被繁杂的数据搞到头大?不如让TA帮你实现快准狠!

Google 1999 年成立,到 2003 年开始处理的数据规模已达到 600 亿条,大数据已经不是新的话题,今天,我们更关注数据价值而不是数据本身。

“整合全世界的信息,让它在全球可达,并且有用。”这是 Google 成立之初的使命,也是多年来的努力践行。当我们通过工具去做数据查询和分析时,希望了解其背后代表的信息,甚至从中做商业决定。
2012 年以前,如果想用 Google 大数据领域的技术,更多是阅读 Google 的论文,或者到 Apache 社区去下载这些开源的项目。2012 年 Google Cloud Platform 平台推出后,在 GCP 上就可以更便捷地使用这些数据服务。
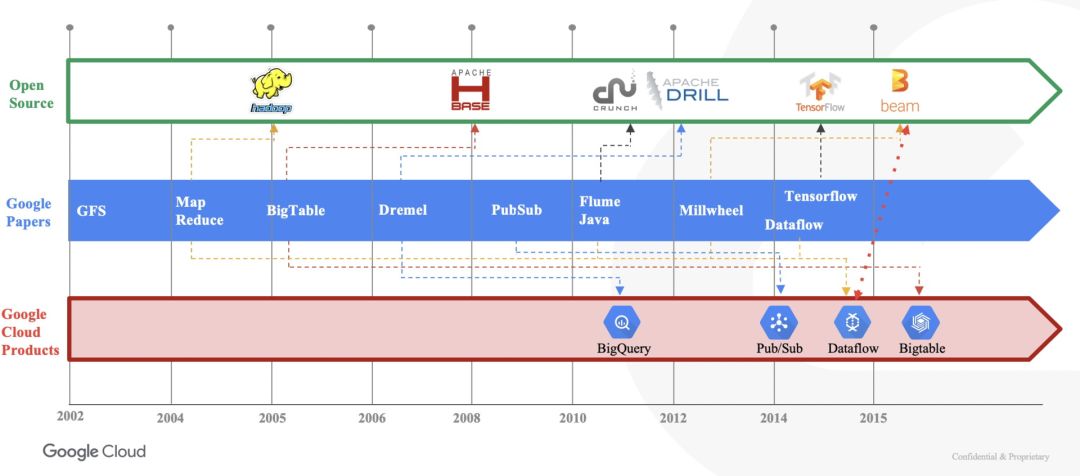
2004 年,Google 发表了一篇论文《MapReduce: Simplified Data Processing on Large Clusters》,提出了 MapReduce 框架,MapReduce 涉及分解一系列简单的 Map 和 Reduce 任务中的所有复杂操作,被用于解决大规模计算问题,这个阶段中更关注的是把大批量数据分而治之,输入的数据集被切分成独立的块,但是它也有难以实现实时流式计算等缺点。
2006 年,雅虎员工发布了 Apache Hadoop 开源项目,MapReduce 是其重要的组件, Hadoop 允许开发人员构建大规模 MapReduce 作业,可以在大型商用机器集群中执行,并且具有极强的弹性和可靠性,但是仍然有作业优化、调度、可写性等问题,Hadoop MapReduce 作业略显笨拙。
2010 年,Google 研究员撰写了一篇名为《FlumeJava: Easy, Efficient Data-Parallel Pipelines》的论文, FlumeJava 出现,引入了一个框架用于组织、执行和调试大规模的 MapReduce 作业管道,可以去管理 MapReduce 未管理到的问题,比如掉队者的问题,优化执行计划,使失败的作业易于回滚而不是从头开始,从而大大减少了 MapReduce 管道的执行时间。
但是在现实业务中我们发现批量数据处理并不能完全满足业务需求,我们希望能实时了解数据并且把它们纳入到统计中,这时出现了 Millwheel, 实现处理实时数据,一直发展到今天在 GCP 上的工具 Dataflow 集成了 Flume、Millwheel 等内部技术,实现同时用一套代码解决数据实时和批量问题。
