【AICC】AI将需要超百万倍计算力,三因素决定深度学习模型计算
1新智元报道
作者:胡祥杰
【新智元导读】人工智能三大支柱之一的计算目前发展是什么样的?它足以支撑人工智能的火速发展吗,会不会拖后腿,让人工智能的发展停滞?9月7日首届AI计算大会上述问题得到了很好的解答。在会上发表演讲的嘉宾首先对“计算力对新一波人工智能浪潮的影响有多大”进行了讨论。浪潮集团VP胡雷钧在主题演讲中对新的model对计算能力的需求三个因素进行了剖析,这里其中一个是网络深度,一个是网络里节点单元的个数和节点单元连接的复杂度,一个是处理的数据集的规模。
AICC首届AI计算大会,9月7日上午在北京国际饭店盛大开幕,中国工程院王恩东院士、李德毅院士、微软技术院士黄学东、集群超算架构创始人Thomas Sterling、浪潮副总裁胡雷钧、国家超算无锡中心主任杨广文、百度人工智能技术委员会主席朱勇、旷视科技首席科学家孙剑、深度学习框架评测专家褚晓文、Uber机器学习主任王鲁明等大咖在主论坛发表演讲,吸引到2000领域精英。
人工智能计算大会(AI Computing Conference,简称AICC)由中国工程院信息与电子工程学部主办、浪潮集团承办,以“创新计算赋能AI”为主题,主旨是围绕AI当下需求及未来发展,从计算创新着眼,联合从事AI计算及应用的公司、用户、专家、开发者共同打造探讨促进AI计算的交流合作平台,推动AI产业的可持续发展。新智元作为独家社群直播合作伙伴在新智元专家社群中对此次大会进行了图文直播,引起热烈讨论。


中国工程院院士、浪潮集团首席科学家王恩东回溯了计算的发展历史,在评价当前的计算发展时,他提到,现在的芯片计算除了原来的CPU以外,有了GPU、TPU和DPU,一堆的“PU”,为什么是这样的?这说明计算性能还不够。“看上去开发了一批专用的芯片,实际上就是ASIC”。
王恩东院士说,图灵先发明的计算机的基本原型,又提出了人工智能,计算机是大儿子,人工智能是二儿子。大儿子和二儿子的特点不一样,大儿子比较稳重比较有耐性,持续的发展,不调皮不捣蛋,像摩尔定律说的一直按照这个规律持续发展。二儿子比较活跃,有创新思维,敢冒险,于是经历了三起三落或三落三起。
他认为,人工智能的发展离不开计算、算法和数据,计算是基础。今天一台小小服务器的计算速度是20年前最快计算机的60倍。正是由于计算能力的快速发展,结合互联网、物联网带来的海量数据和深度学习等先进算法,才共同催生了第三次人工智能浪潮。

随后中国工程院院士、中国人工智能学会理事长李德毅。他在演讲中提醒人们要冷静地看待人工智能热潮,计算只是这波人工智能发展的三个要素之一。他认为,当下,首先受到人工智能冲击的四个行业分别是:制造业、教育、医疗和金融。

最近,微软宣布,微软的语音对话研究小组在Switchboard语音识别任务中,将错误率从去年的 5.9% 再一次降低到 5.1%,达到目前最先进水平。
微软语音首席科学家、技术院士黄学东在本次演讲中解读了微软的这一工作。他说,核心技术用了三类很大的标准的神经网络,DNN、CNN、RNN。微软用了将近十几个神经网络在并行的工作,语言模型也用了好几种不同的语言模型神经网络在并行的工作,通过跑了好几千个试验,用了好几百个模型的比较。“ 感谢计算的威力,我们的系统bug比较少。我们的工具比较快,CNTK比同类的深度学习工具做语音识别任务上至少快3-4倍”,因此,他也说到,CNTK可以认为是他们的秘密武器。
针对新的语音识别准度的突破,黄学东说,有这样研究的突破,大家会问这个能干什么事情?跟电脑交互的时候会不会做到真的跟人一样好?我可以告诉大家,今天的产品因为需要实时,所以还需要计算的更加努力,更加强大的GPU,大家才能真正用上超人水平的语音识别,但这只是时间问题。

