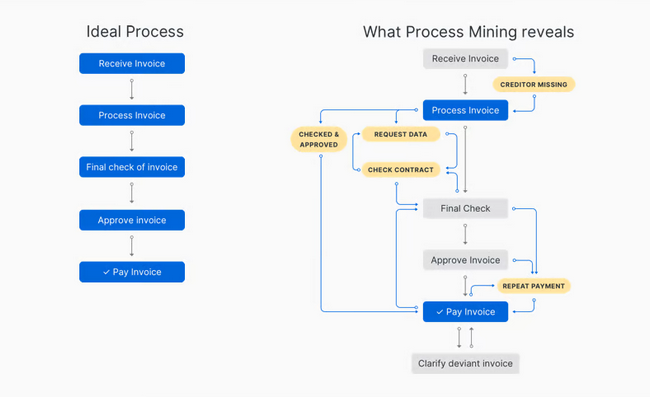
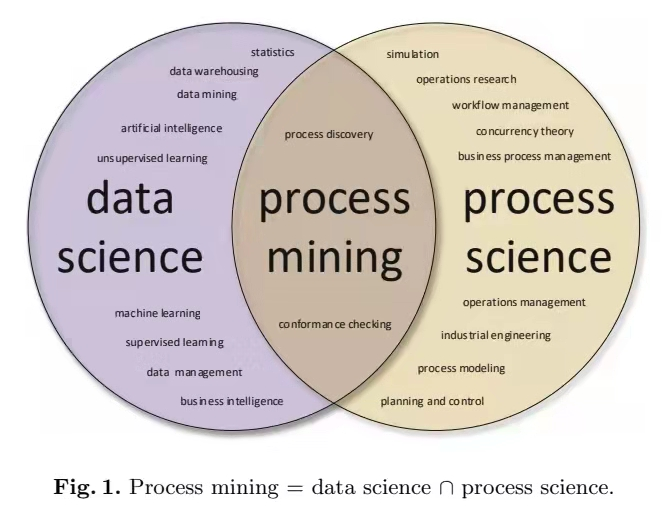
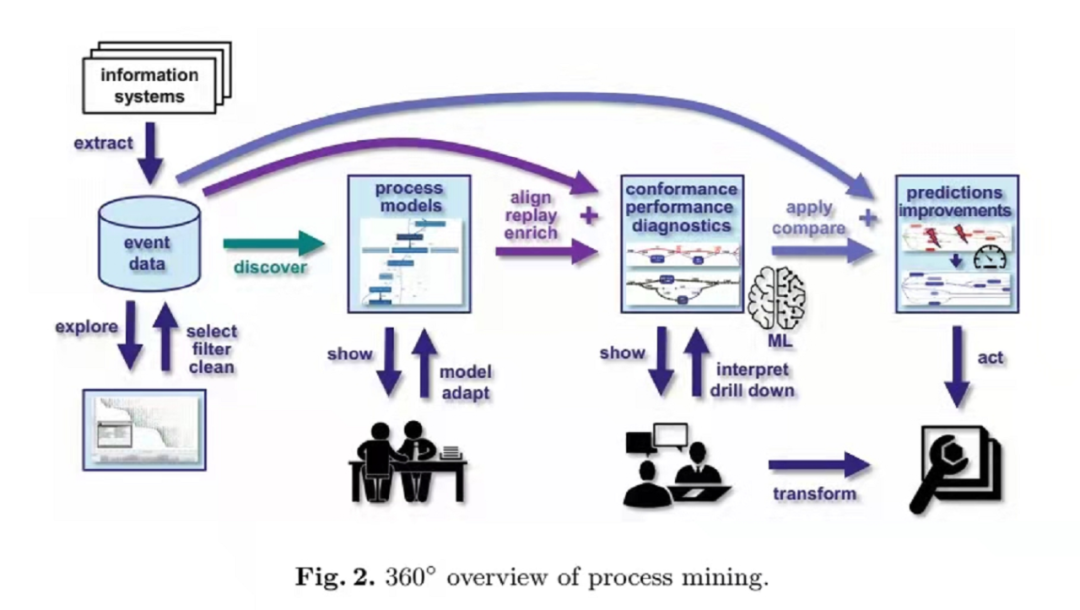
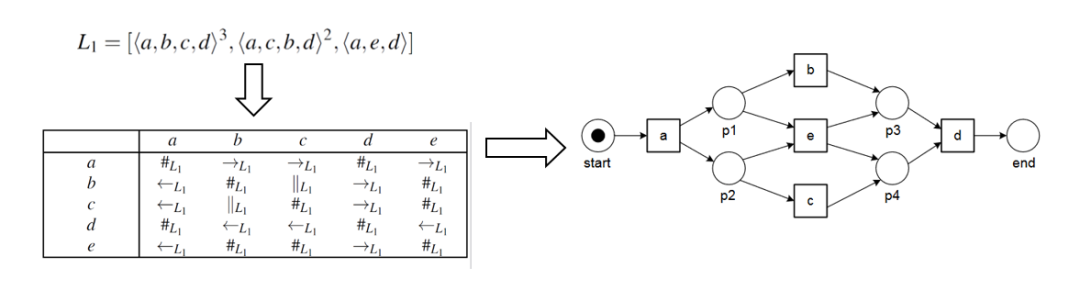
这一小节主要介绍流程挖掘的两个相关领域:业务流程管理(BPM,business process management)和数据挖掘(data mining)。业务流程管理,是一套达成企业各种业务环节整合的全面管理模式。传统的流程管理方法主要是基于先验知识建模,即模型驱动的流程管理,例如工作流技术(Workflow)。这类方法的缺点在于
[1] van der Aalst, W., & Weijters, A. (2004). Process mining: A research agenda. Computers in Industry, 53 (3), 231–244.[2] dos Santos Garcia, C., Meincheim, A., Junior, E. R. F., Dallagassa, M. R., Sato, D. M. V., Carvalho, D. R., ... & Scalabrin, E. E. (2019). Process mining techniques and applications–A systematic mapping study. Expert Systems with Applications, 133, 260-295.[3] van der Aalst, W. (2012a). Process mining: Overview and opportunities. ACM Transactions on Management Information Systems, 3 (2), 1–17.[4] van der Aalst, W. M., & Carmona, J. (2022). Process Mining Handbook.[5] Rosa, M. L., Aalst, W. M. P. V. D., Dumas, M., & Milani, F. P. (2017). Business process variability modeling: A survey. ACM Comput. Surv., 50 (1), 2:1–2:45.