转载来自新智元
事实检验算法旨在利用现有知识库来检验文本的事实正确性。
目前,事实验证的方法通常是将问题拆解为两个步骤:检索阶段(retrieval)和验证阶段(verification)。
在检索阶段,检索模型根据给定的陈述文本(claim)从知识库中检索得到相关的文本描述,作为用于验证最终结果的证据(evidence);在验证阶段,验证模型则会根据检索到的证据来推理得出最终的预测结果。
然而,大多数现有模型通常只是给出最终分类结果,缺乏对一个陈述正确与否的解释,导致我们很难知道模型为何做出了这样的预测。这对于构建值得信任的人工智能应用是十分有害的。
为了解决事实检验中的可解释性问题,字节跳动人工智能实验室和复旦大学的团队提出了 LOREN ,一种全新的可解释事实检验范式:将针对整个陈述的验证拆解为短语级别的验证。
Paper: https://www.zhuanzhi.ai/paper/ef84397cfe7e6ec8e906d047895d1564
Code: https://github.com/jiangjiechen/LOREN
在该范式下,模型能够给出整个陈述的细粒度验证结果,从而以更直观的方式帮助大家了解模型推理过程,也能够更快地锁定事实错误。
LOREN的主要思想是将句子级别(sentence-level)的验证拆解为短语级别(phrase-level的验证。
针对给定的陈述
以及证据集
组成的输入
,模型需要在得到最终预测结果
的同时,给出陈述中所有短语
的验证结果
,其中
,
分别表示符合事实 (Supports),不符合事实 (Refutes) 和无法验证 (Not Enough Information)。
定义隐变量
为所有短语的预测结果,显然最终的预测结果
依赖于每个短语的预测结果
,因此可以将最终的预测结果用概率表示为:。
在给定输入数据
对应的标签
后,可以得到整个模型的优化目标:
。
该问题的一种解法是使用 EM 算法,然而
的真实后验分布
很难求解(intractable)。
因此,利用变分推断(variational inference)的方法,通过引入一个变分后验分布
,将问题转化为优化对应的变分下界目标函数——negative Evidence Lower BOund(ELBO):
为了得到短语验证结果的先验分布
,作者借鉴了自然语言推理(Natural Language Inference,NLI)的工作,将 NLI 中的
,
和
标签分别对应到
。
借助在 NLI 数据上预训练好的预训练模型,就可以计算得到先验分布
。
