随机森林和提升树
王妮梅连续搞砸了妈妈介绍的40个男生,要么不约要么约完再无联系,她妈妈心急如焚又给她找了20个男生。王妮梅疯了,因为她失败了这么多次,已经不再相信自己对男生喜好的判断了。这时她找来闺蜜刘舒,想让刘舒帮她捋一捋,告诉她这20个男生哪个喜欢应该去约哪个讨厌应该不约?
王妮梅
刘舒,能帮我捋一捋这 20 个男生哪个喜欢应该去约哪个讨厌应该不约吗?
刘舒
你疯了吗?这太难了吧,起码你得给我你对男生的一些判断标准吧。

刘舒也疯了,觉得这也太难了,起码让我知道王妮梅你对男生的一些判断标准吧。王妮梅把之前失败的 40 个男生信息给她,也告诉了她之前对每个男生做出的“约或不约”的判断。王妮梅这就是将样本 (男生) 打上标签 (约/不约),给刘舒参考。
刘舒看完所有信息之后大概知道了王妮梅对男生的喜好标准,然后对这20个男生设计了一系列的问题,比如“X 是否有大男子主义?”,“X 是否不接你的电话”等等。问完之后刘舒说应该约 X。刘舒 (柳树) 是判断王妮梅的男生喜好的一棵决策树 (decision tree)。
刘舒只是个人,所以她并不总能很好地概括王妮梅的喜好 (过拟合)。为了获得更准确的建议,王妮梅去询问一堆朋友,结果他们中的大多数人认为自己应该约 X。这些朋友叫宋舒 (松树)、杨舒 (杨树) 和佰舒 (柏树),他们组成了判断王妮梅的男生喜好的一片森林 (forest)。
现在王妮梅不想让她的每个朋友都做同样的事情,给你一样的答案,所以王妮梅首先给每个人略有不同的数据。毕竟,王妮梅也并不完全确定自己的喜好:
她告诉刘舒,她想约 Y,但也许因为她当天加薪开心并不是真的钟意 Y,因此刘舒应该给“王妮梅想约 Y 这个决定”少放点权重
她告诉宋舒,她想约 Z,并且实际上她真的很喜欢 Z,因此宋舒应该给“王妮梅想约 Z 这个决定”多放点权重
所以,王妮梅决定给宋舒、杨舒和佰舒的数据不要和给刘舒的数据一样,她在给他们的数据上随机加一些轻微的干扰项。王妮梅不会改变自己的最终喜好,只会加一些“很喜欢”、“一般喜欢”、“很讨厌”之类的感情色彩。这时候王妮梅给每个朋友是原始数据的自助采样 (bootstrapped) 版本。通常这种机制,王妮梅希望朋友能给她一些相互独立的推荐,刘舒觉得你喜欢 X 和 Z,宋舒觉得你喜欢 X 和 Y,而杨舒觉得你讨厌所有人。他们之间这些错误可以在多数投票时可以相互抵消。现在他们组成了判断王妮梅的男生喜好的一片随机森林 (random forest)。
虽然王妮梅喜欢 X 和 Y,但并不是因为他们都是基金经理,也许她喜欢这两个男生有其他原因。因此,王妮梅不希望她的朋友们都根据“是否赚钱多”而提出建议。王妮梅只允许朋友们问一小部分随机的问题,比如刘舒不能问“是否赚钱多”,柏舒不能问“是否热爱小动物”等等。以前王妮梅在数据层面注入随机性 (通过稍微扰乱自己的男生喜好),现在她在问题层面注入随机性 (让她的朋友在不同的时间提出不同的问题)。现在他们组成了判断王妮梅的男生喜好的一片更为随机的随机森林 (random forest)。
