7 Papers | 腾讯王者荣耀绝悟AI;ICLR高分论文Reformer
机器之心整理
作者:杜伟
本周 7 Papers 包含多篇 AAAI 2020、ICLR 2020 入选论文,如腾讯 AI Lab 游戏 AI 研究、提高 Transformer 性能的研究等。
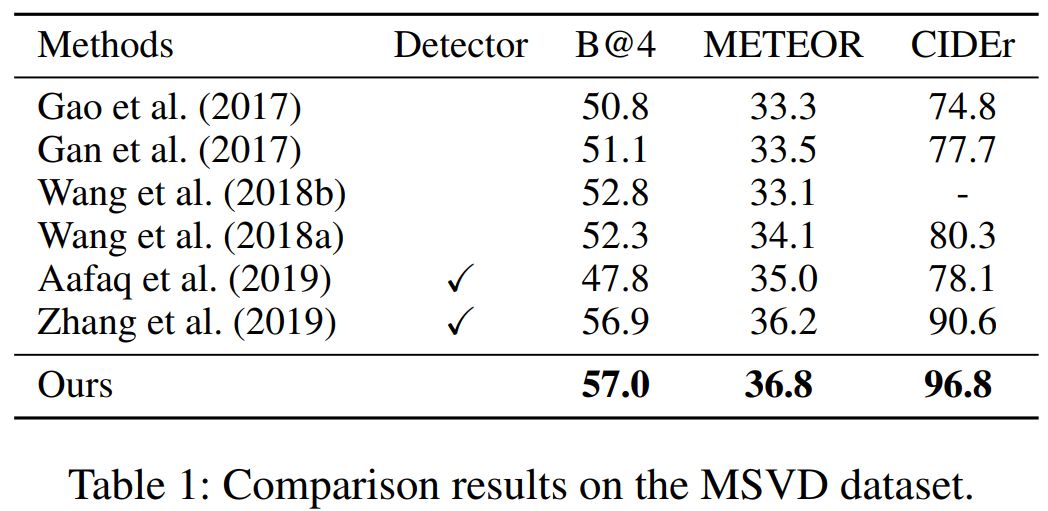
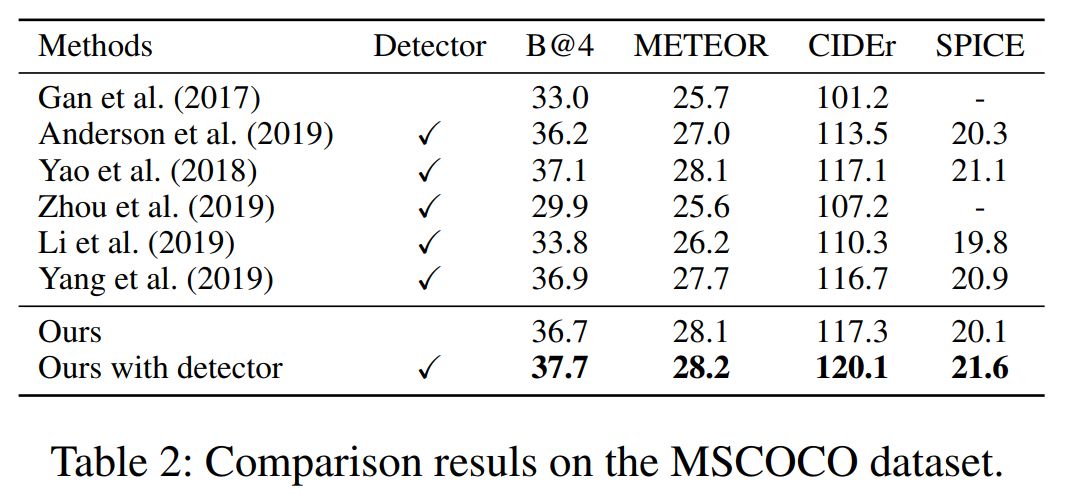
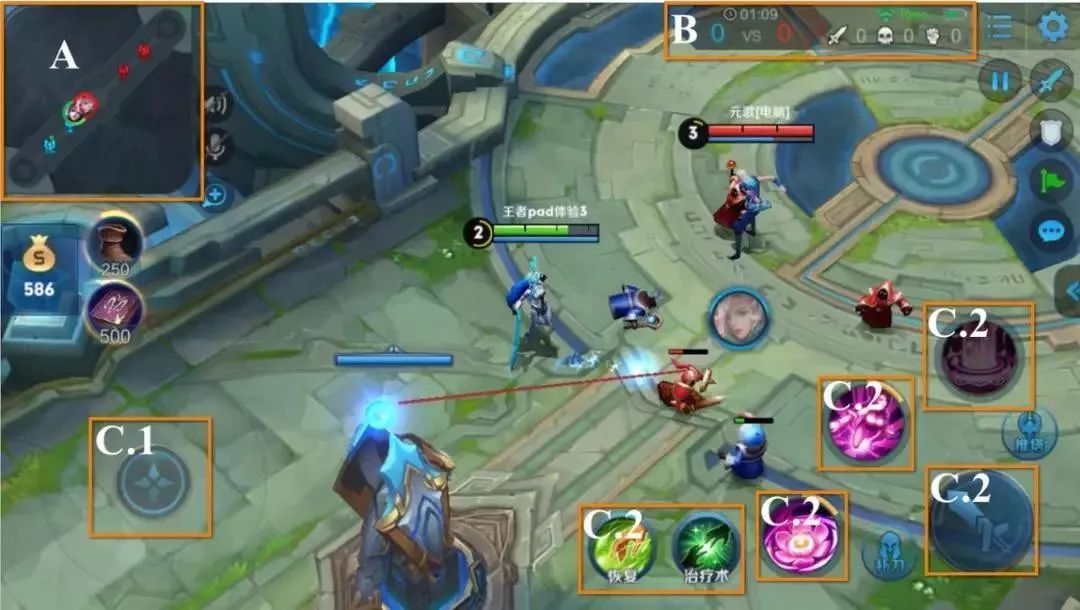
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
