爱奇艺语音转换技术的探索与实践

文章作者:Daniel Chen 爱奇艺
编辑整理:刘一全
内容来源:爱奇艺技术沙龙
出品社区:DataFun
注:欢迎转载,转载请在留言区内留言。
导读:随着语音技术,深度学习技术以及相关硬件的发展,语音技术应用已经逐渐走进大家的日常生活中。语音识别,语音唤醒是大家比较熟悉的两个应用场景,一个比较新的应用场景——语音转换 ( voice conversion ) 也逐渐吸引了研究者的注意力。柯南的变声蝴蝶结要成为现实了!
Voice Conversion ( VC ) 是将一个人的声音转换为另一个音色,而声音内容没有改变。能够应用到爱奇艺的多个业务场景中,给用户带来更有乐趣的体验。Voice Conversion 主要分为基于 parallel 语料和 non-parallel 语料等两类。早期的 VC 方法多为基于 parallel 语料找出 Source 和 Target 的一些映射关系,但是 parallel 语料难以获取限制了这类方法的使用。现有的基于 ASR 的 VC 方法,多基于 PPG 或者 Bottleneck 特征,该类方法多适用于将语音转换为特定音色,无法满足到任意音色的转换。近年来,出现了一些基于 GAN 网络的 VC 方法,试图解决 Many-to-Many 的问题。在本次分享中,主要介绍 VC 的发展历史,常见方法,并结合我们的实际业务需求,介绍爱奇艺在 Voice Conversion 方向的一些探索与实践。
关于 VC 的介绍会围绕下面三点展开:
① 语音转换 ( voice conversion ) 的简介,包括定义及应用场景
② VC 在平行语料及非平行语料两方面的进展
③ VC 未来的发展方向
▌VC ( 语音转换 ) 基础
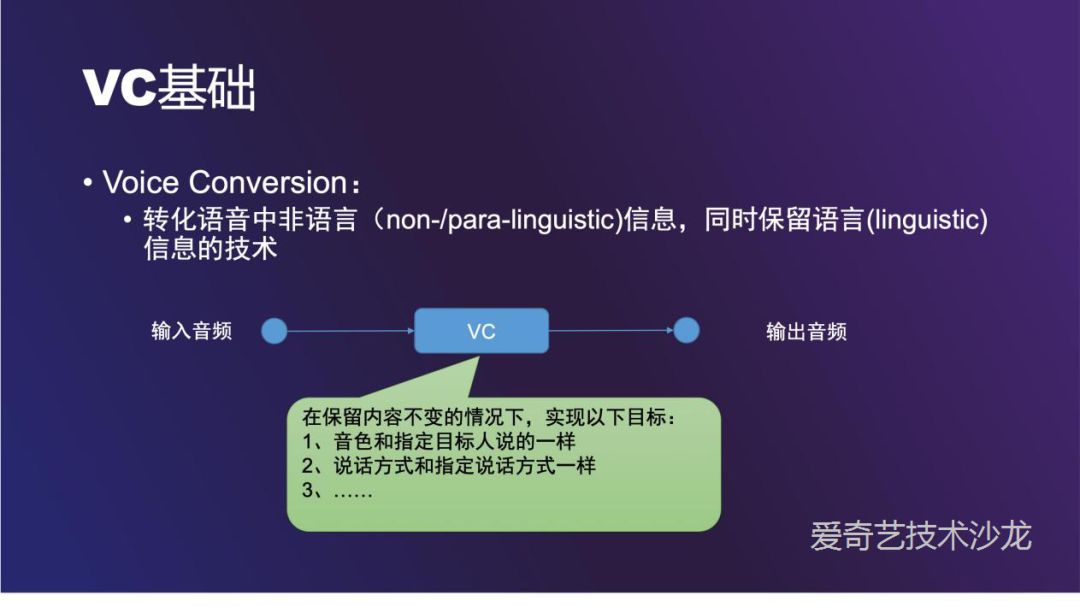
通俗的讲,VC 就是将语音中的文本保留,转换说话人的音色,说话方式等其他信息的技术。

医学是 VC 的一个主要的应用场景,帮助某些发音器官有缺陷的病人发音。在爱奇艺的一个主要应用场景是给电影电视剧做配音,另一个想法是做一些 toC 的娱乐功能。