最终,王妮梅拿到所有人对这 20 个男生的推荐,再根据自己对这些朋友的信任度和品位在他们的推荐上加个权重。信任刘舒多一些,就多注重她的推荐,信任杨舒少一些,就少注重他的推荐。这个最终结合类似于 boosting。
上贴的装袋法 (bagging) 和提升法 (boosting) 的两种结合 (aggregate) 方法,但是结合的模型或假想都是抽象的 h,本帖将 h 具体化,来探讨这两种方法配上树模型之后的结合模型,bagging 对应的随机森林和 boosting 对应的提升树。
第一章 - 前戏王
1.1 偏差和方差
1.2 分类回归树
1.3 损失函数和代价函数
1.4 加法模型和前向分布算法
第二章 - 随机森林
2.1 随机来源
2.2 包外估计
2.3 特征选择
第三章 - 提升树
3.1 提升分类树
3.2 提升回归树
3.3 梯度提升分类树
总结和下帖预告

给定一个模型,它做回归或分类预测是一定会有误差的,误差来源有三个:
对 N 套训练集得到的 N 个模型求均值得到一个平均模型,它与真实模型之间的差距叫做偏差 (bias)
用 N 套训练集得到的 N 个模型本身也各不相同,它们的变动水平叫做方差 (variance)
一些不可消除的因素造成的误差是噪声 (noise)
更多关于偏差和方差的细节可见模型的评估和选择一贴,简单来讲
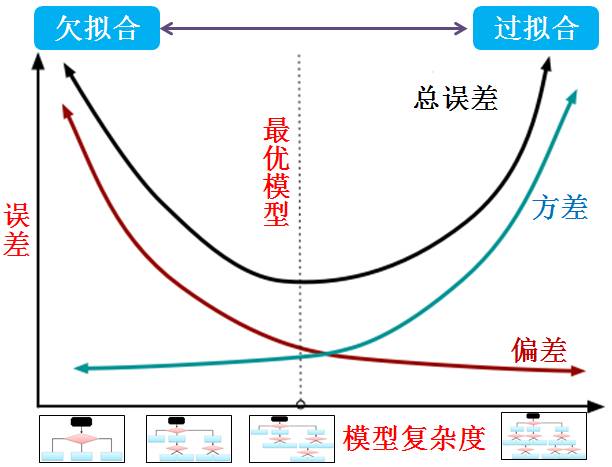
简单模型的偏差大方差小,复杂模型的偏差小方差大。
偏差和模型复杂度成反比,方差和模型复杂度成正比。
简单模型“欠拟合”,复杂模型“过拟合”。
欠拟合”的模型的偏差大方差小,“过拟合”的模型的偏差小方差大
用决策树当模型,那么树的深度越大叶子越多,模型复杂度也就越高。因此决策树桩 (decision stump) 最简单,偏差大方差小,而长成的树 (fully-grown tree) 最复杂,偏差小方差大。一张图胜过千句话:
注:小节 2.1 会用到
分类回归树 (classification and regression tree, CART) 既可以用于创建分类树 (classification tree),也可以用于创建回归树 (regression Tree)。CART 的主要特点有:
特征选择:根据 CART 要做回归还是分类任务,对于
回归树:用平方残差 (square of residual) 最小化准则来选择特征,叶子上是类别值
分类树:用基尼指数 (Gini index) 最小化准则来选择特征。叶子上是实数值
