不可错过!纽约大学最新《语音识别Speech Recognition》2020课程,学习语音最新技术进展!

本课程以计算机科学的方式介绍自动语音识别,以及正确转录语音的问题。描述包括创建大规模语音识别系统的基本算法。所提出的算法和技术目前已在大多数研究和工业系统中得到应用。
目前在自然语言处理、计算生物学和机器学习的其他应用领域中使用的许多学习和搜索算法和技术,最初都是为解决语音识别问题而设计的。语音识别继续给计算机科学带来挑战性的问题,特别是因为它产生的学习和搜索问题的规模。
因此,本课程的目的不仅仅是让学生熟悉语音识别中使用的特定算法,而是以此为基础来探索一般的文本和语音,以及与计算机科学其他领域相关的机器学习算法。本课程将利用几个软件库,并将研究这一领域的最新研究和出版物。
https://cs.nyu.edu/~mohri/asr12/
目录内容:
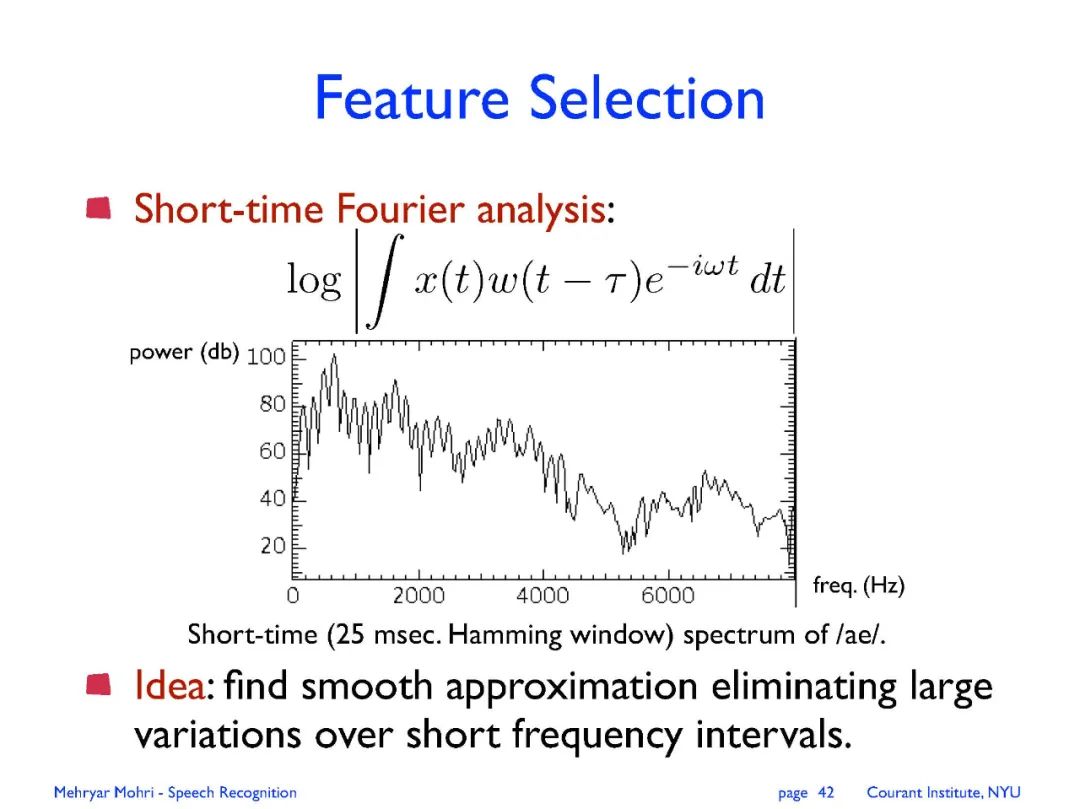
Lecture 01: introduction to speech recognition, statistical formulation.
Lecture 02: finite automata and transducers.
Lecture 03: weighted transducer algorithms.
Lecture 04: weighted transducer software library.
Lecture 05: n-gram language models.
Lecture 06: language modeling software library.
Lecture 07: maximum entropy (Maxent) models.