VC 技术潜在的危害是可能会被不法分子用来做一些欺诈行为,有一些识别这种欺诈行为的比赛。
▌VC ( 语音转换 ) 进展

1. 应用方式
在模型层面可以分三类:
One to One:只能把某一个人的声音转换成某另一个人的声音
Many to One:只能把任意人的声音转换成特定某一个人的声音
Many to many:可以把任意人的声音转换成任意人的声音
语料层面可以分两类:
平行语料:两个说话人的录音的文本内容是一致的
非平行语料:两个说话人录音的文本不相同
平行语料相对非平行语料研究的比较早,这种方式实现难度比较低,但是应用限制比较大。
2. 平行语料
首先介绍基于平行语料的 VC:
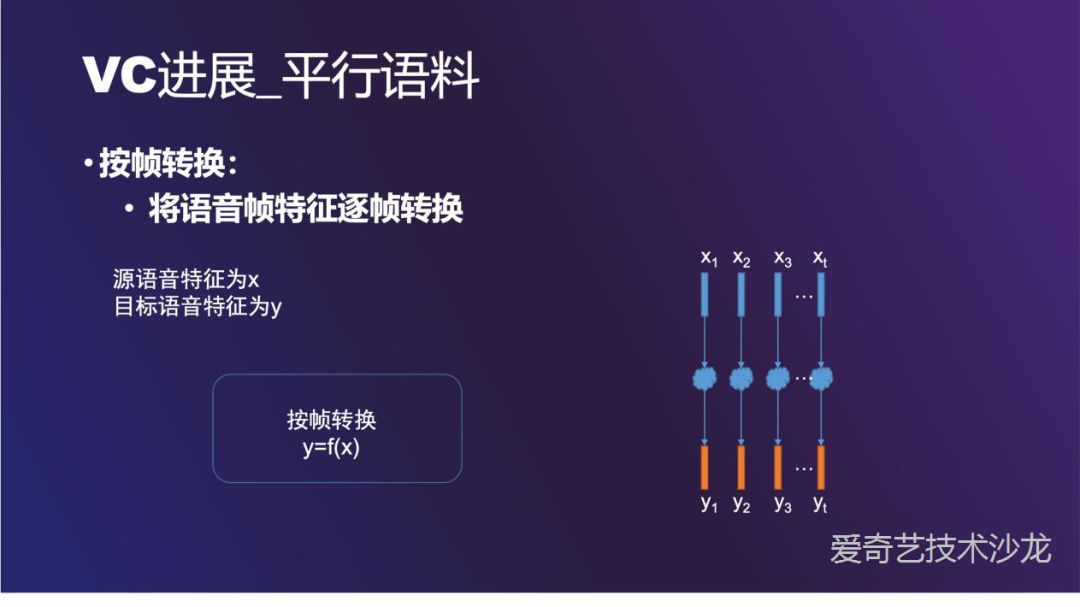
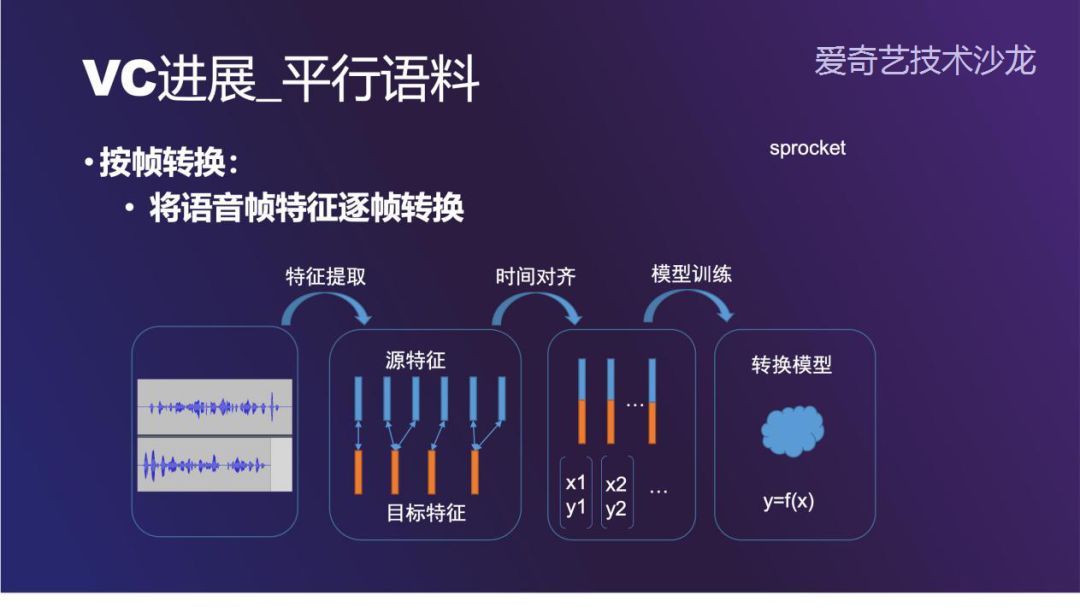
最简单的方法是按帧转换,这种方法的难点在 A 和 B 两个人说同一句的话的时间不一致。整体的流程中,首先提取源语音和目标语音的特征。