学界 | Jeff Dean等人提出ENAS:通过参数共享实现高效的神经架构搜索
选自arXiv
机器之心编译
参与:黄小天、刘晓坤
本文提出超越神经架构搜索(NAS)的高效神经架构搜索(ENAS),这是一种经济的自动化模型设计方法,通过强制所有子模型共享权重从而提升了NAS的效率,克服了NAS算力成本巨大且耗时的缺陷,GPU运算时间缩短了1000倍以上。在Penn Treebank数据集上,ENAS实现了55.8的测试困惑度;在CIFAR-10数据集上,其测试误差达到了2.89%,与NASNet不相上下(2.65%的测试误差)。
1. 简介
神经架构搜索(NAS)已成功用来设计图像分类和语言建模模型架构 (Zoph & Le, 2017; Zoph et al., 2018; Cai et al., 2018; Liu et al., 2017; 2018)。在 NAS 中,RNN 控制器进行循环训练:控制器首先采样候选架构,即一个子模型(child model),接着训练它收敛以测量其在所需任务上的表现。控制器接着把子模型表现作为指导信号以发现更好的架构。这一过程需要重复迭代很多次。尽管其实证表现令人印象深刻,NAS 的算力成本巨大且耗时,比如 Zoph et al. (2018) 使用 450 块 GPUs 耗时 3-4 天(即 32,400-43,200 GPU 小时)。同时,使用的资源越少,所得结果的竞争力就越小 (Negrinho & Gordon, 2017; Baker et al., 2017a)。我们发现 NAS 的计算瓶颈是训练每个子模型至收敛,只测量其精确度同时摈弃所有已训练的权重。
