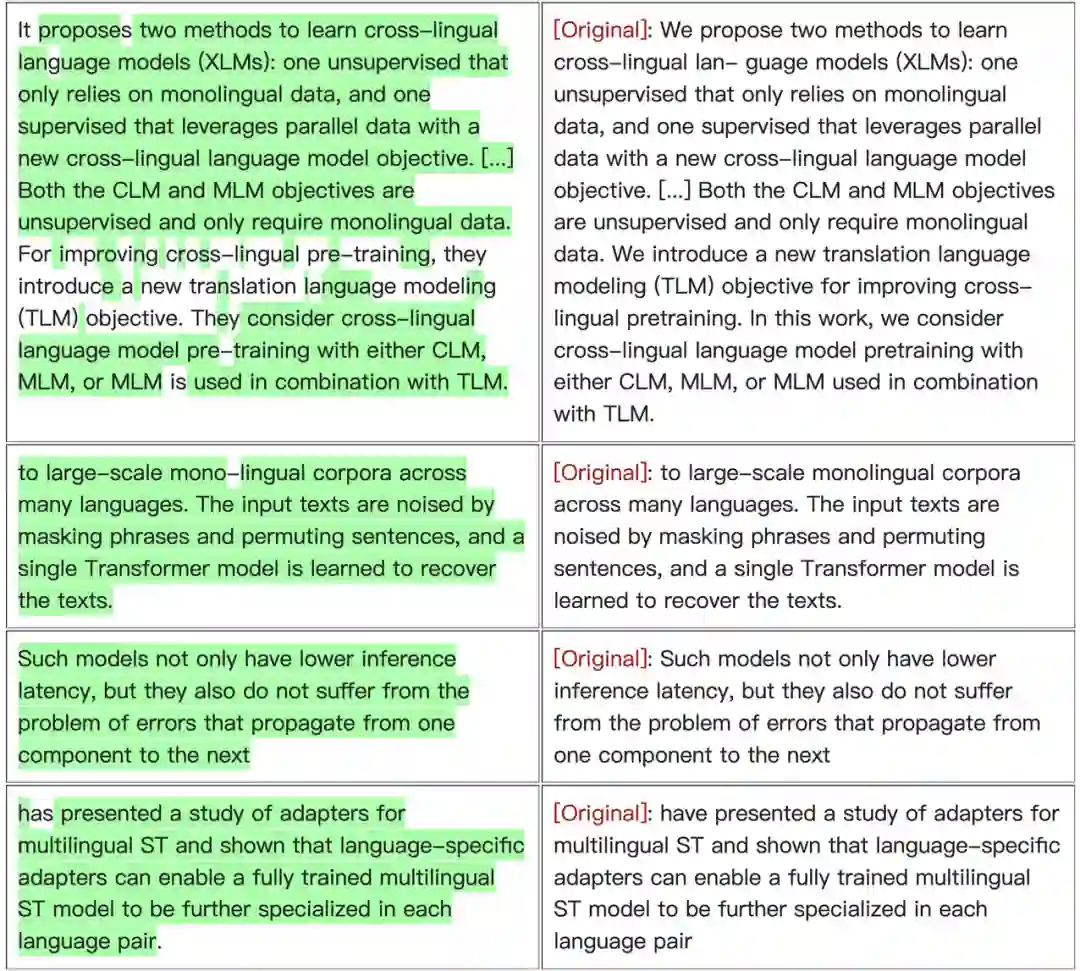
在博客中,声称被抄袭的作者也做出了举证:「Big Models」抄袭了 Carlini 论文的参考和相关工作部分。如下所示,左侧是「Big Models」论文中的文本,右侧是原始论文中的相应文本。被「复制」的文本以绿色高亮显示:



事件引起多方讨论之后,Nicholas Carlini 本人在博客的更新中表示:

这篇文章受到的关注比我想象的要多得多。(每小时访问这个页面的人数比上周访问我整个网站的人数还要多。)…… 在不清楚幕后情况的时候,我想避免做出判断。也许一些初级作者的本意是好的,认为有一条引文就可以复制文本。也许是来自上面的压力,让一些学生觉得他们唯一的选择就是按时交稿。对于资深作者来说,他们可能已经阅读了文本,认为它看起来非常合理,只是在不知道文本来自何处的情况下对文本做了一些调整。
我希望这篇文章能够引起人们对此类事情的注意。例如,大约有 1% 的已发表和被接收的论文比这篇报告有更高的数据复制比例。我应该在最初写博客的时候就给出这个背景。所以,再一次,请大家不要特别严厉地批评这篇论文。
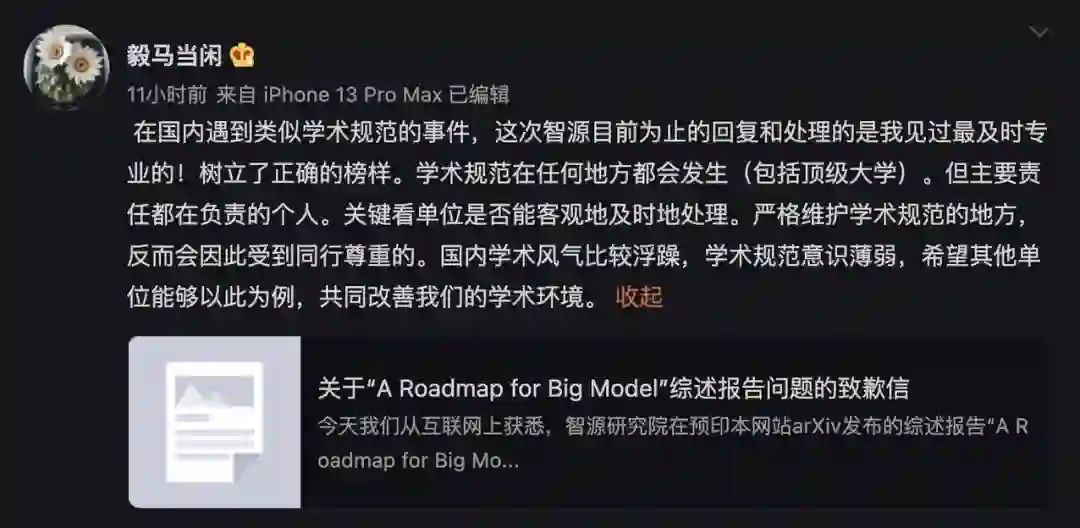
最后想说一句,相信这件事也足以为大家敲响警钟,社区要严格维护学术规范。正如 UC 伯克利教授马毅在微博上的观点:「严格维护学术规范的地方,反而会因此受到同行尊重的。国内学术风气比较浮躁,学术规范意识薄弱,希望其他单位能够以此为例,共同改善我们的学术环境。」
参考链接:https://nicholas.carlini.com/writing/2022/a-case-of-plagarism-in-machine-learning.html

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com