接下来做时间对齐,最经典的对齐算法是 DTW ( Dynamic Time Warping )。最后使用 GMM 训练转换模型。这一套流程在开源软件 sprocket 中有实现。
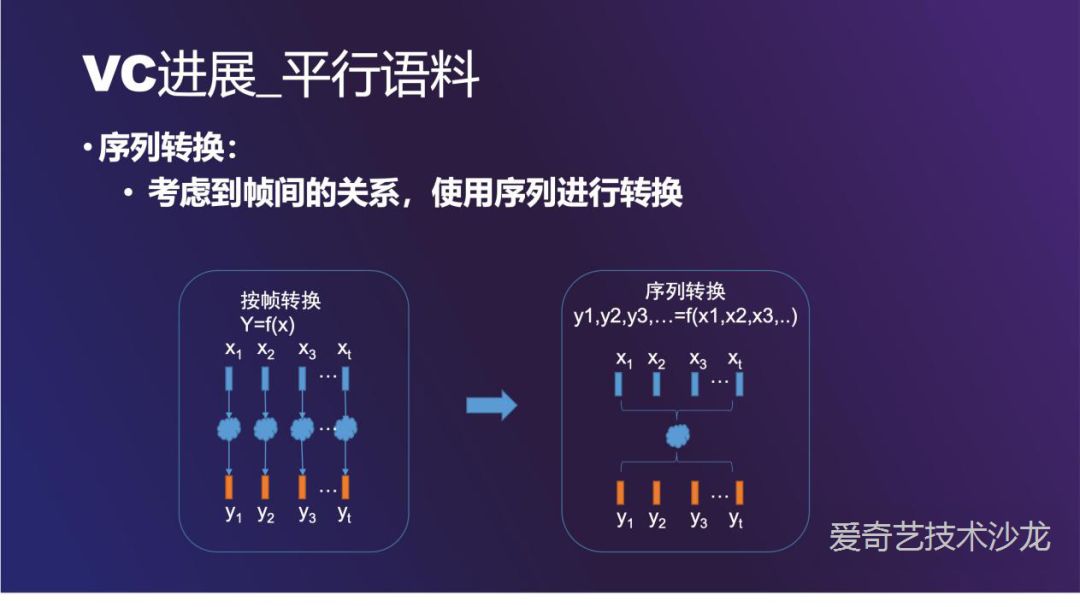
按帧转换这种方法的效果一般,因为有很多信息没有考虑进来。一种更好的方法是考虑到帧与帧之间关系的序列转换方法,比如 x1 和 x2,x3 都有关系。这种思想在语音识别 ( ASR ) 和语音合成 ( TTS ) 中都有应用。

序列转换中最经典的算法是极大似然参数生成算法 ( MLPG ),由于结合了静态特征和动态特征,转换的效果会更好。MLPG 算法同样在 sprocket 中有实现。
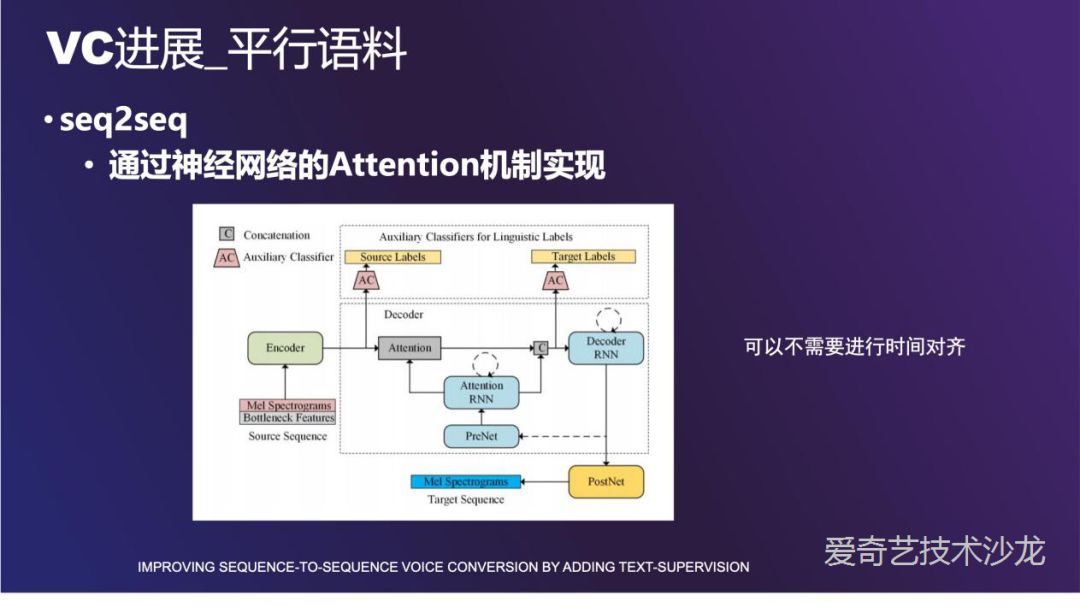
最后要介绍的基于平行语料的方法是 seq2seq。因为运用了神经网络的 attention 机制,源语音和目标语音时间长度不一致的问题可以被解决。