二叉树:在内节点都是对特征属性进行二分 (binary split)。根据特征属性是连续类型还是离散类型,对于
连续类型特征 X:X 是实数。可将 X < c 对应的样例分到左子树,X > c 对应的样例分到右子树,其中 c 是最优分界点,由最小化平方残差而得
离散类型特征 X :X 是 n 类变量。假设 n = 3,特征 X 的取值是好、一般、坏,那么二分序列会有如下 3 种可能性:
{ [好,一般],[坏] }
{ [好,坏], [一般] }
{ [好], [一般,坏] }
需要分别计算按照上述三个在二分序列做分叉时的基尼指数,然后选取产生最小的基尼指数的二分序列做该特征的分叉二值序列参与回归树。因此,CART 不适用于离散特征有多个取值的场景。
停止条件:根据特征属性是连续类型还是离散类型,对于
连续类型特征:当某个分支里所有样例都分到一边
离散类型特征:
当某个分支里所有样例都分到一边
当某个分支上特征已经用完了
对“停止条件”这条还想加点说明:根据离散特征分支划分子树时,子树中不应再包含该特征。比如用特征“相貌”来划分成左子树 (相貌=丑) 和右子树 (相貌=美),那么无论在哪颗子树再往下走,再按特征“相貌”划分完全时多余的,因为上面早已用“相貌”划分好;而根据连续特征分支时,各分支下的子树必须依旧包含该特征 (因为该连续特征再接下来的树分支过程中可能依旧起着决定性作用)。
通常先让 CART 长成一棵完整的树 (fully-grown tree),之后为了避免过拟合,再后修剪 (post-pruning) 树,具体用到的方法见决策树一贴。
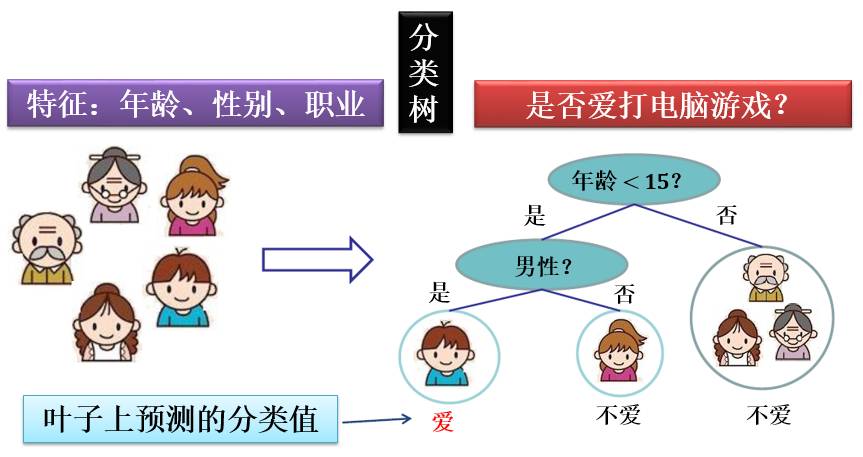
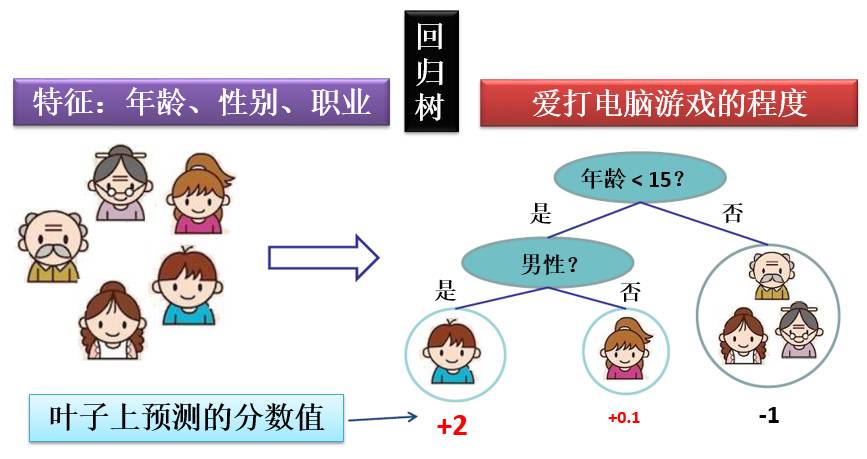
下面两图分别画出分类树和回归树的一个例子:
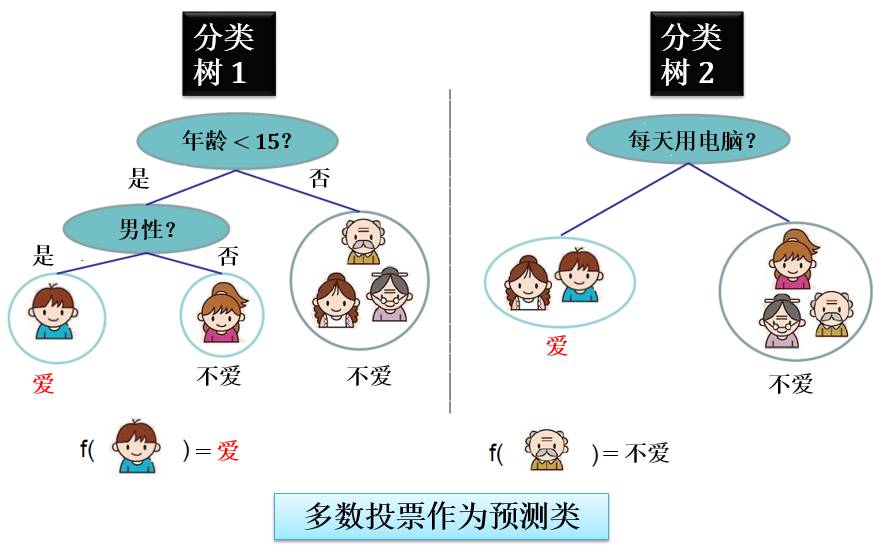
第二、三章要讲随机森林和提升树,下面两图画出分别由分类树林或回归树林的一个例子:
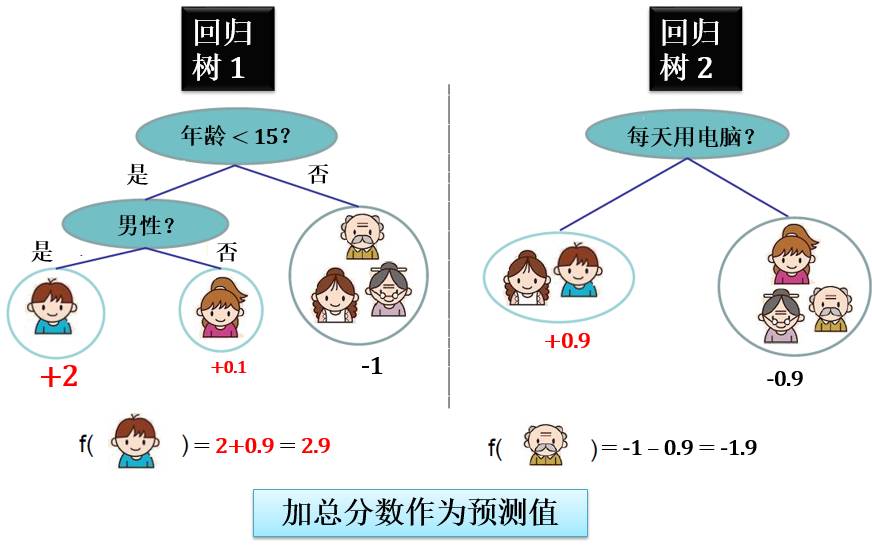
注:在第二、三章讲的随机森林和提升树用的原材料都是 CART
损失函数 (loss function) 是用来估量在一个样本点上模型的预测值 h(x) 与真实值 y 的不一致程度。它是一个非负实值函数,通常使用 L(y, h(x)) 来表示。
损失函数可由 y 的类型来分类,而第三章提升树的梯度提升法在高层面上讲是相同的,不同的是用的不一样损失函数。
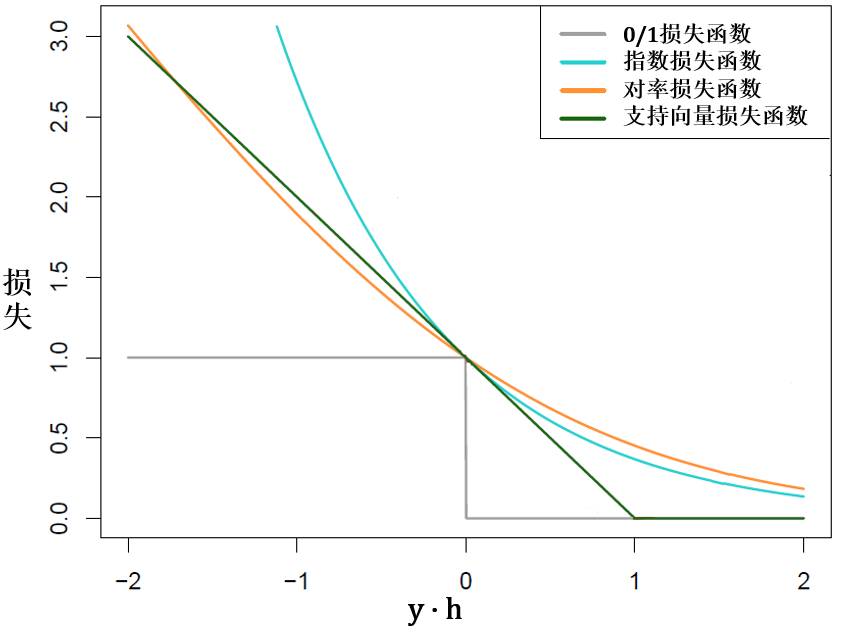
如果 y 是离散型变量 (对应着提升分类树 y 和 sign(h) 取 -1 和 1)
0-1 损失函数 (misclassification)
