登临科技联合创始人王平:创新+自研“双核”驱动,GPU+赋能AI落地生根|量子位·视点分享回顾
视点 发自 凹非寺
量子位 | 公众号 QbitAI
人工智能的蓬勃发展带来了算力需求的指数增长。
摩尔定律和Dennard Scaling效应在CPU的性能提升上失效,针对于图形加速和高性能计算设计的GPU在AI计算领域略显乏力。
百花齐放的ASIC AI芯片虽然在某些方面有所改进,但也存在着应用场景局限、依赖自建生态、客户迁移难度大、学习曲线较长等问题。
通用图形处理器GPGPU在不断迭代和发展中成为了AI计算领域的最新发展方向。
技术发展,既要兼容现有AI软件生态,也要坚持自主创新。登临科技的“GPU+”创新架构应运而生,基于“GPU+”的首款芯片产品Goldwasser已在多个行业商业化落地。
为什么“GPU+”更适合解决高性能与通用性等AI计算难题?众人瞩目的“GPU+”架构的核心竞争力在哪里?使用“GPU+”架构的芯片能够有多强大?
围绕GPGPU在人工智能领域的创新技术,登临科技联合创始人王平在「量子位·视点」直播中分享了他的从业经验和观点。

以下根据分享内容进行整理:
登临科技是目前国内首个实现规模化商业落地的GPU企业,登临“GPU+”已经在安防、交通、医疗、金融、能源、电力、智能驾驶、互联网等多个行业实现了商业落地。登临GPU+的主要特点是是低碳、能效比高,在客户侧用登临产品替换原先加速卡的比率很高。
我们独特的“GPU+”的架构,可以在硬件上兼容支持CUDA/OpenCL这样主流的语言以及主流AI框架,并且针对AI计算我们做了深度优化,相对于传统的GPU架构,GPU+经实测有三倍以上的能效提升。我们采用并坚持的路线是,核心技术完全自主研发。
算力:数字经济引擎,智能社会基石
在这个过程中,我们首先解决的问题是什么呢?就是算力。
算力,其实解决的是我们现在比较新的一个概念——数字经济。数字经济,从经济学的角度来讲,是指人们通过大数据(这里主要是经过数字化的知识和信息),进行识别—选择—过滤—存储—使用,实现资源的快速优化配置与再生,实现经济发展的经济体形态。
在这个经济形态里,核心就是数据。数据是数字经济的矿石,而这个矿石具有相当高的含金量,要获得其中的“金”,就要像刚才提到的一样进行识别选择,需要对它进行打磨或者挖掘——也就是在海量的、意义模糊的数据之中,实现数据的挖掘。
这样的过程中,算力工具,成为了整个数字经济的基础设施。它在大数据和智能化应用的这个年代,提供了重要的支撑作用。
类比于传统工业时代,例如汽车工业的驱动力是马力,那么在数字经济年代,数字经济的驱动力无疑是算力。人工智能领域对算力的需求,每年以指数级增长,而算力最基础的来源则是计算芯片。

计算芯片的重要性是毋庸置疑的,简单来说,芯片就是计算机。比如二十多年前,我上中学的时候,那时候提到计算机是386或者486,到现在的大规模并行计算的板卡甚至机器在以T4、A100直接指代,这在一定程度上是用芯片来代称计算机了。从本质上来讲,这些就是提供核心算力最主要的载体。
今天我们通过登临科技四年多的发展经历,以及产品化的路线,给大家介绍一下“登临芯”是如何做到规模化落地的。
“登临芯”是怎么创造出来的?
