马维英:AI Lab是公司最能冒险的部门,五大AI战略资源是钥匙

新智元原创
新智元原创
编辑:三石
【新智元导读】AI Lab在一个公司应当是什么样的角色?字节跳动副总裁、人工智能实验室主任马维英表示:AI Lab不仅是公司内部的AI研究所,也是AI技术提供商与服务商,应当注重与高校和政府的合作,并强调人才培养的重要性。
AI Lab应当是公司的“厂牌”。
字节跳动实现建设全球创作与交流平台的愿景,以及取得当前全球化进展,都离不开人工智能技术提供的关键支撑。字节跳动一向重视人工智能技术的发展,而其AI Lab,最开始是因NLP领域科学家李磊的加入而出名,随后马维英、李航等大佬也陆续入伙。
与此同时,今日头条母公司字节跳动,推出抖音、火山小视频等一些列风靡全球的产品,估值上升、用户增长。
而这一切背后提供支撑的人工智能实验室却鲜少露面,这一年来字节跳动的AI Lab究竟都做了什么呢?作为亚研院前常务副院长的马维英,所带队的字节跳动AI Lab又有何不同呢?
11月11日,字节跳动举办了2018 AI OPENDAY沙龙。活动展示了字节跳动AI Lab在计算机视觉、自然语言处理、语音和视频处理、机器学习等领域中取得的一些列成果。
而后字节跳动副总裁、人工智能实验室主任马维英,针对此次沙龙活动做了主题演讲,慢慢揭开了字节跳动AI Lab神秘的面纱。
相似于人才培养:给予自由,让兴趣成为自驱的动力
马维英表示,之前在微软亚洲研究院时特别欣赏其培养人才的一个方式,就是当新人刚入职时,不会立刻让他们选择具体研究方向,而是会给予他们足够多的自由和空间,激励他们寻求自己最为感兴趣的一个领域。
