干货 | 图像分割概述 & ENet 实例

本文为 AI 研习社编译的技术博客,原标题 :
Image Segmentation Overview & ENet Implementation
作者 | Aviv Shamsian
翻译 | sherry3255、alexchung
校对 | 邓普斯·杰弗 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://medium.com/@mista2311/image-segmentation-overview-enet-implementation-8394ff71cf26
在这篇博文中,我将概述图像分割并介绍ENet论文。
论文链接:
https://s3-us-west-2.amazonaws.com/mlsurveys/54.pdf
⭐库链接:
https://github.com/iArunava/ENet-Real-Time-Semantic-Segmentation
图像分割概述
在计算机视觉领域中,将一幅数字图像分割为多个组成部分(一系列像素,或所熟知的超像素)的过程即为图像分割。分割的目标就是简化并/或变换可以将图像转换为更有意义和更易分析的内容的表达。图像分割通常被用来定位图像中目标和边界(线、曲面)的位置。更准确地说,图像分割是为图像中的每一个像素打上标签,其中具有相同标签的像素具有相同特征。在图像分割领域中有多种技术:
基于区域的分割技术
边界检测分割技术
基于聚类的分割技术
图像分割的经典算法
过去,提出了很多不同的算法来进行图像分割,有:
阈值技术--该技术的主要目的在于确定图像的最佳阈值。强度值超过阈值的像素其强度将变为1,其余像素的强度值将变为零,最后形成一个二值图。用于选择阈值的方法有:Otsu,k均值聚类,和最大熵法。
运动与交互分割--该技术基于图像中的运动来进行分割。其思想很直观,在假设目标是运动的情况下找出两幅图中的差异,那么不同之处一定就是目标位置。
边界检测--包含多种数学方法,其目的在于标出数字图像中处于图像亮度变化剧烈,或者更正式的讲,具有不连贯性的区域中的点。由于区域边界和边具有很高关联性,因此边界检测通常是另一种分割技术的前提步骤。
区域增长方法--主要建立在同一区域中相邻像素具有相近像素值的假设之上。常见步骤为将像素与其近邻像素作比较,如果满足相似性标准,则该像素就可以被划分到以一个或更多其近邻点组成的聚类中去。相似性标准的选择很关键,并且在所有实例中其结果易受到噪声影响。