根据此前的报道,浪潮的AI解决方案在全中国的占有率达到了60%,为BAT提供的产品占比达到80%。那么,浪潮具体为BAT提供的是什么?
在接受新智元的采访时,浪潮集团VP胡雷钧说:“一个是系统平台。比如浪潮研发的面向AI的产品家族,有十几款产品几十种组合。这等于为我们的客户应用这类技术提供了一个非常好的条件和环境。另外在底层的系统软件方面我们有AIStation,能够帮助客户去管理计算平台和分析计算瓶颈。我们在AI计算的框架上做了Caffe-MPI,是面向集群的非单机的比较好的并行计算框架。同时我们也很好的工程师队伍,能够帮助客户移植和优化AI的应用,能够在GPU、MIC、FPGA加速器平台上得到比较好的应用效果。”
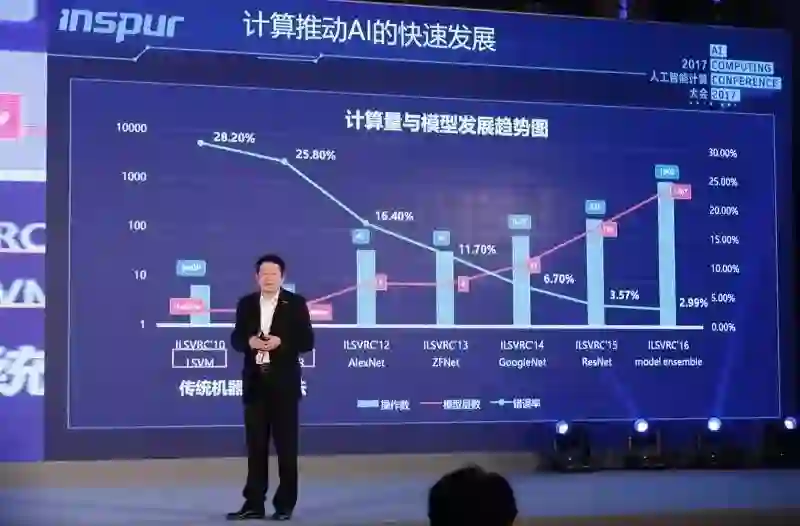
上图:绿线是人工神经网络在某一类应用, 红线是训练这个模型训练这个网络需要的总计算量。
浪潮集团 VP 胡雷钧在演讲中提到,新的model对计算能力的需求由三个因素决定,一个是网络深度,一个是网络里节点单元的个数和节点单元连接的复杂度,一个是处理的数据集的规模。这三个因素加在一起使得我们训练这个模型需要的计算能力是非常大的,比如说用120万张图片的数据集来训练一个ResNet,需要的时间是41天,整个浮点运算操作的总量是2200亿亿次。
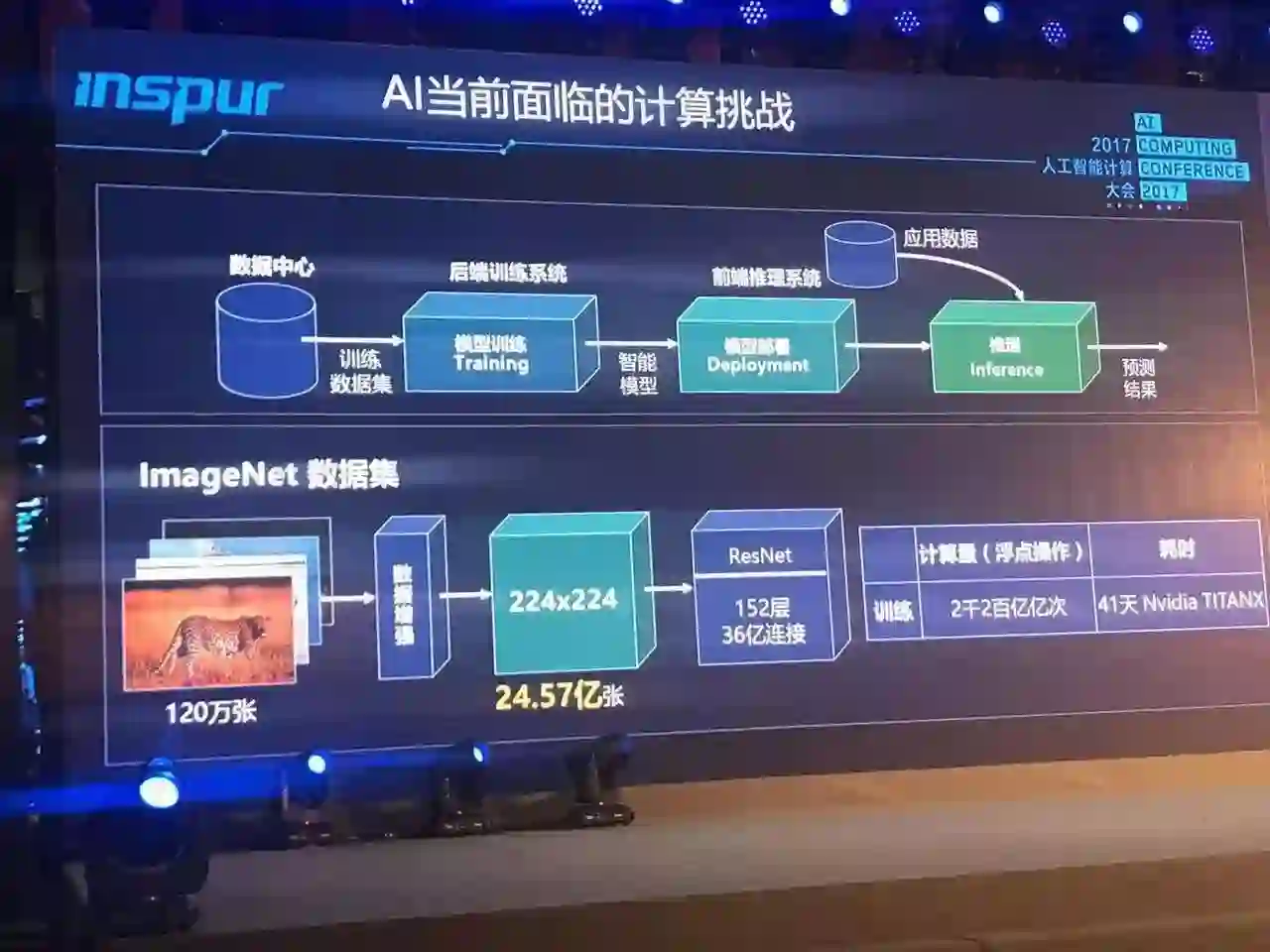