芯片行业的特点在于,它是一个充分竞争的行业,俗称“老大吃肉老二喝汤”竞争残酷。
在这样残酷的市场竞争环境里创造一个好的产品,非常重要的,它不仅仅是一个好的技术,而是一个好的产品——“好”在于这个产品能够解决客户的问题,而不是仅仅去解决一个自己想解决的问题,或者我们所拥有的技术能解决的问题。
在登临成立之初,CEO李建文先生花了半年多时间走访了几十个客户,向大家了解对公司产品和产品相关技术架构的需求。针对于这些需求我们要如何解决?我们就需要以创新为灵魂,以计算为突破口,以及坚持核心技术自主研发。
在我个人看来,没有创新,就没有核心竞争力。登临科技从成立开始,我们就是用技术和产品说话。我们希望在商业市场上,产品能够为客户创造价值,为了达到这个目标,我们最核心、最有价值的东西,一定是要来自创新。因为只有这样,我们才能够达到很高的上限,最起码是要打败我们的竞争对手,否则我们不可能为客户创造出价值,我们自己也很难在这样残酷的市场里获得一席之地。
在一个竞争对手是国际巨头的赛道里,我们不能只是复制别人,或是引入落后技术。我们所做的处理器,回首过去几十年的发展历程,其技术是在不断迭代、持续演进的。不断的迭代、优化和创新,才能够让产品具有更强竞争力。
计算这个核心的部分,自研才是唯一的出路。只有自己掌控,才可以在系统的关键路径、硬件和软件,避免一些不可控的瓶颈和堵点,能够让自家可以提供一套完整的方案,也更容易设计并且优化一些客户方面面临的问题。
因为我们是全方位自己的架构,我们可以更深入地理解客户的痛点,并且通过一些软硬件协同的设计,能够定点地解决客户的问题,这样的方法能够实现我们客户的需求,同时也对我们的落地有更好的帮助。
继续分析算力这个问题。算力很重要,而且算力也在持续的增长之中,那么到了现在,算力的增长点在哪里呢?
在我接触到电脑的时候,算力增长还相对比较容易,可以通过工艺的改进,在单核上提高CPU的频率,就可以简单地实现算力的增长。在单核走到上限的时候,还可以通过多核的堆砌,实现算力的提升。但是即使工艺仍然在改进,摩尔定律走到现在还是基本失效了,问题的已经是以功耗和散热为主要矛盾了。
随着工艺越来越小以及功耗的限制,Dark Silicon(暗硅)也就成了客观存在,这时候解决问题的思路已经不再是一味的多核,堆砌算力。