还有很多用于图像分割的方法在上文中未提及,比如双聚类方法、快速匹配法、分水岭变换法等等。
用于图像分割的深度学习模型
UNet--u-net是用来快速准确的分割图像的一种卷积神经网络结构。到目前为止,在ISBI挑战中,该网络较先前最好的模型(一种基于滑动窗口的卷积网络)已在分割电子显微镜下神经元结构的任务中取得了更好的效果。在2015年ISBI大会上,它赢得了计算机自动检测咬翼片中重龋病的大挑战,并且在很大程度上(参见我们的公告)可被认为是两个最具挑战性的透射光显微镜类别上(相位对比度和DIC显微镜),赢得了细胞跟踪的挑战。
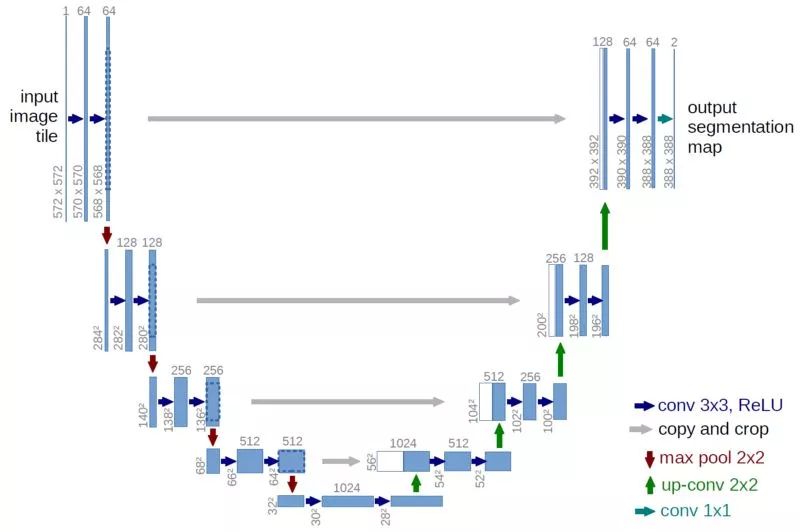
SegNet--SegNet由编码器和解码器构成,但没有全连接层。SegNet是一个包含全卷积网络(FCN)的13 VGG16卷积层。
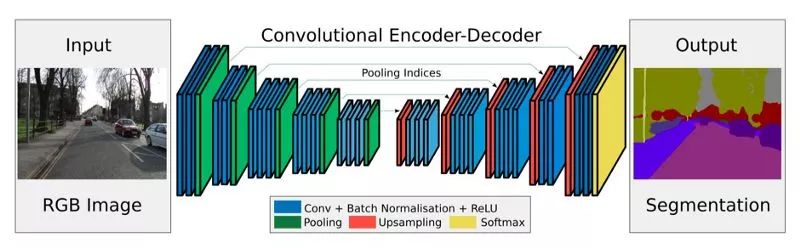
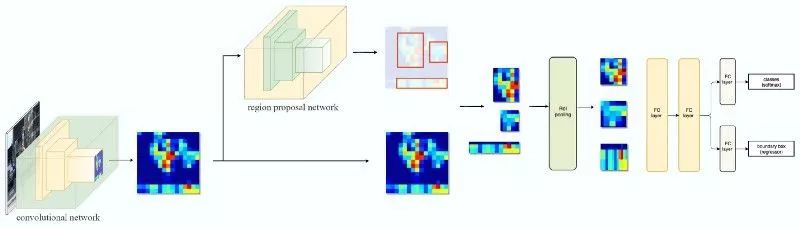
Mask R-CNN--Faster R-CNN采用一个CNN特征提取其来提取图像特征。然后使用CNN区域建议网络来生成感兴趣区域(Roi)。我们应用RoI池化层将它们打包以形成固定维度。然后将其作为全连接层的输入来进行分类和边界框预测。
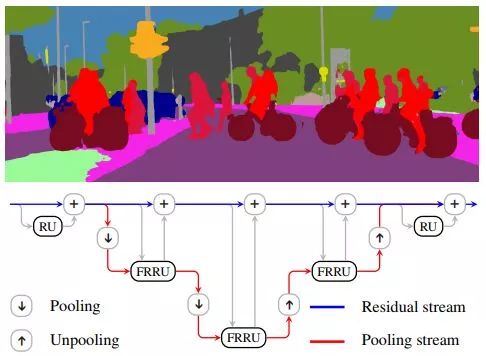
全分辨率残差网络(FRRN)--FRRN通过执行必要的额外处理步骤来获取全图像分辨率下像素精度的分割掩码。
金字塔场景解析网络(PSPNet)--全分辨率残差网络的计算非常密集,应用在全尺度照片上非常缓慢。为了解决这个问题,PSPNet采用了4种不同的最大池化操作,这些操作分别对应4种不同的窗口大小和步长。使用最大池化层可以更有效地提取不同尺度中特征信息。
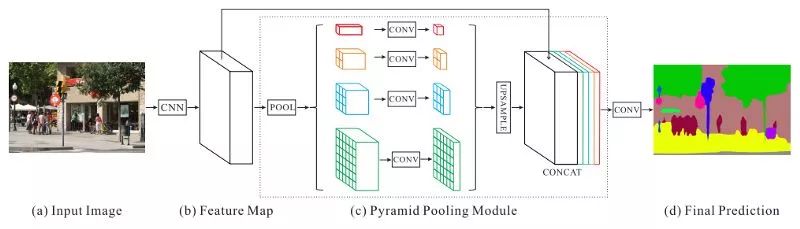
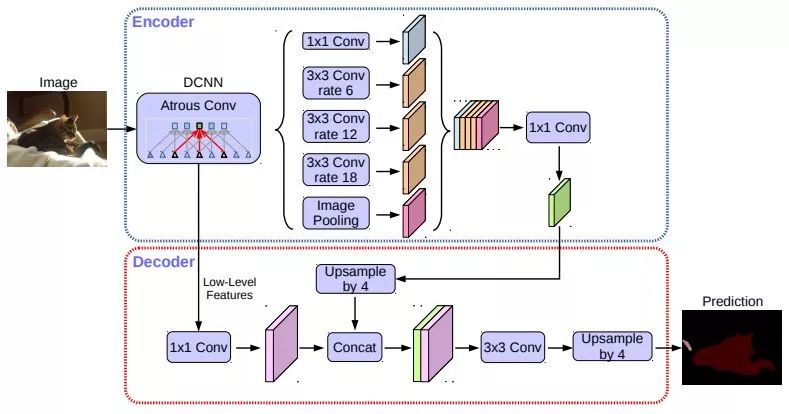
DeepLabv3+ --先前的网络可以通过使用不同变化率的过滤器和池操作来编码多尺度上下文信息。更新的网络可以通过恢复空间信息来捕捉更清晰的目标边界。DeepLabv3+结合了这两种方法。DeepLabv3+同时采用了编码器、解码器和空间金字塔池化模块。
ENet 实现
ENet(Efficient Neural Network)提供了执行实时逐像素语义分割的能力。ENet的执行速度快了18倍,且需要的浮点运算次数少了75倍,同时参数减少了79倍,并且提供了与现有模型对比相似或更高的精度(根据2016年)。在CamVid, CityScapes 和SUN数据集执行测试。
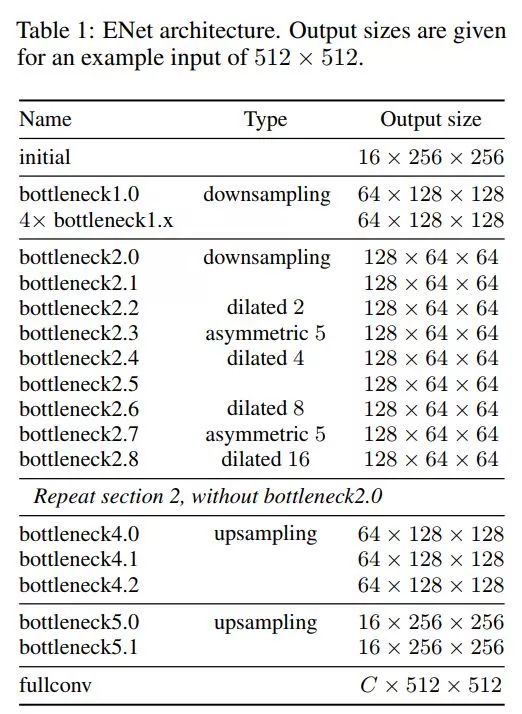
模型体系结构由初始块和五个bottlenecks组成。 前三个bottlenecks用于编码输入图像,另外两个用于解码输入图像。
每个bottlenecks模块包含:
1x1 投影可降低维度
主卷积层(conv)(任意常规、膨胀或者全卷积)(3x3)
1x1 扩张
在所有卷积层之间进行批量标准化和PReLU
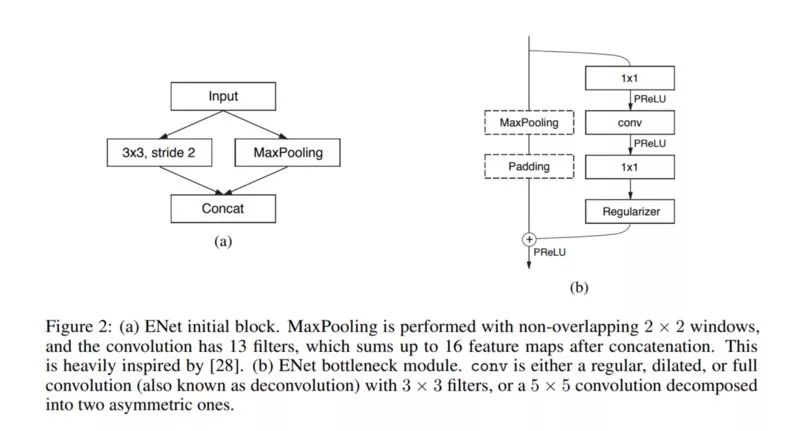
如果bottleneck是降采样,则将最大池化层添加到主分支。同时使用步长为2的 2x2 的卷积替换第一个 1x1的投影。
它们零填充激活以匹配功能图的数量。
卷积有时候是非对称卷积,例如一系列5 * 1 的卷积与1 * 5的卷积。
他们使用空间Dropout进行正则化:
p = 0.01,在 bottleneck2.0前
p = 0.1,之后
ENet 模型结果