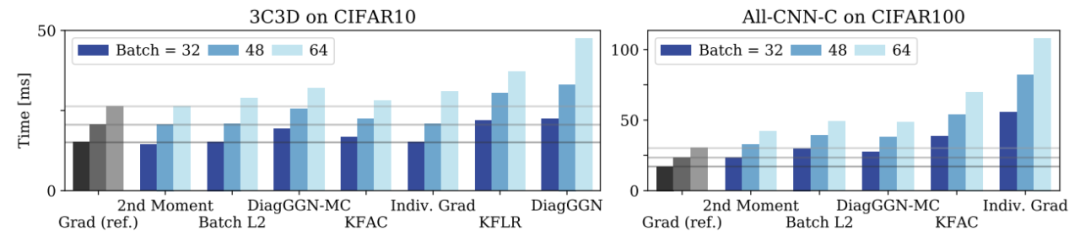
BackPACK: Packing more into backprop
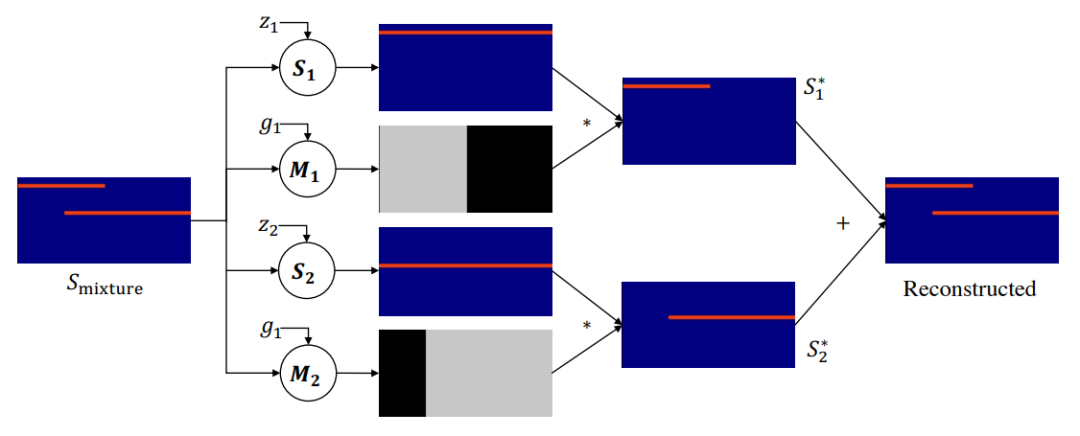
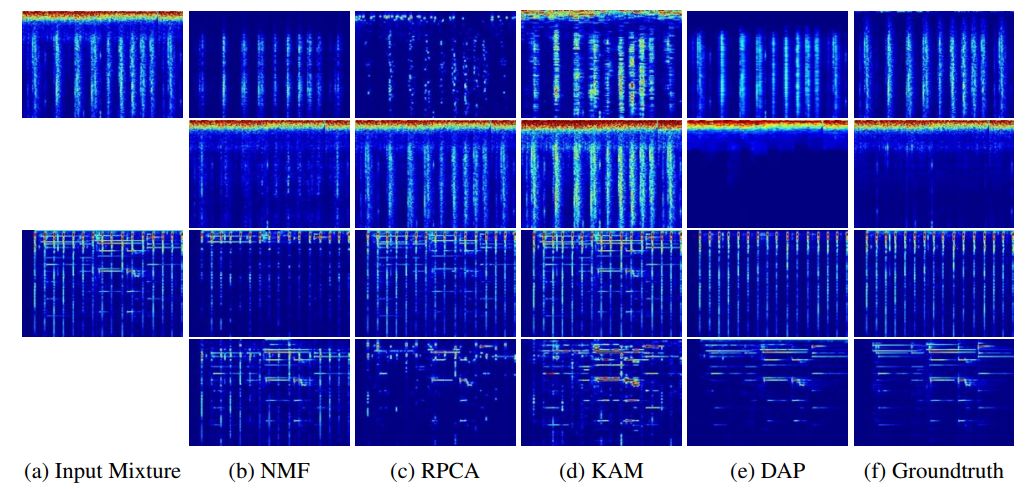
Deep Audio Prior
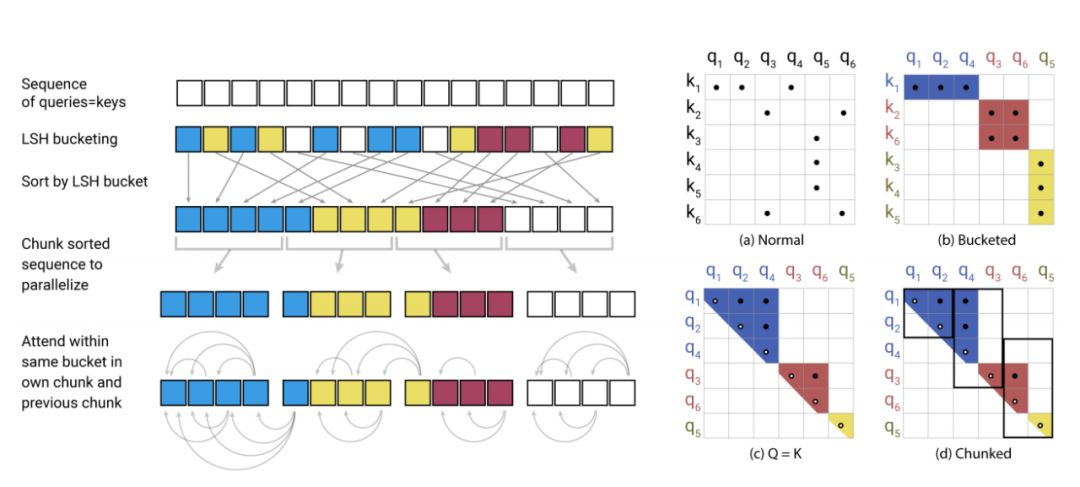
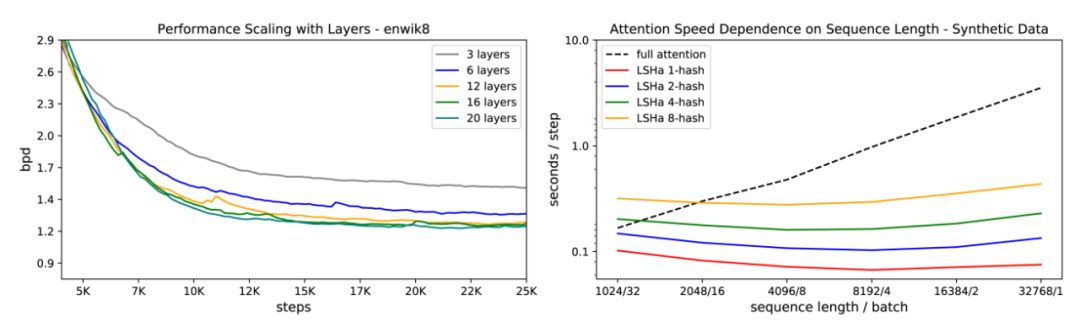
REFORMER: THE EFFICIENT TRANSFORMER
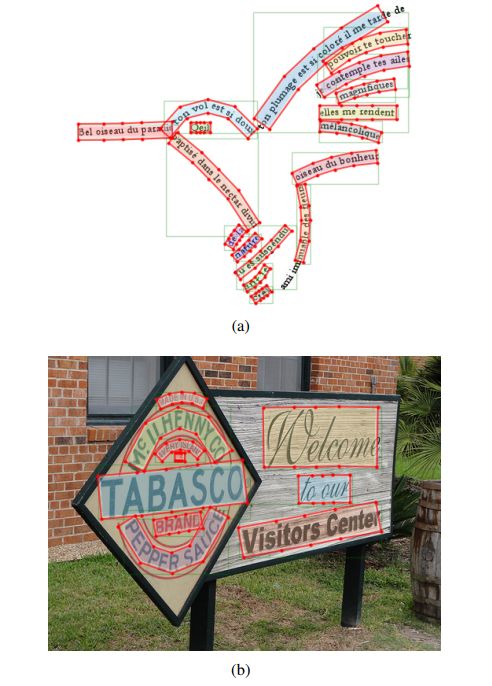
