近期必读的五篇AAAI 2021【3D视觉目标学习】相关论文和代码
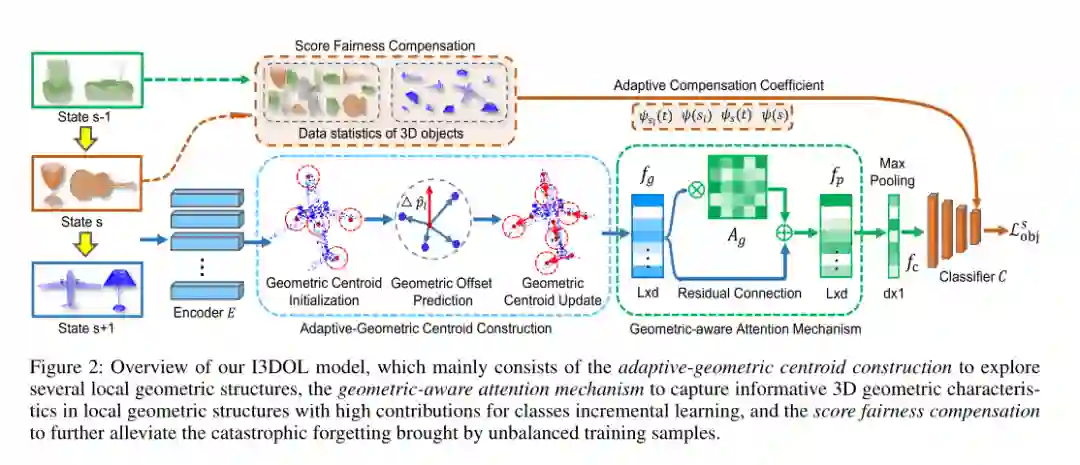
1. I3DOL: Incremental 3D Object Learning without Catastrophic Forgetting
作者:Jiahua Dong, Yang Cong, Gan Sun, Bingtao Ma, Lichen Wang
摘要:3D目标分类在学术研究和工业应用中引起了人们的关注。但是,当面对常见的现实场景时,大多数现有方法都需要访问过去3D目标类的训练数据:新的3D目标类按顺序到达。此外,由于3D点云数据的不规则和冗余几何结构,对于过去学习的已知类(即灾难性遗忘),先进方法的性能会大大降低。为了解决这些挑战,我们提出了一种新的增量式3D目标学习(即I3DOL)模型,这是不断学习新类别的3D目标的首次探索。具体来说,自适应几何质心模块被设计用来构造可区分的局部几何结构,从而可以更好地表征3D目标的不规则点云表示。然后,为防止冗余几何信息带来的灾难性遗忘,我们开发了一种几何感知注意力机制来量化局部几何结构的贡献,并探索对类别增量学习具有高贡献的独特3D几何特征。同时,提出了一种分数公平性补偿策略,通过在验证阶段补偿新类的偏向预测,进一步减轻了过去和新类3D目标之间数据不平衡所导致的灾难性遗忘。在3D代表性数据集上进行的实验验证了I3DOL框架的优越性。
网址:
https://www.zhuanzhi.ai/paper/d53544eea1a0c20c1c5ef76901ed855b
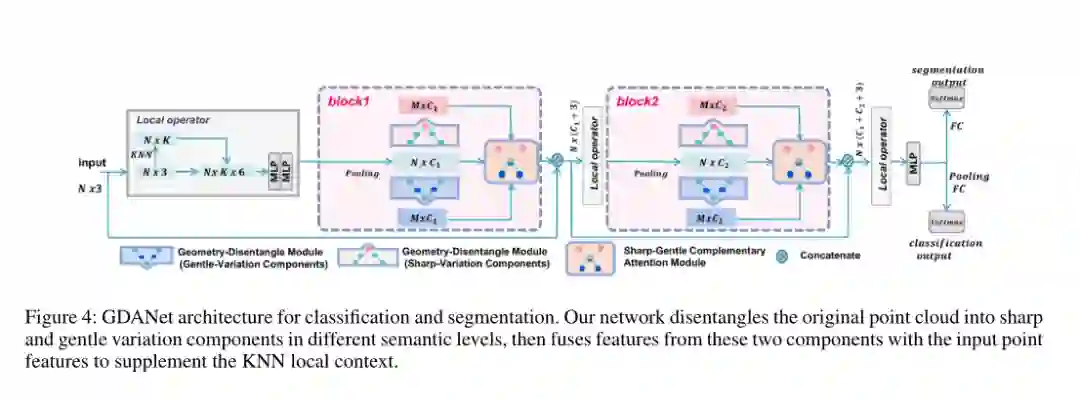
2. Learning Geometry-Disentangled Representation for Complementary Understanding of 3D Object Point Cloud
