Netflix Drive:构建媒体资产云原生文件系统

Netflix Drive 是一个多接口、多操作系统的云文件系统,目的是在工作室艺术家的工作站上提供典型 POSIX 文件系统的外观和体验。
它有 REST 端点,行为和微服务类似。它有许多供工作流使用的后端动作以及自动化用例(用户和应用程序不直接处理文件和文件夹)。REST 端点和 POSIX 接口可以在任何 Netflix Drive 实例中共存,并不相互排斥。
Netflix Drive 配有事件告警后端(作为框架的一部分)。在 Netflix Drive 中,事件和告警是一等公民。
我们将 Netflix Drive 打造成了一个通用框架,这样用户就可以插入不同类型的数据和元数据存储。例如,让 Netflix Drive 使用 DynamoDB 作为元数据存储后端,并使用 S3 作为数据存储后端。使用 MongoDB 和 Ceph Storage 作为后端数据存储和元数据存储。要了解关于这个框架的更多细节,请观看完整的视频演示。(https://www.infoq.com/presentations/netflix-drive/)
一般来说,Netflix 开创了云上娱乐工作室的概念,目的是为了让世界各地的艺术家都可以在上面工作并开展合作。要做到这一点,Netflix 需要提供一个分布式、可扩展且性能良好的平台基础设施。
在 Netflix,资产是数据、元数据文件和文件夹集合,这些文件和文件夹由不同的系统和服务存储和管理。
以拍摄为起点,即相机录制视频(产生数据),直到数据进入电影和电视节目,不同系统基于创作流程给这些资产加上了各种元数据。
艺术家在边缘端使用资产,他使用的应用程序需要一个接口,以便无缝地访问这些文件和文件夹。这个简单的工作流不只局限于艺术家,也延伸到了工作室。内容渲染期间发生的资产转换就是一个很好的例子,该过程使用了 Netflix Drive。
工作室的工作流需要在创作迭代的各个阶段之间转移资产。每个阶段的断言都被标记为新的元数据。我们需要有一个系统,支持向数据添加不同形式的元数据。
我们还需要可以在每个阶段改变的动态访问控制等级,使得平台只向某些应用程序、用户或工作流暴露特定的资产子集。然而 AWS 存储网关在性能和安全方面不符合我们的要求。