本文研究做出的主要贡献是通过强制所有子模型共享权重而提升了 NAS 的效率。这个想法明显存在争议,因为不同的子模型利用权重的方式也不同,但本文受到先前迁移学习和多任务学习工作的启发,即已确定一个特定任务的特定模型所学习的参数可用在其他任务的其他模型之上,几乎无需做出修改(Razavian et al., 2014; Zoph et al., 2016; Luong et al., 2016)。
研究者证明,不仅子模型之间共享参数是可能的,而且表现也很出色。尤其在 CIFAR-10 上,他们的方法取得了 2.89% 的测试误差,相比之下 NAS 为 2.65%。在 Penn Treebank 上,他们的方法实现了 55.8 的测试困惑度,明显优于 NAS 62.4 的测试困惑度 (Zoph & Le, 2017),这是 Penn Treebank 在不使用后训练处理的方法中所实现的一个新的当前最优结果。重要的是,在本研究所有使用单个 Nvidia GTX 1080Ti GPU 的实验中,搜索架构的时间都少于 16 小时。相较于 NAS,GPU 运算时间缩短了 1000 倍以上。鉴于其高效率,我们把这一方法命名为高效神经架构搜索(ENAS)。
2. 方法
ENAS 思想的核心是观察到 NAS 最终迭代的所有图可以看作更大图的子图。换句话说,我们可以使用单个有向无环图(DAG)来表征 NAS 的搜索空间。图 2 是一个通用实例 DAG,其架构可通过采用 DAG 的子图而实现。直观讲,ENAS 的 DAG 是 NAS 搜索空间之中所有可能的子模型的叠加,其中节点表征局部计算,边缘表征信息流。每一个节点的局部计算有其自己的参数,这些参数只有当特定计算被激活时才使用。因此在搜索空间中,ENAS 的设计允许参数在所有子模型(即架构)之间共享。
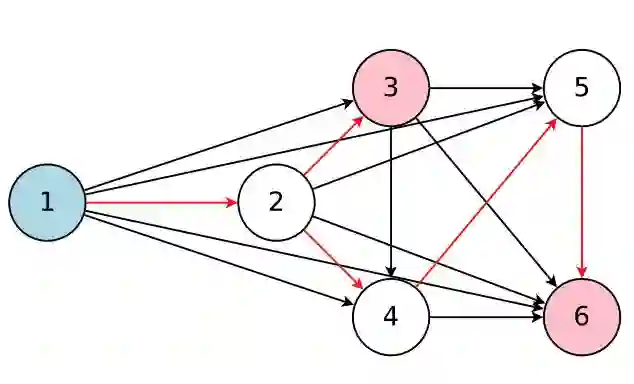
图 2:该图表征了整个搜索空间,同时红箭头定义了其中一个由控制器决定的模型。这里,节点 1 是模型的输入,节点 3 和 6 是模型的输出。
2.1 设计循环单元
为了设计循环单元,作者使用了有 N 个结点的有向无环图(DAG),其中每个节点代表局部运算,而每条边代表 N 个节点中的信息流。ENAS 的控制器是一个 RNN,它会控制:1)哪一条边处于激活状态;2)在 DAG 中的每一个结点会执行哪些运算。

图 1:搜索空间中带有四个计算节点的循环单元案例。左图为对应循环单元的计算 DAG,其中红色的边代表图中的信息流。中间为循环单元。右图为 RNN 控制器的输出结果,它将会生成中间的循环单元和左边的 DAG。注意节点 3 和 4 永远不会被 RNN 采样,所以它们结果是平均值,且可以作为单元的输出。
2.3 设计卷积网络
在卷积网络的搜索空间中,RNN 控制器在每一个决策模块上会制定两组决策:1)前一个单元需要连接什么;2)它需要什么样的运算过程。这些决策共同构建了卷积网络中的不同层级。
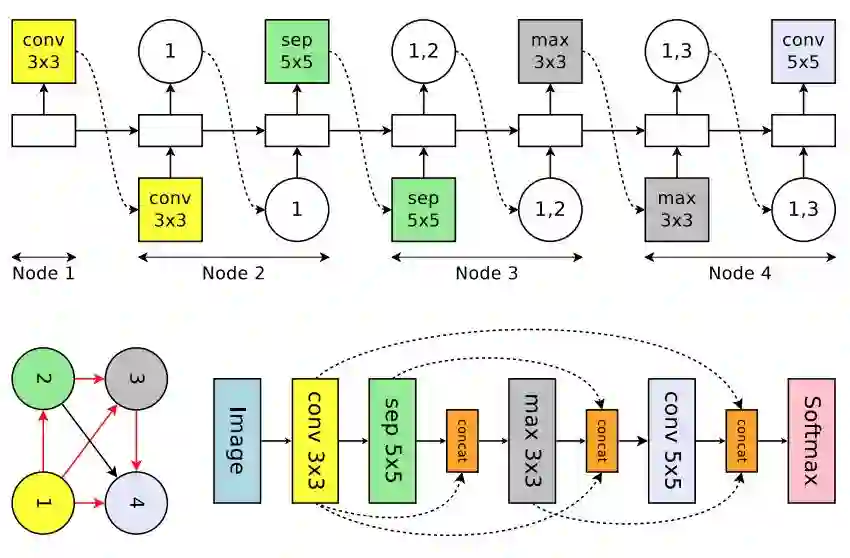
图 3:搜索空间中一个循环单元的实例运行,该空间带有 4 个计算节点,表征卷积网络的 4 个层。顶部:控制器 RNN 的输出。左下:对应于网络架构的计算 DAG。红箭头表征激活的计算路径。右下:完整的网络。虚线箭头表征跳跃连接。
2.4 设计卷积单元
本文并没有采用直接设计完整的卷积网络的方法,而是先设计小型的模块然后将模块连接以构建完整的网络(Zoph et al., 2018)。图 4 展示了这种设计的例子,其中设计了卷积单元和 reduction cell。接下来将讨论如何利用 ENAS 搜索由这些单元组成的架构。
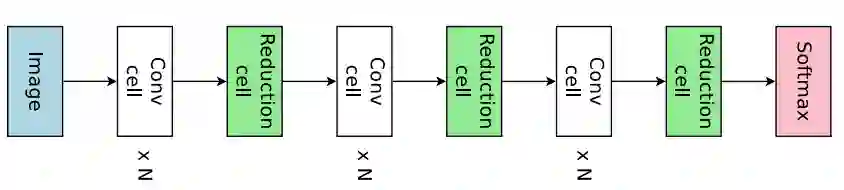
图 4:连接卷积单元和 reduction 单元,以构建完整的网络。
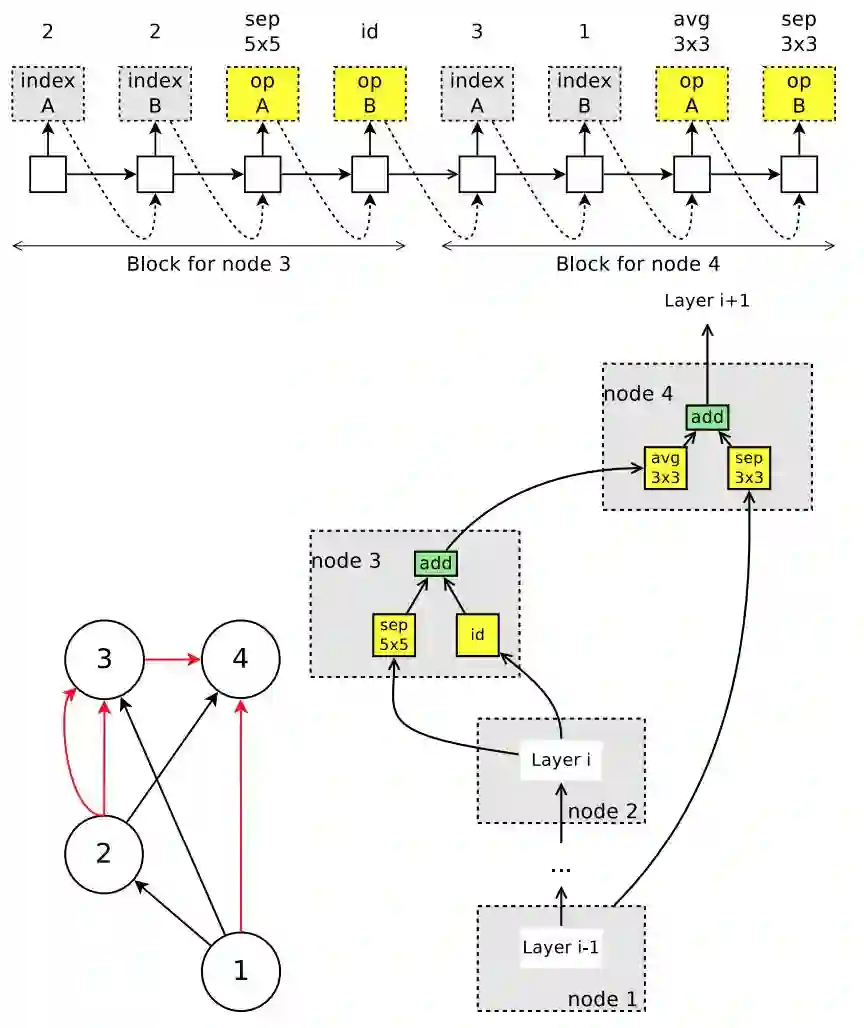
图 5:控制器在卷积单元搜索空间中运行的示例。上:控制器的输出。在卷积单元的搜索空间中,节点 1 和节点 2 是单元的输入,因此控制器只需要设计节点 3 和节点 4。左下:对应的 DAG,其中红边代表激活的连接。右下:由控制器采样得到的卷积单元。
3 实验
3.1 在 Penn Treebank 数据集上训练的语言模型
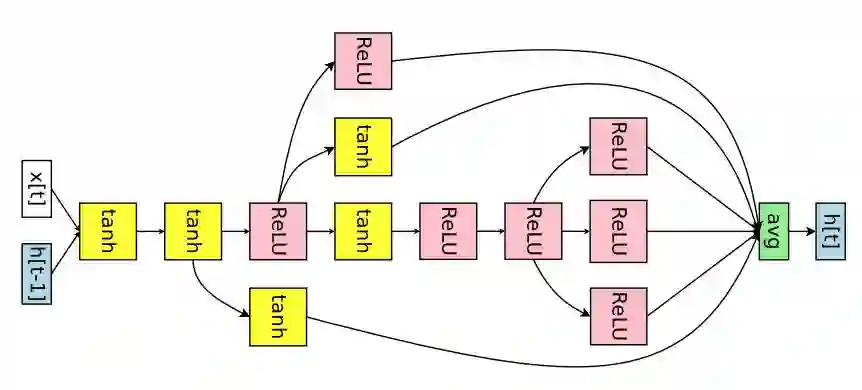
图 6:ENAS 为 Penn Treebank 数据集发现的 RNN 单元。
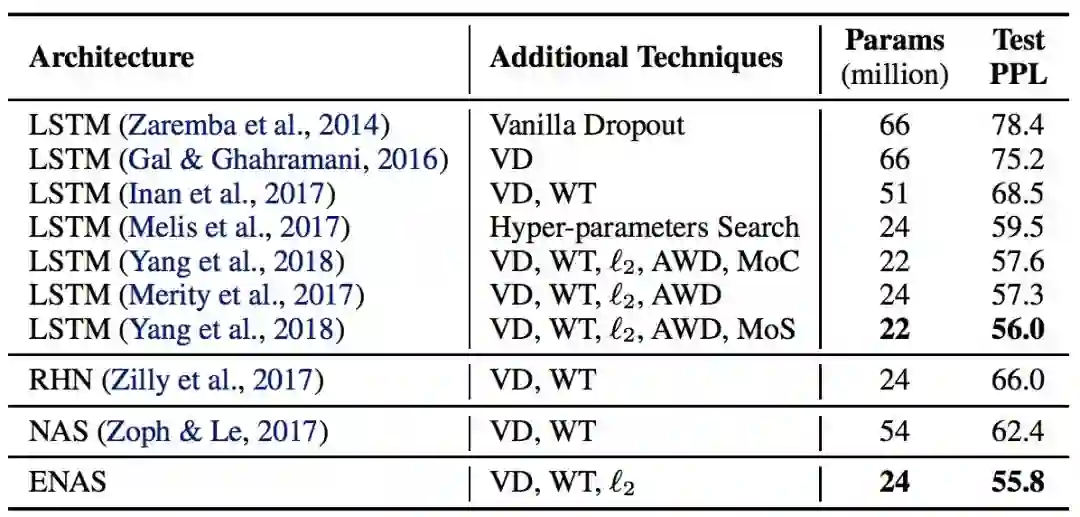
表 1:ENAS 为 Penn Treebank 数据集发现的架构的测试困惑度以及其它的基线结果的比较。(缩写说明:RHN 是 Recurrent Highway Network、VD 是 Variational Dropout、WT 是 Weight Tying、ℓ2 是 Weight Penalty、AWD 是 Averaged Weight Drop、MoC 是 Mixture of Contexts、MoS 是 Mixture of Softmaxes。)
3.2 在 CIFAR-10 数据集上的图像分类实验
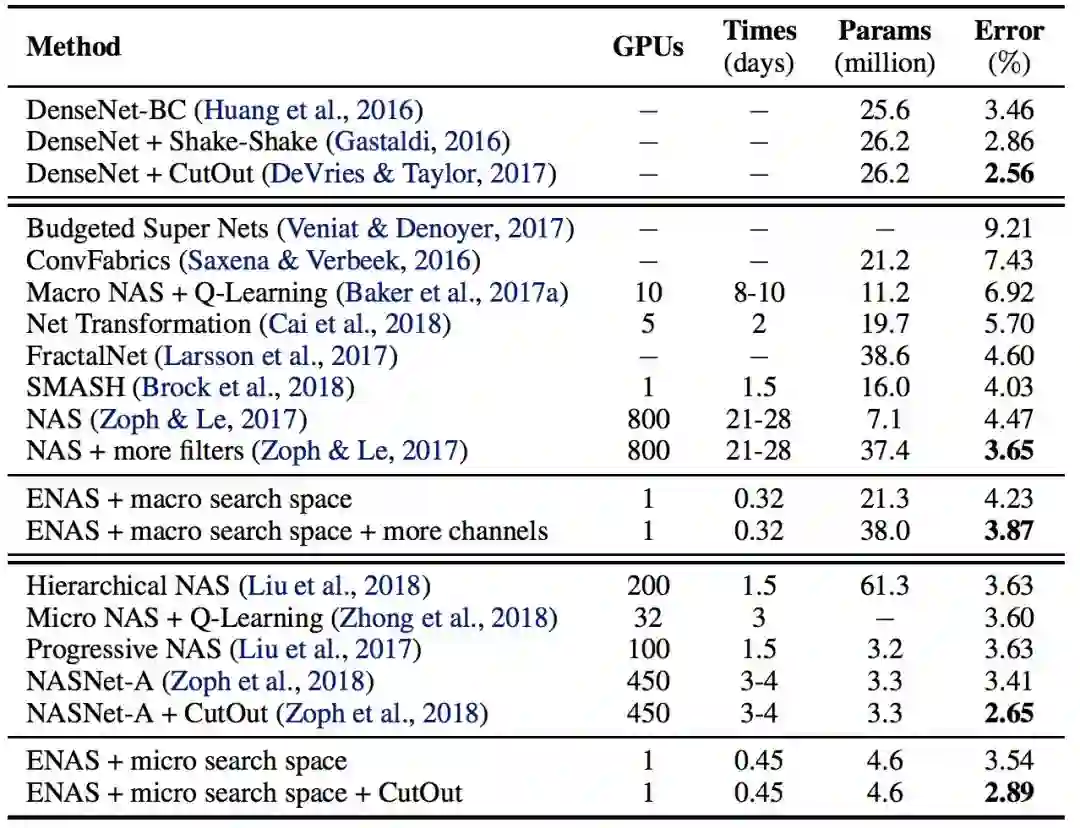
表 2:ENAS 发现的架构在 CIFAR-10 数据集上的分类误差和其它基线结果的对比。在这个表中,第一块展示了 DenseNet,由人类专家设计的当前最佳架构。第二块展示了设计整个网络的方法。最后一块展示了设计模块单元以构建大型模型的技术。
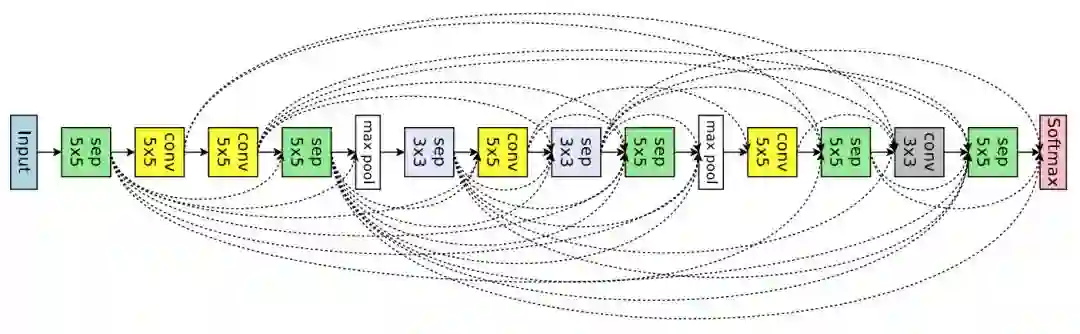
图 7:ENAS 从大型搜索空间中发现的用于图像分类的网络架构。
ENAS 用了 11.5 个小时来发现合适的卷积单元和 reduction 单元,如图 8 所示。