他说,AI计算平台会遇到很多瓶颈,比如数据的瓶颈、计算能力的瓶颈、延迟的瓶颈、通信能力的瓶颈。这里边无非有几个核心问题,第一处理单元能多快速度的取到它处理的数据,第二每次处理之后能以多快的速度去交换数据,这是通讯问题。第三我们在单位的空间内能集成多少计算能力。这是约束着一个计算系统最大规模也是约束着我们能以多快的时间完成一个模型的训练的问题。

胡雷钧说,监督式学习的训练复杂度相对要小一些,无监督学习不但训练的数据是变的,网络本身也是变的,网络的深度、每一层的节点的数量、每一层与每一层之间的连接都是变动的,在这些变动之下我们需要的计算规模可能要达到100个E级。而对于通用人工智能,以目前在摩尔定律约束下的专用化计算能力,还看不到在哪一天能够真正达到人脑级的运算。结论是计算推动 AI 快速发展,训练一个模型需要的计算能力是非常大的。
胡雷钧强调只有生态势能可以让AI突破计算能力的局限。他说,人工智能要想继续往前发展,就必须体系化、层次化的构建它的生态系统。有一个相对完整的生态系统的支撑,我们才能推动计算系统能够面向应用需求。在具体的实践中,我们认为AI的计算平台、AI的系统管理、AI的计算框架、AI的应用方案作为一个生态系统里不可或缺的几个重要环节,在滚动推动着AI的发展。

