IJCAI2022 | MLP4Rec: 基于纯MLP的序列化推荐模型
标题:MLP4Rec: A Pure MLP Architecture for Sequential Recommendations
链接:https://arxiv.org/pdf/2204.11510v1.pdf
会议:IJCAI 2022

1. 导读
自注意力模型通过捕获用户-商品交互之间的序列依赖关系,在序列推荐系统中实现了最佳性能。但是,它们依赖于位置embedding来保留顺序关系,这可能会破坏商品embedding的语义。大多数现有工作都假设这种顺序依赖性仅存在于商品embedding中,而忽略了它们在商品特征中的存在。本文基于 MLP 的架构的最新进展提出了一种新颖的序列推荐系统 (MLP4Rec),该方法对序列中商品的顺序敏感,设计一种三向融合方案,连贯地捕获顺序、跨通道和跨特征相关性。
2. 懒人阅读
本文针对序列推荐提出MLP4Rec方法,针对位置编码可能会破坏embedding语义的问题以及特征中的顺序依赖关系问题,作者提出了三向融合方案。主要是采用三个MLP分别在不同的维度上进行交互和序列信息发掘。分别采用序列混合器,通道混合器和特征混合器三个块构成一层,经过多层得到最终的embedding进行预测打分。
-
在embedding层得到商品ID和特征的embedding -
将商品的各个特征和ID的embedding进行堆叠可以得到2-d的张量,然后再将序列中的各个商品对应的二维张量堆叠可以得到3-d的张量。 -
序列混合器是在序列维度上对不同商品对应的同一特征经过MLP挖掘顺序关系 -
通道混合器是在通道维度上对同一商品的不同通道经过MLP挖掘挖通道的相关性 特征混合器是在特征维度进行特征交互
3. 方法
3.1 问题定义
用户集合为 ,商品集合为 ,商品m的特征集合为 ,用户n的交互序列为 。序列推荐的目标就是预测第s+1次可能交互的商品。
3.2 框架概览
MLP4Rec可以显式地学习三向信息。第一个是时间信息,即 之间的顺序依赖关系。第二个是商品embedding中包含的兴趣信息,由于商品embedding的不同通道(维度)代表不同的潜在语义,因此跨通道相关性对任务也很重要。第三个是商品特征之间的相关性,它们共同有助于对商品的语义进行建模。如图 2 所示,通过在输入embedding的不同方向上重复转置和应用 MLP 块,可以同时捕获顺序、跨通道和跨特征相关性。
MLP4Rec包含L层,每一层都有相同的设置,一个序列混合器、一个通道混合器和一个特征混合器。所有层都共享参数来减少模型参数量,每一层中都是先对特征使用序列混合器和通道混合器,学习唯一的表征,然后使用特征混合器学习特征之间的关系。
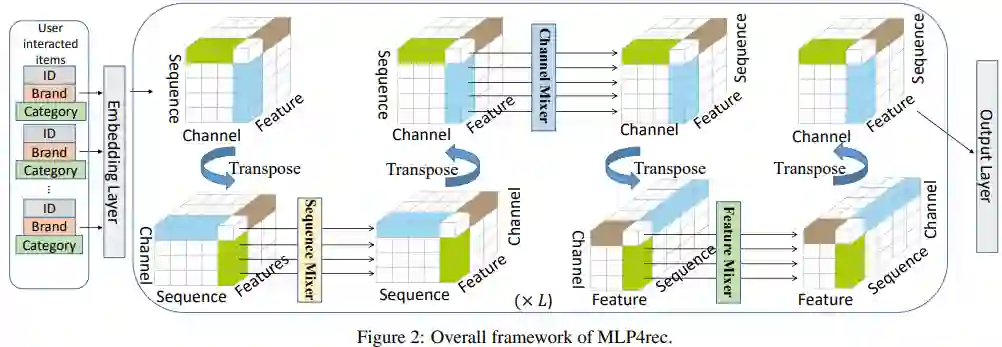
3.3 框架细节
3.3.1 embedding层
采用常用方法来构建商品 ID embedding和特征embedding,即学习embedding查找表以将离散的商品ID和特征(例如类别和品牌)投影到维度为C的稠密向量表征中。之后,可以将商品 ID 和显式特征的embedding堆叠到单独的embedding表中,其中embedding表的行是每个embedding向量,列包含通道信息。将所有embedding表堆叠在一起,得到一个 3-d embedding表。与自注意力方法不同的是,本文的方法不需要位置embedding。