指数损失函数 (adaBoost)
对数损失函数 (logitBoost)
支持向量损失函数 (support vector)
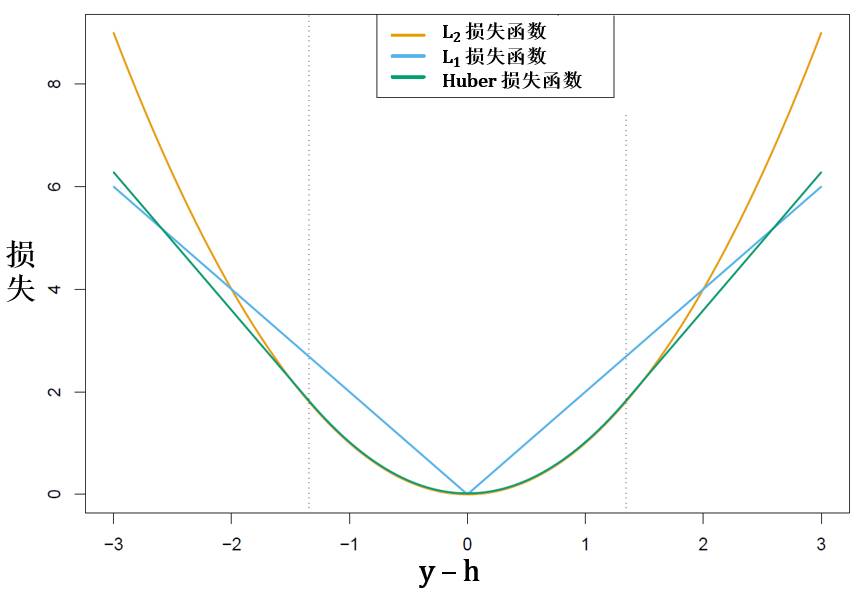
如果 y 是连续性变量 (对应着提升回归树 y 和 h 取任意实数)
L2 损失函数 (regression boost)
L1 损失函数
Huber 损失函数
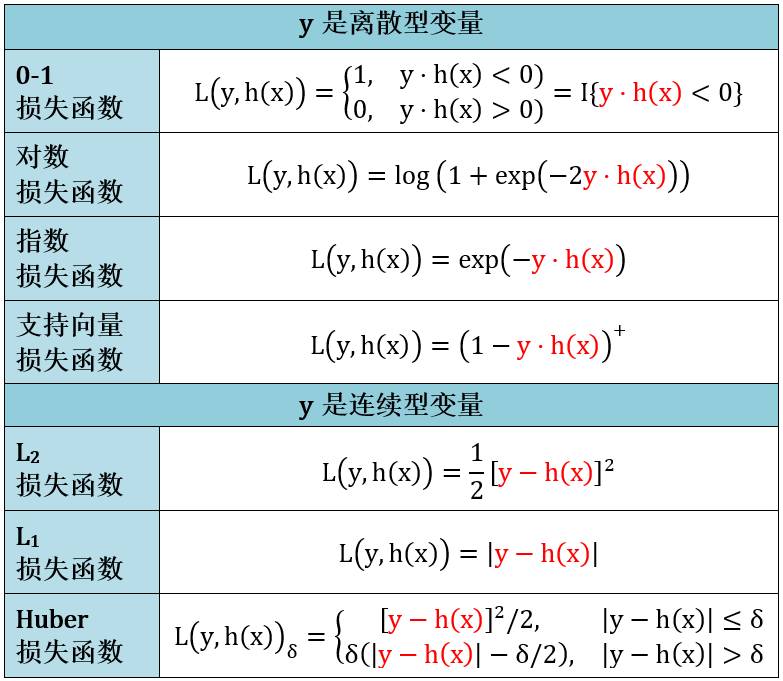
下表列出了每个损失函数的具体表达式:
当 y 是离散性变量时对应的问题都是分类问题
真实值 y 和预测值 sign(h) 都规定只能取正负 1
损失函数里面都有 y∙h 这一项而且函数是它的减函数。在这里我们用 1 表示正类,-1 表示反类,那么 y∙h > 0 代表预测结果和真实结果一致,因而损失值低些;反之 y∙h < 0 代表预测结果和真实结果不一致,因而损失值高些
当 y 是连续性变量时对应的问题都是回归问题
真实值 y 和预测值 h(x) 可以取任意实数
损失函数里面都有 |y – h(x)| 这一项而且函数是它的增函数。当真实值 y 和预测值 h(x) 之间差别越大(小),损失值越高(低)
代价函数 (cost function)就是所有样本点上的损失函数的加总。代价函数越小,模型的鲁棒性 (robustness) 就越好。
注:小节 3.1 和 3.2 会用到
加法模型 (additive model) 是由一系列的基函数 (base function) 线性组成,表示如下
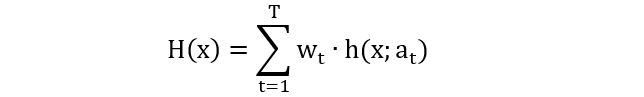
其中
h(x; at)是基函数
at 是基函数的参数
wt 是基函数的系数 (权重)
在给定训练数据 (x(i), y(i)) 及损失函数 L(y, H(x)) 的条件下,学习加法模型 H(x) 可转换成下面损失函数最小化问题
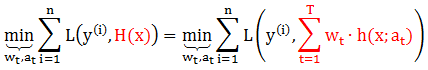
通常一次性优化解出 wt 和 at 是很复杂的,我们现在思路是如果从 t 等于 1 到 T,每一步只学习一个基函数和其系数,逐步逼近上面的函数式,从而简化了优化的复杂度。具体优化步骤如下:
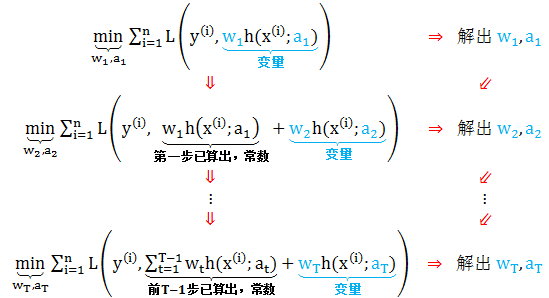
上面的算法也称为前向分布 (forward stage-wise) 算法。

这样,前向分布算法将同时求解从 t 等于 1 到 T 所有参数 wt 和 at 的优化问题简化为逐步求解各个 wt 和 at 的优化问题。大家仔细回顾一下上贴集成学习前传讲的 adaBoost 算法里面也是逐步确定权重的,和前向分布算法的步骤很像,两者有什么联系吗?