图中展示的框架是讯飞一篇论文介绍的方法。输入是 mel 频谱和 bottleneck 特征,Encoder 编码之后送给一个音素判别器。Attention 机制保证源序列和目标序列对齐的准确性。
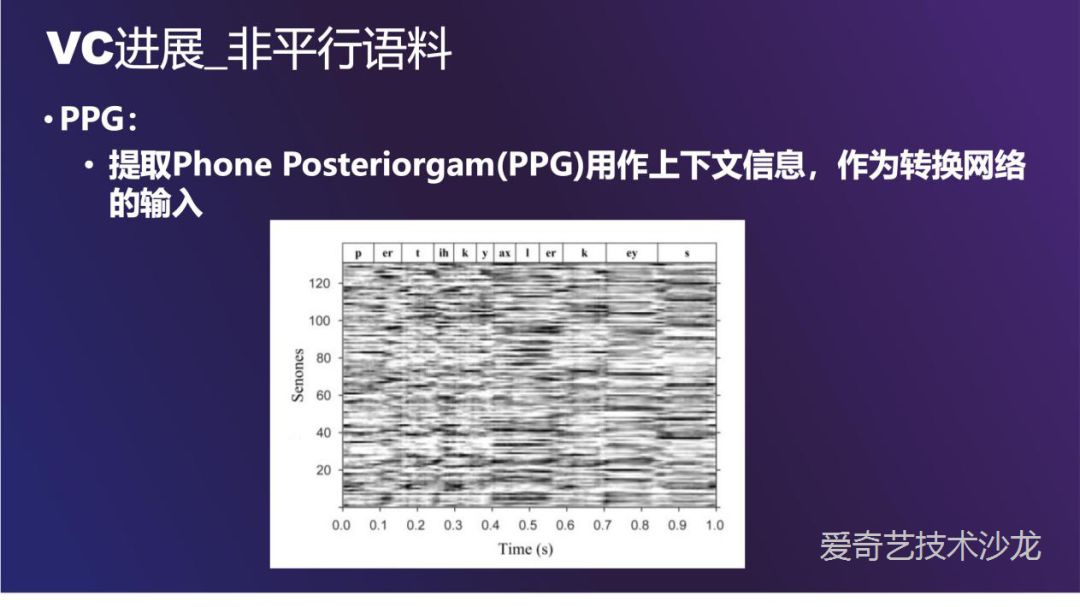
非平行语料方法中比较经典的是 PPG ( 后验概率图 )。图的上面是语音的内容,下面是时间轴,纵轴是 senone,是考虑更复杂的上下文关系的多元音素,中间线的深浅表示概率大小。
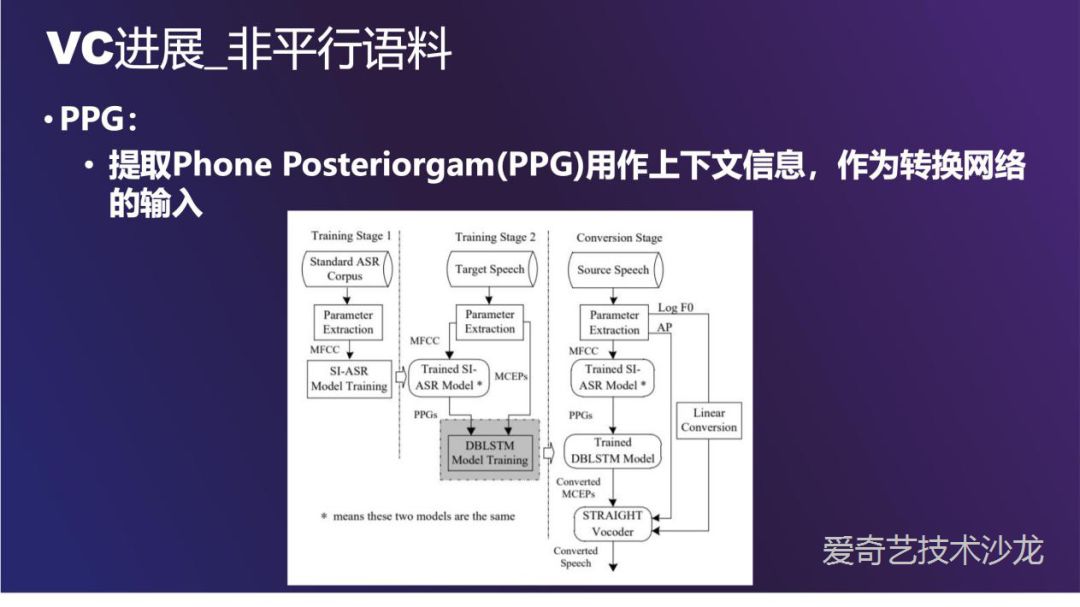
训练过程的第一阶段是训练一个说话人无关的 ASR 模型。第二阶段的转换网络是一个比较深的 LSTM,输入是 ASR 识别网络产出的 PPG,目标是 mel 参数。最后交给声码器做合成,原始文章中使用的声码器是 STRAIGHT。

PPG 方法中,ASR 去掉了原始说话人的信息,在转换网络中重新加入目标人信息。
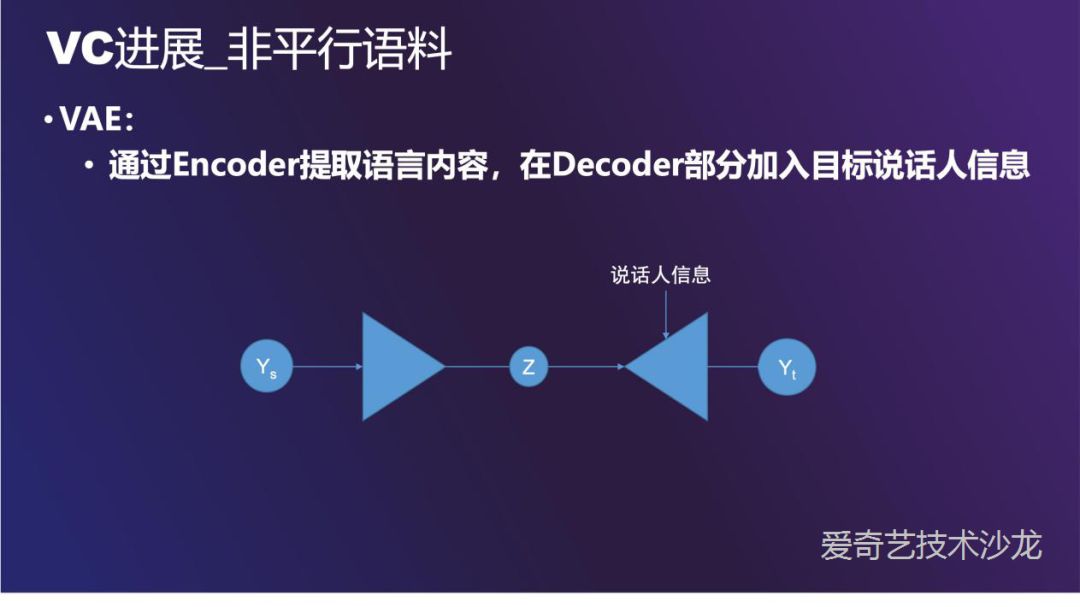