本工作中最大的挑战在于:现有的数据并不支持短语粒度的学习,因为没有(也不可能有)短语的事实正确性
标注结果。
针对这个问题,作者提出并利用了事实检验问题中天然存在的一套逻辑聚合规则来提供弱监督信号来帮助学习
,并事实上将其转化为最终标签与短语级别标签之间的一种逻辑约束。
可以观察到以下逻辑规则:
如果一个陈述是不符合事实的(REF),那么其中至少存在一个短语不符合事实;
如果一个陈述是符合事实的(SUP),那么其中所有短语都应该符合事实;
如果一个陈述是无法验证的(NEI),那么应该不存在不符合事实的短语,并且其中至少一个短语是无法验证的。
这样通过概率聚合得到的结果
就包含了上述的逻辑知识。作者将其作为老师模型 (teacher model) 去指导
,即进行逻辑知识蒸馏:。
找到陈述中需要被验证的短语;
在知识库中找到足以检验这些短语的信息。这些都可以在训练上述验证模型之前离线完成。
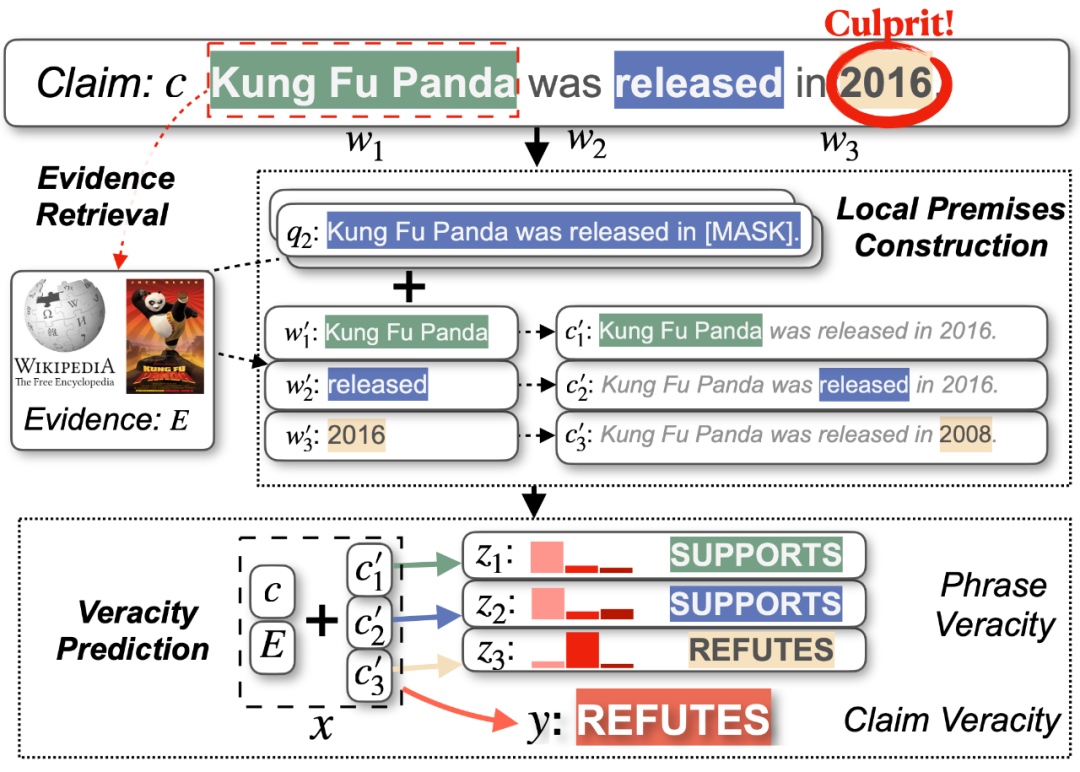
针对第一个问题,作者利用现有的 NLP 解析工具去识别给定陈述中的命名实体,名词短语,动词短语以及形容词短语。例如给定陈述「Kung Fu Panda was released in 2016.」,我们可以将其拆分为「Kung Fu Panda」(命名实体), 「released」(动词短语)以及「2016」(名词短语)。
针对第二个问题,作者将其建模为一种阅读理解 (MRC) 任务。给定陈述和短语,首先对给定的短语构造引导问题,如「Kung Fu Panda was released in [MASK].」和「When was Kung Fu Panda released?」,并利用 MRC 模型从证据集中获取到对应的事实部分,如证据集中存在描述「Kung Fu Panda premiered in the United States on June 6, 2008.」,那么我们希望模型能够回答出「2008」。
将这个事实回填到陈述的对应位置后,就可以得到一个短语对应的局部前提(local premise)
,如「Joe Biden won the 2020 election.」。具体地,利用
的数据去自监督地构造数据并训练这个生成式 MRC 模型。
得到了陈述的局部前提,就可以利用神经网络参数化
和
这两个分布以用于最终的事实验证。
利用预训练语言模型来编码局部信息(陈述与局部前提拼接为
)和全局信息陈述与证据集拼接
),并得到了
与
。
得到全局与局部的信息表示后,分别利用全连接网络来构建最终的
和
:
接收标签
的向量表示和全局信息
与局部信息
作为输入,输出
的预测概率分布。
