论文浅尝 | 基于表示学习的大规模知识库规则挖掘

动机
传统的规则挖掘算法因计算量过大等原因无法应用在大规模KG上。为了解决这个问题,本文提出了一种新的规则挖掘模型RLvLR(Rule Learning via LearningRepresentation),通过利用表示学习的embedding和一种新的子图采样方法来解决之前工作不能在大规模KG上scalable的问题。
亮点
文章的亮点主要包括:
(1)采样只与对应规则相关的子图,在保存了必要信息的前提下极大减少了算法的搜索空间和计算量;
(2)提出了argument embedding,将规则表示为predicate sequence;
概念
1. closed-pathrule,LHS记为body(r),RHS记为head(r)

2. supportdegree of r,满足 r 的实体对个数
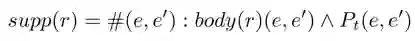
3. standard confidence 和 head coverage
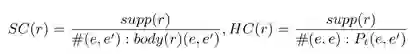
方法

⒈ Sampling Method
以head predicate Pt为输入,把KG看成无向图,选择到Pt的头尾实体路径长不超过len-1的实体和关系组成子图K’=(E’,F’),后面所有的计算都基于这个子图。
⒉ argument embedding
对于谓词P,它的subject argument定义为所有出现在subject上实体的embedding的加权平均,object argument则为尾实体上实体的embedding的加权平均,这个主要用在后面的score function上,即本文引入了共现的信息,对于路径(P1,P2)来说,P1的object argument与P2的subject argument应该很相似,这里就应用到了下面说的基于argument embedding的score function。

⒊ co-occurrence score function
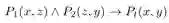
这个 score function 就是基于上面的 argument embedding,以上图这个长为 3 的 rule 为例,path p=P1,P2的embedding是P1*P2,之前通用的synonymy scoring function就是让 p 和 Pt 的 embedding 相似,再与这个本文提出的co-occurrence scorefunction,结合起来就是最后的score function,下图左边的就是利用了路径的同义信息,即 body(r) 的 predicate embedding path 的乘积应当与 head 的 predicate embedding 相似。

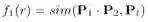


⒋ Rule Evaluation
根据 score function 抽出来的 rule 还要进过筛选,具体做法是先排除掉 support degree 小于 1 的 rule,再过滤掉 standard confidence<minSC 和 head coverage<minHC 的 rule。
实验
⑴. 数据集
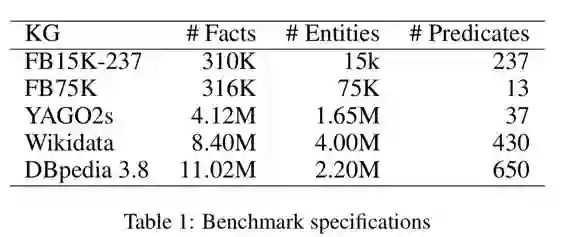
本文的关注点是 scalable,所以选取做比较的数据集都是大规模知识库
⑵. 实验结果
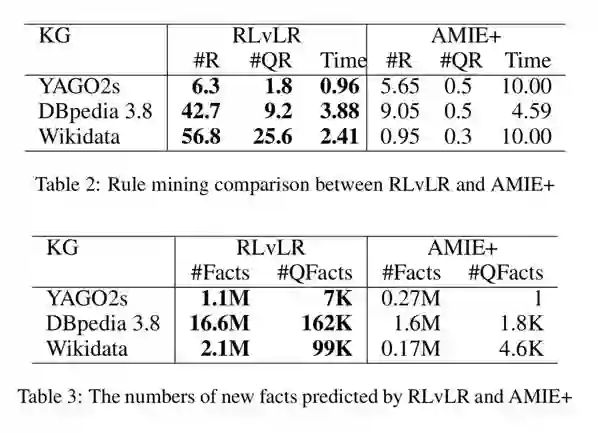
作者与 AMIE+ 在三个规模较大的知识库上进行了比较,具体做法是随机选取 20 个 target predicate 进行挖掘,其中 R 是 SC>0.1&HC>0.01 的规则,QC 是 SC>0.7 的规则,结果显示了 RLvLR 在大规模 KG 上的效率和挖掘规则的能力。
总结
本文提出了一种可以在大规模 KG 上可以以较小计算量进行规则挖掘的模型,减少计算量的方式包括子图采样,argument embedding 和 co-occurrence score function。
论文笔记整理:汪寒,浙江大学硕士,研究方向为知识图谱、自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