为了满足多种场景下需求,我们设计了 Netflix Drive。该平台可以作为一个 POSIX 文件系统,在云端存储数据并从云端检索数据,它有一个功能更丰富的控制接口。它是存储基础设施的基础组成部分,可以满足许多 Netflix 工作室和平台的需求。
Netflix Drive 提供了许多接口,如图 1 所示:
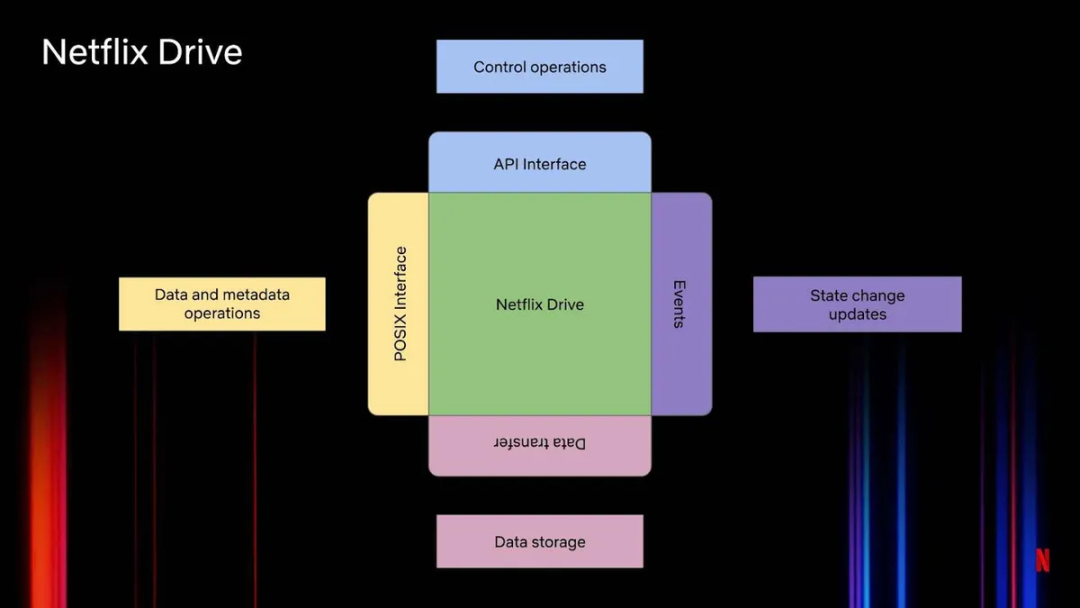
图 1:Netflix Drive 的基本架构
POSIX 接口(图 2)支持对文件做简单的文件系统操作,如创建、删除、打开、重命名、移动等。这个接口处理 Netflix Drive 上的数据和元数据操作。不同应用程序、用户、脚本或工作流会读、写存储在 Netflix Drive 上的文件,或者创建文件及提出其他操作请求。这与实时文件系统类似。
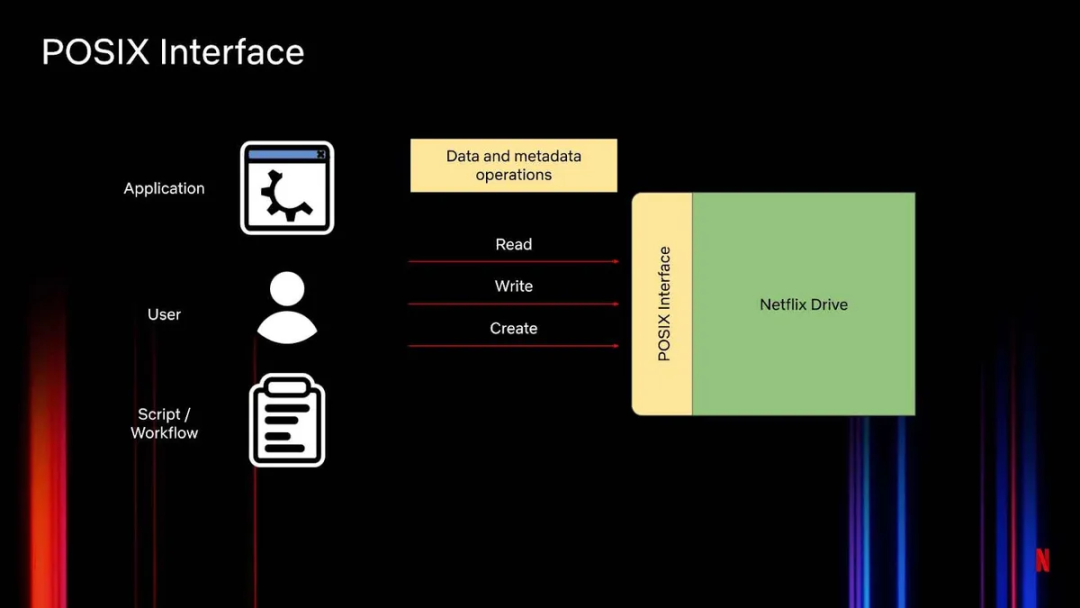
图 2:Netflix Drive 的 POSIX 接口
另一个接口是 API 接口(图 3)。它提供了一个可控的 I/O 接口。该 API 接口是很多工作流管理工具或代理特别关注的。它暴露了 Netflix Drive 上某种形式的控制操作。工作室中使用的很多工作流都在一定程度上涉及资产或文件。它们想控制这些资产在命名空间上的投影。比如,当 Netflix Drive 在用户的机器上启动时,工作流工具最初只允许用户查看大型数据集的一个子集。这就是由这些 API 管理的。这些 API 也可用于动态操作,如将特定文件上传到云端,或动态下载一组特定的资产,并在命名空间的特定点上附加和展示它们。
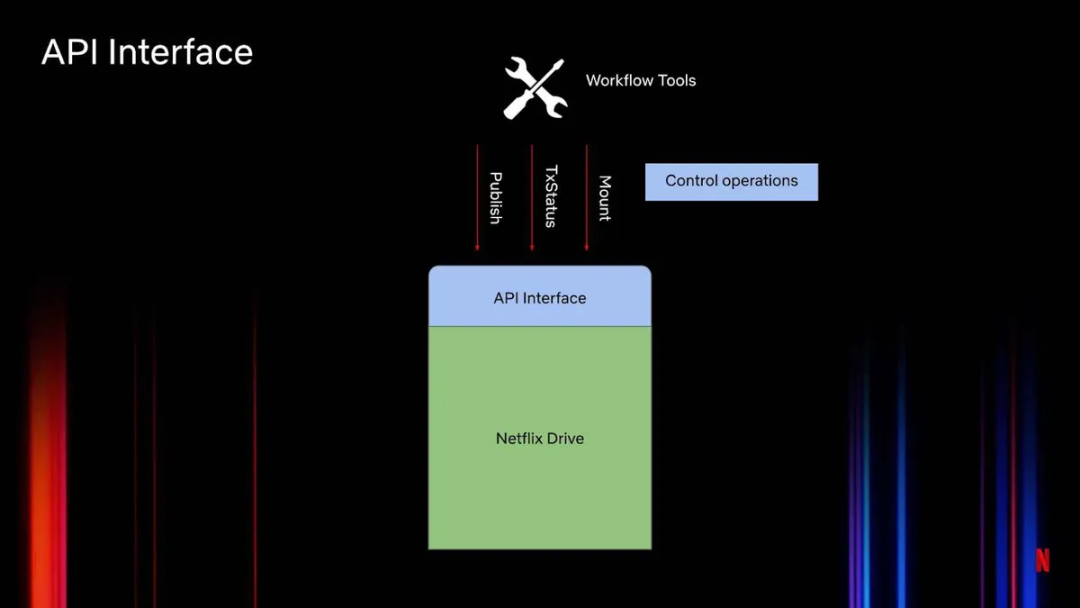
图 3:Netflix Drive 的 API 接口
如前所述,事件(图 4)在 Netflix Drive 架构中最为重要,它包含遥测信息。比如,使用审计日志跟踪不同用户对同一个文件所做的所有操作。我们需要在云中运行的服务能够消费审计日志、度量和更新。这里使用了通用框架,允许将不同类型的事件后端接入 Netflix Drive 生态系统。
另外,事件接口也用于基于 Netflix Drive 进行的构建。这个接口可以创建共享文件和文件夹。
