谷歌大脑开源「数据增强」新方法:RandAugment,在ImageNet准确率达85%
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

十三 发自 凹非寺
本文转载自:量子位(QbitAI)
你的数据还不够强。
玩深度学习的人都知道,AI算法大部分是数据驱动。数据的质量一定程度上决定了模型的好坏。
这就有了深度学习天生的一个短板:数据不够多、不够好。
而数据增强就是解决这一问题的有效办法。
谷歌大脑去年提出了自动数据增强方法(AutoAugment),确实对图像分类和目标检测等任务带来了益处。
但缺点也是明显的:
1、大规模采用这样的方法会增加训练复杂性、加大计算成本;
2、无法根据模型或数据集大小调整正则化强度。
于是乎,谷歌大脑团队又提出了一种数据增强的方法——RandAugment。

这个方法有多好?

谷歌大脑高级研究科学家Barret Zoph表示:
RandAugment是一种新的数据增强方法,比AutoAugment简单又好用。
主要思想是随机选择变换,调整它们的大小。
最后的实验结果表明:
1、在ImageNet数据集上,实现了85.0%的准确率,比以前的水平提高了0.6%,比基线增强了1.0%。
2、在目标检测方面,RandAugment能比基线增强方法提高1.0-1.3%。
值得一提的是,这项研究的通讯作者是谷歌AutoML幕后英雄的Quoc Viet Le大神。

△Quoc Viet Le
这么好的技术当然开源了代码:
https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/autoaugment.py
RandAugment是怎么做到的?
正如刚才说到的,单独搜索是问题的关键点。