Lecture 08: expectation-maximization (EM) algorithm, hidden Markov models (HMMs).
Lecture 09: acoustic models, Gaussian mixture models.
Lecture 10: pronunciation models, decision trees, context-dependent models.
Lecture 11: search algorithms, transducer optimizations, Viterbi decoder.
Lecture 12: n-best algorithms, lattice generation, rescoring.
Lecture 13: discriminative training (invited lecture: Murat Saraclar).
Lecture 14: structured prediction algorithms.
Lecture 15: adaptation.
Lecture 16: active learning.
Lecture 17: semi-supervised learning.







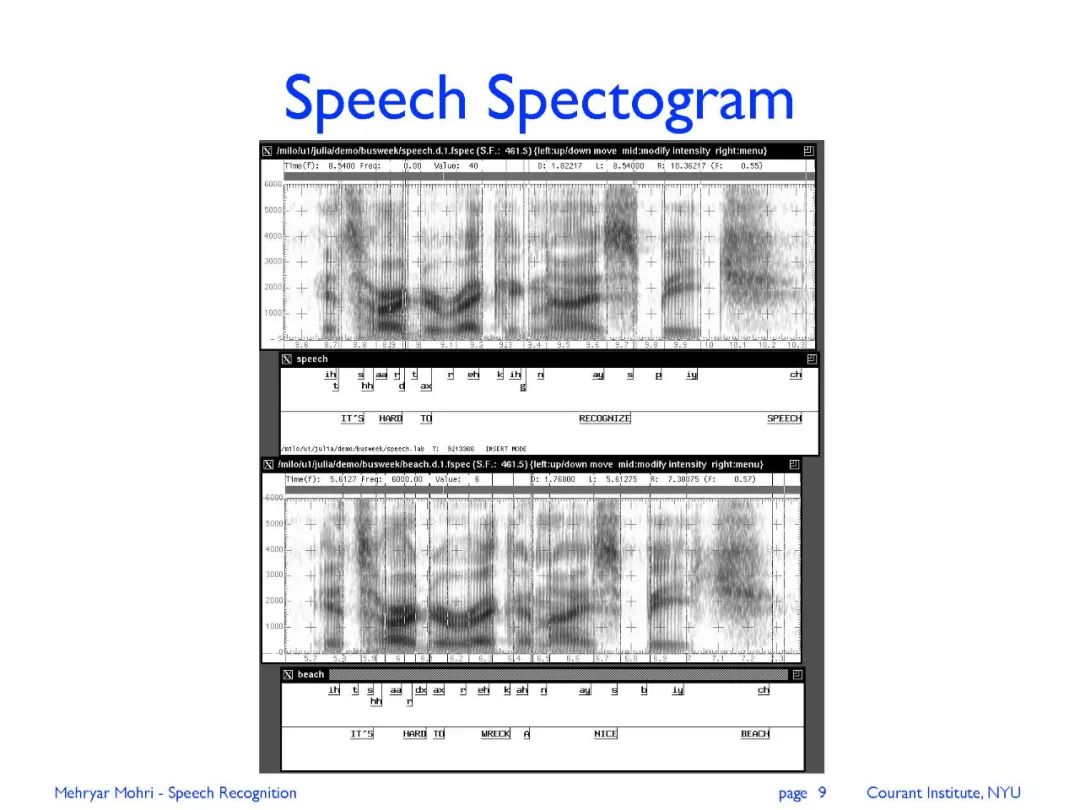







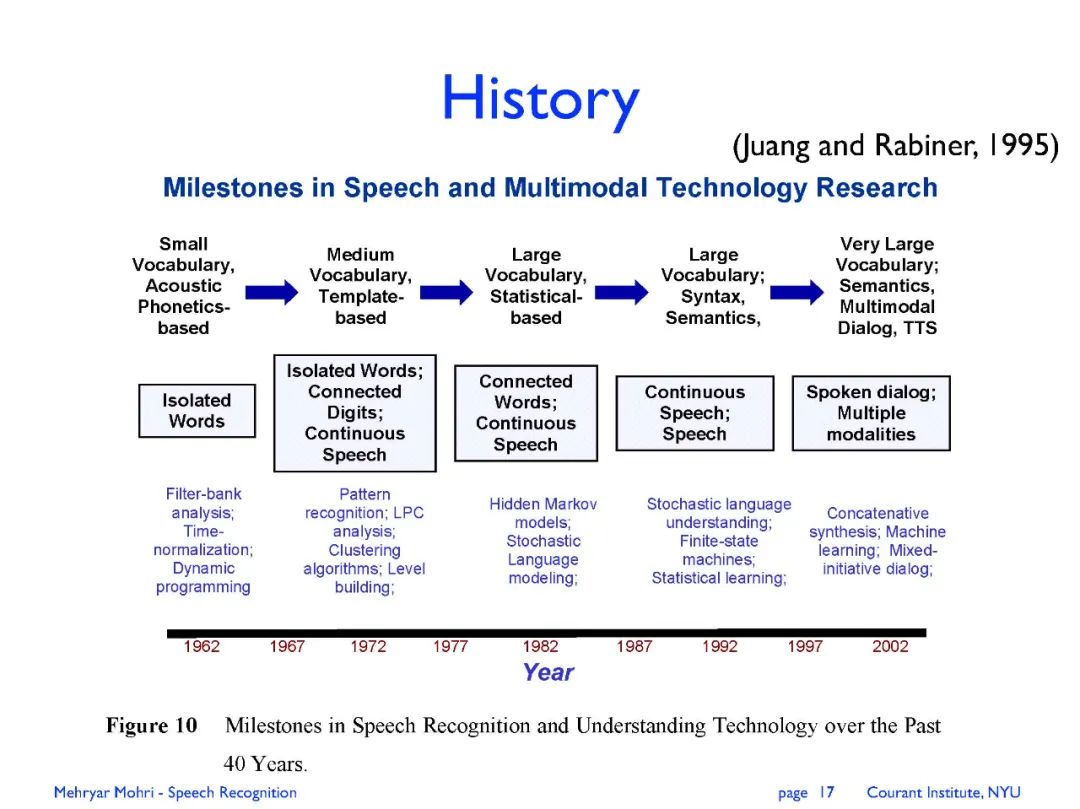
















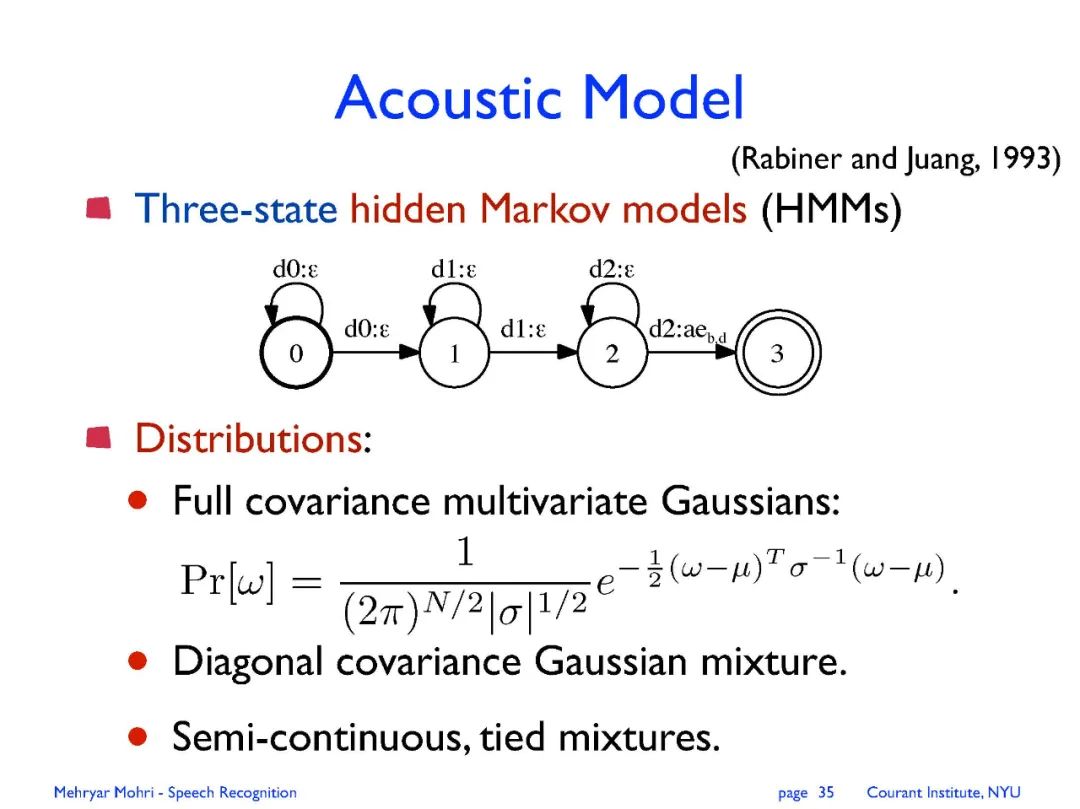



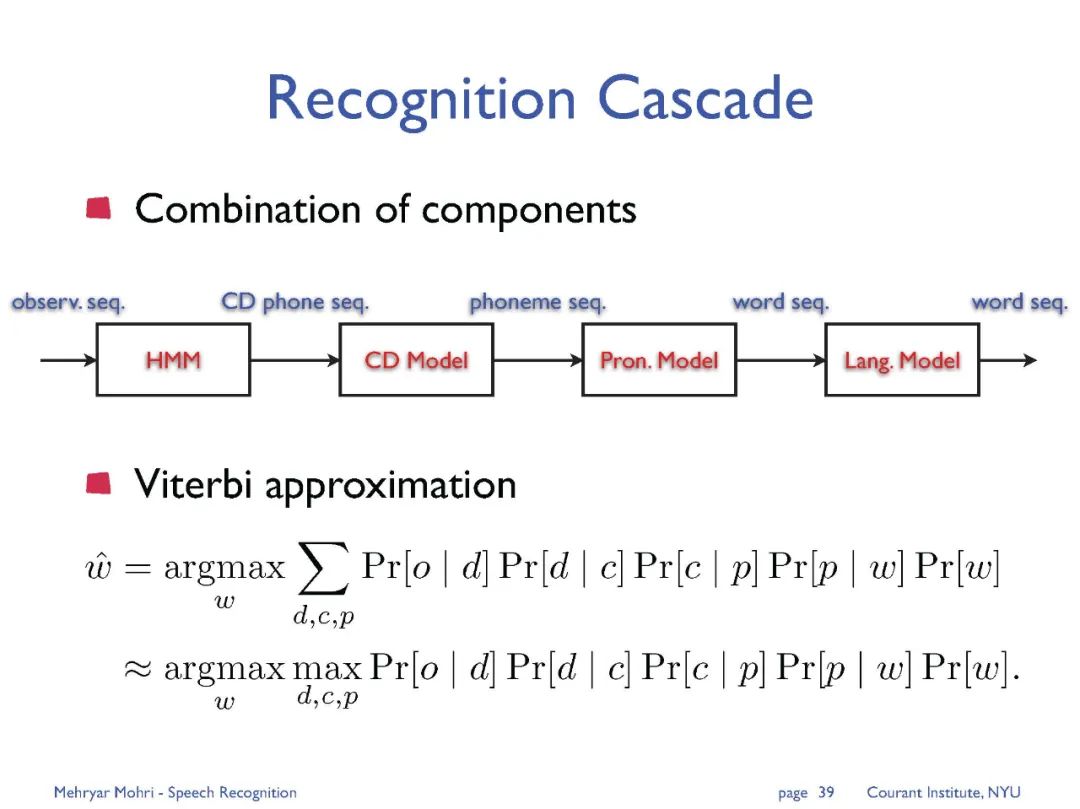







专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SR2020” 可以获取《不可错过!纽约大学最新《语音识别Speech Recognition》2020课程,学习语音最新技术进展!》专知下载链接索引