但是客户需要算力,需要更高性能更低功耗的算力。解决这个问题,对于我们而言,就是让我们开始思考如何用更有效的组合算力在功耗带宽这样的约束条件下,选择最适合的架构。
芯片:异构计算是趋势,GPU+将成为主流AI芯片
既然提到选择,我们就来看看对比方案。
第一个不得不说的对比方案,就是GPU和通用GPU(GPGPU)。
GPU对于从业人员而言,是非常优秀的架构,它为游戏、为并行计算而生,其比较主流的生态CUDA已经成为了并行计算的标配,而且这些年它还在不断地进行改进。但是无论它怎么样改进,它还是有一些根本的问题不能够在架构层解决的。他的效率是在多条产品线上的均衡,在AI场景下效率一般,改进效率较低。
GPU整个产品线比较广,所覆盖的领域其实非常多。从公司理念或者产品理念上,它也是希望用一个架构解决各个领域的问题。所以,在它没有办法在任何特定领域下实现最优的情况下,给其他产品提供了特定领域里的优化空间,甚至是创新空间,我们则是思考的是如何在特定领域里面实现更高的效率。
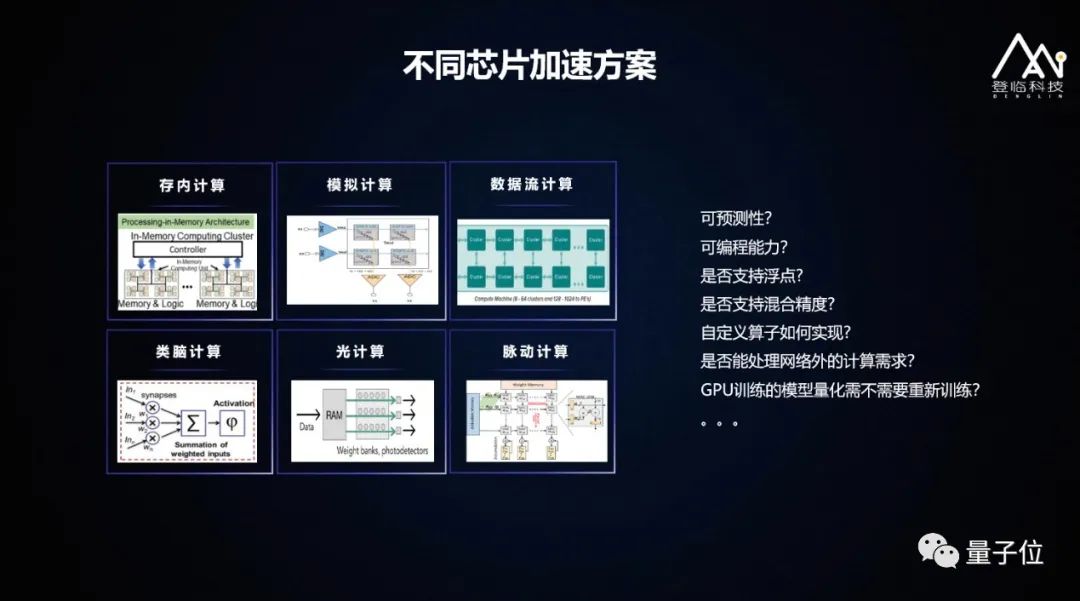
GPU在AI领域有一些局限。主要几个问题是计算效率、存储子系统和片上延迟,这些基本问题导致它的能耗比较高,但性能比较有限,效率一般。
从我们走访客户的反馈可以看出,他们对GPU是又爱又恨。GPU的确为他们创造了价值,但是他们购买的GPU存在性价比不高的问题:即高价买到一些冗余的通用设计组件,但这些组件无法在他们所需的领域发挥能效,这就增加了产品部署的成本。
客户急需的是更高能效的处理器,那么有没有呢?在登临GPU+之前,有非常多的Paper、Demo来展示一些更高效的方案。这些高效方案更多展示的是在矩阵或者卷积运算这些方向上的提升,有更高的能效比以及创新。
但是根据我们在客户中的调研结果,矩阵和卷积运算固然重要,但这并不是全部:这些方案或许能够在矩阵加速方面解决一些问题,甚至能够在一两个特定的应用里面有一些不错的效果,但这并不是一个处理器的方案,因为处理器这个词本身就代表某种通用性;这些方案并不能够为客户提供一套完整的通用解决方案。
