清华大学柯沛:闲聊对话中的句式控制 | AI研习社65期大讲堂
AI 科技评论按:在闲聊对话领域,对话策略研究是近几年的热门话题,实现对话策略需要引入一些要素,让聊天机器人变得更加拟人化,以便能跟用户更好地交互。来自清华大学的柯沛认为,日常对话中的句式可以直接反映一个人的对话目的,通过引入句式控制,聊天机器人将能生成优质的回复——不仅句式受控,还包含了丰富的信息量。
在近日的 AI 研习社大讲堂上,柯沛给我们介绍了这项具有开创性的研究成果。
公开课回放地址:
http://www.mooc.ai/open/course/527
分享主题:闲聊对话中的句式控制
分享提纲:
从对话策略分析句式控制的缘由
基于条件变分自编码器的对话生成模型
生成质量的自动评价和人工评测
未来工作及展望
AI 科技评论将其分享内容整理如下:
很高兴能有机会跟大家分享我们的工作,我叫柯沛,是清华大学计算机系的在读博士生,研究方向是自然语言处理,主要关注自然语言生成和对话系统。
今天分享的是我们今年发表在 ACL 上的一个工作,研究的是闲聊对话中的句式控制问题。首先,我会从对话策略讲起,跟大家谈谈闲聊对话主要会涉及哪些问题,再结合句式控制的任务介绍我们所使用的模型,然后通过机器评测和人工评测说明模型的效果,同时给出一些对话示例,最后总结我们的工作和未来的发展方向。
我们先来讲一下对话策略的问题。闲聊对话与任务型对话有本质上的区别,闲聊对话最大的特点是涉猎的话题较广泛,什么都能聊。目前闲聊对话做得比较好的产品是微软小冰,只要有足够的耐心和它聊,对话就会一直持续下去。

在闲聊对话领域,对话策略研究是近几年的热门话题,实现对话策略需要引入一些要素,让聊天机器人变得更加拟人化,能够跟用户更好地交互。比如我们实验室所做的一个工作:通过引入情绪因素,让聊天机器人可以生成带有不同情绪的回复,提高用户的聊天体验。我们实验室还试图将人物设定赋予聊天机器人,让聊天体验变得更有意思。
我们这篇文章着重要谈的是句式(Sentence Function)问题,在我们看来,日常对话中的句式可以直接反映一个人的对话目的,所以我们总结出了常见的 3 种句式类型:
第一种类型是疑问句,在双方都不熟悉的情况下,如果我想认识你,可能就会更多使用疑问句,通过提问来获取更多关于你的信息。
第二种类型是祈使句,主要用于发出请求或者邀请,类似的回复我们一律称为祈使句,祈使句一般可以促进更深层次的交互。
第三种类型是平时用得比较频繁的陈述句,从语气上来讲比较平淡,主要用于陈述事实或者解释原因。
在进一步展开我们文章的话题前,需要跟大家理清几个近义词,Sentence Function 被我们暂译为「句式」,根据 Sentence Function 可以把所有的句子划分成多种 Sentence Type,比如我们目前考虑的 3 种 Sentence Type:疑问句、祈使句和陈述句。然而单就疑问句而言,其实还包含很多种细分的模式,比如一般疑问句和特殊疑问句,这说明同一类型的句子中也可能存在多种不同的 Sentence Pattern。
既然我们说句式可以反映一个人的说话目的,那么引入句式因素,是否就能有效提高聊天机器人的交互性呢?
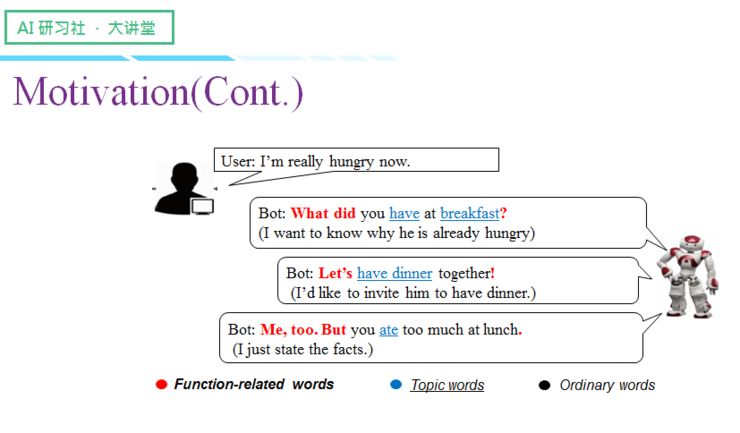
这里我们给了一个例子,用户说我现在饿了,聊天机器人则可以根据不同的对话目的,给出不同句式类型的回复。
如果机器人想知道用户为什么饿了,那么他会提问:你早餐吃的什么呀?