在这个方面,字节跳动也是如此的。马维英很感谢微软给他的成长空间,因此到了字节跳动之后,他也在新的团队延续了这样的氛围。字节跳动AI lab特别喜欢自己有想法、能够自驱、愿意不断去学习且更加无所畏惧的研究人员;而不是害怕失败,着重于眼前利益的人。
区别于数据与场景:微软研究院专注于技术转移,字节跳动AI Lab鼓励研究员直接参与到产品研发,利用丰富的应用场景、大量的数据和用户反馈推进科研和技术创新
除了基础研究这方面,微软做的更多的是技术转移。与微软不同的是,字节跳动拥有丰富的应用场景。大量的数据和反馈对AI Lab的工作是有帮助的。就像在象牙塔里搞研究,有时反而解决不了问题。只有解决真实的应用场景问题,才是所谓的Real Impact。
正如最近一位UC Berkeley的教授所述,要做“Use Inspired”的研究。而在字节跳动,非常幸运一点就是,人类所有的数据都在信息和内容里。
再具体一点可总结为一句话:字节跳动拥有做AI最重要的五个战略资源。
大数据:最好这家公司能够拥有全世界最大的数据资源,拥有数据才是“王道”;
应用场景:在字节跳动,研究人员每天都能够从公司的应场景中找到问题,并想要去解决;
算力:而字节跳动的Internet Data Center在国内也是比较出众的;
AI需闭环:其实很多用户交互相当于递给了你一份大数据的,提供了更为细粒度的标注数据,而字节跳动每日全球活跃用户所提供的数据之海量,堪称一笔财富;
人才:最顶尖聪明的人才是非常关键的一点。不仅公司内部要有这样的人才,最好与之相关的学术界、产业界、社区都是顶级的人才。
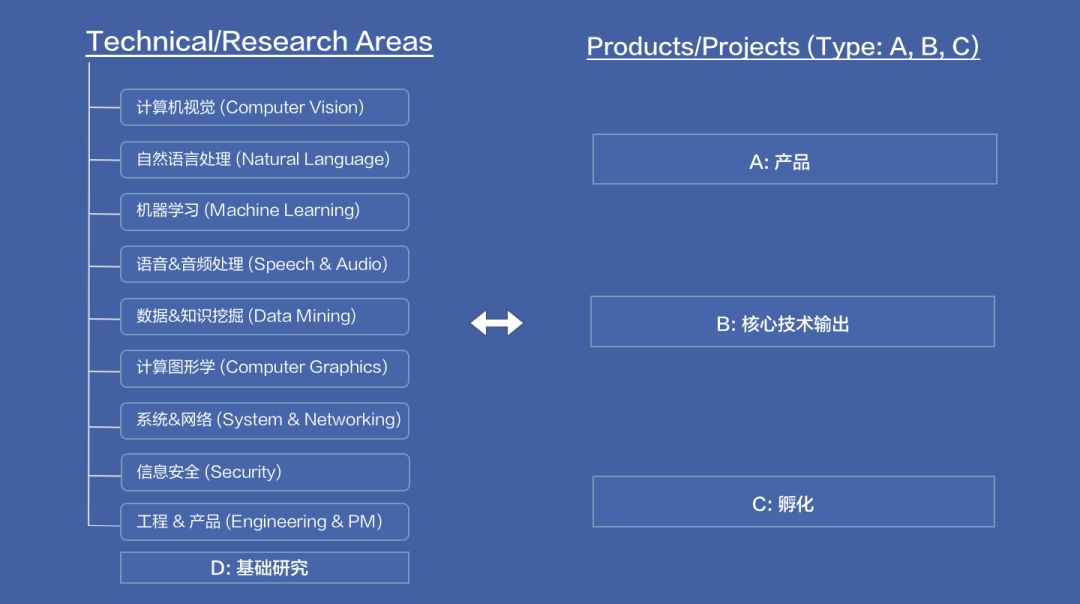
在基础研究方面,字节跳动的AI Lab研究领域包括计算机视觉、自然语言处理、机器学习、语音&音频处理、数据&知识挖掘、计算机图像学、系统&网络、信息安全以及工程&产品。