注:整个第三章会用到
随机森林 (random forest, RF) 是用随机的方式建立一个森林。为什么叫森林呢?因为它是由许多决策树组成的。为什么叫随机呢?下节告诉你。
数据集是二维的,每一行是一个样例 (instance),除最后一列的每一列是一个特征 (features),最后一列是标记 (label),如下图所示:
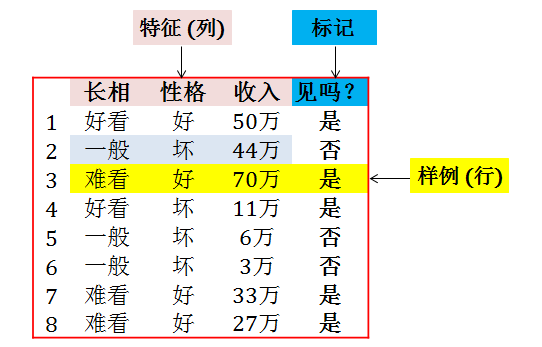
根据数据的二维结构,生成随机数据的办法有两个:
在样例上随机 (行采样):采用自助采样法 (重置采样),也就是在采样得到的样例集合中,可能有重复的样例。通常是从含 n 个原始样例集自助采样出来一个新的含 n 个采样样例集。
在特征上随机 (列采样):因为树可以在特征集上分裂,因此在每棵树不同分裂点上,从 m 个特征中随机选择 j 个 (j < m) 而规定这个分裂点上只能在这j个特征上做分裂。
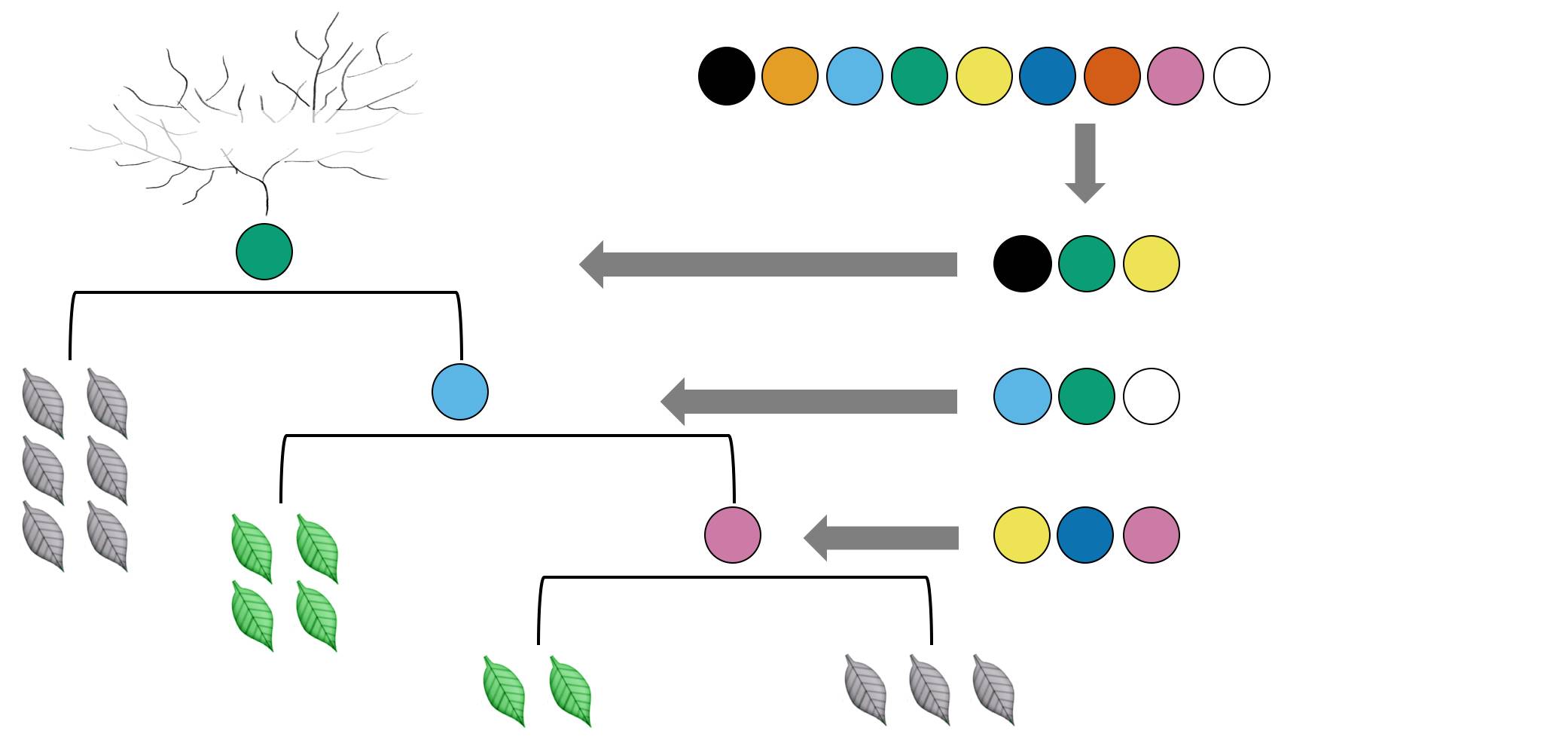
因此随机森林有两种常见形式,第一种是只做行采样,第二种是做行采样和列采样。第二种森林里面的树更加随机,因此在实践中用的也更多。这二种随机形式如下图。
第一种:没有在特征上随机采样
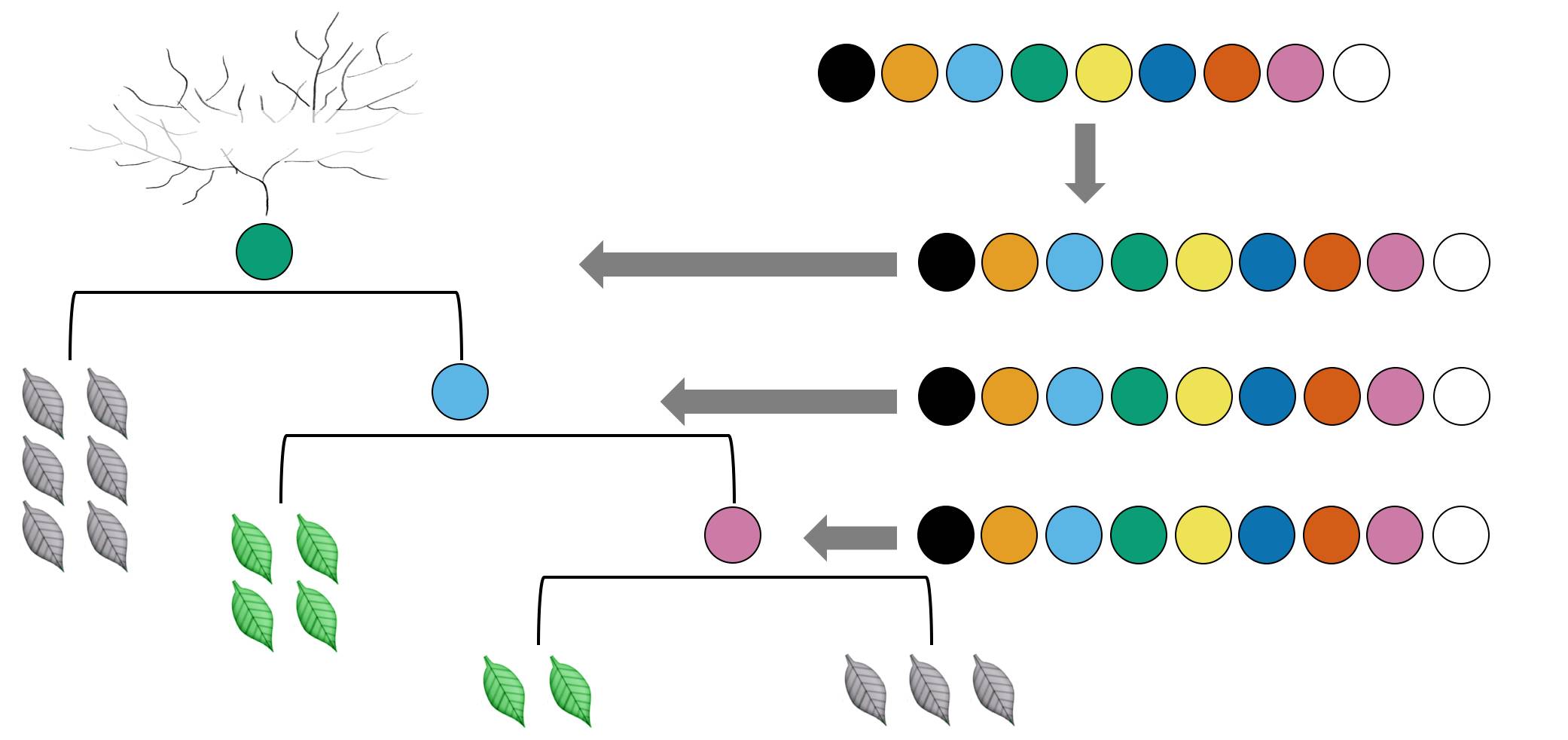
第二种:从 9 个特征随机取 3 个
随机选出数据和特征之后,使用完全分裂的方式建立出决策树。一般很多的决策树算法都一个重要的步骤 - 剪枝,但是在随机森林不需要做。由于之前的两种随机采样的过程保证了随机性,只要森林里面的树够多,所以就算不剪枝,也不会出现过拟合。
在生成森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,对于
分类树:将每个样本在不同树叶属于的类别,找一个最多的当预测类别
回归树:将每个样本在不同树叶上得到的值,求一个平均当预测值
由于在数据上、特征上都注入随机的成分,因此可以认为随机森林中的每一棵决策树之间是相互独立的。假设森林有 M 棵小树
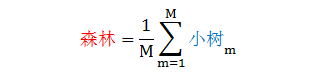
M 棵树的平均误差等于每个小树和真实树之间误差的平方再平均
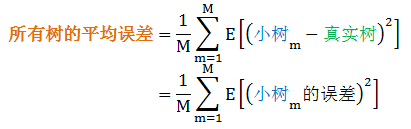
森林的平均误差等于森林和真实树之间误差的平方

上式倒数第三步因为小树之间相互独立,因此它们之间误差的协方差等于零。由上面证明可看出随机森林通过均匀结合的方式可以降低误差 (由上贴集成学习前传的 1.3 小节可知降低误差这一部分都是方差而不是偏差),因而对每个子模型 (即,决策树) 可以选复杂的高方差低偏差 (即,完全长成的树)。这样一来,每棵小树的缺点是方差高,优点是偏差低;而森林将所有小树融合起来,降低了整体的方差,也没有增高偏差。此外,随机森林算法从 bagging 过程中可以分配到不同的计算机中进行计算,每台计算机可以独立学习一棵树,不同的树之间没有任何依赖关系。这使得随机森林算法很容易实现并行化。
对一个样本数量为 n 的初始数据集自助采样 (bagging),如果采样集的样本数量也为 n,那么没有被选到的样本大概占 (1 – 1/n)n,当 n 很大时,有下列极限公式
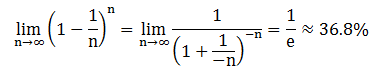
因此每次做这样一次自助采样,初始数据集里面只有 63.2% 的数据被选中当训练数据,剩下 36.8% 没被选中的可以自动作为验证数据。这些验证数据可对随机森林的泛化能力做包外 (out-of-bag, OOB) 估计。
假设有 n 个数据,森林里面有 T 棵树,下图列出每个数据 (x(i), y(i)) 出现在不同的树 ht 里的一种可能情况。
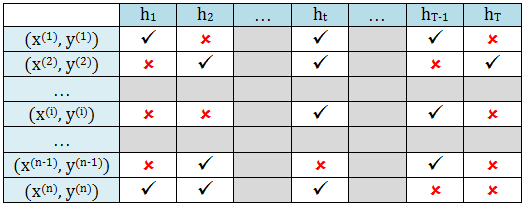