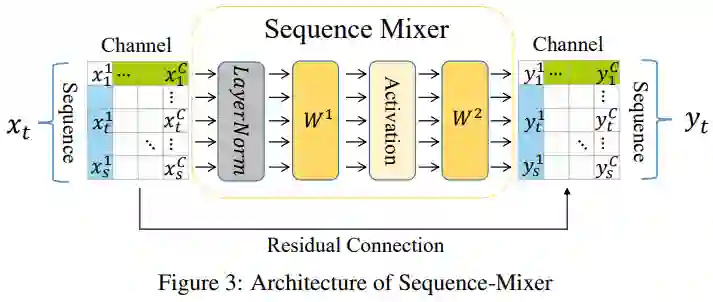
3.3.2 序列混合器
序列混合器是一个 MLP 块,旨在学习整个商品序列的顺序依赖关系。序列混合器块将embedding表的行作为输入特征(应用于转置的embedding表),并输出与输入具有相同维度的embedding表。但是在这个输出表中,所有的顺序依赖都融合在每个输出序列中。具体来说,如图3所示,一组输入特征将是整个序列中每个嵌入向量的第 c 个维度,即 。它们之间存在顺序关系,这显示了用户兴趣随时间的演变,从而使序列混合器对顺序敏感。第 层的公式表示如下,其中 为输入特征,t=1,...,s,
3.3.3 通道混合器
结合和序列混合器类似,不过他的目标是学习embedding向量内部的相关性。商品 ID 或商品特征的embedding通常在每个维度上表达一些潜在语义,学习它们的表征和内部相关性对于推荐至关重要。通道混合器将embedding表的列作为输入特征,如图 2 所示,在将嵌入表转回其原始形状后应用通道混合器。在序列混合器之后,在每个序列中融合了序列信息,但尚未发现跨通道相关性。通道混合器将第 t 个 商品embedding 的维度作为输入特征,即 ,它们之间的相关性是跨通道的,共同表达了整体embedding的语义。所以在通道混合器之后,跨通道相关性将融合在输出序列内。第 层的公式表示如下,c=1,...,C
3.3.4 特征混合器
特征混合器是将特征连接在一起的关键组件,在序列混合器和通道混合器之后,顺序和跨通道依赖关系在每个序列中融合。但是,不同特征的embedding表之间的信息仍然是相互独立的。特征混合器可以将交叉特征相关性融合到每个序列的表征中。由于特征混合器是一层中的最后一个块,它不仅传递特征信息,而且将每个特征内的顺序和跨通道依赖关系共享给其他特征。特征混合器作用于特征维度,如图 2 所示。第 层的公式表示如下,k=1,...,K
3.4 训练和推理
和常见的序列推荐方法一样,本文也采用各个序列的子序列构建交叉熵损失函数,公式如下
推理预测阶段,经过 L 层的序列混合器、通道混合器和特征混合器,得到一个隐藏状态序列,其中分别包含每个交互的顺序、跨通道和跨特征依赖关系。假设在时间步 t,预测下一个项目 给定隐藏状态序列 ,可以通过点积计算 和所有候选商品embedding 之间的余弦相似度,m=1,,...,M
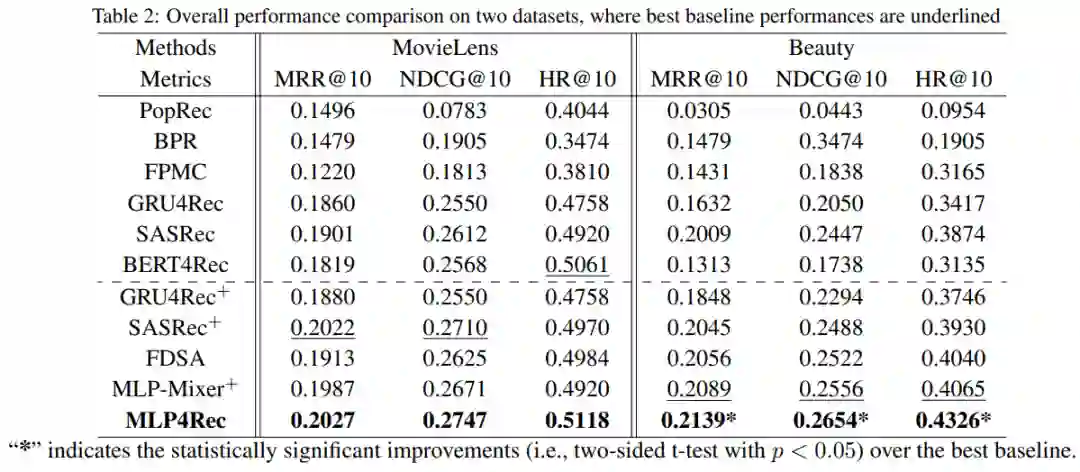
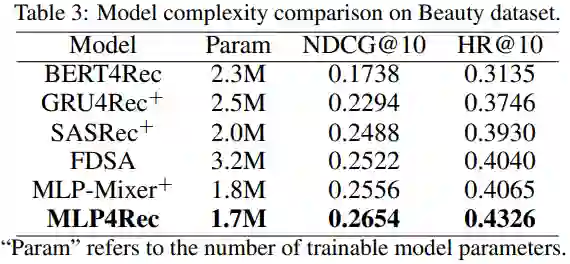
4. 结果
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
WWW2022 | Recommendation Unlearning
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