接收隐变量
与全局与局部信息作为输入,输出
的预测概率分布。在预测阶段,通过随机初始化变量
并迭代地解码
和
直至收敛,至此,就能够在预测最终标签的同时,针对给定陈述中不同的短语进行细粒度的验证。
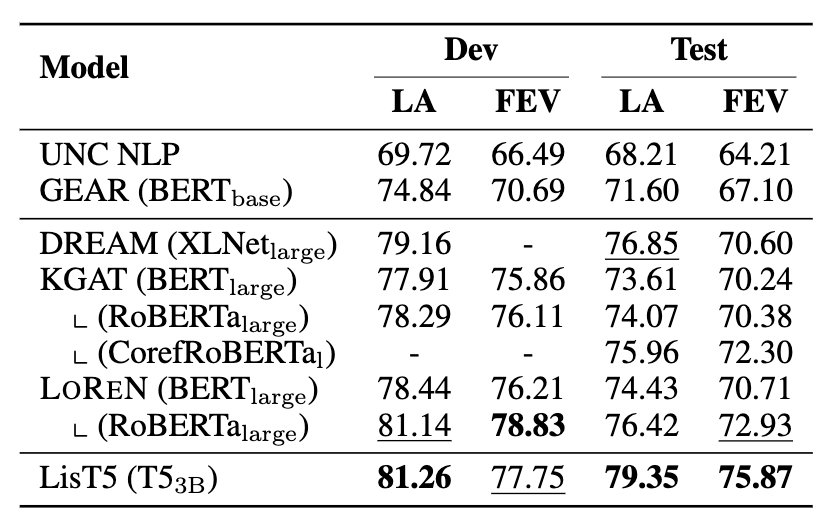
作者在事实验证数据集 FEVER 上开展了实验,并采用官方的 Label Accuracy 以及 Fever score 作为评估指标,整体结果如表1所示。对比 LOREN 与 KGAT[2],可以发现在相同量级的模型下,LOREN 取得了显著的效果提升。
虽然 DREAM[3] 与 LOREN 在检索阶段采用了不同的策略,但是 LOREN 在最终指标上的提升也表明了该框架的优势。然而 LisT5[4] 因为其强大的预训练模型(T5-3B,十倍于RoBERTa-large),在测试集上的效果要明显优于其他模型。
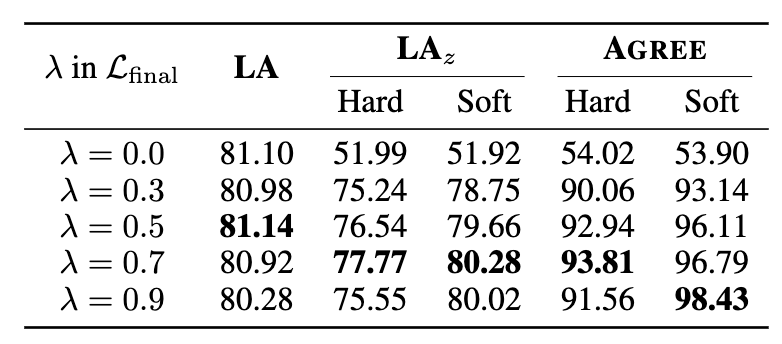
LOREN 最大的优势体现在能够针对短语级别进行验证,而这一特性则是通过引入
实现的,因此作者验证了在不同超参
下 LOREN 的表现,如表2所示。
结果显示,通过 LOREN 框架学习得到的解释既正确又忠实。具体地,
表示利用逻辑聚合得到最终的结果的准确率(accuracy),而
则表示聚合结果与模型最终预测结果之间的一致性(faithfulness)。
可以看到引入逻辑约束之后,模型在
和
上都得到了提升,并且概率软逻辑的聚合方式整体上要优于离散逻辑的聚合方式。
特别地,当
时,短语事实正确性的学习没有了逻辑约束,因此这些中间结果也就失去了意义和可解释性。
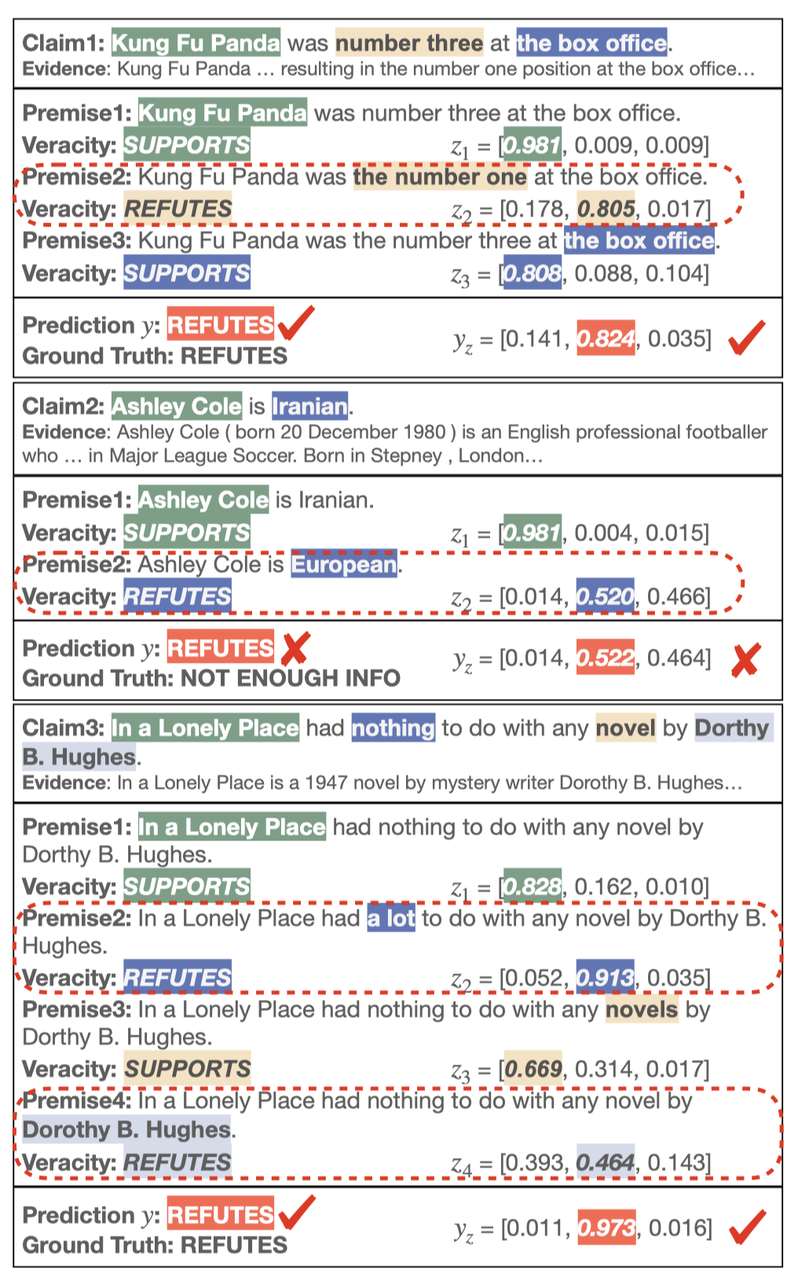
图3展示了 LOREN 的一些验证结果。在第一个例子中,LOREN 能够正确地在给定的陈述中找到错误的短语「number three」并将其纠正为「number one」,并且基于局部的验证结果,LOREN 正确地给出了最终的验证结果。
然而 LOREN 也会在一些缺少充分证据支持的场景下出现错误,如例2的证据只提及了「Ashley Cole」出生于「England」,而没有提及「England」和「Iranian」的关系,因此只能给出
,但是 LOREN 错误地给出了
。例3则表明 LOREN 具备检测包含多个错误的陈述的能力。
本文提出了一种基于短语级别分解的可解释事实检验算法 LOREN。通过利用 MRC 对分解的短语寻找验证信息,并通过聚合逻辑约束短语正确性的学习,使黑盒模型获得了既准确又忠实的解释性。