马维英表示,字节跳动会在每个领域中,都会招聘最优秀的人才,而在招聘后不会立即确定他们的方向,而是会让他们摸索自己感兴趣的方向,而后再做出选择。
除了基础研究,字节跳动AI Lab也非常重视工程落地的能力,因此也倍加关注对这方面的人才招聘。将工程团队与科研研究人员混搭在一起,做更好的创新,并输出核心技术,孵化产品,做到真正的AI应用落地。
正因如此,字节跳动吸引了一大批优秀的“新鲜血液”。例如,来自字节跳动AI Lab的一位90后研究人员,不仅论文被Transition of ACL收录,还被邀请去了墨尔本做现场演讲。
该论文中所提出的模型在中英,德英和英法三个标准数据集上可以显著地提高基线系统的性能,相比于老一辈的「覆盖率模型」拥有更好的翻译质量和对齐质量。
该研究也已成功的应用到了字节跳动旗下多款国际产品中(如TopBuzz、Tik Tok等等),为全球上亿的用户们提供着内容翻译服务。
马维英谈招聘标准——三个关键字:
马维英老师还透露了他在招聘人才时的标准,总结为三个关键字:
数学功底:能够知晓问题的本质,对模型能够有透彻的了解,而不是把它当一个黑箱或者工具,简单的调调参数;
编程能力:有很好的想法,但是无法实现也是不行的;
态度:人际沟通、表达,对工作的态度也是非常重要的。
另外,马维英老师也非常注重眼神的交流,“大概沟通十分钟,我就能看出一个人特质。”马维英老师笑言,这可能是他在招聘中独有的一种天赋。
国内外各大巨头与初创企业纷纷成立人工智能实验室,而各家企业人工智能实验室所关注与努力的侧重有所不同。
字节跳动人工智能实验室成立于2016年,依托字节跳动的海量数据,专注于人工智能领域的前沿技术研究,并将研究成果应用于字节跳动的产品中,利用人工智能帮助内容的创作、分发、互动、管理。将人工智能最早大规模应用于信息分发便是字节跳动早期发展的核心。