所以研究人员的目标就是消除数据增强过程中对单独搜索的需求。
再考虑到以往数据增强方法都包含30多个参数,团队也将关注点转移到了如何大幅减少数据增强的参数空间。
为了减少参数空间的同时保持数据(图像)的多样性,研究人员用无参数过程替代了学习的策略和概率。
这些策略和概率适用于每次变换(transformation),该过程始终选择均匀概率为1/k的变换。
也就是说,给定训练图像的N个变换,RandAugment就能表示KN个潜在策略。
最后,需要考虑到的一组参数是每个增强失真(augmentation distortion)的大小。
研究人员采用线性标度来表示每个转换的强度。简单来说,就是每次变换都在0到10的整数范围内,其中,10表示给定变换的最大范围。
为了进一步缩小参数空间,团队观察到每个转换的学习幅度(learned magnitude)在训练期间遵循类似的表:
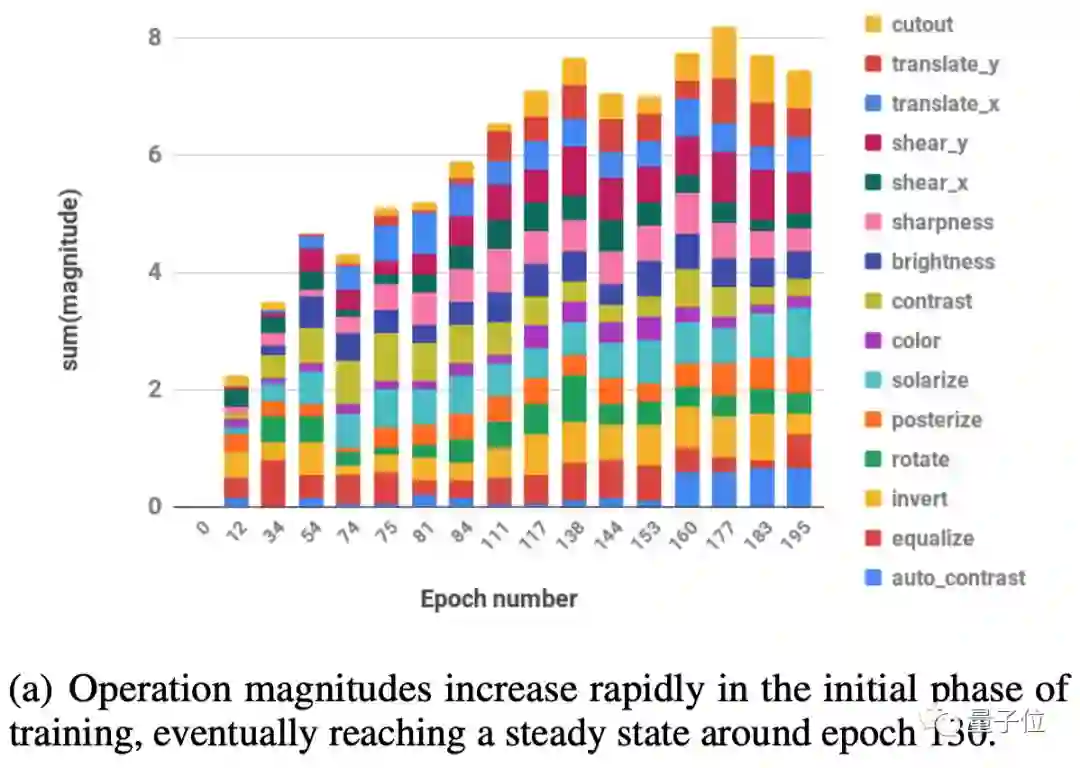
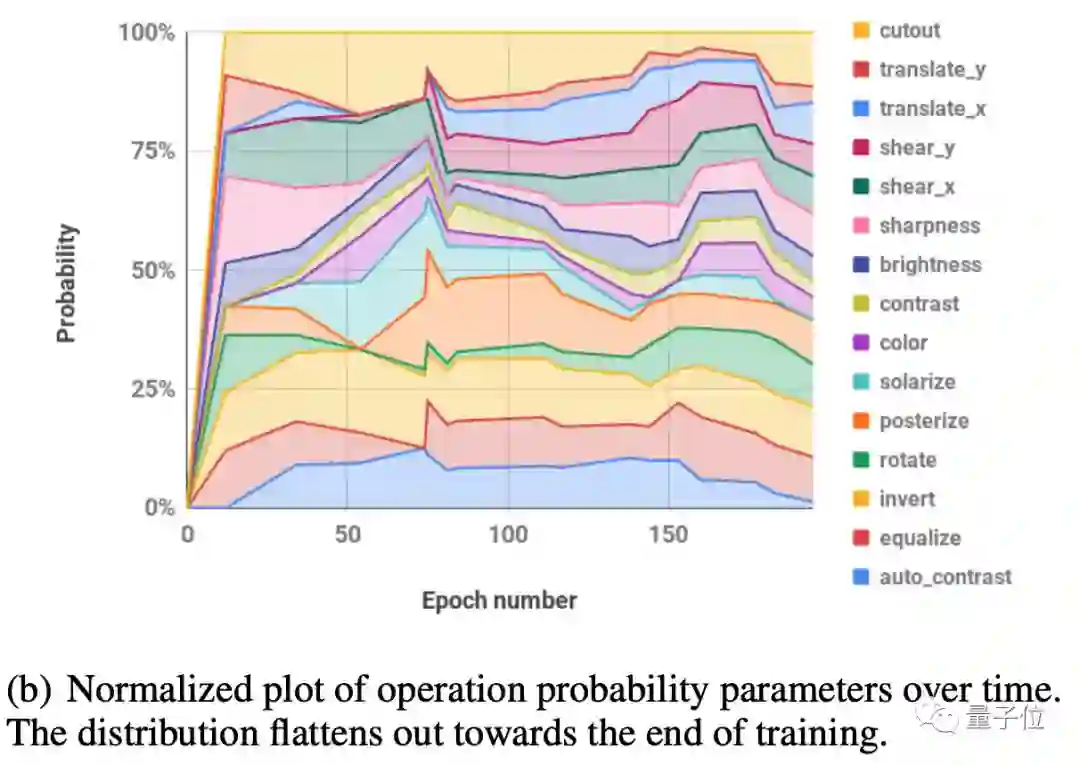
并假设一个单一的全局失真M(global distortion M)可能就足以对所有转换进行参数化。
这样,生成的算法便包含两个参数N和M,还可以用两行Python代码简单表示:

△基于numpy的RandAugment Python代码
因为这两个参数都是可人为解释的,所以N和M的值越大,正则化强度就越大。
可以使用标准方法高效地进行超参数优化,但是考虑到极小的搜索空间,研究人员发现朴素网格搜索(naive grid search)是非常有效的。
实验结果
在实验部分,主要围绕图像分类和目标检测展开。
研究人员较为关注的数据集包括:CIFAR-10、CIFAR-100、SVHN、ImageNet以及COCO。