[6] van der Aalst, W., Weijters, T., & Maruster, L. (2004). Workflow mining: Discovering process models from event logs. IEEE Transactions on Knowledge and Data Engineering, 16 (9), 1128–1142.[7] Weijters, A. J. M. M., & van der Aalst, W. M. P. (2003). Rediscovering workflow models from event-based data using Little Thumb. Integrated Computer-Aided Engineering, 10(2), 151-162.[8] vanden Broucke, S. K., & De Weerdt, J. (2017). Fodina: A robust and flexible heuristic process discovery technique. decision support systems, 100, 109-118.[9] van der Aalst, W. M., Medeiros, A. K., & Weijters, A. J. (2005, June). Genetic process mining. In International conference on application and theory of petri nets (pp. 48-69). Springer, Berlin, Heidelberg.[10] Márquez-Chamorro, A. E., Resinas, M., Ruiz-Cortés, A., & Toro, M. (2017). Run-time prediction of business process indicators using evolutionary decision rules. Expert Systems with Applications, 87 , 1–14.[11] Günther, C. W., & van der Aalst, W. M. P. (2007). Fuzzy mining –Adaptive process simplification based on multi-perspective metrics. In Lecture notes in computer science (pp. 328–343). Springer Berlin Heidelberg.[12] van der Aalst, W. (2016). Process mining: Data science in action . Springer Berlin Heidelberg.