从论文到开源项目到平台工具,Google 所提供的服务一直遵循着如何让客户使用时更方便,更简单,其背后的技术是复杂的,但是需要保证使用上是简单的,GCP 数据分析平台希望能够让使用者更多的关注分析和洞察,其他如计算资源、存储、数据何时做分区……这些都是 GCP 需要考虑的事。
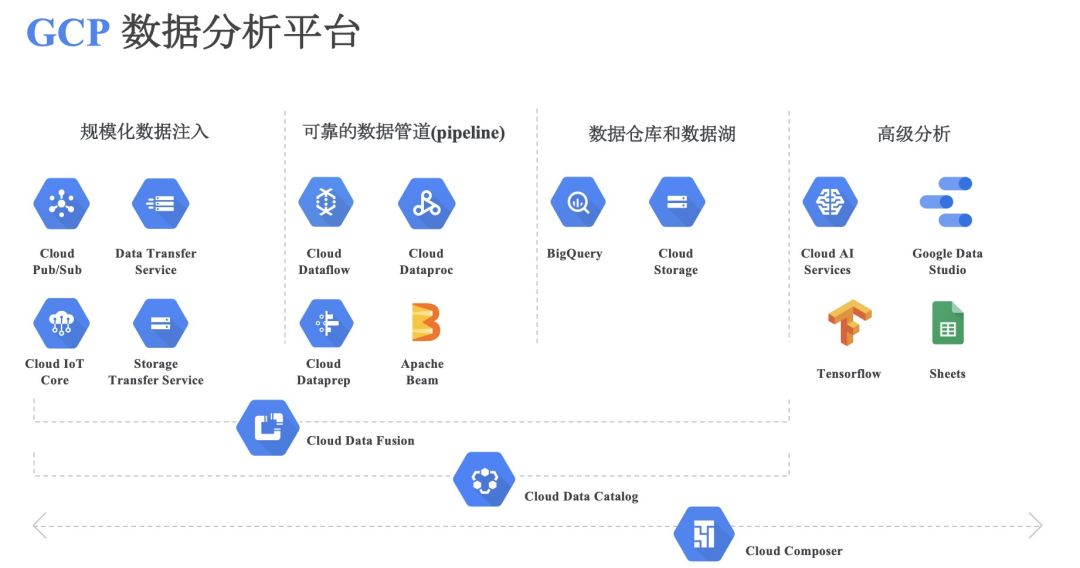
Google 在大数据领域成果颇丰,开放在 GCP 数据分析平台上,为企业提供完整数据生命周期的管理,包括规模化数据注入、数据迁移过程中的处理、数据计算和存储、到最后的高级分析预测、数据展示等。
在整个分享中,Shirley 重点分享了 3 款工具产品
数据注入 - Cloud Pub/Sub
流式和批量数据处理 - Cloud Dataflow
-
数据分析 - BigQuery
在数据注入的时候,往往会遇到数据被重复发送,出现数据延迟,或者发布者和接收者其中一方出了问题等这些异常情况,我们可能会选择恢复数据或者删除处理等方式。而实际上 Google 的 Pub/Sub 为解决这样的情况提供了很多选择。
Google Cloud Pub/Sub 是 Open API, 是一个全托管、无运维、全球性的服务,对于对网络连接重度依赖的应用,Pub/Sub 可以依托 Google 的全球网络,提供实时可靠的服务间消息聊天服务。在 GCP 平台创建一个 Pub/Sub 实例的时候,用户得到的入口是一个全球都可达的边缘节点,不用在每个区域都设计流式处理的入口,使得 Pub/Sub 适用于服务全球的业务。Google 称其已在 Snapchat 以及 Hangouts 应用中支持这项技术。
消息的生命周期机制是 Pub/Sub 里面重要的概念,消息的消费机制,其实就是从发布者到接收者,需要一个介质帮助传递信息和管理信息,以便我们想拿到的时候就能拿到,在 Pub/Sub 里,这个能力就叫做订阅(Subscription),只有当用户确认接收到消息的时候,这个消息才在订阅里消失。
Pub/Sub 可以设置 deadline 区间,从最低 10s 到最高 600s,如果在 deadline 之前没有收到 ACK(确认字符),消息将被重新送入队列。如果在所设置的区间内,接收者都没有明确收到消息,消息将最多保存 7 天。