与此同时,在事实检验基准数据集 FEVER 上的结果说明了 LOREN 模型达到了与相同量级模型更好的结果。
当然,LOREN 也存在许多尚未解决的问题,如常识推理能力、更强的证据检索能力、更一般的陈述分解方法等等。
LOREN 在事实检验领域做出了可解释推理的简单尝试,希望未来出现更多推动模型具备推理能力的研究 (make a system right for the right reasons)。
论文一作陈江捷,复旦大学三年级博士生,复旦大学知识工场实验室成员。主要研究兴趣为自然语言推理与生成。
参考资料:
Jiangjie Chen, Qiaoben Bao, Changzhi Sun, Xinbo Zhang, Hao Zhou, Jiaze Chen, Yanghua Xiao, and Lei Li. "LOREN: Logic Enhanced Neural Reasoning for Fact Verification." AAAI 2022 (pre-print).
Zhenghao Liu, Chenyan Xiong, Maosong Sun, and Zhiyuan Liu. "Fine-grained fact verification with kernel graph attention network." ACL 2020.
Wanjun Zhong, Jingjing Xu, Duyu Tang, Zenan Xu, Nan Duan, Ming Zhou, Jiahai Wang, and Jian Yin. "Reasoning over semantic-level graph for fact checking." ACL 2020.
Jiang, Kelvin, Ronak Pradeep, and Jimmy Lin. "Exploring listwise evidence reasoning with t5 for fact verification." ACL 2021.
专知便捷查看
便捷下载 ,请关注 专知 公众号(点击上方蓝色 专知关注)
专知,专业可信的人工智能知识分发 ,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai ,获取70000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群 ,获取最新AI专业干货知识教程资料和与专家交流咨询 !
点击“
阅读原文
”,了解使用
专知
,查看获取70000+AI主题知识资源