VAE ( Variational Autoencoder ) 的思路也适合来做 VC。通过 Encoder 网络把语音压缩成隐变量,如果 Encoder 足够好,隐变量不含有目标说话人的信息,最后在 Decoder 部分加入目标说话人信息,可以使得产生的语音符合目标说话人的特征,也不丢失源说话人的韵律,说话方式等信息。
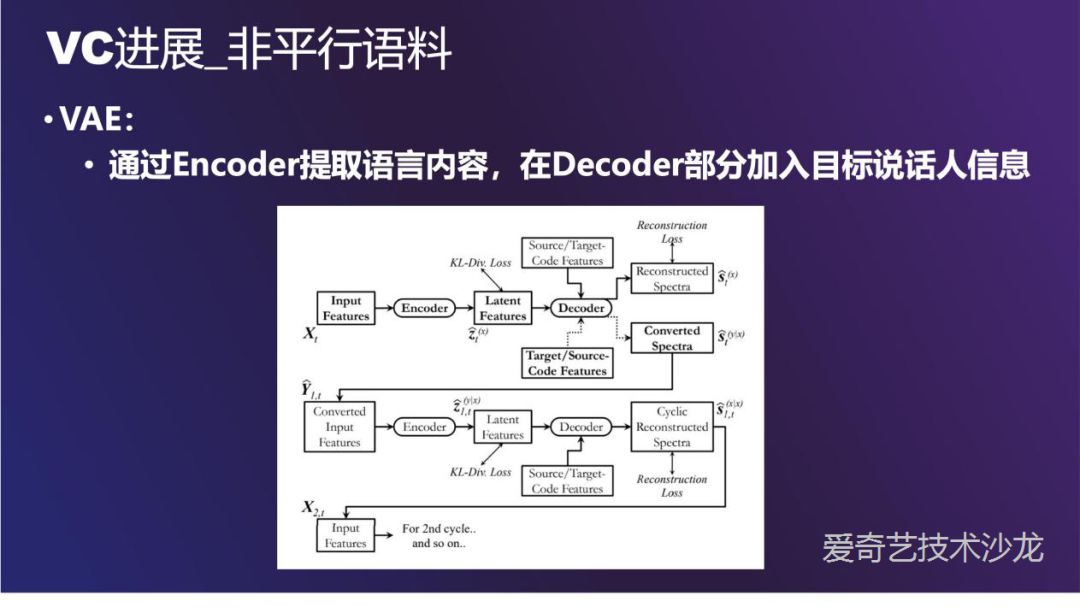
这是一个典型的 VAE 系统,上面是一个条件 VAE,把源语音的特征编码成隐变量,加入说话人特征,最后交给 Decoder 解码。特殊之处在把重建以后的语音再送给 VAE 形成循环,使得 Encoder 部分丢失的信息更少。

Blow 是一个比较新的工作,和 normalization flow 有一些共通之处。这个网络的特点是,输入 x 和隐变量 z 是通过一系列可逆变换 f1 <-> fk 得到的。
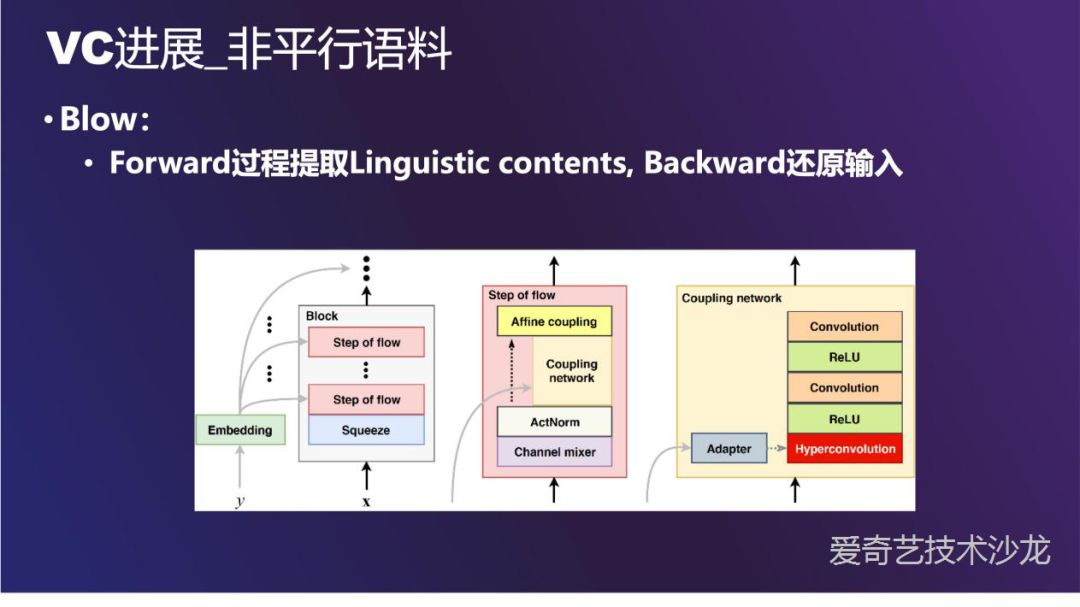