AI时代下的4种管道连接人和信息,促进交流和创作
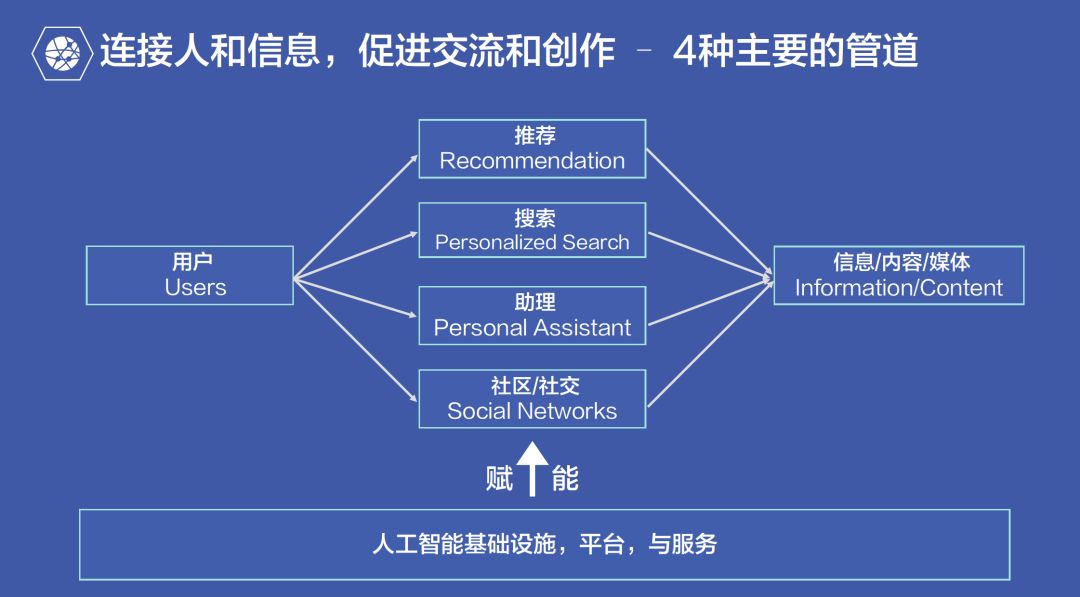
这4种主要的方式分别是推荐、搜索、助理与社区/社交。推荐和助理都属于比较被动的方式,会根据用户的所好进行内容的分发;搜索在今天也仍然重要,它是一种主动获取行为;新一代的语音助理能够让用户更加自然地与计算机进行交互,从而达到帮助用户的目的;最后,类似转发“朋友圈”这种社交式的信息传播也是非常重要的。
新一代AI驱动信息平台,使得交流与创作方式更加智能
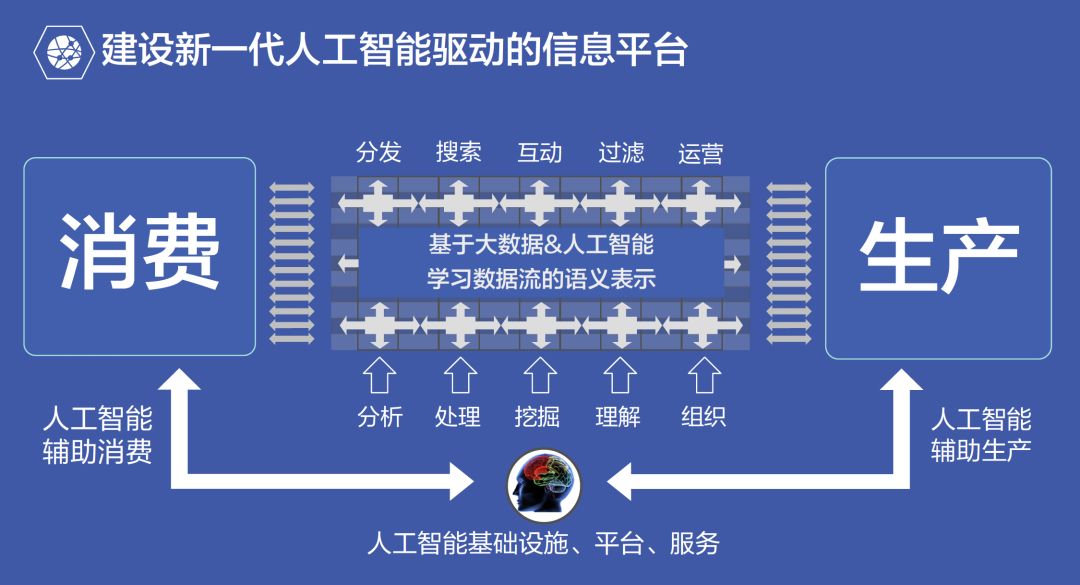
人工智能基础设施、平台与服务,基于大数据、人工智能学习数据流的语义表示,对信息进行分析、处理、挖掘、理解和组织,使得内容能够在分发、搜索、互动、过滤和运营方面变得更加智能,做到人工智能辅助消费与生产。
所以,人工智能实验室所肩负的使命是艰巨而又重要的。
AI Lab赋能产品、服务人类
短视频已然成为一个内容形态的爆发点。特别是计算机视觉、智能语音赋予了每位用户更强的创作能力。
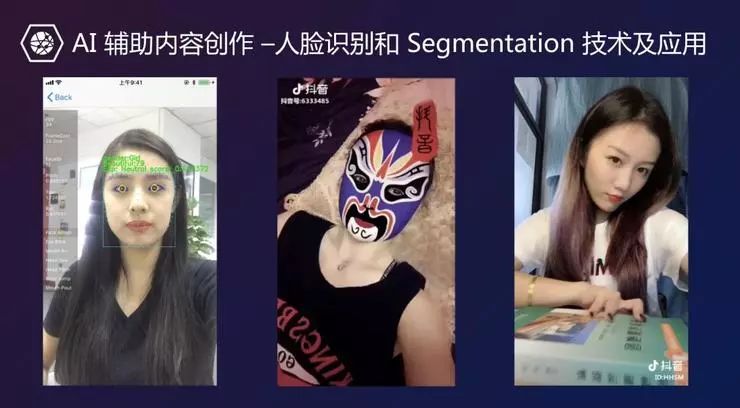
抖音是字节跳动风靡全球的产品。这个产品背后有非常多的 AI 技术。比如,抖音是一个开放共享的平台,内容审核方面的挑战是非常大的。字节跳动一直用人工智能辅助审核,过滤理解这些视频内容,进行版权识别。
目前平台上,每天有庞大数量的短视频内容被创作出来。而机器学习模型上线之后,也在持续不断迭代完善。
在视频内容领域也希望能够做出更好的搜索。视频的搜索需要对视频的内容有更好的理解,包括动作的理解、物体的检测跟踪,还有视频里的环境识别。也希望针对每一个视频,AI都能理解它的情感和情绪。