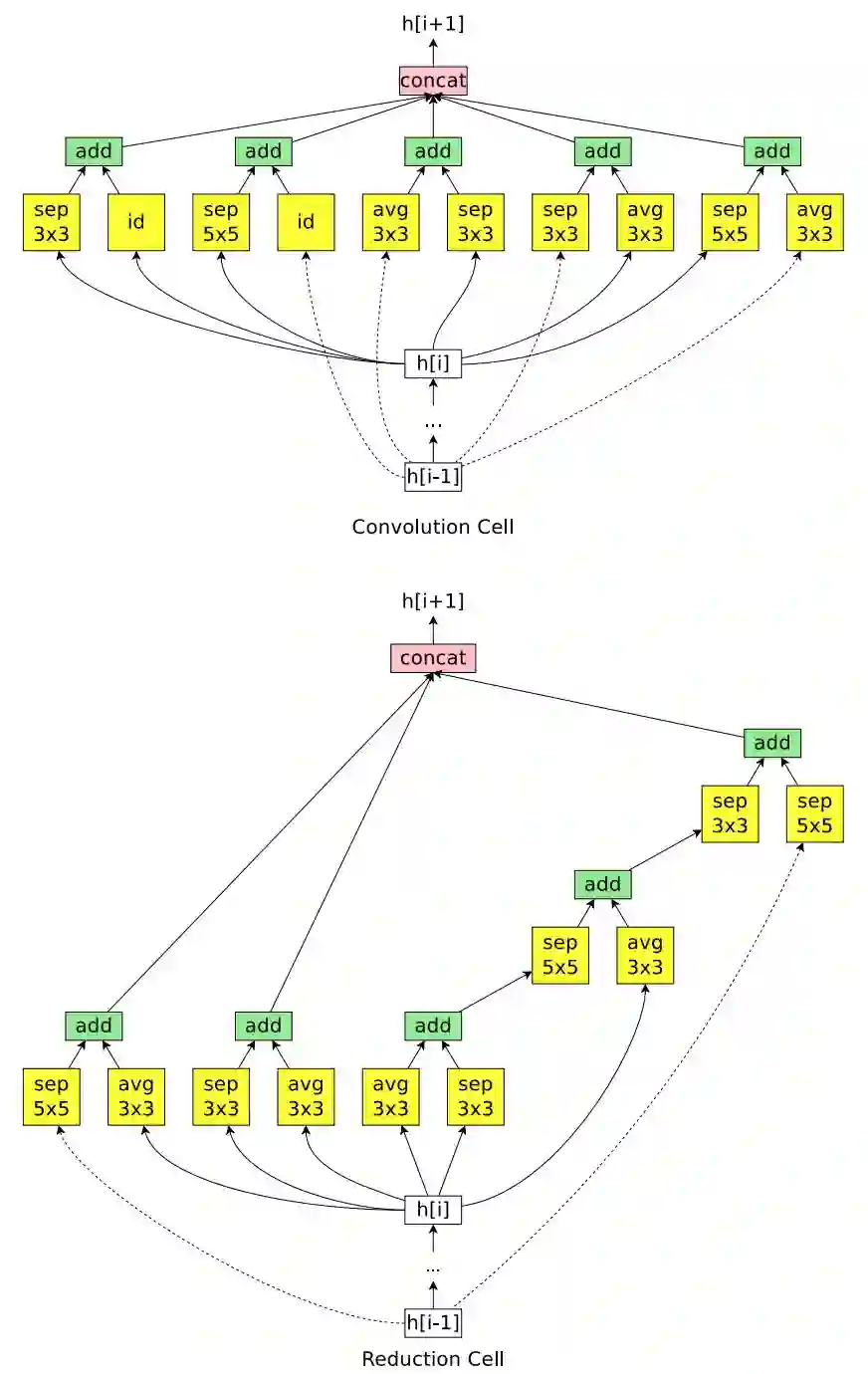
图 8:ENAS 在微搜索空间中挖掘新的单元。
论文:Efficient Neural Architecture Search via Parameters Sharing

论文链接:https://arxiv.org/abs/1802.03268
我们在本文中提出高效神经架构搜索(ENAS),这是一种高效和经济的自动化模型设计的方法。在 ENAS 中,有一个控制器通过在一个大型计算图中搜索一个最优的子图以学习发现最优神经网络架构的方法。控制器采用策略梯度进行训练,以选择最大化验证集期望奖励的子图。同时,和所选子图对应的模型将进行训练以最小化标准交叉熵损失。由于子模型之间的参数共享,ENAS 的速度很快:它只需要使用少得多的 GPU 运算时间就能达到比当前的自动化模型设计方法好很多的经验性能,尤其是,其计算成本只有标准的神经架构搜索(NAS)的千分之一。在 Penn Treebank 数据集上,ENAS 发现了一个新颖的架构,其达到了 55.8 的测试困惑度,这是未经后处理而达到当前最佳性能的新方法。在 CIFAR-10 数据集上,ENAS 设计了一个新颖的架构,其测试误差达到了 2.89%,与 NASNet(Zoph et al., 2018)不相上下(2.65% 的测试误差)。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论