作者:Mutian Xu, Junhao Zhang, Zhipeng Zhou, Mingye Xu, Xiaojuan Qi, Yu Qiao
网址:在2D图像处理中,一些尝试将图像分解为高频和低频分量,分别描述边缘和平滑部分。类似地,3D目标的轮廓和平坦区域(例如椅子的边界和座椅区域)描述了不同但互补的几何形状。但是,这样的研究在以前的深层网络中丢失了,这些深层网络通过直接平等地对待所有点或局部面来理解点云。为了解决这个问题,我们提出了几何分离注意力网络(GDANet)。GDANet引入了Geometry-Disentangle模块,可将点云动态分解为3D目标的轮廓和平坦部分,分别由清晰而柔和的变化分量表示。然后,GDANet利用Sharp-Gentle Complementary Attention模块,该模块将锐利和柔和变化成分的特征视为两个整体表示,并在将它们分别与原始点云特征融合时给予了不同的关注。通过这种方式,我们的方法从两个不同的解缠组件中捕获并完善了整体和互补的3D几何语义,以补充局部信息。关于3D目标分类和细分基准的大量实验表明,GDANet使用更少的参数即可实现最新技术。
网址:
https://www.zhuanzhi.ai/paper/e8f84338d92b8a54105b6e7ba00302c9
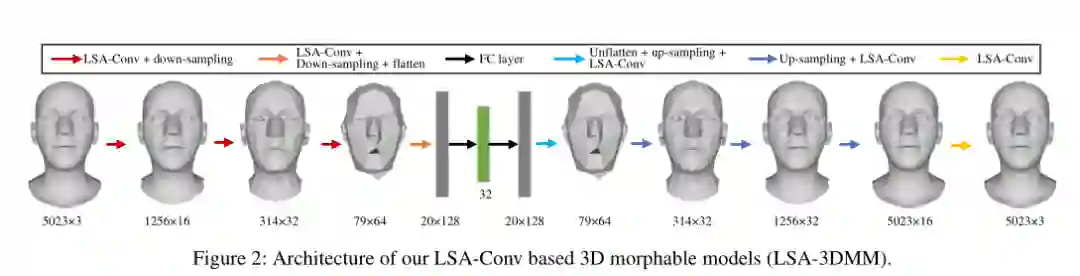
3. Learning Local Neighboring Structure for Robust 3D Shape Representation
作者:Zhongpai Gao, Junchi Yan, Guangtao Zhai, Juyong Zhang, Yiyan Yang, Xiaokang Yang
摘要:网格(Mesh)是用于3D形状的强大数据结构。3D网格的表示学习在许多计算机视觉和图形应用中很重要。卷积神经网络(CNN)在结构化数据(例如图像)方面的最新成功表明,将CNN的洞察力应用于3D形状具有重要意义。但是,由于每个节点的邻居都是无序的,因此3D形状数据是不规则的。