这个特性可以让我们做这样一件事情,x 是源说话人的语音,经过一系列可逆变换 f 得到了隐变量 z,之后逆向传播回来。此时把 y 换成目标人的信息y',还原回来的 x' 就是目标说话人的语音了。
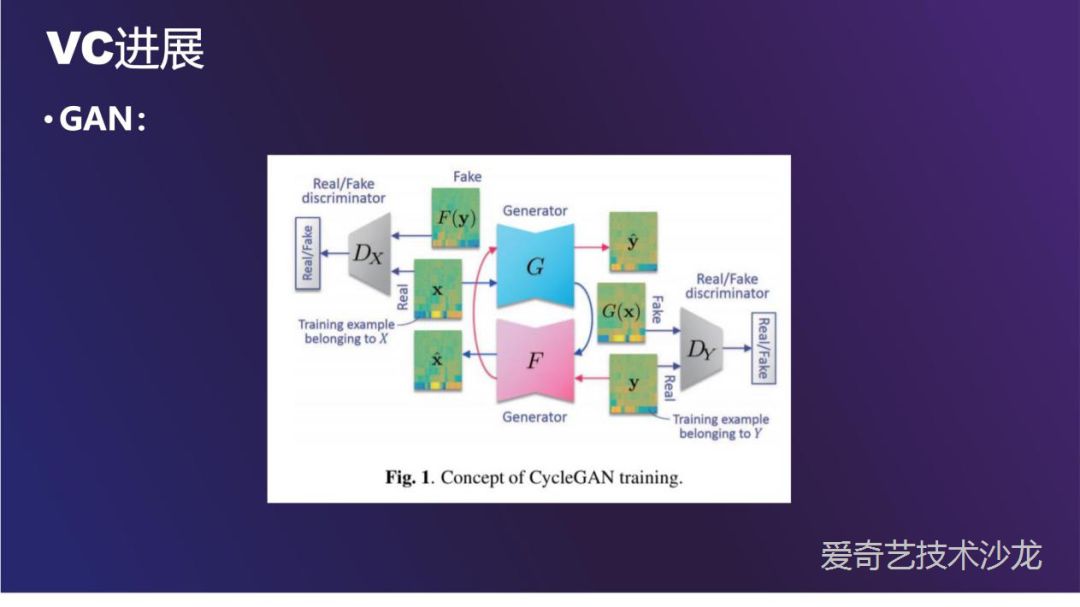
GAN 可以应用于平行或者非平行语料。最经典的两种结构是 CycleGAN 和 StarGAN,其中 StarGAN 是引入了更多的条件,可以做 many to many。这里只介绍一下 CycleGAN。
GAN 最基本的结构是一个生成器一个判别器。这里的 cycle 是指生成器有两个,第一个 G 生成器用 x 生成 y,第二个 F 生成器把 y 还原回 x,目的是保证 y 中有足够多的信息使得 y 可以还原回 x。这样形成了一个循环,所以叫 cycleGAN。
▌VC ( 语音转换 )方向

在爱奇艺的实际应用中,为了降低对使用者的限制,我们使用 many to one 或者 many to many 的方案。韵律信息在日常说话场景下表现的不明显,但是在朗诵和清唱的场景下,VC 的效果做起来难度大很多。另外还尝试过加入 Prosody Encoder,pitch contour 和数据增强来降低噪声的干扰。
▌QA 环节
Q:有没有好的方法来区分声音是否是 VC 生成的?
A:可以关注下这个比赛:
https://www.asvspoof.org/
Q:用 VC 来扩充 ASR 的训练数据?
A:可能会有一些效果,不建议用太多。VC转换出来的都比较同质,数量太多意义不是很大。
Q:跨语种的 VC 能否保留说话人的节奏?
A:VC 对语种的限制不大,并不会改变原始语料中的韵律信息。一个应用场景是给影片中的大牌明星做配音,解决方案是找专业的播音员录音,再转换成明星的声音。
Q:请问 TTS ( 谷歌的 AI 打电话 ) 的现状和未来发展方向?
A:TTS 目前的韵律做的还比较简单,谷歌的 AI 打电话成功率也不是很高,因为还涉及 NLP、NLU 等很复杂的东西。如果对韵律和情感 ( 表达出说话人的喜怒哀乐 ) 要求不高,和真人还是很接近的。


Daniel Chen
——END——
延伸阅读:





