学界 | 超越过去三年冠军,AAMAS2019 桥牌游戏论文揭秘

游戏的研究在 AI 发展历史上起到了非常重要的作用
AI 科技评论按,近年来,AI 在博弈游戏中的研究成为研究者们关注的热点之一。2017 年,AlphaGo 成功击败人类最高围棋水平的代表柯洁,一度占据各大媒体的头条。之后,AlphaGo 不断进化,AlphaZero 轻松击败国际象棋和日本将棋并击败业内远超人类冠军水平的顶尖计算机程序。今年,OpenAI Five 击败 DOTA2 世界冠军 OG 团队。
而在今年 AAMAS 2019 的 140 篇入选论文中,我们注意到,其中有一篇关于不完全信息博弈游戏——桥牌游戏的论文——《Competitive Bridge Bidding with Deep Neural Networks》。该论文的作者是中科院计算所博士生荣江(现在阿里巴巴工作)、微软亚洲研究院资深研究员秦涛博士、新加坡南洋理工大学计算机科学与工程学院安波博士。
论文主要研究了在桥牌游戏中,基于神经网络构建叫牌系统的方法。
论文下载地址:https://arxiv.org/abs/1903.00900v2
论文的摘要如下:
AI 科技评论将摘要翻译如下:
桥牌游戏分为叫牌和打牌两个阶段。对计算机程序来说,虽然打牌相对容易,但叫牌是非常具有挑战性的。在叫牌阶段,每个玩家只知道自己牌,但同时,他需要在对手的干扰下与搭档交换信息。现有的解决完全信息博弈的方法不能直接应用于叫牌中。大多数桥牌程序都是基于人工设计的规则,但是,这些规则并不能覆盖所有的情况,而且,它们通常模棱两可甚至相互矛盾。本文首次提出了一种基于深度学习技术的叫牌系统,在文中,我们展示了两个创新点。首先,我们设计了一个紧凑的表示,对私人和公共信息进行编码,供玩家投标。第二,在分析其他玩家的未知牌对最终结果的影响的基础上,设计了两个神经网络来处理不完全信息,第一个神经网络推断出搭档的牌,第二个神经网络将第一个神经网络的输出作为其输入的一部分来选择叫牌。实验结果表明,我们的叫牌系统优于基于规则的最优方案。
桥牌游戏的研究背景是什么?有哪些难点?其现实意义是什么?本次论文的工作,用了哪些方法,遇到了什么困难?带着这些问题,雷锋网 AI 科技评论采访了论文的作者。以下是这次采访的主要内容。
问答记录:
AI 科技评论:你们着手桥牌游戏研究有多久了?训练数据源是什么?为什么会研究桥牌而不是德扑?这两个游戏都是不完全信息博弈,它们的异同点在哪里,研究的侧重点有区别吗?
答:我们是 2016 年开始研究桥牌的,一直到 2018 年,历时一年多,文章于 2019 年发表在 AAMAS 上。
我们的数据包括两部分,用于监督学习的专家数据和用于强化学习的随机数据。其中专家数据来自 Vugraph Project(http://www.bridgebase.com/vugraph_archives/vugraph_archives.php),该项目记录了世界各种高水平桥牌比赛的完整过程,经过处理以后共得到 1200 万条专家数据。用于强化学习 self-play 的数据是随机生成的,我们用了 100 万局比赛。
实习的时候有同事懂桥牌,我们觉得有意思就开始研究桥牌了。桥牌和德扑共同点是,它们都是不完全信息博弈。它们的不同点有两个,第一点是桥牌有四个人,已有的算法很难保证像二人德扑那样找到纳什均衡,第二点是,桥牌涉及到队友间的协作。
相比于德扑,桥牌的难度更大、更具有挑战性。虽然它们都是不完全信息博弈,但已经发表的德扑算法(如 CFR 算法)仅对二人德扑有理论保证,无法拓展到多人。而桥牌是四人博弈,因此会更难一些。此外,桥牌不仅涉及到对手间的对抗,还涉及到队友间的合作,比德扑更复杂。
之所以选择桥牌,是因为现实中大部分环境是既充满合作也充满竞争的,如果我们能做好桥牌这种非完全信息游戏,那么我们就能对很多实际生活中遇到的问题进行建模了。比如,这项研究成果可以用在处理国家和国家之间的关系上,任何国家和国家之间关系都不是两个国家之间的关系,我们要考虑到多方的关系,而这些国家之间既存在竞争也可能同时存在合作。其中会涉及到很多私有信息,这些信息都是未公开的,为非完全信息,这就和桥牌游戏是类似的。我们觉得,这项工作是比较接近现实的抽象,通过这项研究,我们可以发掘相关算和积累相关技术,便于日后落地到实际应用。
AI 科技评论:你们的文章中提到,桥牌游戏的难点有两个,一是进行决策时需要考虑的状态空间很大,二是来自对手的挑战,你们是如何应对这些难点的?
答:第一,我们用了一个紧凑的向量来表征状态(如下图所示),从而降低模型输入的维度。此外,由于每个玩家只能看到自己的 13 张牌,其余 39 张都是未知的,这导致不完全信息的信息集很大,我们通过预测队友的牌来缩小信息集,从而降低结果的不确定性。
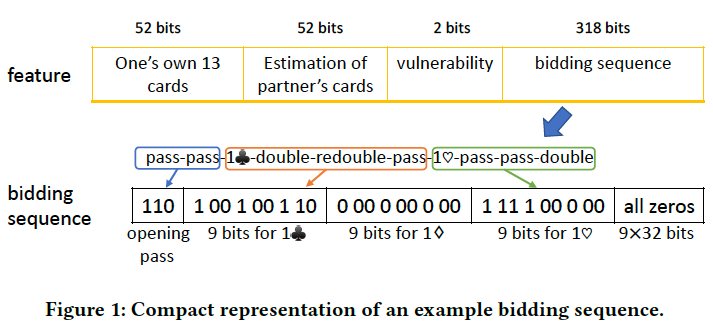
第二,我们首先通过监督学习来较好地初始化智能体,然后通过强化学习算法让我们的智能体不停地 self-play,这个过程中同一个团队的 2 个智能体会通过不断修正对队友牌面的预测准确性来保持信息交换和协作,同时与自己的历史版本对抗,在不断的学习中提升自己的胜率。
AI 科技评论:你们的成果超越了过去三年的冠军,和他们相比,你们的优势和创新点在哪里?
答:桥牌分两个阶段,叫牌(bidding)和打牌(playing)。我们目前的工作只是在叫牌阶段超越了当前版本的 Wbridge5,当然,Wbridge5 也在不断优化中。我们的优势在于用神经网络构建叫牌系统,这样能够通过监督和强化学习让该系统不停地探索和优化自己的策略,而 Wbridge5 是基于规则的,他们通过消除已有规则中的歧义和冲突来优化自己的系统,这样就会有一定的局限性,把系统的性能的上限局限在了人类已有的知识中。
AI 科技评论:你们的工作是如何分工的?在研究的过程中,选取了哪些特征,尝试过哪些机器学习算法?未来会在哪些方面进行改进和提升?
答:荣江主要负责具体实现工作,秦涛老师和安波老师参与方案的讨论并指导荣江工作。
我们用到的特征包括完全信息和不完全信息两部分,其中完全信息包括自己的牌、局况(vulnerability)、叫牌序列(bidding history),不完全信息包括对队友牌的预测。
研究过程中,我们尝试过 DQN 算法,但由于不完全信息带来的不确定性,DQN 算法的方差很大。另外,我们还试过 boosting tree 算法,这种算法的好处是有很好的模型可解释性,但算法的性能并没有基于 policy 的强化学习算法好。此外,我们还尝试过单纯用强化学习算法,但是算法不收敛,这跟完全信息类型的博弈(如围棋)有很大差别。
未来,我们会尝试加入带有 reward shaping 功能的 value-network,用于位叫牌过程的每一步中间结果生成一个单独的即时收益,而不是等到叫牌结束后给所有中间过程一个相同的收益,这可能会有让策略更新的方向更加精准。此外,我们还会尝试加入 attention 模块(如 Transformer),对叫牌序列做权重处理,让智能体能捕捉到更加关键的信息,从而得到更好的策略。
AI 科技评论:这项工作成果的应用前景如何?可以用在工业上吗?
答:我们的算法说明「策略网络+预测网络」这种组合是有效的,这个思路可以用在很多地方,比如商业推荐系统。我们正在尝试用一个预测网络来预测用户的兴趣,然后通过一个打分网络来对用户感兴趣的商品进行排序。
AI 科技评论:目前,桥牌游戏研究在国内外的研究现状如何,这项研究未来的方向是什么?
答:目前,做棋牌类游戏研究的人非常多。目前,科学家们已经攻破了围棋这种完全信息的游戏,因此我们着手研究桥牌这种非完全信息游戏。目前,这些游戏在国外的研究相对于国内来说要多一些。
目前几乎所有的桥牌软件(如 GIB,Wbridge5,Jack 等)都是基于规则的。虽然深度学习已经在很多完全信息类博弈中取得了显著的效果(如 AlphaGo),但目前桥牌领域使用的还很少。ECAI16 发表了一篇基于神经网络和强化学习的桥牌算法,但该算法不考虑竞争,即假设对手一直出「pass」。我们的论文应该是第一篇用深度学习算法来求解桥牌叫牌游戏的文章。今后应该会出现更多基于神经网络和深度学习的桥牌算法。
AI 科技评论:您对游戏类的研究有什么看法?这种研究有什么实际意义吗?
答:科学研究始终要走在工业应用的前面,要有前瞻性。从 AI 的发展历史来看,很多精妙的算法和理论都是从研究游戏开始的,学者们在研究的过程中能积累大量的知识和技术,最后用于实际应用,如博弈论的研究可从最简单的囚徒困境游戏开始,强化学习算法也基本上是基于游戏(如 Atari Games)来不断发展的。
现实应用往往过于复杂,而游戏的规则明确,易于建模,为科学研究提供了很好的对象,从游戏研究入手来探索新的理论和技术然后拓展到实际是一个自然的过程。
虽然,这些工作未来具体会用在哪里我们并不知道,但是在 AI 的发展历史上,游戏起到非常重要的作用,它是一项比较偏基础性的研究,短期内也很难看它的应用,但是,这些研究能够推动整个领域的发展。因此,研究游戏的解法是很有意义的。
附:论文作者简介
荣江

荣江,于 2019 年在中国科学院计算技术研究所获得计算机科学博士学位,主要研究领域包括机器学习、强化学习、博弈论、多智能体系统等,在相关国际会议(AAAI、AAMAS 等)发表过多篇论文,现任阿里巴巴高级算法工程师。
秦涛

秦涛博士,微软亚洲研究院资深研究员,研究重点是深度学习和强化学习的算法设计、理论分析及在实际问题中的应用,在国际会议和期刊上发表学术论文 100 余篇,曾/现任机器学习及人工智能方向多个国际大会领域主席,曾任多个国际学术研讨会联合主席。秦涛博士是中国科学技术大学兼职博士生导师,IEEE、ACM 高级会员。他的团队获得国际机器翻译大赛(WMT2019)8 项第一。
安波

安波,南洋理工大学校长委员会讲席副教授,于 2011 年在美国麻省大学 Amherst 分校获计算机科学博士学位。主要研究领域包括人工智能、多智能体系统、算法博弈论、强化学习、及优化。曾获 2010 年国际智能体及多智能体系统协会 (IFAAMAS) 杰出博士论文奖、 2011 年美国海岸警卫队的卓越运营奖、2012 年国际智能体及多智能体系统年会 (AAMAS) 最佳应用论文奖、2016 年人工智能创新应用会议 (IAAI) 创新应用论文奖,2012 年美国运筹学和管理学研究协会 (INFORMS)Daniel H. Wagner 杰出运筹学应用奖,以及 2018 年南洋青年研究奖等荣誉。受邀在 2017 年国际人工智能联合会议 (IJCAI) 上做 Early Career Spotlight talk。获得 2017 年微软合作 AI 挑战赛的冠军。入选 2018 年度 IEEE Intelligent Systems 的「人工智能 10 大新星」(AI s 10 to Watch)。当选为国际智能体及多智能体系统协会理事会成员和 AAAI 高级会员。
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。