连接人跟信息是一个人类社会的基础设施。在这个设施的运作过程中,能够利用大数据、丰富应用的场景、大量的活跃用户,去不断完善和迭代,进一步赋能。而技术的进步最终是服务于人类的。

截至2018年10月24日,头条寻人共弹窗52824寻人启事,找到7401
字节跳动将人工智能结合产品功能积极服务于公益,两年半时间成功寻回7254名走失者的“头条寻人”,这是一个典型的运用人工智能促进信息效率,进而服务公益的产品机制:结合智能推荐和地理推送技术,以走失者走失地为圆心,根据走失者行走速度等信息进行数据分析和计算,预估出可能的走失范围,在此范围内推送寻人信息,实现每条寻人信息的精准地理范围覆盖和人群触达,从而大大提高寻人成功率。
9月底上线、目前已成功寻回30名走失者的“抖音寻人”和“头条寻人”工作原理一致,只是推送的寻人信息变成了短视频形式,运用自动生成视频技术,一条文字版的寻人信息,不到10秒钟,即可自动生成为一条抖音寻人视频。
马维英对字节跳动AI Lab的定义为:公司内部的AI技术提供商和服务商,于未来将成为公司对外输出AI能力的重要部门。
一个人工智能实验室的成功,少不了顶尖“智脑”的相聚与思想的碰撞。而字节跳动AI Lab可谓是群贤毕至,包括大家熟知的马维英、李航、李磊等。
除了拥有大量优秀的科学领军人物之外,2018年字节跳动AI Lab团队建设和成长方面也是收获颇丰。AI Lab团队总人数由去年的65人增长至150人,计算机视觉、自然语言、机器学习、系统&网络的团队人数比去年增加一倍之多,而语音&音频、安全以及美国AI Lab的团队人数更是飞速增长。
不仅在团队建设,字节跳动AI Lab在学术和项目成果方面也可谓是硕果累累。
11月11日,在字节跳动举办的2018 AI OPENDAY沙龙活动中,展出了AI Lab许多优秀的项目与研究。