TextTubes for Detecting Curved Text in the Wild
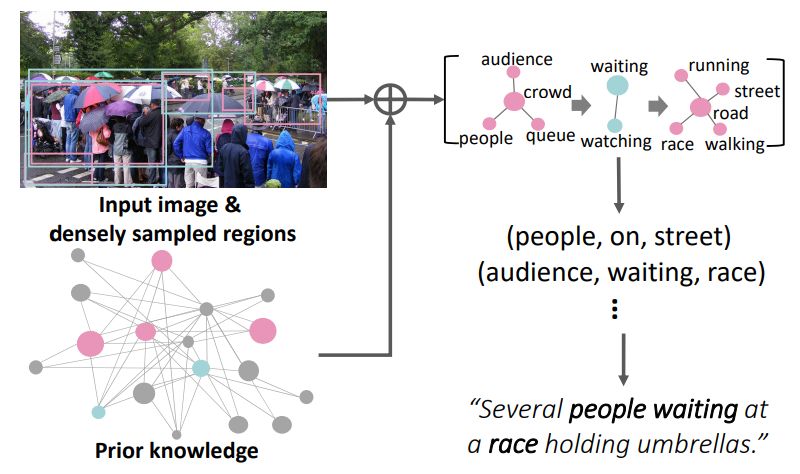
Joint Commonsense and Relation Reasoning for Image and Video Captioning
作者:Deheng Ye、Zhao Liu、Mingfei Sun 等
论文链接:https://arxiv.org/abs/1912.09729
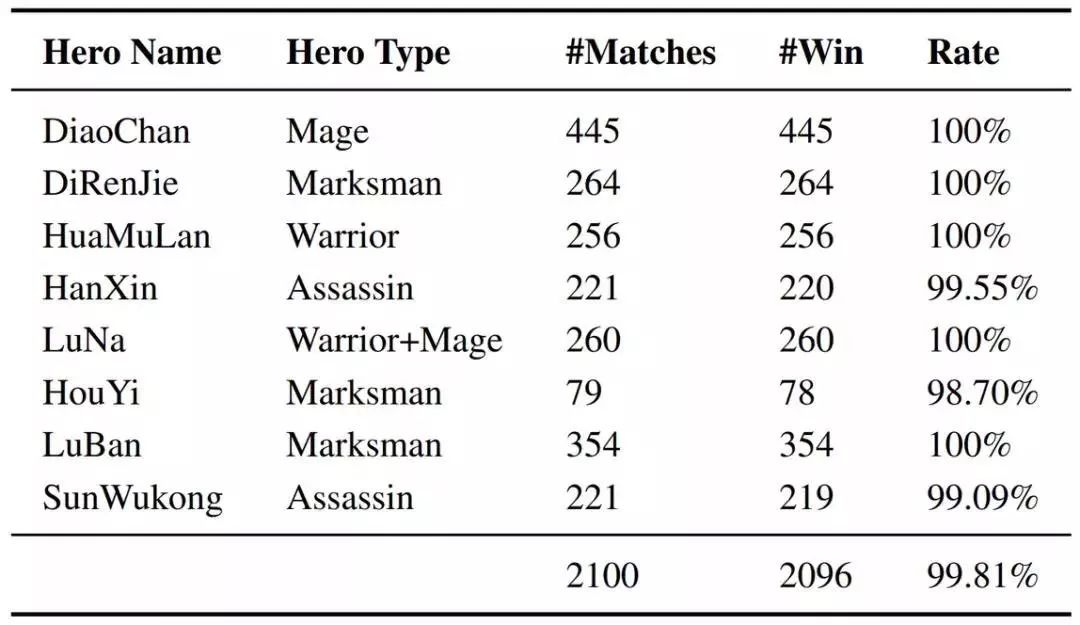
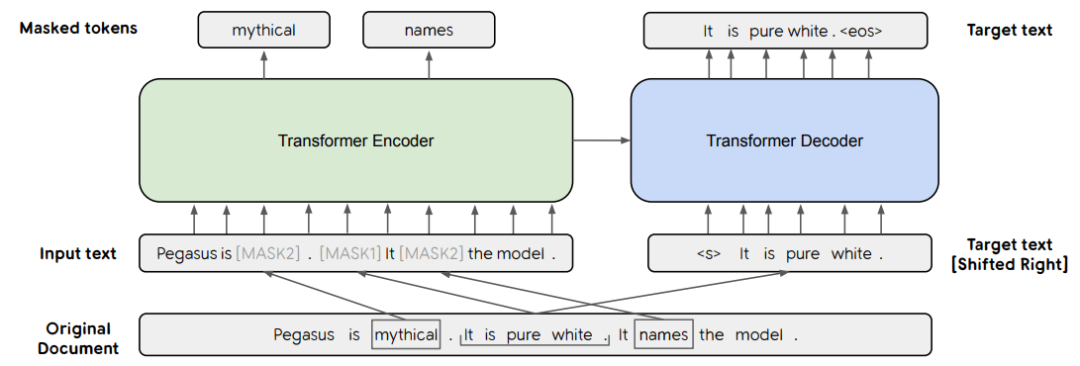