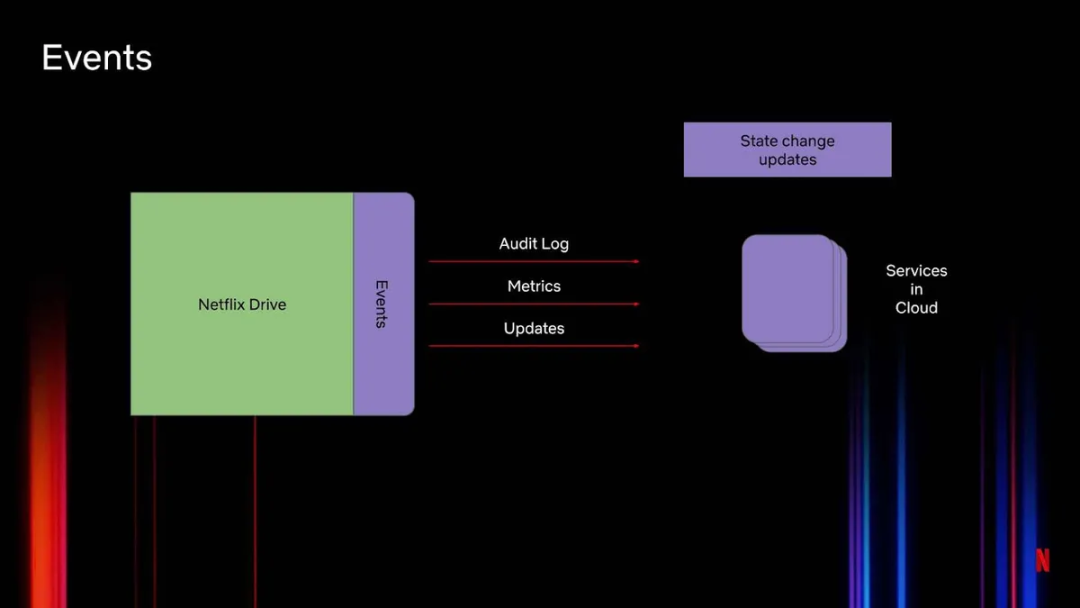
图 4:Netflix Drive 中的事件
数据传输层(图 5)是一个抽象概念,处理数据从 Netflix Drive 到多层存储和不同类型接口的传输。它把文件传输到艺术家工作站或机器上的 Netflix Drive 挂载点。
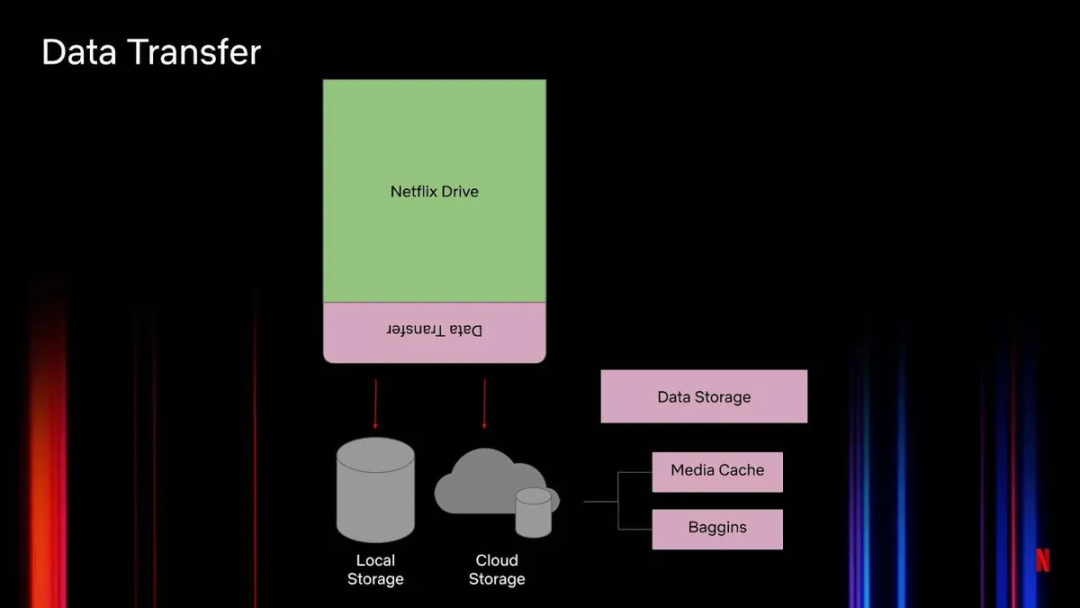
图 5:Netflix Drive 中的数据传输
出于性能考虑,Netflix Drive 不处理直接将数据发送到云端的问题。我们希望 Netflix Drive 的性能尽可能地模拟本地文件系统。因此,如果可以,尽量使用本地存储来存储文件,然后按既定的策略将数据从本地存储转移到云存储。
我们通过两种方式将数据转移到云端。第一种是控制接口使用动态发布 API,让工作流可以将资产的子集转移到云端。另一种是自动同步,这是一种将所有本地文件与云存储文件自动同步的能力。这与 Google Drive 存储文件的方式相同。为此,云存储分成了不同的层。图 5 列出了媒体缓存(Media Cache)和 Baggins:媒体缓存是一个具备区域感知能力的缓存层,使数据更靠近边缘用户;Baggins 是位于 S3 之上的一层,处理分块和加密内容。
总的来说,Netflix Drive 的架构包含用于数据和元数据操作的 POSIX 接口。API 接口处理不同类型的控制操作。事件接口跟踪所有状态变化更新。数据传输接口将在 Netflix Drive 上进进出出的数据到云端的传输进行抽象。
Netflix Drive 包含 3 个层(图 6):接口、存储后端、传输服务。
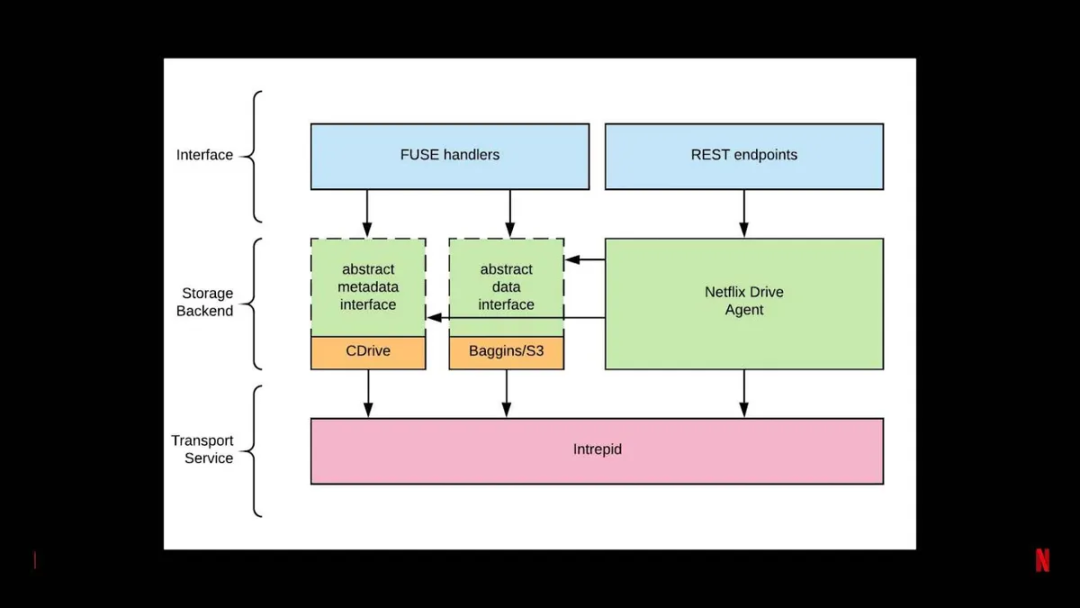
图 6:Netflix Drive 剖析
最上面的接口层包含所有的 FUSE 文件处理程序和 REST 端点。
中间是存储后端层。请记住,Netflix Drive 提供了一个框架,你可以在其中插入并使用不同类型的存储后端。这里有抽象的元数据接口和抽象的数据接口。在第一次迭代时 CDrive 作为元数据存储。CDrive 是 Netflix 自己的工作室资产感知( studio-asset-aware)的元数据存储。如前所述,Baggins 是 Netflix 的 S3 数据存储层,在将内容推送到 S3 之前对其进行分块和加密。