Deep Understanding of Live Soccer Matches
已被CVPR 2018接收
项目介绍:基于计算机视觉技术,系统可以对足球比赛视频进行深度理解和信息挖掘,丰富球迷的观赛体验。该系统在2018世界杯期间介入今日头条客户端直播间,实时提供精彩时刻剪辑动画、双方进攻防守统计、足球运动热力图等多种信息;并于赛后为自动写作机器人Xiaoming Bot提供图像素材,丰富文章内容。
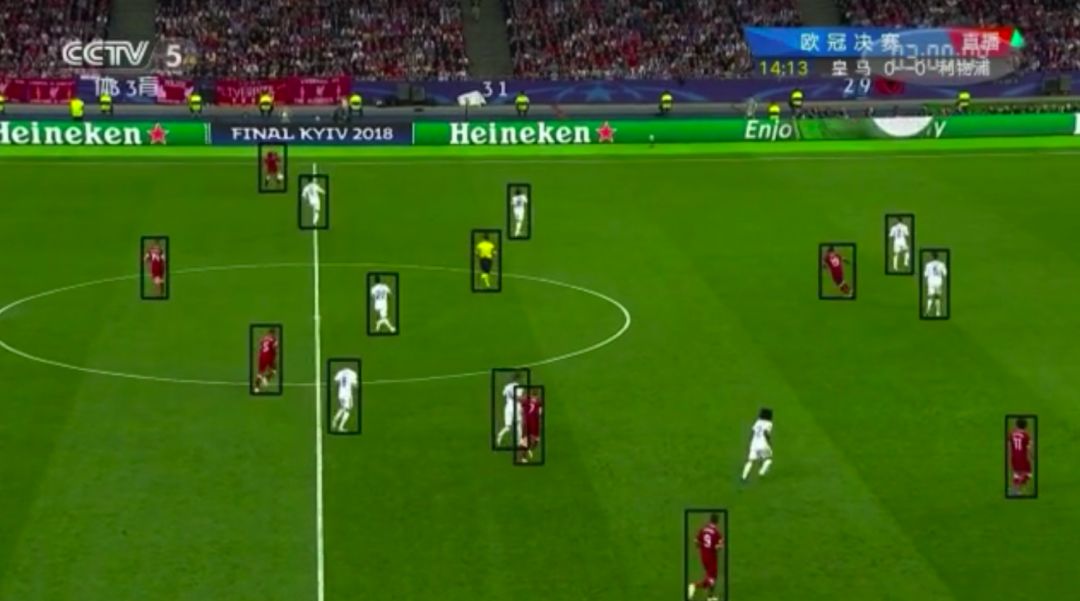
目标检测

轨迹跟踪

生成鸟瞰视角

捕捉精彩瞬间
相关技术:
检测&语义分割:基于SSD的目标检测,逐帧输出球员和足球的位置;基于DeepSORT的多目标跟踪,使用Kalman Filter对球员和足球的运动进行建模使用度量学习对球员外观建模。
相机估计&语义分割:检测球场上的关键点,计算单应性变换参数,以此来估计相机的拍摄角度。
号码识别&球员聚类:使用半监督的空间变换网络(STN)在检测框内提取号码区域进行识别。
精彩时刻检测:对固定划窗内的片段进行分类,包含射门、任意球、角球、受伤等多种类别。
统计分析:基于上述多种结构化信息,输出多种统计指标,包括双方控球率、足球运动热力图及控球区域分布等。
相比于人类作者,小明的效率和产量高,2秒就能成稿,每场比赛赛后发稿,2年内生成12万粉丝和10亿阅读。过去头条平台上许多体育播报是由小明写的,他每天读很多内容,综合网上文字描述理解和图片例子和视频理解能够自动生成一个内容,分发给对某一类信息感兴趣的读者。
xiaomingbot写作机器人也因此获得了吴文俊人工智能科学技术奖。