某个网络或者某个应用中的部分加速在客户的业务线里连不起来,他为了适应这个业务线又要做很多的变动,而这些部分加速只能适用于部分业务。这对客户来讲,是非常难用的方案,而且现在客户的应用其实是在不断演变的,客户在不断的进步,但如果你只能解决一个问题,哪怕这是一个比较主要或者是算力比较集中的问题,也很难在客户端实现落地。
客户通常不会为了你的一个小小的提升来改变他整个方案的框架。提升方案的能力其实也不一定完备,到了不能支持的部分就是一种灾难。从这个角度来讲,加速方案虽然看起来很美,但是并不能够很好地融入客户框架,或者融入客户框架的成本实在太高了。
我们应该探索能不能有一些好的方案,能够基于客户基本的应用框架比较好地融入,并且能够支持客户使用他比较熟悉的语言或者编程方式来实现定制式需求。达到了这两点,客户的接受度就会比较高,他会更愿意接受你的产品,他的创新也可以用比较通用的语言进行表达,而不需要学习专用的语言。
总结下来,其实最关键的两点就是:高效率,硬件的高效率,以及整个解决方案的通用性和应用性。这个就是我们在AI领域要解决的最主要的问题,这两个问题再总结成一个问题,其实就是高效率问题。
一个是机器要高效率,就是说我们要能够提供一个高性能、低功耗,高能效比的系统。另外一个是要实现人的高效率,能够提升整个客户公司的高效率,而且灵活易用。达到这个目标,首先是集成,其次是优化,并且是用客户熟悉的办法优化,这样就可以实现很迅速的落地。
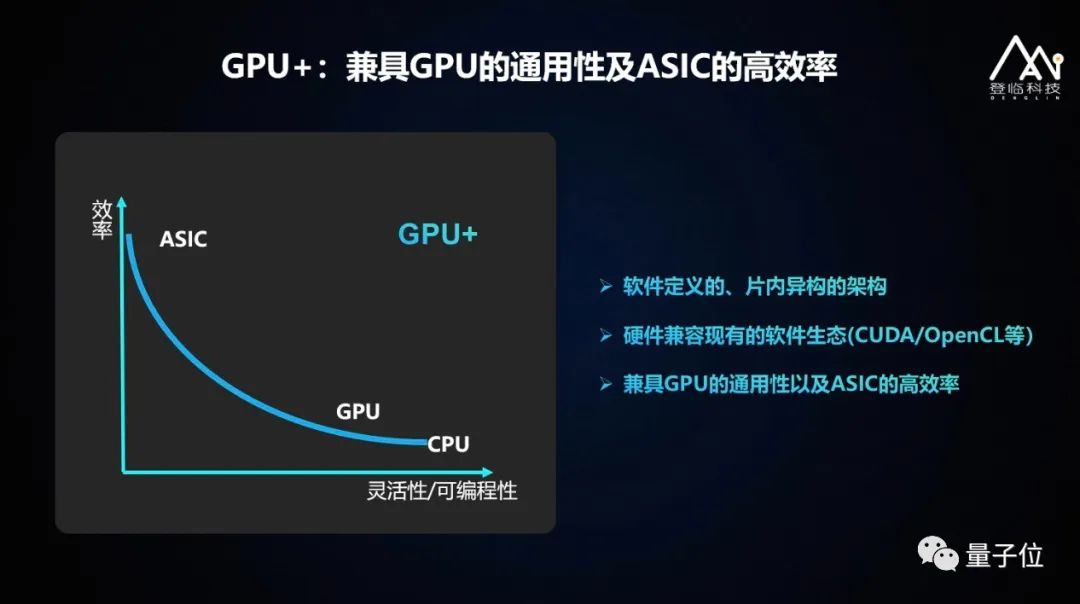
这是客户的“既要又要”。那么从我们自己对架构的设计需求,或者一个基本要求出发,我们是怎么解答“既要又要”这个问题的呢?那就是,我们的产品方案既要ASIC高效率,又要GPU的通用性。
进行了刚才问题的分析后,我们可以看到在AI计算领域异构系统应该是片内异构的系统,是一个水到渠成的选项。
刚才我们也提到了Dark Silicon(暗硅),传统片上无法把堆砌的大量的中效率核全部打开,但登临在片上选择一些异构的高、中、低效率不同核来结合,共同完成提高算力的任务,让不同的核实现各司其职。
那么在AI这个领域,我们做的是,用高密度的处理器解决高密度的计算需求,解决客户的硬件能力高效率问题。