在演讲中,胡雷钧介绍了浪潮在Caffe的尝试,叫Caffe-MPI。
浪潮是首个把Caffe的计算模型从原先的单机版扩展成为集群版,通过这个集群版可以做到在一个系统里运行更大尺寸的神经网络,同时通过MPI的编程能够更有效的调动系统的资源来完成一个高性能计算。
这实际上就是把在高性能计算领域里的应用模式和应用方法移植到了AI的平台上,通过原先已经有的在大规模计算平台上的经验,提高AI应用或者说提高神经网络的训练效率。Caffe-MPI目前是一个开源项目,由浪潮贡献,可以自由下载。
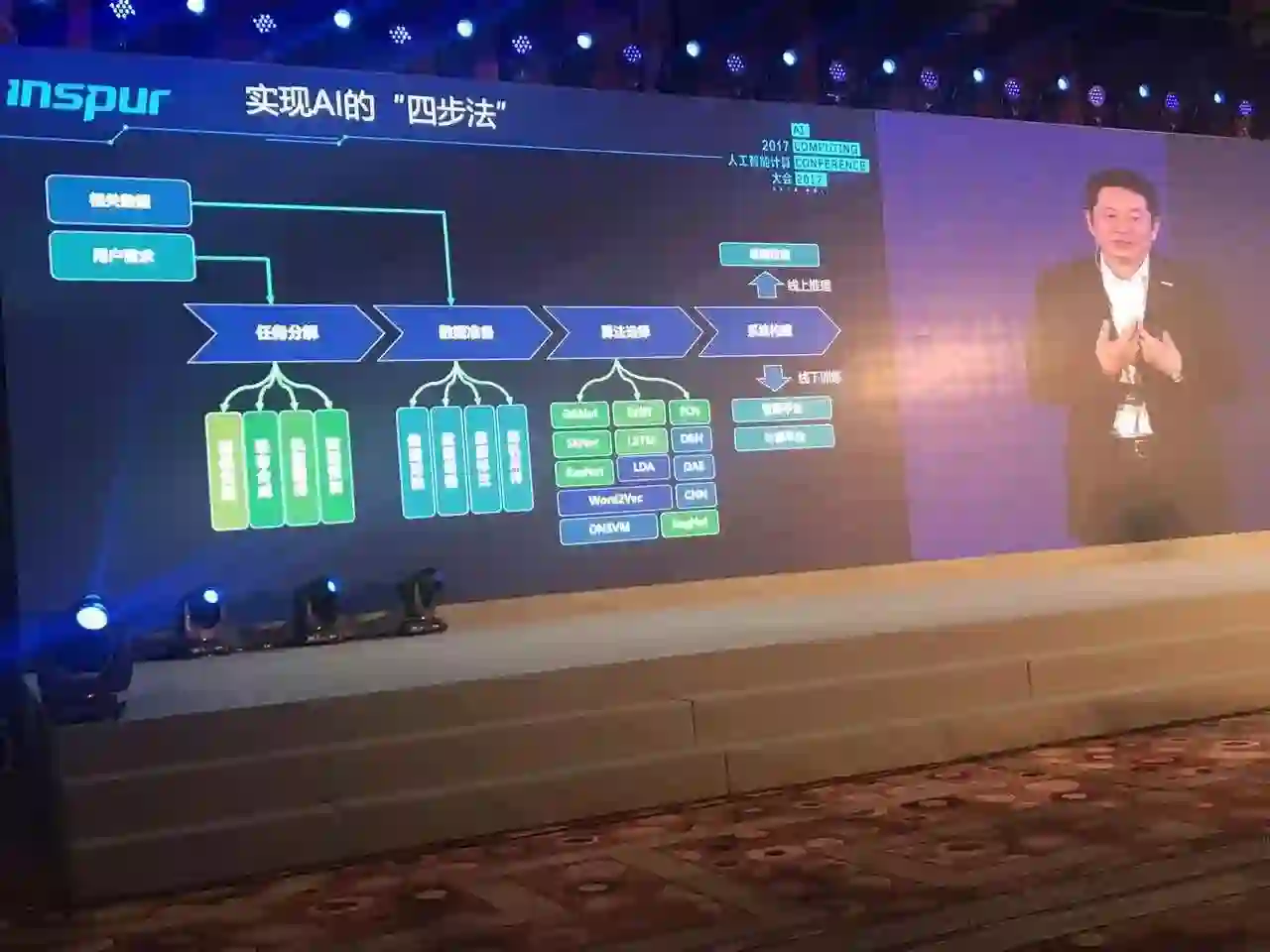
要构筑一个AI系统无论它是一个训练的系统、还是它的应用系统,无论是AI模型的供应者还是训练者,都要仔细考量系统应该怎么构成。胡雷钧总结了四步法:任务分解也就是用户需求的分解;数据准备,要有大批的数据去训练,这些数据通过采集、筛选、清洗最终把它归类,把它送到AI的平台里面去;算法选择,目前针对不同的应用有不同的算法。有了算法之后还要在系统平台上做一些试验看看我们应该构建什么样的系统平台,才能让这个算法训练得更好、运行得更好;系统构造,构造这个系统的时候我们要考虑应该用什么样的计算平台,应该用什么样的管理平台,应该怎么考虑线下的训练,应该怎么考虑线上的识别。

在这个基础上面向AI的应用,浪潮提供了E2E的解决方案。 在这里有高密度高性能的模型训练的平台AGX-2。胡雷钧说,它是目前世界上最高密度的AI计算平台,在2U空间之内支持NVLink,支持P100GPU,有基于FPGA的F10A加速卡,有高效的人工智能管理平台AIstation,有高性能深度学习框架Caffe-MPI,同时还有非常有经验的工程师队伍可以帮助优化算法。
AICC8大金句








【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~