BRITS:BidirectionalRecurrent Imputation for Time Series
NIPS 2018
项目介绍:
时间序列在许多分类、回归任务中被广泛用作信号。时间序列中存在许多缺失值,这是普遍存在的。给定多个相关时间序列数据时,该如何填补缺失值并预测其类标签呢?现有的归一化方法往往对潜在的数据生成过程有很强的假设,比如状态空间中的线性动力学。
本文提出了一种新的基于递归神经网络的时间序列数据缺失值估计方法,BRITS算法。该方法直接学习双向递归动力系统的缺失值,没有任何具体的假设。将赋值作为RNN图的变量,在反向传播过程中可以有效地进行更新。
算法优势:
(a) 可以处理时间序列中多个相关缺失值;
(b) 推广到具有非线性动力学的时间序列;
(c) 提供数据驱动的估算程序,适用于缺少数据的一般设置。
实验结果:
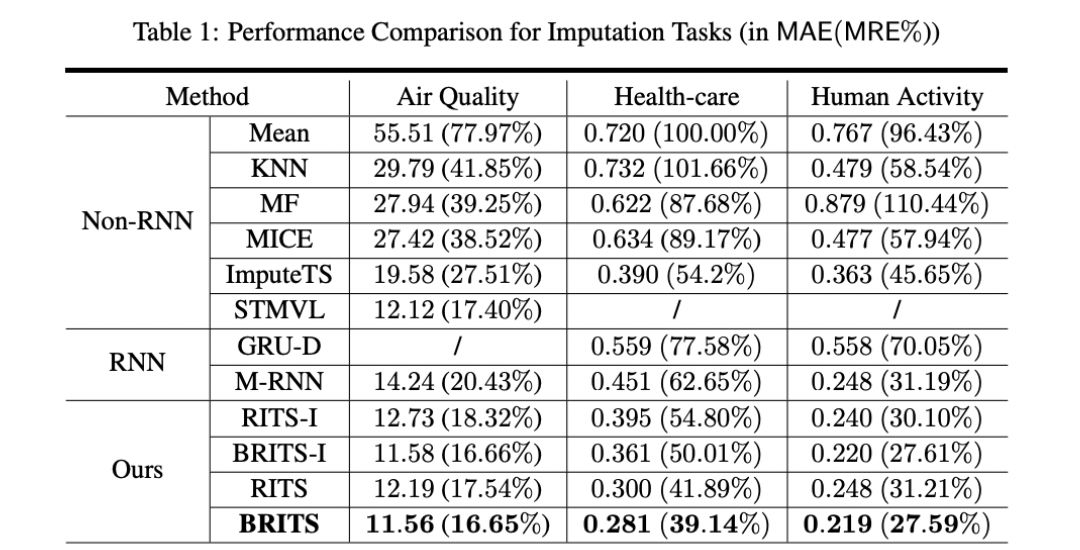
在三个真实世界数据集上评估BRITS模型,包括空气质量数据集,医疗保健数据和人类活动的本地化数据。实验表明,该模型在插补和分类/回归精度方面都优于最先进的方法。
Reinforced Co-Training
NAACL 2018
项目介绍:
Co-Training是一种流行的半监督学习框架,除了少量标记数据外,使用大量的未标记数据。Co-Training方法利用未标记数据上的预测标签,并基于预测置信度选择样本来进行增强训练。
然而,在现有的协同训练方法中,样本的选择是基于一种预先确定的策略,这种策略忽略了未标记子集和标记子集之间的抽样偏差,并且无法挖掘数据空间。
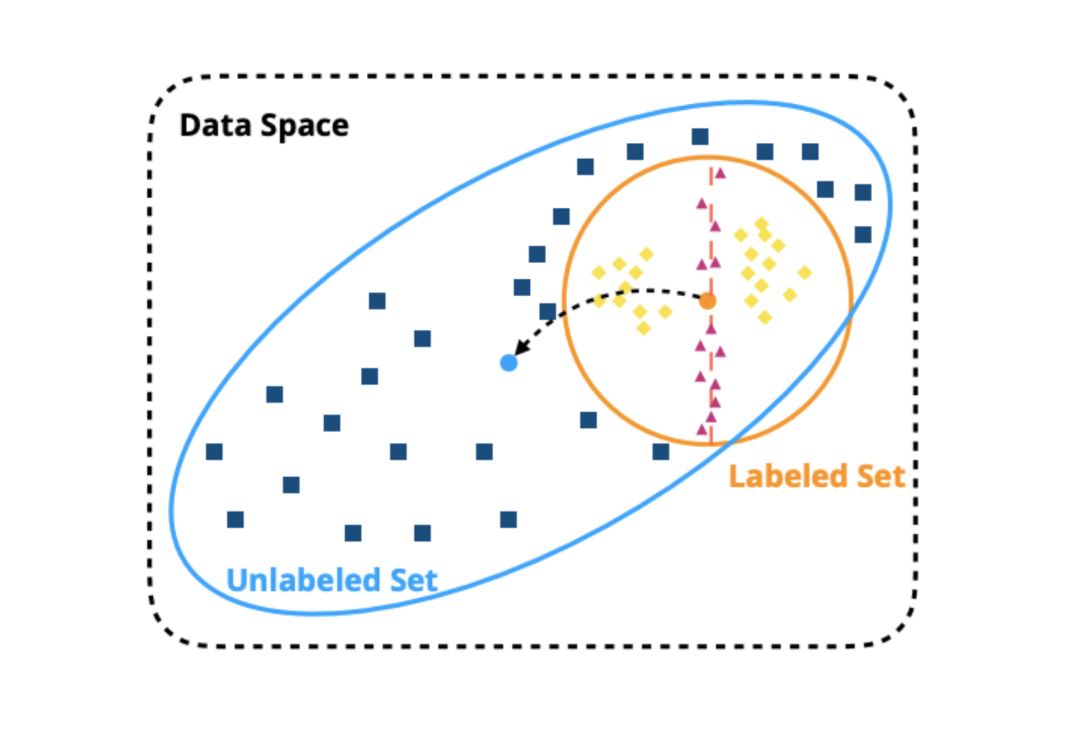