如果机器人想向用户发出邀请/请求,就会使用祈使句:那我们一起吃晚饭吧!
当然,机器人也可以选择比较平稳的回复,这时会选择陈述句:我也饿了,可你在午饭时候吃了很多。
为了赋予机器人生成不同句式的回复的能力,我们的工作在生成过程中规划了句式控制词、话题词以及普通词的生成位置,以达到理想的生成效果。

我们的工作涉及到可控对话生成和可控文本生成的任务,也就是说给定一个属性值,生成的语言必须和这个属性值相匹配,目前学界做的较多的是跟情绪相关的研究,比如设定一个情绪「喜欢」,聊天机器人自动生成各种与「喜欢」属性相匹配的对话内容;还有一种更加粗线条的情感极性,主要分为「正向情感」和「负向情感」。另外还有一种与英语时态相关。还有人研究对话意图,让生成的对话能够符合事先设定的对话意图。也有人做「风格」相关的一些研究工作,不过这方面更多集中在图像领域,比如说风格迁移,就语言领域的研究来讲,这块还是处于比较初级的阶段(比如把对话风格统一调整为「男性」)。
以上这 5 类工作是近几年比较热门的研究方向。
回到我们的工作,我们首先会输入用户请求以及设定的句式类型,模型会生成一个回复——这个回复不仅在语义上要与用户的请求对应,并且还要与设置的句式类别相匹配。
完成这项任务会面临两个比较大的挑战:第一个是涉及到对生成过程的全局控制,比如生成一个疑问句,开头可能是个疑问词,中间还涉及到一些助动词,最后可能还要考虑标点符号的因素;第二个挑战在于如何平衡句式控制与信息量兼容性的问题,毕竟生成结果中如果不能包含丰富的信息量,句式控制得再完美也会影响到对话体验。
基于条件变分自编码器的对话生成模型
接下来我会给大家介绍我们的模型,看看我们是如何解决以上两个挑战的。
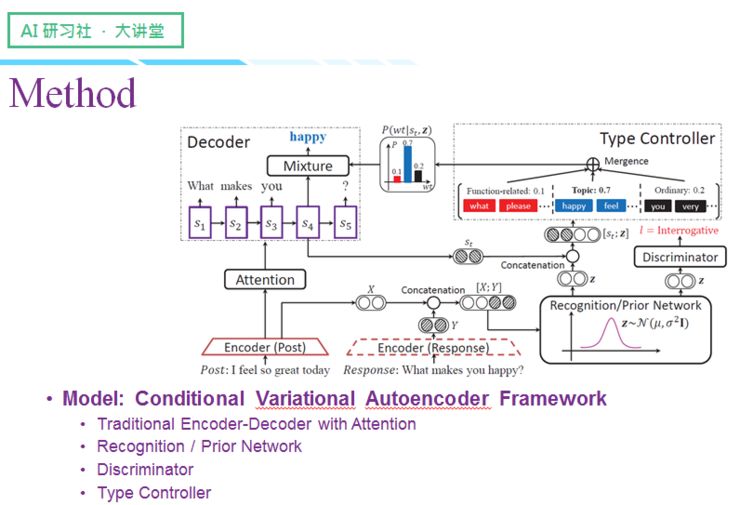
左边是对话领域中常见的「编码-解码」结构,该结构一般带有 attention,以增强 post 和 Response 间的对齐关系,然而仅仅只有这个结构,生成的结果肯定不是我们想要的,因此我们需要增加控制组件,让模型能够达到控制句式的效果。
整个模型主要基于条件变分自编码器(CVAE 模型),该模型早年更多在图像领域使用,一直到最近两年才运用到文本与对话上来,如果只是单纯引入 CVAE 作为技术框架,之前提到的全局控制与信息量兼容问题依然无法得到解决,因此我们便在原先的 CVAE 基础上做了改进。
我会从四个关键部件来给大家讲解这个模型,分别是:传统的编码-解码器、识别/先验网络、判别器以及类型控制器。