当然另外一个非常重要点中密度的并行计算的需求,争对并行计算我们选择用GPU加速,并且采用硬件兼容CUDA/OpenCL等现有软件生态。考虑兼容现有软件生态是从客户端出发,让客户比较容易的编写自己的自定义算子,使其快速的实现方案的集成。
综上,我们最终设计开发了基于GPGPU的片内异构计算体系:GPU+,其兼具GPU的通用性及ASIC的高效率。
以下我深入介绍下GPU+的软硬件细节。
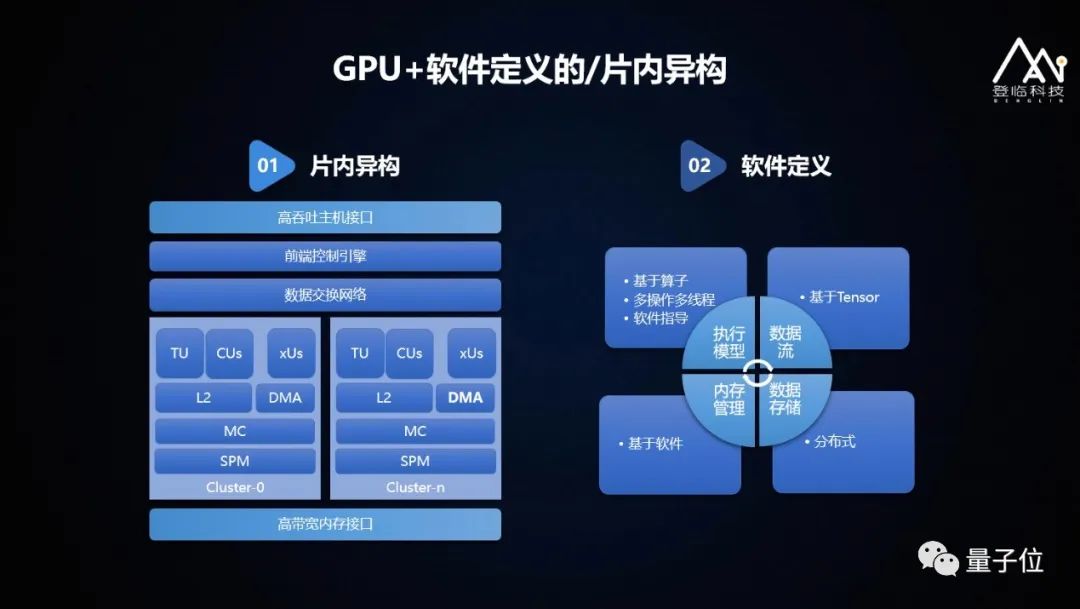
GPU+的核心是片内异构,在特定应用领域里,比如说我们现在落地的AI场景,实现我们的高能效的一个计算需求。以AI计算为例,AI计算中传递的数据是Tensor,操作是算子,尤其是绝大多数算子的算法是结构化的。我们基于这个特征设计一个高效的处理单元,对应的软件栈也只需要对这些算子进行特别加速,这部分专用既易用又能提供高能效的基础。而且,我们的内存子系统使用CUDA/OpenCL语言编写,能够让客户的生态的代码实现无缝接入。此外,我们采用了片上的高速数据交换网络,和软件管理的片上内存,最大程度的解决低带宽、低延迟,这样GPU+也就是实现了低功耗、高能效。
从一开始就在AI计算上还有一个什么好处呢?举一个例子,今年H100发布的一些Feature,可以看到他们试图解决一些访存、效率的问题并且引进了相关的编程模型,而这些问题在我们的原创架构可以做到一开始就不存在,或者说从一开始就可以有简单的解法。我们通过架构创新,让复杂的问题变简单。
此外,针对客户需求,GPU+通过使用片上不同的计算单元以及扩展xU进一步加速解决行业的共性计算问题。
自研IP:大芯片企业可持续发展的根本动力

登临GPU+的核心竞争力是:核心IP完全自主研发。
选择核心计算IP全自研其实一个相对挑战的路线,我们和计算有关的核心IP无论是架构,微架构包括算术单元,包括SoC的架构,都是自主设计,每行代码都是自主编写。选择自主研发主要是来自于我们团队多年来在计算领域耕作的自信以及对计算IP的深刻理解。另一方面,我们坚信只有自主研发,才能够承载架构创新,确保自己的竞争力。此外,算力产品在深度上需要迭代,精益求精,广度上要利用leverage之前的技术与经验,只有自研,才能自我突破,并迭代出在边缘侧、云端不同应用需求的不同产品,实现企业的良性自我造血,循环可持续发展。