在消息队列里面,保证消息顺序一直都是难题,比如游戏玩家突然断网,或者在网络传输的过程中,后发生的事件可能先传送到了,这是 Dataflow 可以解决的问题。
Dataflow 可以保证消息能够及时准确按顺序进入系统,进入后对于数据做一定层面的聚合、去重或者数据质量检查、数据清洗等等 ETL 的工作,这里面不仅仅是流式数据,也包含批量数据。数据在进入分析系统之前,Dataflow 其实就是完成预处理的工作。
Dataflow 拥有以下几个特点全托管与自动配置自动图形优化以获得最佳执行路径自动缩放 - 在 Pipeline 启动中间,动态调整每一个 stage 应该分配多少个 workernode动态工作平衡
BigQuery 是企业级的数据仓库,默认加密,从 GB 到 TB 级的存储都是秒级交互式查询,不管数据量多大,比如提交一个 Job,可以随时去看 Job 有没有执行完,是不是把结果放在了制定目标上。
BigQuery 有以下特点
无服务器,全托管
支持实时流数据——即使 BigQuery 没有搭配 Dataflow、Pub/Sub,仍然可以通过 Google 提供的 API 把实时数据放在仓库
内嵌 Machine Learning 功能,在 BigQuery 可以通过 SQL 建模
-
基于内存数据库 BI Engine 加速报表生成——对于复杂大数据查询情况下,是超高效的存储介质
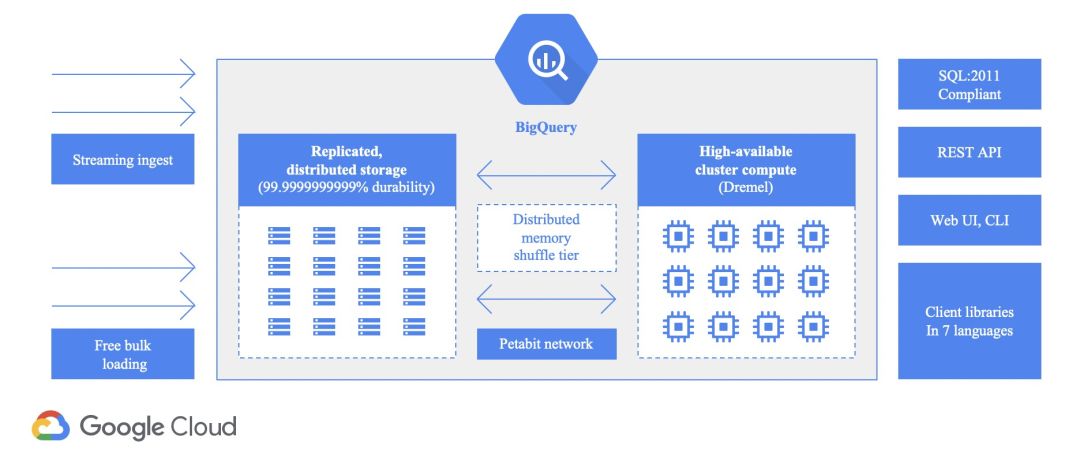
BigQuery 架构同时 BigQuery 架构是一个计算存储分离的结构。计算和存储的分离带来诸多好处,比如自动扩展,在复杂查询场景下,当计算复杂,而涉及的数据并不多的时候,就分配更多的计算资源,当数据量特别大,但是计算相对简单,甚至没有任何计算只是把数据收集起来反馈给用户的时候,就扩展更多的存储资源。
而 Google 强大的网络支撑,保证计算和存储能够协同工作,保证两种资源分开后他们的交流也是非常高效,快速的。
木瓜移动专注于服务国内企业出海,业务覆盖游戏、应用、电商等行业,数据服务上有很多 Google Cloud 数据产品应用经验,木瓜移动数据工程师Bin Wang 主要分享了两个案例。
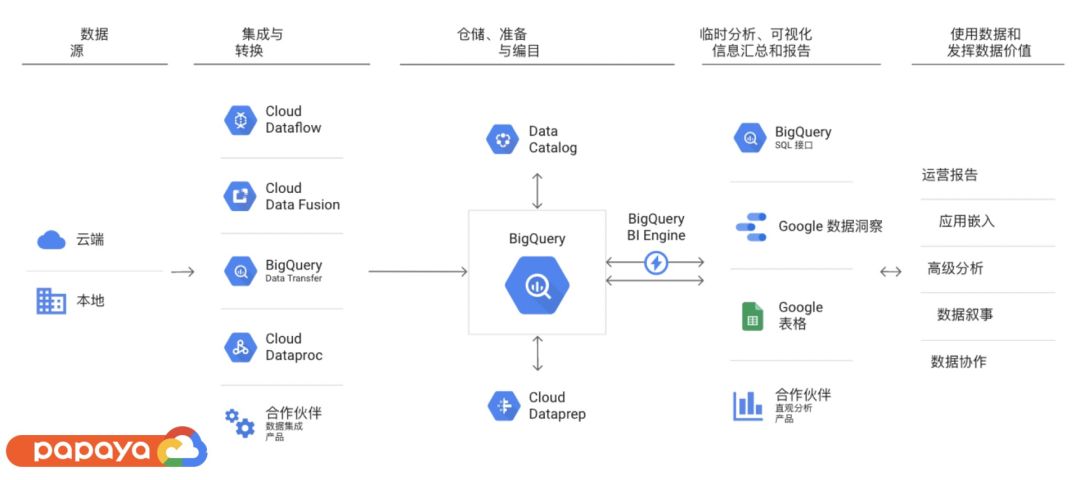
木瓜移动游戏项目正在计划迁到 GCP,目前还没有把数据全部放到 GCP 进行存储和使用。但是在整个数据处理流程中有非常丰富的数据连接器,可以直接把数据放到 BigQuery 里面,在 BigQuery 里经过 Dataproc 或者其他的工具进行清洗之后,直接把数据提供给一线的产品运营或者产品经理,借助 Data Studio 探索更深的价值。
