视频剪辑是一项费时费力的工作,需要剪辑者自己去找合适的帧并将其拼接在一起。如果能将这一过程自动化,部分剪辑师可能就不用熬夜剪片子了。来自清华、北航、哈佛大学和以色列赫兹利亚跨学科研究中心的研究者开发了一种全新的视频剪辑方法,可以通过编辑视频对应的文本完成镜头选取和拼接,生成符合文字描述的连贯视频。
![]()
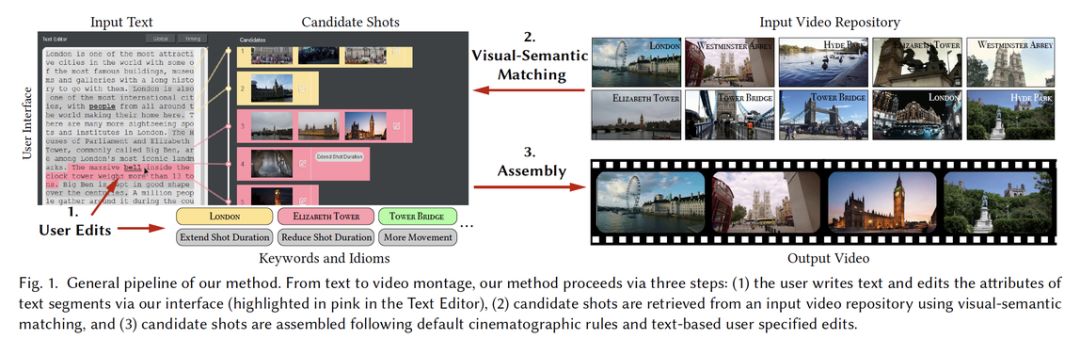
研究者提出的这一工具名为「Write-A-Video」,它可以根据文本来决定选取库中的哪些镜头或场景,以此来组成剪辑者所需的故事情节。该工具对新手非常友好,即使不具备专业的视频剪辑技巧也能得到高质量的视频蒙太奇。
研究者还提出了一个全新的视频剪辑界面,用户可以直接在文本上进行操作,而无需对视频帧进行操作。
他们在不同的主题文本和视频资料库中进行了测试,并进行了定量评估和用户研究。结果表明,这一结合了人类和算法能力的智能数字化工具可以在创意创造过程中给予用户帮助。借助于 Write-A-Video 工具,没有任何视频剪辑经验的用户也可以剪出令人满意的视频,有时候剪辑速度甚至比那些使用帧剪辑工具的专业人士还要快。
该团队准备在本月 17-20 号举办的 ACM SIGGRAPH Asia 大会上展示这一成果。ACM SIGGRAPH Asia 是一个由国际图形图像协会举办的电脑图像和互动技术展览及会议,是计算机图形学的顶级国际会议。
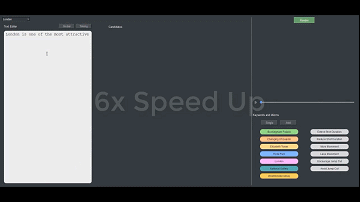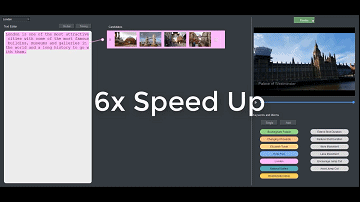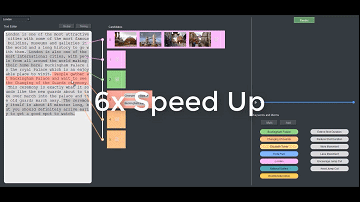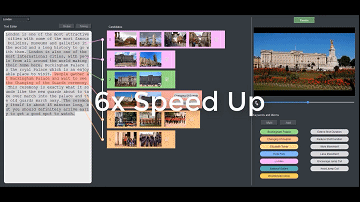
研究者表示,「Write-A-Video」允许剪辑者创通过简单地编辑视频附带的文本来创建视频蒙太奇。他们可以添加或删除文本、移动句子转换成视频剪辑操作,如找到相应的镜头、剪辑或重置镜头等。
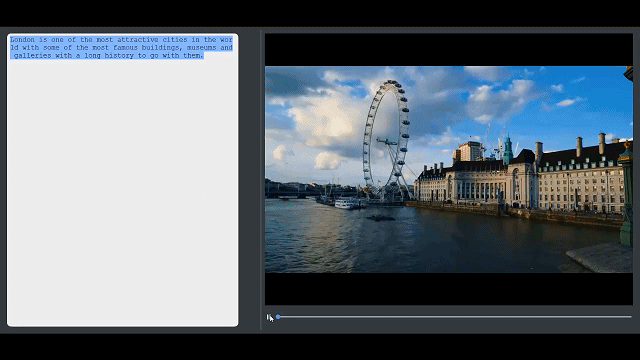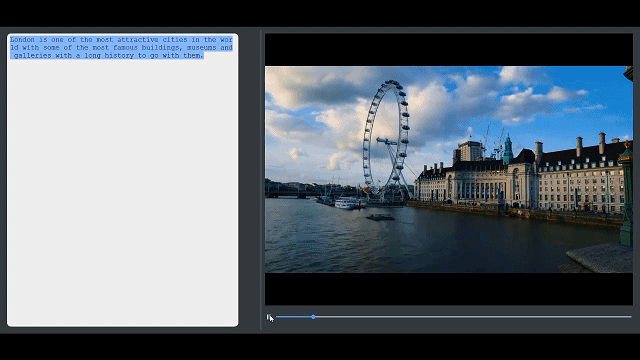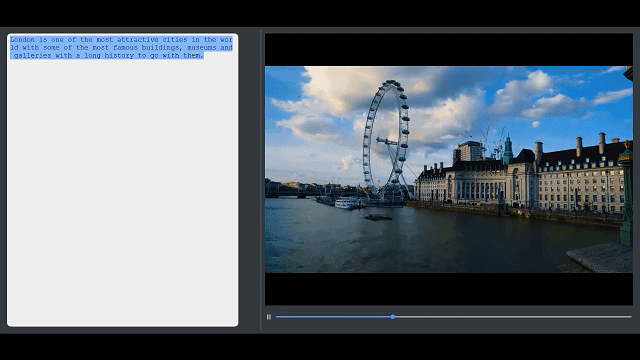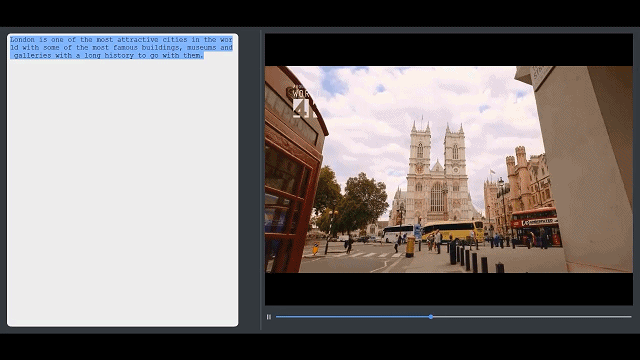
剪辑过程分为三个步骤:(1)用户提供输入,大部分时候是编辑文本;(2)系统自动搜寻视频库中语义匹配的镜头;(3)拼接视频。分割文本和镜头之间的视觉-语义匹配是通过级联关键词匹配和视觉-语义嵌入来实现的,比其他解决方案准确率要高。考虑到时间限制,视频重组被定义为对镜头、摄像机运动和色调等电影技术指标以及用户指定的电影技术习惯用法(cinematographic idiom)的混合优化。
![]()
「Write-A-Video 利用了当前自动视频理解的先进技术和独特的用户界面,可以生成更加自然、简单的视频剪辑效果,」赫兹利亚跨学科研究中心的教授 Ariel Shamir 表示。「使用我们的工具,用户能够以文本编辑的方式提供输入。该工具可以从视频库中自动搜索语义匹配的候选镜头,然后使用优化方法,通过自动裁剪和镜头重排来组合视频蒙太奇。」
现为北航虚拟现实技术与系统国家重点实验室助理研究员及硕士生导师的王淼博士说道:「Write-A-Video 可以使用户通过电影技术习惯用法探索每个场景的视觉风格,以此来加快或减缓视频节奏、增加或减少动作内容等。」
![]()
此外,当从视频库中选取候选镜头时,Write-A-Video 会兼顾镜头的美学效果,自动选择那些灯光、聚焦良好以及清晰稳定的镜头。来自清华大学的胡事民教授说道:「在任何时间点上,用户都可以借助旁白叙事来渲染视频和预览视频剪辑效果」。
在众多视频网站中,「观看某位明星镜头」的选项已经出现一段时间了,最近有关自动剪辑的研究看起来又将自动化提高了一大步。这样的技术,什么时候会进入实用阶段呢?
项目链接:
http://www.faculty.idc.ac.il/arik/site/writeVideo.asp
参考链接:
http://siggraphasia.mystrikingly.com/blog/lights-camera-and-text-novel-video-editing-tool-for-user-friendly?categoryId=129388
机器之心「SOTA模型」:22大领域、127个任务,机器学习 SOTA 研究一网打尽。
![]()