Intrepid 是传输层,将数据传输到 Netflix Drive 以及从 Netflix Drive 传出数据。Intrepid 是内部开发的高效传输协议,许多 Netflix 应用程序和服务都用它来将数据从一个服务传输到另一个服务。Intrepid 不仅用于传输数据,而且还用于元数据存储某些方面的传输。通过这种能力来在云上保存元数据存储的一些状态。
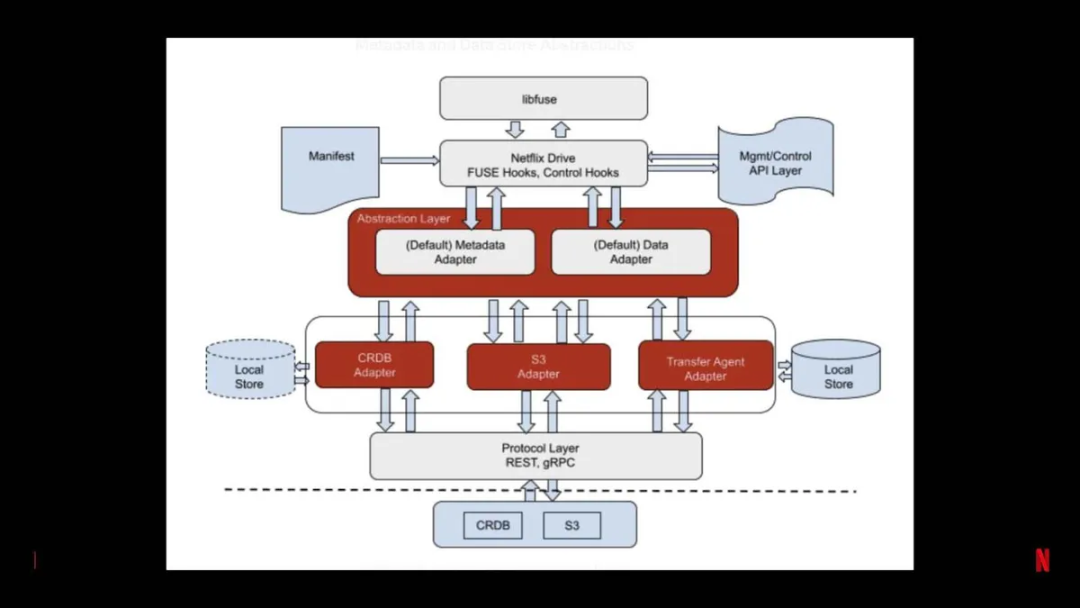
图 7:Netflix Drive 的抽象层
因为我们使用的是基于 FUSE 的文件系统,libfuse 负责处理不同的文件系统操作。启动 Netflix Drive,通过清单文件以及 REST API 和控制接口对它进行引导。
抽象层抽象了默认的元数据存储和数据存储,可以使用不同类型的数据和元数据存储。在这个例子中,用 CockroachDB 适配器作为元数据存储,用 S3 适配器作为数据存储。此外还可以使用不同类型的传输协议,它们是 Netflix Drive 即插即用接口的一部分。协议层可以是 REST 或 gRPC。最后是实际的数据存储。
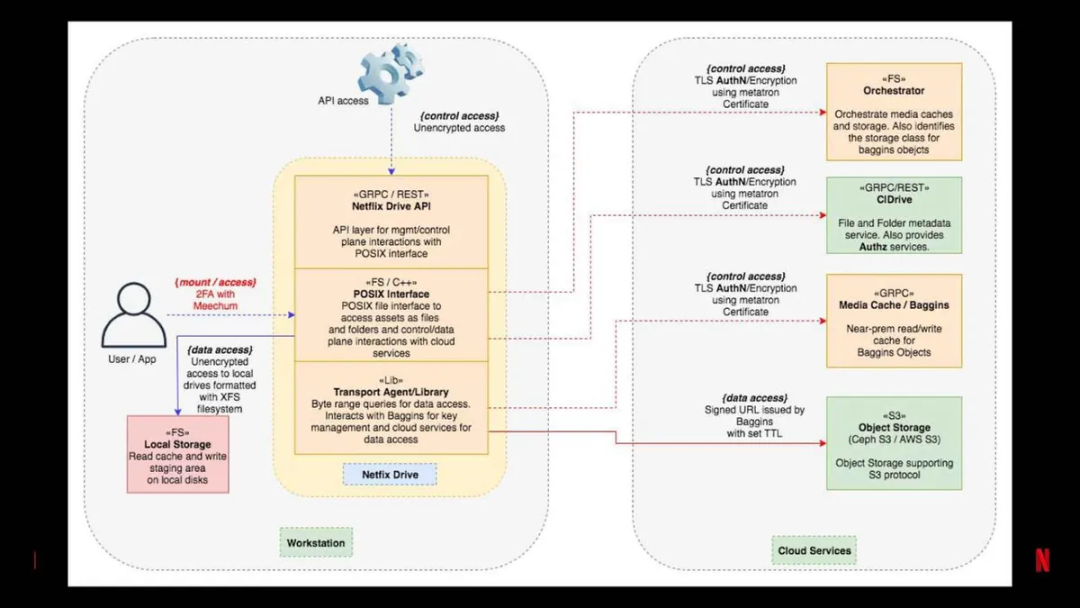
图 8:Netflix Drive 服务在本地工作站和云之间的划分
工作站机器上配有典型的 Netflix Drive API 和 POSIX 接口。本地工作站上的 Netflix Drive 将使用传输代理和库来与元数据存储和数据存储进行交互。
云服务包含元数据存储,在 Netflix 是 CDrive。媒体缓存作为存储的中间层。S3 提供对象存储。
注意,我们也使用本地存储来缓存读和写,以满足用户对 Netflix Drive 的高性能期待。
安全是 Netflix Drive 的一个关注点。许多应用程序使用这些云服务;它们位于 Netflix 的所有资产库之前。确保这些资产的安全,并且只允许有适当权限的用户查看允许他们访问的资产子集,这一点至关重要。因此,Netflix Drive 上使用了双因素认证。
安全是基于 CockroachDB 构建的一个层。Netflix Drive 利用了 Netflix 内部的一些安全服务,目前没有可以插入的外部安全 API。我们计划在发布任何开源版本之前把它们抽象出来,这样任何人都可以构建可插拔的模块来进行处理。
鉴于 Netflix Drive 能够动态地呈现命名空间,并将不同的数据存储和元数据存储汇集在一起,因此必须考虑其生命周期。
最初通过清单启动 Netflix Drive,而这个初始清单可能是空的。工作站或工作流从云端下载资产,并将这些内容预加载到 Netflix Drive 的挂载点。工作流和艺术家修改这些资产,Netflix Drive 会定期用公开的 API 进行快照,或者使用自动同步功能将这些资产上传到云端。
在启动过程中,Netflix Drive 通常要求指定一个挂载点。它使用用户的身份进行认证和授权。它创建本地存储的位置(文件将被缓存在那里),以及端点的云元数据存储和数据存储。清单包含用于预加载内容的可选字段。
使用 Netflix Drive 的应用程序和工作流有不同的类型,每一种角色都有自己的特点。例如,有的应用程序可能特别依赖 REST 控制接口,因为它知道资产,所以会直接使用 API 将文件上传到云端。其他应用程序可能不知道何时将文件上传到云端,所以会依靠自动同步功能在后台上传文件。这些都是 Netflix Drive 的每个角色所定义的各种可选方案。
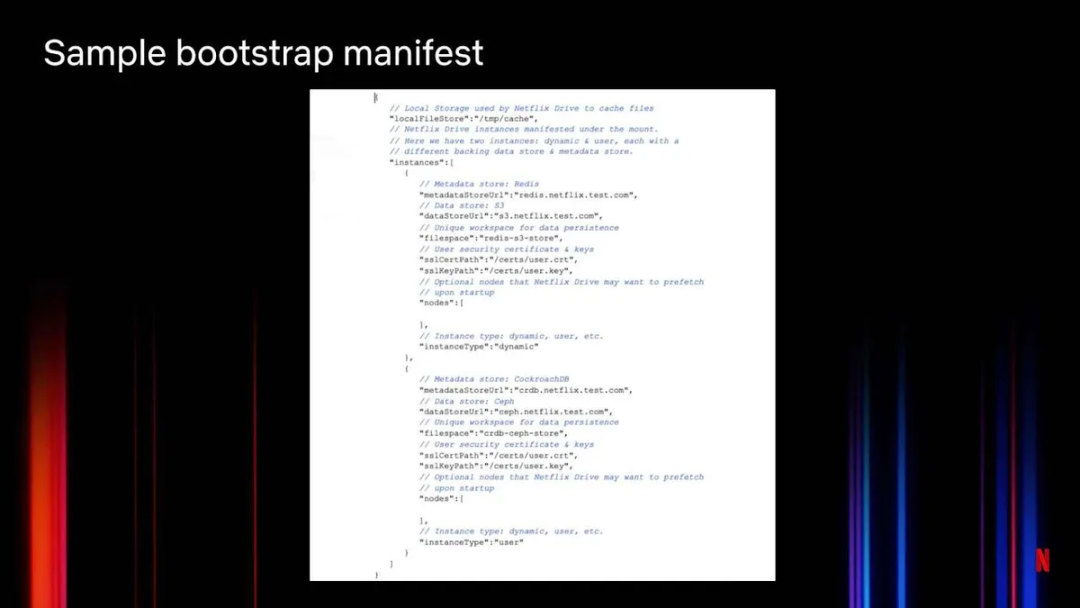
图 9:Netflix Drive 的引导程序清单示例
图 9 展示了一个引导程序清单示例。定义好本地存储之后,Netflix Drive 声明了实例。每个挂载点可以有多个不同的 Netflix Drive 实例。这里使用了两个实例:一个动态实例和一个用户实例,每个实例有各自的后端数据存储和元数据存储。动态实例使用 Redis 元数据存储和 S3 数据存储。用户实例使用 CockroachDB 元数据存储和 Ceph 数据存储。为实现数据持久化,Netflix Drive 为每个工作空间分配了一个唯一标识。
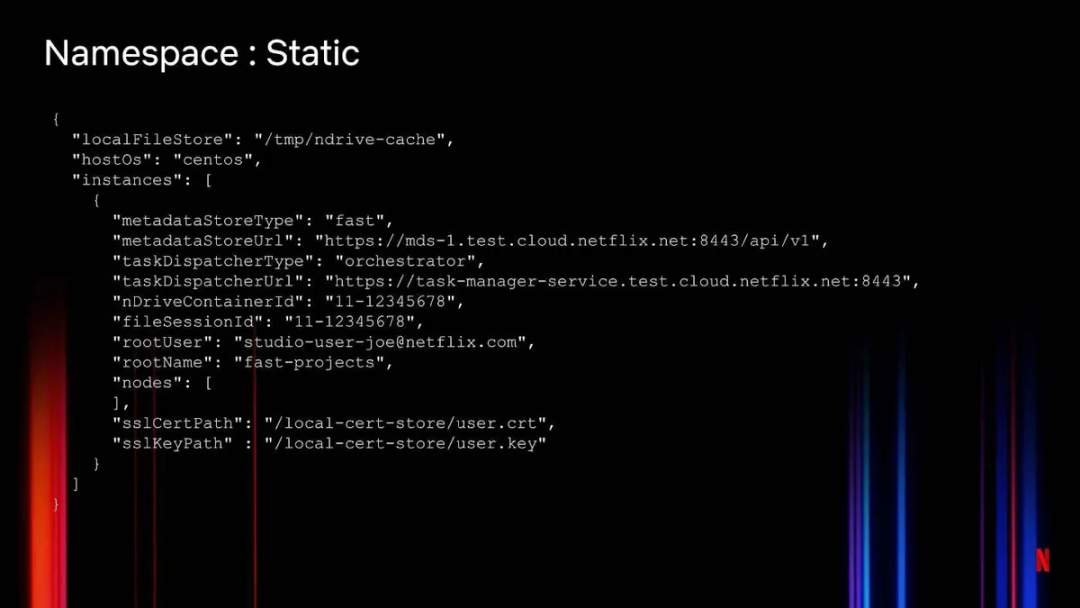