其中“勾勾”表示该数据出现在用来训练某一棵树的数据集中,“叉叉”表示该数据没有出现在用来训练某一棵树的数据集中。比如
(x(1), y(1)) 用来训练 h1, ht 和 hT-1
(x(2), y(2)) 用来训练 h2, ht 和 hT
(x(n), y(n)) 用来训练 h1, h2 和 h3
那些没有用来当训练集的数据可以自动归为测试集。需要注意的是
这些测试集不需要测试每课树,因为即使单棵树测试出来的性能很差,并不能说明均匀结合后的森林的性能很差
测试集里某数据只能测试这个数据没有用于训练的树上,比如 (x(1), y(1)) 训练了 h1, ht 和 hT-1,那么它只能测试 h2 和 hT
上述过程总结与下图
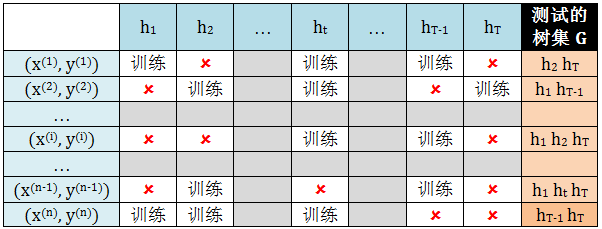
定义第 i 个数据对应的测试树集为 G(i),那么用所有 OOB 数据计算出来的测试误差为
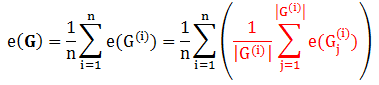
其中
e(∙) 是误差函数
G 是整个测试树集
G(i) 是第 i 个测试树集
|G(i)| 是集合的大小
Gj(i) 是第 i 个测试树集里第 j 棵树
特征选择 (feature selection),其目的主要是使用程序来自动选择需要的特征,而将冗余的、不相关的特征忽略掉。对于线性模型,特征选择很简单。在正规化线性回归一帖中讲过,拟合出 y = wTx 里面的参数 w,根据每个参数的绝对值大小 (绝对值越大,变动一点 x 对 y 的影响越大) 来对其重要性排序,选出前 d 个作为最重要的 d 个特征。因此对线性模型,根据重要性 (参数的绝对值) 来选择特征 (回忆一下岭回归和套索回归)
重要性(j) = |wj|
但是对非线性模型,特征选择就没有这么简单了。幸运的是,随机森林虽然是非线性模型,但是其特有的机制可以很容易做到初步的特征选择。随机森林的特征选择的核心思想是“如果特征 j 是重要特征,那么加入一些随机噪声模型性能会下降”。现在问题就在如何加随机噪声了。直接在原数据上加一些均值分布或正态分布的数据好吗?不好,因为这样做会改变原有特征的数据分布。因此我们的做法是把所有数据在特征 j 上的值重新随机排列,整个过程的专业叫法是置换检验 (permutation test)。这样做的好处是可以保证随机打乱 (干扰) 的数据分布和原数据接近一致。
下图给出了在特征“性格”上做随机排列后的数据样貌,随机排列将“好坏坏好坏坏好好”排成“坏坏好好好坏坏好”。
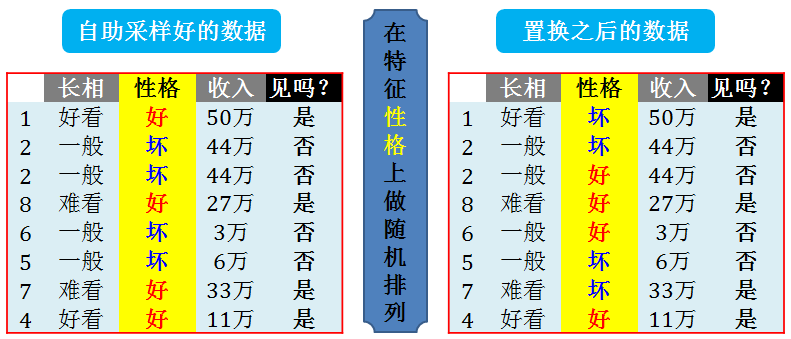
在置换检验后,特征 j 的重要性可看成是森林“在原数据的性能”和“在特征 j 数据置换后的性能”的差距,有
重要性(j) = |性能(D) – 性能(Dp)|
其中
D 是原有采样数据
Dp 是置换之后的数据
这样做太消耗时间,还要重新再用 Dp 训练一遍随机森林。随机森林的 OOB 数据可以简化以上步骤:
重要性(j) = |性能(D) – 性能(Dp)|
= |误差(DOOB) – 误差(DpOOB)|
其中
DOOB 是 OOB 数据
DpOOB 是 OOB 置换之后的数据
这样看来,我们就不用重新训练模型了。训练好森林之后,对每个树 ht 对应的 OOB 数据,在特征 j 上随机打乱 (注意现在随机打乱的是 OOB 数据而不是全部数据),分别计算打乱前和打乱后的误差,最后在森林层面上再求一个平均,公式如下:

若给特征 j 随机加入噪声之后,OOB 的误差率大幅度增高,则重要性(j)也会大幅度增大,因此它特征比较重要而应该选择。