传统的编码-解码框架会先通过循环神经网络对用户的 post 进行编码,得到每个位置的隐层向量,然后再将隐层向量传给解码器,通过逐步解码最终生成回复。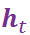
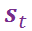
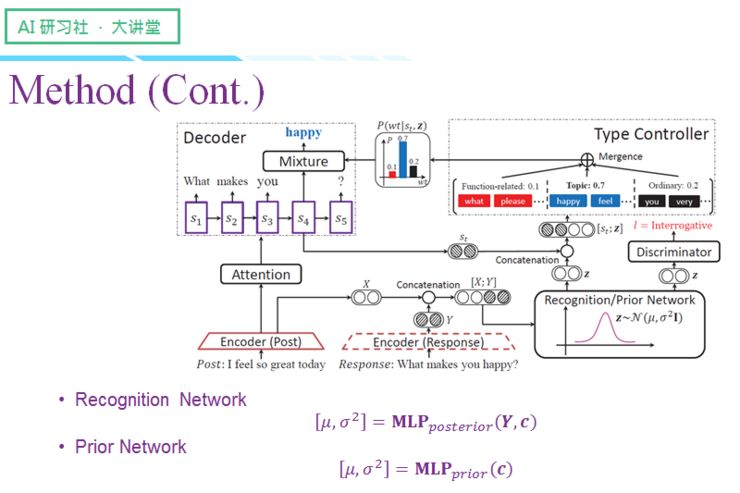
为了让回复的句式能够符合我们之前的设定,我们引入了识别网络和先验网络。根据条件变分自编码器原理,训练的过程中我们是知道真实回复的,所以训练的时候我们会利用后验网络对 Post 信息和 Response 信息进行编码,获得隐变量分布的参数,隐变量分布选的是高斯分布,这里我们假设协方差矩阵是对角阵,所以我们要得到的两个参数是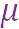
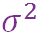
这个高斯分布的用处是什么呢?实际上引入隐变量的目的,是希望可以将一些跟句式相关的特征编码到隐变量中,然后再通过隐变量来引导 response 的生成。不过要注意的是,这个是在训练的过程获得的,测试过程是看不到真实回复的,所以在测试时我们使用了不包含 response 信息的先验网络。
这样可能造成的一个问题是,两个不一样的网络会导致训练和测试之间存在隔阂。对此,我们的解决方案是通过设计一个 lost function 让两个网络的隐变量分布尽可能的接近,以保证测试的时候也能得到一个含有句式信息的隐变量分布。
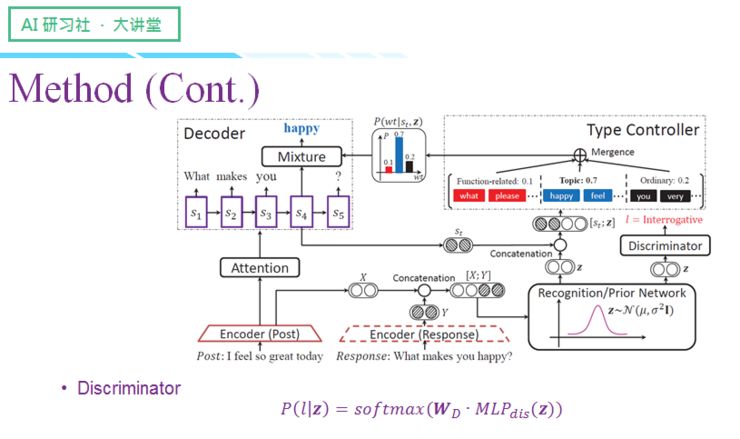
经过识别/先验网络后,我们会得到一个隐变量 z 的高斯分布,我们在高斯分布中采样得到 z,那么又会面临一个新的问题:网络的输入是 x(post)和 y(response),也就是说 z 是提取了 post 和 response 的信息,然而这个信息可能与句式无关,我们要怎么做才能让 z 编码到尽可能多的句式信息呢?我们的解决方案是借助判别器,判别器以 z 为输入,最终得到一个分类结果,这个分类结果就是之前提到的三种句式(疑问句、祈使句、陈述句)上的离散概率。
分类器以输入时设定的句式类别为监督,如果发现分类结果与人为设置的句式结果不一样,就会产生一个 loss,进而督促 z 编码更多在 Post 或者 response 中体现的句式信息。总的来说,判别器主要用于辅助 z 编码与句式相关的信息。
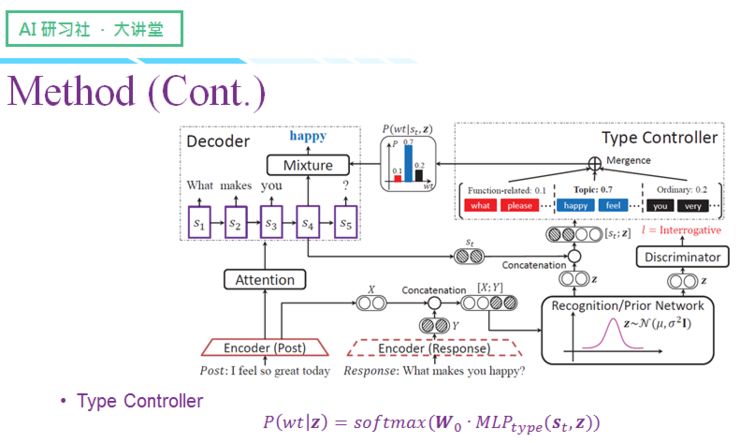
接下来要分享的是比较重要的部分,那就是类型控制器,我们当前每一步的生成,解码器都会计算