图 10:Netflix Drive 命名空间的静态设置
Netflix Drive 的命名空间是可以查看所有文件的地方。Netflix Drive 可以静态或动态地创建命名空间。静态方法(图 10)准确指定了要在引导时预下载到当前实例的文件。为此,我们提供了一个文件会话和容器信息。工作流可以用文件预先填充 Netflix Drive 挂载点,这样后续的工作流就可以以此为基础进行构建。
创建命名空间的动态方法是在 REST 接口中调用 Netflix Drive API(图 11)。在本例中,stage API 暂存文件以及从云存储中拉取文件,然后将它们附加到命名空间中的特定位置。这些静态和动态接口并不相互排斥。

图 11:Netflix Drive 命名空间的动态设置
Netflix Drive 的 POSIX 操作可以完成文件的打开 / 关闭、移动、读 / 写等动作。
此外,REST API 的一个子集也可以修改文件——例如,API 可以暂存文件,从云中拉取文件。可以设置文件检查点,可以保存文件,显式地将文件上传到云存储。
图 12 展示了如何使用 Publish API 将文件上传到云上。我们可以自动保存文件,即定期检查文件并上传到云上,还可以执行显式保存,显式保存是一个 API,不同的工作流可以调用它来发布内容。
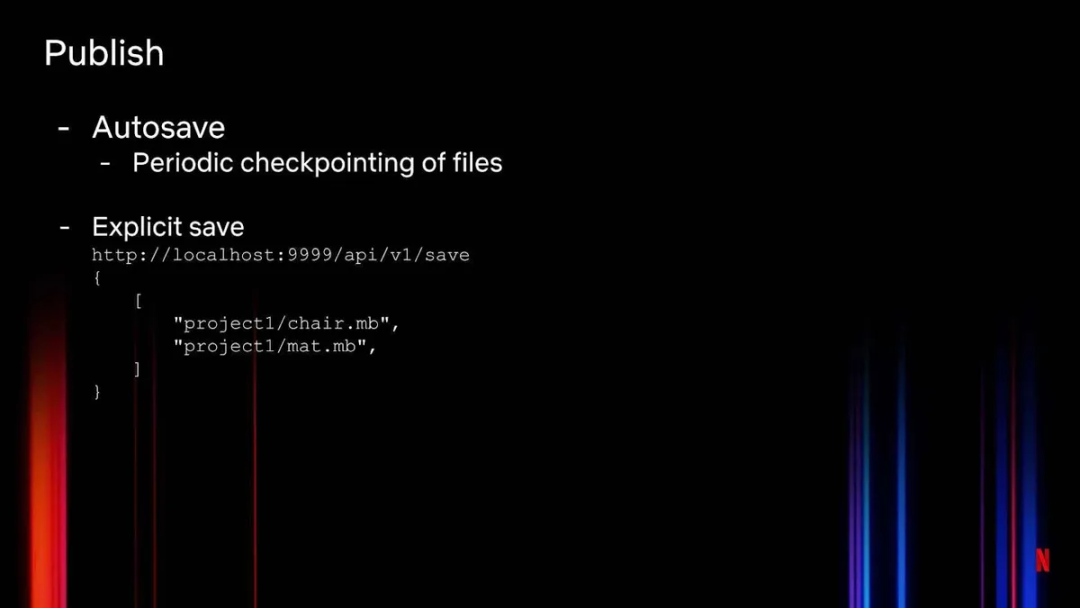
图 12:Netflix Drive 的 Publish API
使用不同 API 的一个很好的例子是当艺术家处理大量瞬息数据时。这些数据中的大部分都不需要上传云端,因为这些数据还只是过程数据,不是最终产品。对于这样的工作流,显式保存更合适,而不是自动保存(即 Google Drive 保存文件的方式)。一旦艺术家确定内容已经可以分享给其他艺术家或工作流,就可以调用这个 API 将其保存到云端。该 API 将在艺术家的 Netflix Drive 挂载点中生成选定文件的快照,并将它们传送到云端,存储在适当的命名空间下。
多个角色在不同类型的工作流中使用 Netflix Drive,这在开发过程中教会了我们很多东西。在设计架构时遇到了多个需要考虑的点。