已经开发出了用于3D形状的各种图神经网络以克服图中的节点不一致问题,例如:具有各向同性过滤器或预定义局部坐标系。但是,各向同性过滤器或预定义的局部坐标系会限制表示能力。在本文中,我们提出了一种局部结构感知anisotropic卷积运算(LSA-Conv),该算法根据局部邻近结构为每个节点学习自适应加权矩阵,并执行共享anisotropic滤波器。实际上,可学习的加权矩阵类似于随机合成器中的注意力矩阵-一种用于自然语言处理(NLP)的新型Transformer模型。全面的实验表明,与最新方法相比,我们的模型在3D形状重建中产生了显着改善。
网址:
https://www.zhuanzhi.ai/paper/b011af0fb636f35cfc5aa72720507db6
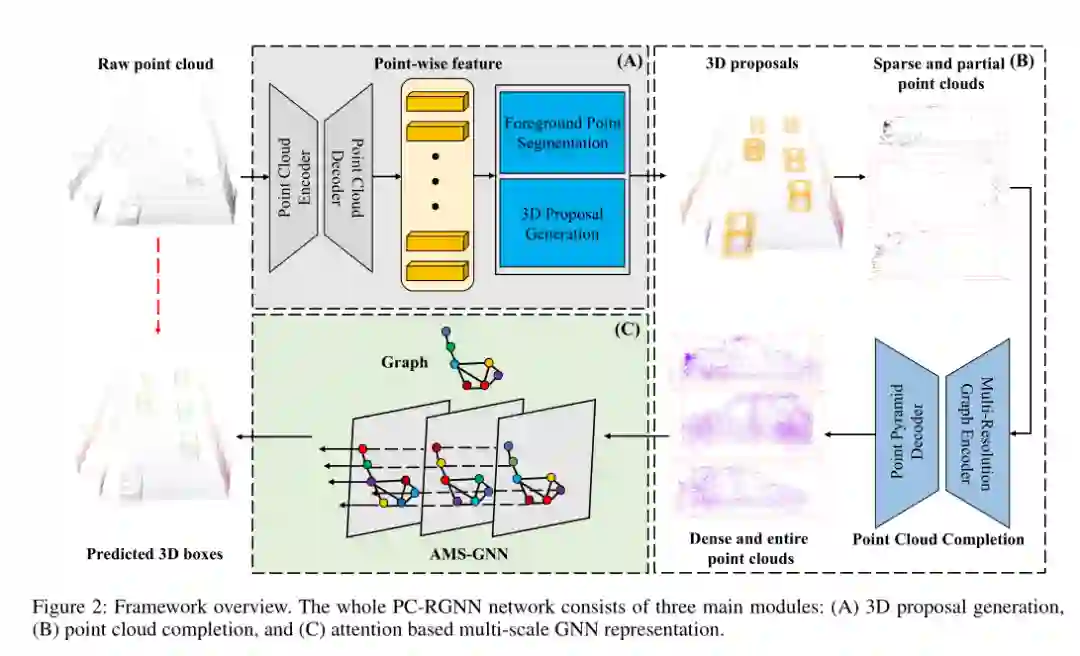
4. PC-RGNN: Point Cloud Completion and Graph Neural Network for 3D Object Detection
作者:Yanan Zhang, Di Huang, Yunhong Wang
摘要:基于LiDAR的3D目标检测是自动驾驶的一项重要任务,当前的方法遭受着遥远和被遮挡目标的稀疏和部分点云的困扰。在本文中,我们提出了一种新颖的两阶段方法,即PC-RGNN,它通过两个特定的解决方案来应对此类挑战。一方面,我们引入了点云完成模块,以恢复密集点和保留原始结构的整个视图的高质量建议。另一方面,设计了一个神经网络模块,该模块通过局部全局注意力机制以及基于多尺度图的上下文聚合来全面捕获点之间的关系,从而大大增强了编码特征。在KITTI基准上进行的大量实验表明,所提出的方法以显着优势超越了之前的最新基准。
网址:
https://www.zhuanzhi.ai/paper/9aa0b239a86d79a3c9dc506dd11f691d
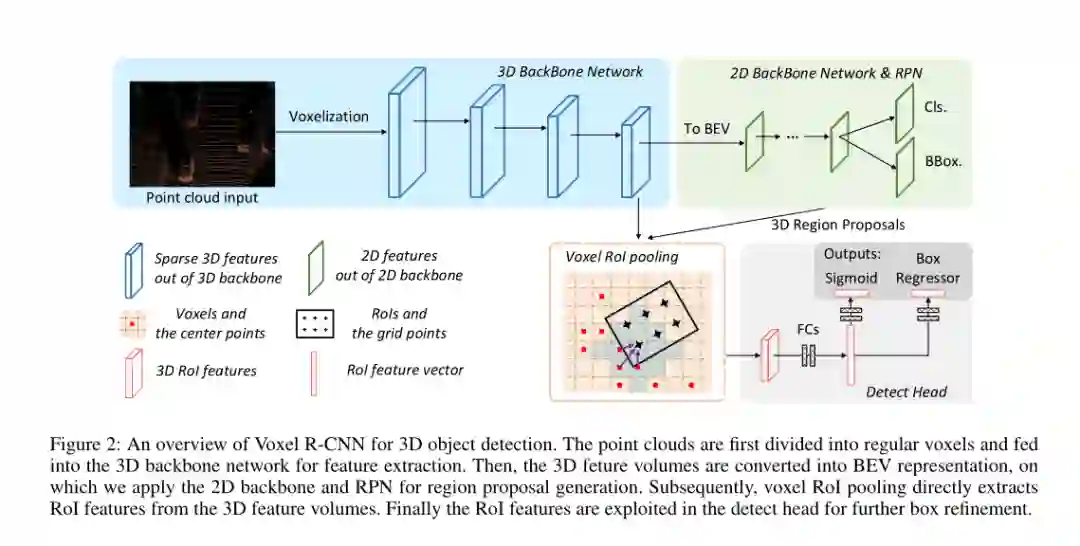
5. Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection
作者:Jiajun Deng, Shaoshuai Shi, Peiwei Li, Wengang Zhou, Yanyong Zhang, Houqiang Li
摘要:3D目标检测的最新进展在很大程度上取决于如何表示3D数据,即,基于体素(voxel-based)或基于点的表示。许多现有的高性能3D检测器都是基于点的,因为这种结构可以更好地保留精确的点位置。但是,由于无序存储,点级特征能会导致较高的计算开销。相反,基于voxel的结构更适合特征提取,但由于输入数据被划分为网格,因此通常产生较低的精度。在本文中,我们采取了略有不同的观点-我们发现原始点的精确定位对于高性能3D目标检测不是必需的,并且粗体素粒度还可以提供足够的检测精度。牢记这一观点,我们设计了一个简单但有效的基于voxel的框架,名为Voxel R-CNN。通过在两阶段方法中充分利用体素特征,我们的方法可与基于点的最新模型实现可比的检测精度,但计算成本却很小。Voxel R-CNN由3D骨干网络,2D鸟瞰(bird-eye-view, BEV)候选区域网络和检测头组成。设计了体素RoI池以直接从体素特征中提取RoI特征,以进行进一步优化。在广泛使用的KITTI数据集和最新的Waymo Open数据集上进行了广泛的实验。我们的结果表明,与现有的基于体素的方法相比,Voxel R-CNN在保持实时帧处理速率的同时,在NVIDIA RTX 2080 Ti GPU上以25 FPS的速度提供了更高的检测精度。该代码将很快发布。
网址:
https://www.zhuanzhi.ai/paper/eae904416c5a74a5e0eba4225e7a9385
请关注专知公众号(点击上方蓝色专知关注)
后台回复“AAAI20213DOL” 就可以获取《5篇顶会AAAI 2021 3D视觉目标学习(3D Object Learning)相关论文》的PDF下载链接~