Data Studio 这一工具可以帮助产品运营更好地产出分析报告,除了把数据放到 BigQuery 之前需要一些技术支持,在后面的分析完全不需要技术,产品和运营人员随时可以拿到数据进行探索,在业务操作上非常方便。
对于机器学习项目来说,了解数据、分析数据是非常重要的,它是算法准确性的根基,将机器学习的项目放到 GCP 上,给了木瓜移动很多惊喜。首先数据收集到 BigQuery,在数据分析和处理的时候,GCP 提供了很多的工具,帮助算法工程师和分析工程师简单快速地了解数据,并且把分析过程记录下来,可以进行重放,定期调度。
在机器学习项目中,做模型或者是进行训练之前,往往要做很多特征计算的工作,包括数据特征的处理和选择,将原始数据变成数据特征。
Bin Wang 提到 “之前我们的一些经验就是利用 Spark 加速计算过程,一般算法工程师把代码写好,再由专门开发的工程师对代码进行优化,跑在 Spark 上,如果出错就得从头来过,花费特别多的时间。现在所有数据在 BigQuery 上, 而 BigQuery 本身内嵌 Machine Learning 功能,在 BigQuery 通过 SQL 建模,算法工程师写出来的 SQL 就是工程可以利用的 SQL,再进行后续数据输出。“
在数据分析处理阶段,还用到了 Google Cloud Dataprep,在界面中每执行一项操作,Dataprep 都会自动建议和预测接下来最合适的数据转换操作。用户定义好转换序列后,Dataprep 会在后台使用 Dataflow 来转换数据。
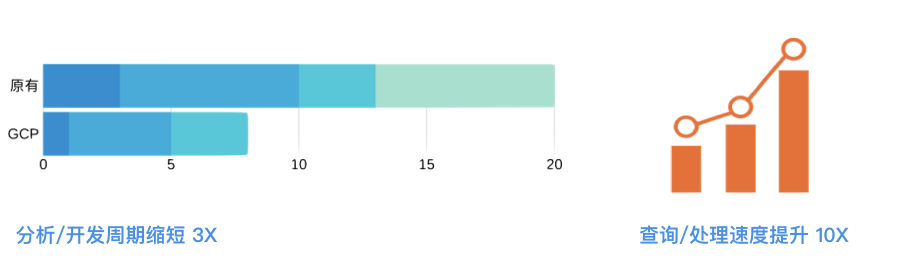
使用 GCP 的数据分析平台,分析开发周期缩短 3 倍,查询处理速度提升 10 倍,木瓜移动项目进度也实现大幅度提高。
Shirley Wang,现担任 GCP 数据分析客户工程师,有丰富的云平台架构设计经验,目前的主要工作是帮助客户设计规划数据分析平台架构、并解决数据分析项目中的技术问题。她本人也对数据分析和机器学习有浓厚的兴趣,热衷于动手实践各种技术,是一个技术派。
Bin Wang ,木瓜移动数据工程师,工作在数据分析和机器学习的第一线,有极强的动手能力,对各大云厂商产品都有所了解,并亲手在 GCP 平台搭建了木瓜移动的数据分析系统。

点个在看少个 bug 👇