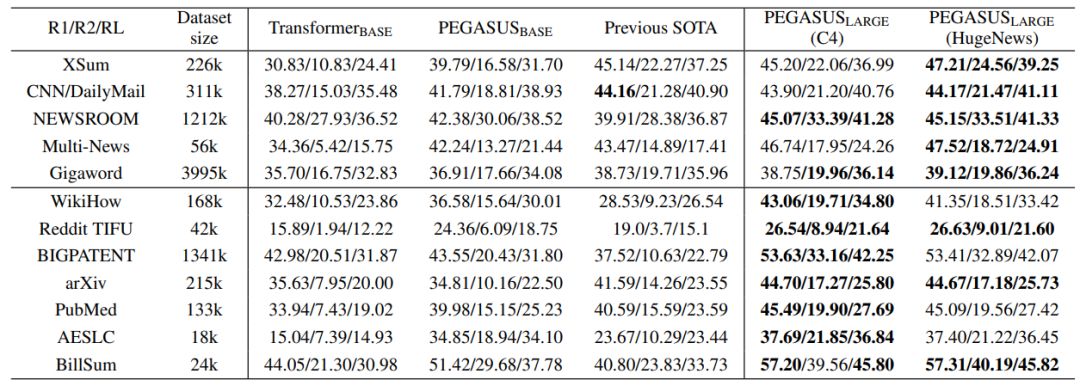
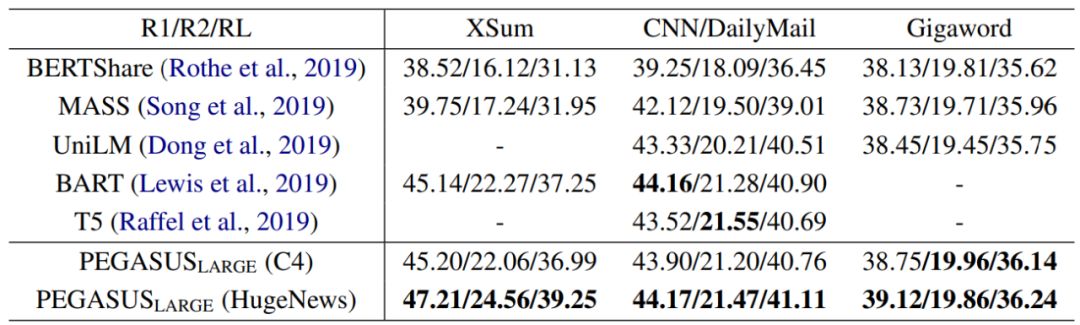
作者:Jingqing Zhang、Yao Zhao、Mohammad Saleh、Peter J. Liu
论文链接:https://arxiv.org/pdf/1912.08777.pdf
作者:Felix Dangel、Frederik Kunstner、Philipp Hennig
论文链接:https://arxiv.org/abs/1912.10985

作者:Yapeng Tian、Chenliang Xu、Dingzeyu Li
论文链接:https://arxiv.org/abs/1912.10292
作者:Nikita Kitaev、Lukasz Kaiser、Anselm Levskaya
论文链接:https://openreview.net/pdf?id=rkgNKkHtvB
作者:Joel Seytre、Jon Wu、Alessandro Achille
论文链接:https://arxiv.org/pdf/1912.08990.pdf

作者:Jingyi Hou、Xinxiao Wu、Xiaoxun Zhang 等
论文链接:https://wuxinxiao.github.io/assets/papers/2020/C-R_reasoning.pdf