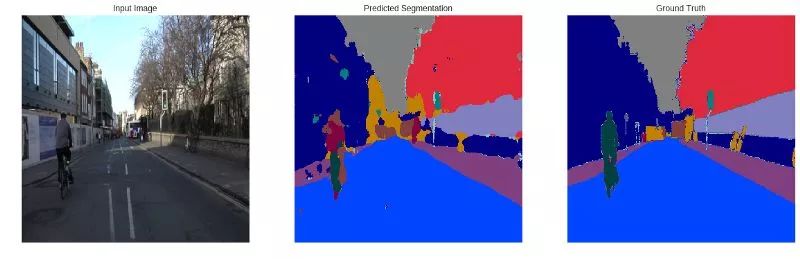

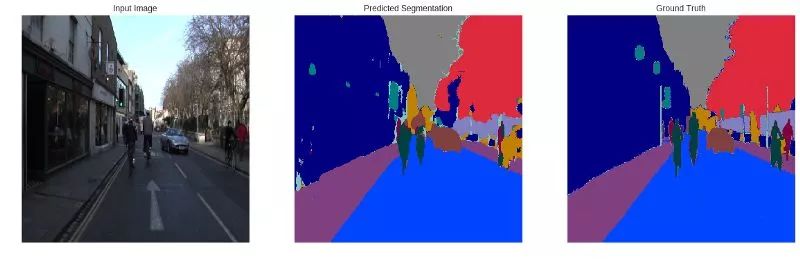

如果喜欢, 不要忘记鼓掌, 标星 和 fork这个项目!!!!
https://github.com/iArunava/ENet-Real-Time-Semantic-Segmentation

点击阅读原文,回看图像分割相关文章