文件、工作流和艺术家工作站的性能 / 延迟要求——以及我们希望为使用 Netflix Drive 的艺术家提供的体验——决定了许多架构选择。我们用 C++ 实现了很多代码。比较各种语言,我们认为 C++ 的性能最好,这是重点关注的一个方面。没有使用 Rust 是因为那时 Rust 还没有充分支持 FUSE 文件系统。
我们希望 Netflix Drive 成为一个通用框架,任何插入数据存储和元数据存储都可以接受。为多个操作系统设计通用框架非常困难。在研究了其他可选方案之后,我们决定在 CentOS、macOS 和 Windows 上使用基于 FUSE 的文件系统来支持 Netflix Drive。这成倍地增加了测试矩阵和支持矩阵。
我们使用不同的后端,拥有不同的缓存和分层。依赖缓存的元数据操作。Netflix Drive 服务 EB 级数据和数十亿项资产,可扩展性设计是架构的基石之一。在云上扩展解决方案的瓶颈是数据存储。但是元数据存储才是瓶颈。可扩展性的关键是处理元数据。我们非常关注元数据管理,降低元数据存储的调用次数。在本地缓存大量数据可以提高工作室应用程序和工作流的性能。通常,这些应用程序和工作流需要大量的元数据。
我们探索在云中使用文件系统(如 EFS)。但是,文件系统扩展到一定程度时会影响性能。为了服务于数十亿项资产,需要使用某种形式的对象存储,而不是文件存储。这意味着艺术家所熟悉的文件必须被转换成对象。最简单的方法是在文件和对象之间建立起一对一映射——尽管这样做很简单,但文件大小可能会超过支持的最大对象的大小。我们需要将一个文件映射到多个对象。如果艺术家改变了文件中的一个像素,Netflix Drive 只需要改变包含相关块的对象。构建转换层是一种权衡,是为了可扩展性。
对象的使用带来了数据去重和分块的问题。对象存储使用版本控制:对象的每次更改,无论更改多小,都会创建对象的新版本。按照惯例,哪怕是文件中的一个像素发生了变化,也要发送整个文件并将其作为一个对象重新写入。你不能只是发送增量并将其应用到云存储上。通过将一个文件分成多个对象,可以缩小必须发送到云端的对象。选择合适的块大小与其说是一门科学,不如说是一门艺术,因为许多较小的块意味着管理大量数据和大量转化逻辑,元数据的数据量会增加。另一个需要考虑的问题是加密。我们对每个数据块进行加密,所以数据块越小越多,加密密钥和元数据就越多。块大小可以在 Netflix Drive 中配置。