这样就可以与之前的工作做比较,证明RandAugment在数据增强方面的优势。
数据增强的一个前提是构建一个小的代理任务(proxy task),这个任务可以反映一个较大的任务。
研究人员挑战了这样一个假设:
用小型proxy task来描述问题适合于学习数据的增强。
特别地,从两个独立的维度来探讨这个问题,这两个维度通常被限制为实现小型proxy task:模型大小和数据集大小。
为了探究这一假设,研究人员系统地测量了数据增强策略对CIFAR-10的影响。结果如下图所示:
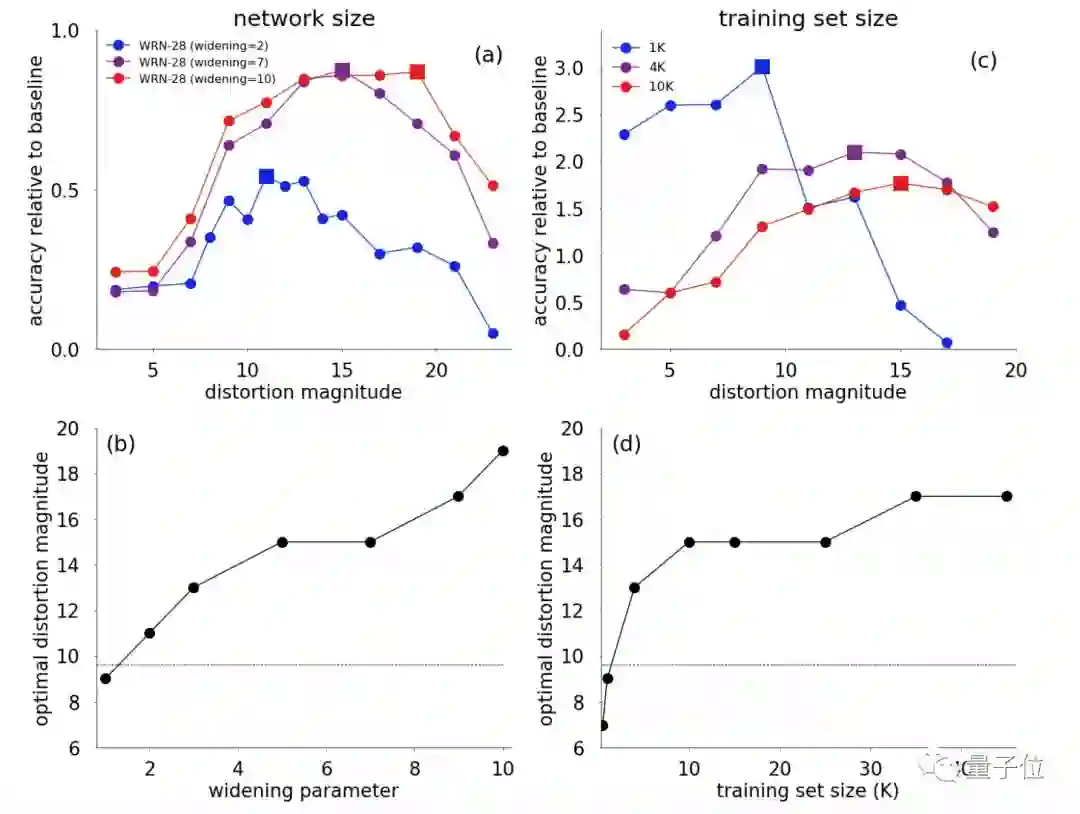
△最优增强量取决于模型和训练集的大小。
其中:
图(a)表示Wide-ResNet-28-2,Wide-ResNet-28-7和Wide-ResNet-28-10在各种失真幅度(distortion magnitude)下的精度。
图(b)表示在7种Wide-ResNet-28架构中,随着变宽参数(k)的变化,所产生的最佳失真幅度。
图(c)表示Wide-ResNet-28-10的三种训练集大小(1K,4K和10K)在各种失真幅度上的准确性。
图(d)在8个训练集大小上的最佳失真幅度。
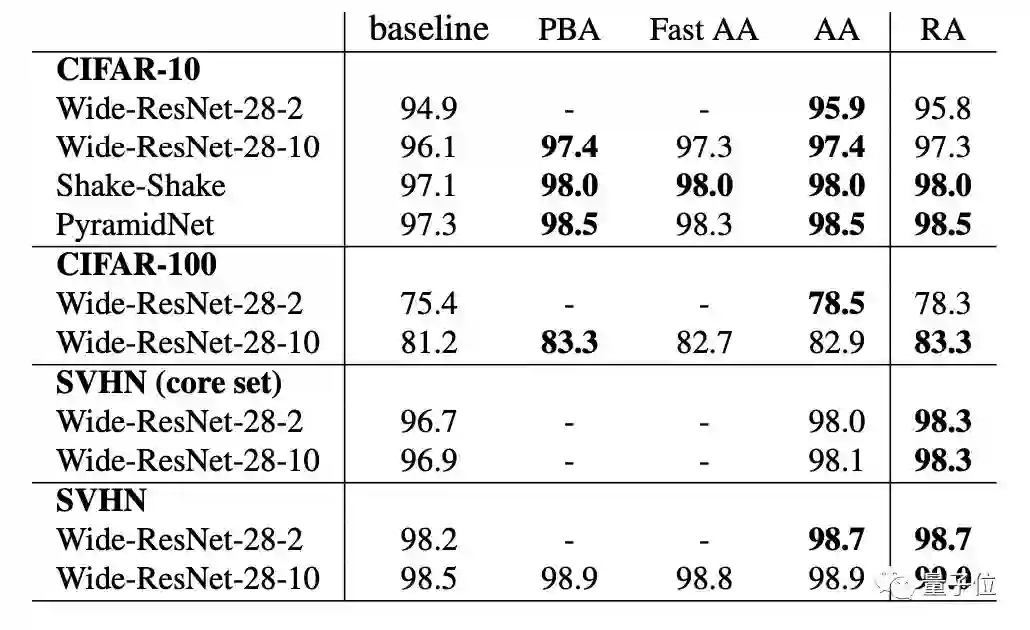
△在CIFAR-10、CIFAR-100、SVHN(core set)和SVHN上的测试精度(%)。
其中,baseline是默认的数据增强方法。
PBA:Population Based Augmentation;
Fast AA:Fast AutoAugment;
AA:AutoAugment;
RA:RandAugment。
但值得注意点的是,改进CIFAR-10和SVHN模型的数据增强方法并不总是适用于ImageNet等大规模任务。