提升树 (boosted tree) 主要在回归分类树上提升性能,3.1 节从上贴的 adaBoost 开始引出提升分类树;3.2 节从一个简单例子开始引出提升回归树;3.3 节则从提升回归树的算法发现梯度提升的规律,进而一般化为梯度提升树。这三节都回用到 1.4 节介绍的加法模型和前向分布算法。
回顾集成学习前传一帖小节 3.3 讲的逐步提升(adaBoost) 的算法:

在集成学习前传一帖中,上面算法推出的核心思想是“在第 t+1 轮生成一个树桩,使得它和第 t 轮的树桩尽量独立”。在本小节,我们根据之前介绍的加法模型和前向分布算法来推出上贴的 adaBoost 算法,在这里就成为提升树桩算法
提升树桩模型是由决策树桩组成的加法模型,损失函数用的是指数损失函数,总结在下表:

定义
H0(x) = 0
Ht(x) = Ht-1(x) + wtht(x)
因此
H(x) = HT(x)
在前向分布算法中,对于求出的前 t-1 个二分类器,我们认为是已知的了,不要去改变它们,而目标是放在之后的分类器建立上。假设经过 t-1 轮迭代的前向分布算法已经得到 Ht-1(x),在第 t 轮最小化损失函数 L(w,h) 得到 wt 和 ht(x)。这里我们把函数 h 当做损失函数中的一个参数。
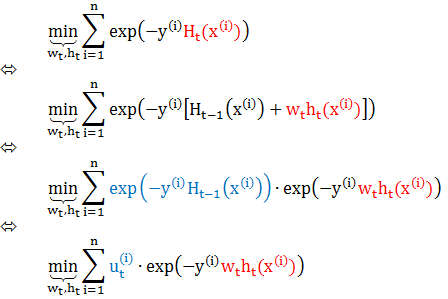
其中 u(i)t 不依赖 wt 和 ht,因此与最小化无关,但是它依赖 Ht-1(x),因此随着每一轮迭代而改变。现在的任务就是就最优解 wt 和 ht 而使得上式最小。
第一步:求 ht
在而分类器是决策树桩的前提下,特征个数是有限的,因此相对应的决策树桩个数也是有限的,你计算出所有决策树桩的误差率,然后找一个最小的作为 h。原因是 w 大于零,要是 exp(-ywh) 最小,那么 y 和 h 要同号的最多,因此要找一个分类误差率最小的 h。
第二步:求 wt
用第一步求出的 h 带入目标函数中,得
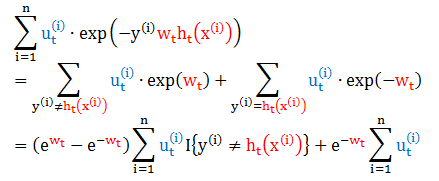
将上式求导设成 0 得到

这和上贴 adaBoost 计算出来的 wt 完全一致。最后来看每一轮样本权值 u(i)t+1 更新,有
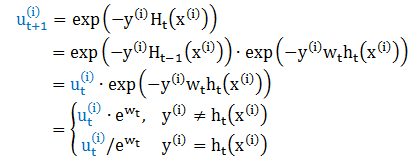
当 t = 0 时,H0(x) = 0,因为每个u(i)1 都等于 1,规范化之后等于 1/N。这和上贴 adaBoost 计算出来的 u(i)t+1 也几乎一致,就相差规范化的因子,因而两者也是等价的。
用加法模型和前向分布算法的提升树桩算法的流程如下:

在讲提升回归树前,先做一个游戏。假设你有 n 个数据 (x1, y1), (x2, y2),…, (xn, yn),任务是拟合一个函数来最小化平方损失。现在你朋友给你一个函数 H,你发现这个函数拟合的不错但不完美,在每个点上还是有误差,比如 H(x1) = 0.8 但是 y1 = 0.9;H(x2) = 1.4 但是 y2 = 1.3。现在你朋友让你改进这个模型,但是必须遵守以下两点规则:
不能改变 H 里面任何项或任何参数
只能在 H 上加额外模型 h (新的预测是 H+h)
最简单的模型改进做法是直接求出 h
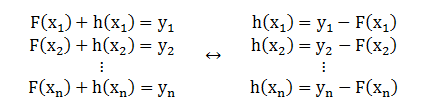
当然你不能把函数 h 在每个点都完美拟合出来,但是在数据 (x1, h1), (x2, h2),…, (xn, hn) 进行新的一轮回归,你可以得到更好的模型 H+h。其中 hi = yi – H(xi) 叫做残差,它们是 H 在第一轮表现不好的地方,也就是说 h 是现有模型 H 的缺点。如果 H+h 的结果还不满意,再进行一轮回归。既然是回归,当然也可以用回归树来做进而一步步提升模型。
提升回归树模型是由回归树组成的加法模型,损失函数用的是 L2 损失函数,总结在下表:

提升回归树算法的流程如下:

回到上节提升回归树的问题,令代价函数为 J,它是对所有数据点上的损失函数的总和,我们有
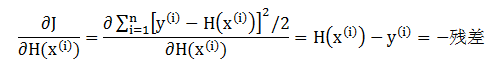
我们发现每轮拟合的残差恰恰就是其损失函数的负梯度,根据上节最后的算法,在第 t 轮更新回归树
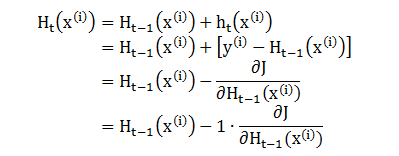
上式最后一步不就是梯度下降 (gradient descent) 吗?回忆一下线性回归里面梯度下降的公式 wt = wt-1 – a∙∂J/∂wt-1。
根据在提升回归树拟合残差来更新模型的过程,又因为残差等于负梯度,下表类比出来更新模型的过程可以用梯度下降来描述:
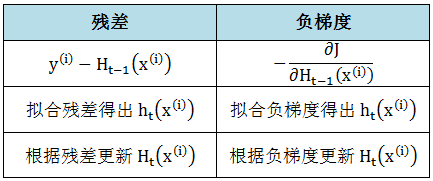
因此我们使用梯度下降法来更新模型,而梯度的概念远比残差的概念更广义,因此让我们现在忘掉残差而接受梯度吧,而其对应的提升树叫做梯度提升树 (gradient boosted tree, GBT)。除了 L2 损失函数,它可以处理任何损失函数。对于回归问题为什么还要选其他损失函数呢,L2 损失函数不够吗?请看下表:
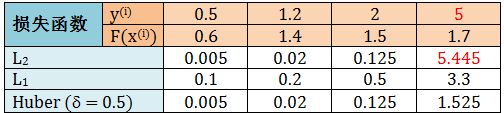
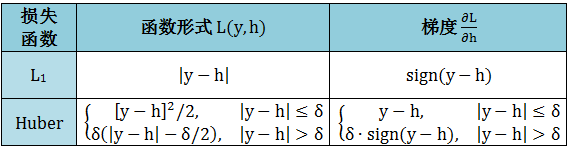
注意上表 y 等于 5 时是一个异常点,而用 L2 算出的损失是 5.445,比起在其他点的损失太过于大了,因此 L2 作为损失函数会放大异常点而降低模型的鲁棒性。再看 L1 和 Huber 下算出的损失就友好很多了,因此在很多提升树模型中,我们会选 L1 和 Huber 损失函数,而这时要套用上节提升回归树的算法,只用计算 L1 和 Huber 损失函数的梯度即可,如下表:
对梯度提升回归树算法的流程如下:

最后总结:其实提升更像是一种思想,梯度提升是一种提升的方法,它的核心理念是,每一次建立模型是在之前建立模型损失函数的梯度下降方向。注意:本节没有讲如何选择一个适当的参数 wt,也没有讲梯度提升分类树。
随机森林 (RF) 和梯度提升树 (GBT) 都是在树上做集成学习,这两种方法都是 Kaggle 中做集成比选用的方法:
随机森林是用自助采样法均匀结合了一堆完全长成的分类回归树,有 "RF = bagging + 强树"
梯度提升树是用梯度下降法非均匀结合了一堆弱的分类回归树,有“GBT = gradient boosting + 弱树”
随机森林的 bagging 本身就用于减小方差,因此森林里面的树可以是高方差低偏差而不用剪枝的强树。此外随机森林容易并行处理,而且自带袋外数据作验证,还可以做特征选择。提升树是将一堆高偏差低方差的弱树结合起来,按顺序的训练出一颗颗树,每棵树通过提升梯度来改进前面训练的结果。其中极度梯度提升 (extreme gradient boosting, XGBoost) 的方法是梯度提升的极品,速度快,效果好,功能多,是 Kaggle 数据科学竞赛获奖选手最常用的方法之一。
没有模型是完美的。使用简单模型 (决策树) 或复杂模型 (随机森林、提升树) 是在模型预测能力和可解释性两者做权衡。这些复杂模型通常被认为是黑盒子,因为随机森林是随机的生成的决策树,而不是由明确的预测规则领导,或梯度提升树后面的数学概念太过复杂,很难想大众解释清楚。有时候不可解释或难于解释的预测可能会在医疗领域使用时带来伦理问题。尽管如此,随机森林和梯度提升树还是被广泛使用,因为它们易于实施,特别是当结果的准确性比可解释性更重要的时候。
下一贴充满着真实数据 (来自美国借贷俱乐部,Lending Club),实际问题和编程代码的一贴。学而不编则罔,编而不学则殆,希望下一贴用代码来复习决策树和集成学习的内容,包括构建树和树桩,用 adaBoost 来提高树的分类性能。Stay Tuned!