多层存储可以提高性能。在设计 Netflix Drive 时,我们并没有局限于本地存储或云存储。构建它是为了可以轻松地将不同的存储层添加到 Netflix Drive 框架中。这体现在设计、架构和代码中。例如,媒体缓存只是一个媒体存储,缓存层更接近于用户和应用程序。Netflix Drive 在本地文件存储中缓存了很多数据,而 Google Drive 不是这样做的。因此,和他们相比,可以有更好的本地文件系统性能。
这是我们拒绝 AWS 存储网关的另一个原因。如果多位艺术家同时处理一项资产,并且该资产的每次迭代都存储在云端,那么云成本将会激增。我们希望这些资产存储在离用户较近的媒体缓存(这是只有 Netflix 才有的东西)中,并控制最终副本何时进入云端。利用这种混合基础设施,这些参数可以通过 AWS 存储网关获得。
软件架构的栈式方法至关重要。共享命名空间就是一个很好的例子。目前,我们正致力于提升在不同工作站或艺术家之间共享文件的能力。我们以事件框架为基础进行构建,而后者已被设计成 Netflix Drive 架构本身的一部分。当 Netflix Drive 实例上的一个用户将一个文件添加到特定的命名空间时,它会生成一个可供不同云服务使用的事件。然后,Netflix Drive 会使用 REST 接口将该文件注入到访问该命名空间的其他 Netflix Drive 实例中。
如果你想了解更多有关 Netflix Drive 的信息,请查阅技术博客。
我们努力争取明年开源 Netflix Drive。许多希望在云端创建工作室的人都联系了我们,他们希望使用 Netflix Drive 的开源版本,并针对其用例构建可插拔模块,这个问题会优先考虑。
作者简介:
Tejas Chopra 是 Netflix 数据存储平台团队的一名资深软件工程师。
原文链接:
https://www.infoq.com/articles/netflix-drive-cloud-native-filesystem/
点击底部 阅读原文 访问 InfoQ 官网,获取更多精彩内容!

点个在看少个 bug 👇