这里我将词分成了三种类型:第一类是句式控制相关的词、第二类是话题相关的词、第三类是起句子连接作用的普通词汇。然后我们将类别上的概率分布放进正常的解码过程中,这个概率分布与生成词原本的概率分布可以做一个概率混合,最后得到每一个词的解码概率,通过采样即可生成解码结果。
这个类型控制器的实现也比较简单,这里用的是 MLP,输入是把当前的

我们的解码器与一般解码器不同的地方在于,在计算每一个词的解码概率时,使用的是混合的计算方式——根据当前
最后我们再来回顾一下整个模型,这个模型会产生 loss 的地方主要有三点:第一点是最终生成的 response 与给定的 response 之间的交叉熵;然后在对 z 做分类时,判断当前类别与我们设定的类别是否一样,中间也会存在一个 Loss;第三个点是为了拉近识别网络与先验网络产生的分布距离,我们设置了一个 KL 项,在这过程也会产生 loss。
三者我们做了联合优化,最终得出一个总的 loss,再通过梯度下降等方法去训练来得到我们最终的模型参数。
评测结果
我们工作的另外一项贡献,是构建了一个带句式标签的中文数据集,这个数据在学界是比较少的。
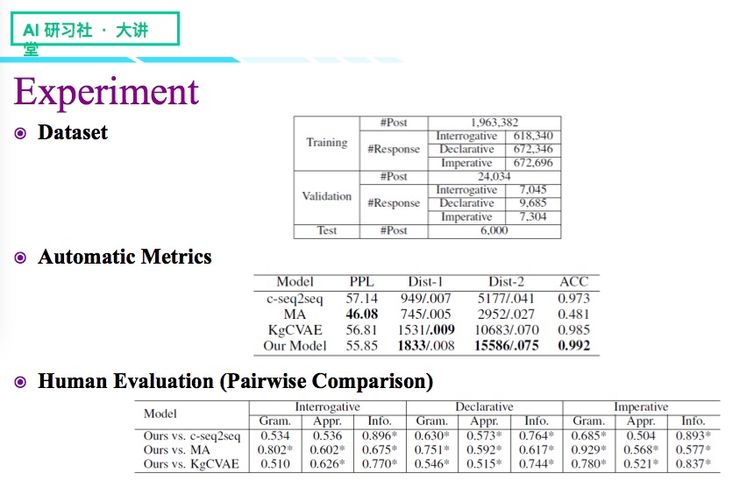
数据集里大概有 196 万的 post,response 和 post 在数量上对等,不过带了相应的句式标签,最后我们还保留了 6000 个 post 作为 test set。
如果不考虑话题因素,目前已有其他模型也在试图做同样的事情,如 c-seq2seq、MA 以及 KgCVAE 模型等,我们将他们作为基线模型,从生成回复的语法性、多样性、准确性三个方面进行对比,结果显示,除了语法性以外,多样性和准确性方面我们的模型都取得了比较出众的效果。
涉猎对话领域的同学可能都知道,自动指标有时候是不靠谱的,这时候我们需要借助一些人工评价,我们这里采取的是一对一比较式评价,我们给标注者一个用户请求以及对应的模型生成结果,让他们从我们的模型更好、基线模型更好、以及平局三者之间做出选择——为了公平起见,标注过程我们会对模型的名称进行保密。
我们比较的指标主要有三个:语法性、合适性、信息量,从结果来看,只要结果显示超过 0.5,就表示我们的模型在该项目的表现要比其他模型更好,我们还会做显著性的测试,结果中我们可以看到除了疑问句(相对而言句式较简单),其他方面都是我们的模型表现得更显著,尤其是在信息量上,这也是我们文章所要解决的挑战,使得回复既包含丰富的信息量,又在句式上是可控的。
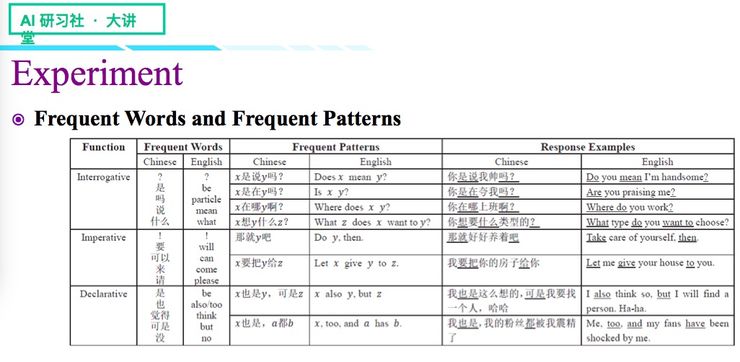