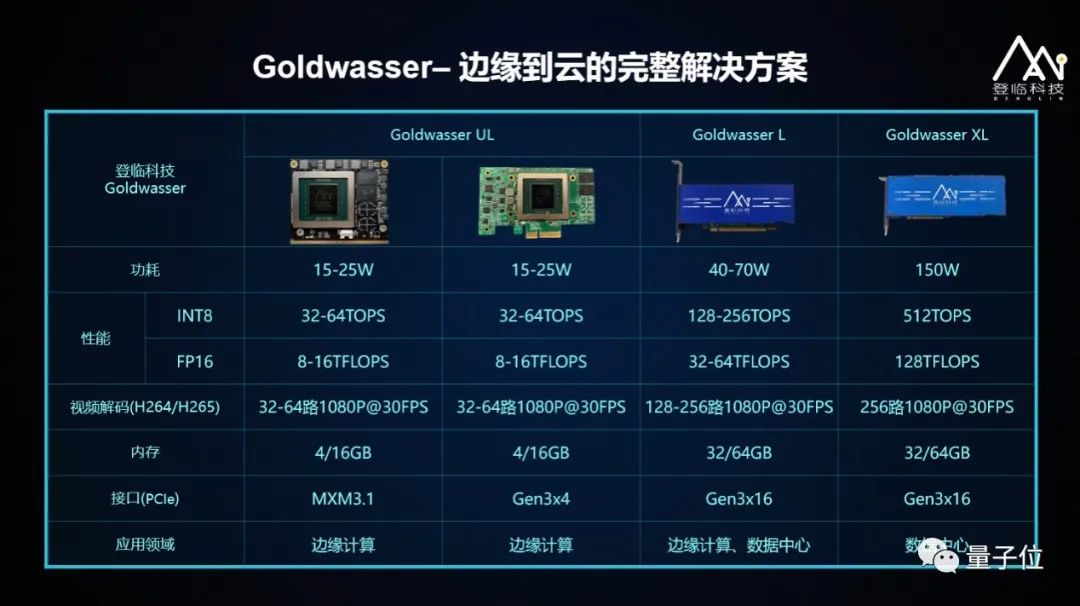
基于GPU+,登临打造了首款边缘至云端全系列产品:Glodwasser。Goldwasser系列产品:包括边缘计算产品Goldwasser UL,功率15-25W,INT8算力32-64TOPS;半高半长的服务器计算卡Goldwasser L,功耗40-70W,提供128-256TOPS算力;另有一种全高全长的Goldwasser XL,输出 512TOPS 算力。
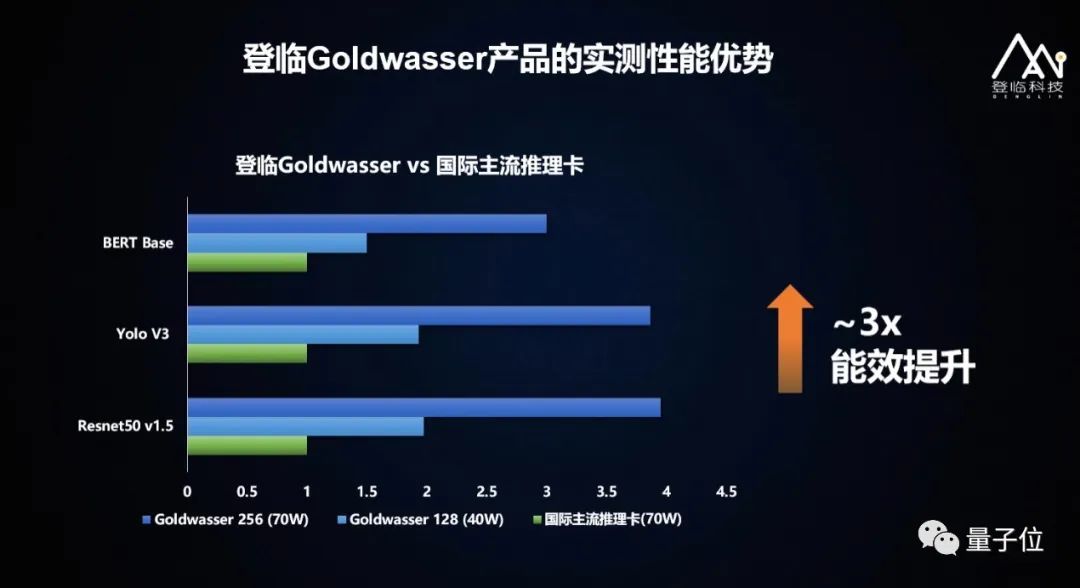
在实测过程中,GPU+在40W TDP时输出了128TOPS算力,和国际主流产品对比其功耗更低,性能更高。在同样的工艺上,GPU+可以以更小的芯片面积,在同样功耗下,在不同神经网络上提升3倍以上计算效率,并同时减低芯片性能对外存吞吐的依赖。此外,Goldwasser使用的Hamming工具链,不仅支持传统GPU使用的硬件加速方式,和PyTorch、TensorFlow、飞桨等国内外主流深度学习框架,也支持国内外主流x86和ARM产品。目前,登临在也和多家CPU、服务器厂商合作,适配了多种CPU、服务器。
客户场景

目前登临Goldwasser目前已在安防、交通、医疗、金融、能源电力、智能驾驶、在线教育、互联网等行业实现商业化落地,并顺利实现规模化量产供货。
除此之外,Goldwasser还在赋能更多的AI应用领域,如视频审核、信息检索、自然语言处理等场景。大量客户产品实测证明,针对AI计算,GPU+相比传统GPU在性能尤其是能效上有显著提升。
总的来说,规模化落地是我们的第一步。下一步,我们将继续与客户进行更深入的合作,坚持核心技术自主研发,创新迭代出新的产品,拓展更多领域的客户,更广泛地为推动数字经济发展做贡献。
关于「量子位·视点」
量子位发起的CEO/CTO系列分享活动,不定期邀请前沿科技领域创业公司CEO/CTO,分享企业最新战略、最新技术、最新产品,与广大从业者、爱好者探讨前沿技术理论与产业实践。欢迎大家多多关注 ~

需要观看直播回放的小伙伴,请戳“阅读原文”吧~
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