同样地,AutoAugment在ImageNet上的性能提升也不如其他任务。
下表比较了在ImageNet上RandAugment和其他增强方法的性能。

△ImageNet结果。
在最小的模型(ResNet-50)上,RandAugment的性能与AutoAugment和Fast AutoAugment相似,但在较大的模型上,RandAugment的性能显著优于其他方法,比基线提高了1.3%。
为了进一步测试这种方法的通用性,研究人接下来在COCO数据集上进行了大规模目标检测的相关任务。
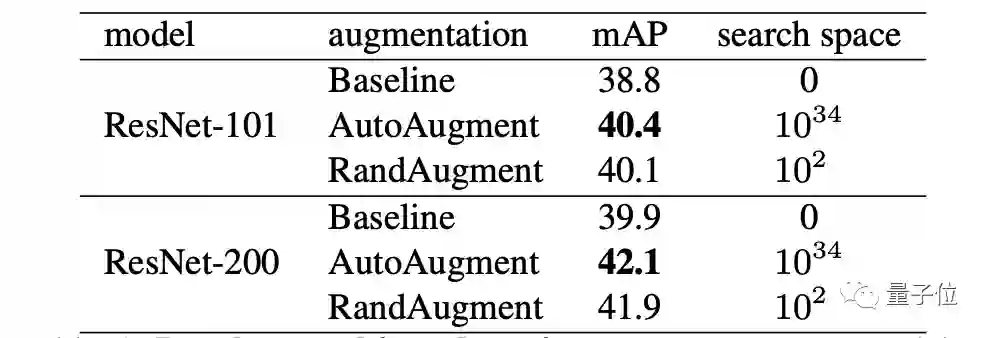
△目标检测结果。
COCO目标检测任务的平均精度均值(Mean average precision,mAP)。数值越高,结果越好。
下一步工作
我们知道数据增强可以提高预测性能,例如图像分割,3-D感知,语音识别或音频识别。
研究人员表示,未来的工作将研究这种方法将如何应用于其他机器学习领域。
特别是希望更好地了解数据集或任务是否/何时可能需要单独的搜索阶段才能获得最佳性能。
最后,研究人员还抛出了一个悬而未决的问题:
如何针对给定的任务定制一组转换,进一步提高给定模型的预测性能。
对此,你又什么想法?
传送门
论文地址:
https://arxiv.org/pdf/1909.13719.pdf
GitHub地址:
https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/autoaugment.py
作者系网易新闻·网易号“各有态度”签约作者
重磅!CVer学术交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