为了分析这些回复究竟有什么样的规律,我们统计了高频词和常见的模式,主要是通过频繁模式挖掘的算法来分析的。疑问句中较突出的是疑问词,频繁出现的模式既包含一般疑问句,还包含特殊疑问句,如果模型确实能够将这些模式灵活运用到回复上的话,我们即可获得优质的生成结果。祈使句和陈述句同理。
值得一提的是,陈述句的频繁模式与高频词相对疑问句和祈使句而言没有那么显著,因为陈述句更多的是转折和并列,但我们的模型有能力利用这些模式生成多样的回复。

接下来我用更加直观的生成例子来做讲解。
这个例子里,post 是「如果有一天我跟你绝交,你会怎样?」在我们的模型生成的回复里,红色部分是从句式控制相关的词表里生成的;蓝色则是从话题词词表里生成的;而剩余的黑色部分则是从一般词汇词表中生成。这也意味着,如果要生成一个好的回复,我们需要将这三种不同类型的词进行合理的规划,这样在面对不同句式类型的生成要求时,才能够生成比较优质的回复——不仅能够控制句式,还能够包含丰富的信息量。
要是我们要求模型生成多个疑问句回复会怎样?我们的模型可以通过采样多个隐变量 z 来达成目标。如图所示,目前的生成结果中,既有一般疑问句的问法,也有特殊疑问句的问法。这说明,我们的模型能够做到的不仅仅是区分 3 种句式类别,通过引入隐变量还能够学习到句式内部的多样性。
结论
总结一下,在单轮对话里通过生成不同句式的回复来实现对话目的,这一点我们的模型已经做得比较好了。在初步具备控制能力的情况下,下一步我们需要做感知,即知道用户表现出什么样的状态,这样我们才能决定我们使用的句式、对话目的与策略,从而在多轮对话里生成较高质量的回复。目前我们的工作只做到了第一步,第二步相对来说比较有难度,因为涉及到的是用户行为的探测和感知。这个可以看做是我们工作未来发展的一个方向。
另外,在语义和结构方面,我们的工作目前只是通过类别控制器去做规划性的工作,比如回复里哪个地方该用哪种类别的词。实际上我们还可以做语义和结构的解耦,以保证在同一个结构下表现不同语义时结构能够不发生变化,这也是我们工作未来的一个发展方向。

最后给大家展示的是可控对话近两年的一些研究成果,它们都是在解决同一个问题:怎样控制回复的某种属性。如果大家对这些话题感兴趣的话,都可以考虑看看这些最新的论文。我今天的分享就到这里,谢谢大家。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到 AI研习社社区(https://club.leiphone.com/)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。