本文提出了一种新的方法——强化Co-Training,来选择高质量的未标记样本,以便更好地进行Co-Training。更具体地说,该方法使用Q-learning学习一个带有小标记数据集的数据选择策略,然后利用这个策略自动训练联合训练分类器。
实验结果:
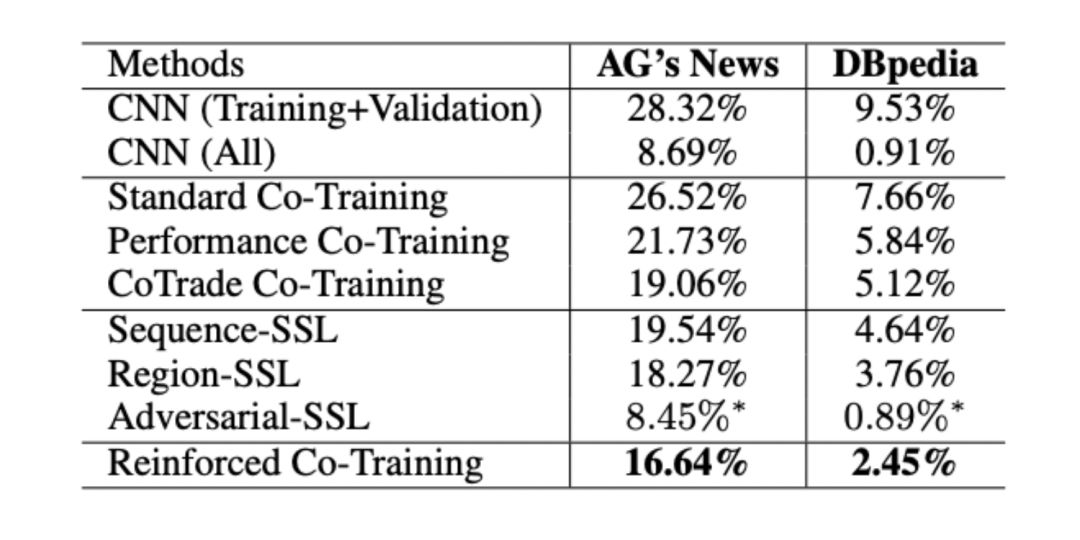
实验结果表明,本文提出的方法能够获得更准确的文本分类结果。
AI Lab与高校合作
珠穆朗玛计划:征集来自计算机科学领域的相关研究提案,为学者的技术研究提供数据、资金等多维度支持。

校企协同,教学人员双向流动:一线工程师赴校宣讲授课,举办AI竞赛开放海量数据,头条青年访问学者。

AI Lab与学术机构合作
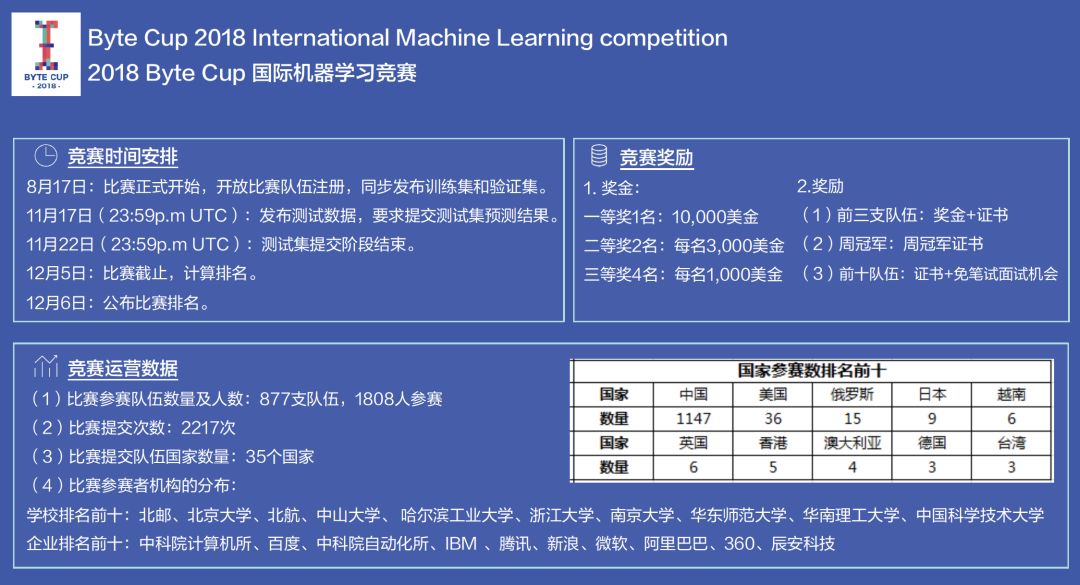
2018 Byte Cup:

2018 Byte Cup国际机器学习竞赛是一项面向全球的机器学习竞赛,旨在促进机器学习的学术研究和具体应用。Byte Cup 2018的主题是自动生成文本标题。
AI Lab与产业合作
字节跳动人工智能实验室不仅与高校与学术机构有合作,还与产业界有着密切的合作。
2018年人工智能与实体经济深度融合创新项目公示,字节跳动申报的“基于分布式机器学习平台的通用人工智能应用解决方案项目”入选;
“面向移动端的低功耗超时AR-VR开放平台项目”入选2018双创周“颠覆性创新榜”TOP10;
北京市市长陈宁领衔,北京市科委牵头,集首都高校、科技专家及领军科技企业智囊之力,为提高北京市新一代人工智能科技创新能力而集中建设的“北京智源研究院”,字节跳动为智能研究院发起成立单位之一,字节跳动技术战略研究院院长张宏江出任研究院理事长。
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。






