我们在讲的 Database Plus,到底能解决什么样的问题?
![]()
![]()
背 景
一直以来,大一统还是碎片化,是数据库发展趋势的两种最主流预测。随着数字化进程的推进,单一场景无法满足应用多样化的需求,数据库碎片化已呈不可逆的趋势。在当前,市场占有率最高的商用数据库—— Oracle 并没有明显短板的情况下,各种全新的数据库依旧如雨后春笋般层出不穷。如今,DB-Engines 上已有超过 300 余种数据库参与排名。
应用场景的不断扩张,加速了数据库碎片化的进程,数据库的架构、协议、功能、适用场景也愈加多样化。在数据库架构方面,基于单机系统演进而来的集中式数据库与原生面向分布式的新一代数据库并存;在数据库协议方面,MySQL 和 PostgreSQL 这两大主要开源生态以及周边厂商所提供的服务生态也在全球数据库体系中各自占有一席之地;每种数据库的独特功能和适用场景,也在相关的领域大放异彩。
在企业的应用现状中,数据库的多元并存已是常态。在互联网行业中,以 MySQL + 数据分片中间件作为核心业务存储的架构模式为主,以 GreenPlum、HBase、Elasticsearch、Clickhouse 等其他大数据生态作为分析型数据的计算引擎为辅助。与此同时,一些遗留系统(如:通过 .NET 转型时遗留的 SQLServer、或通过外采而遗留的 Oracle)的数据库仍在运行;在金融行业中,核心交易系统仍然大量使用 Oracle 或 DB2,新业务向 MySQL 或 PostgreSQL 迁移,部分业务则逐渐尝试使用自主研发的数据库。除了交易型数据库,分析型数据库的种类则更加繁多。
因此,碎片化是数据库领域的大势所趋,单一品类的数据库无法适用于所有场景,只能适用于某一种或某几种擅长的场景。


一直以来,大一统还是碎片化,是数据库发展趋势的两种最主流预测。随着数字化进程的推进,单一场景无法满足应用多样化的需求,数据库碎片化已呈不可逆的趋势。在当前,市场占有率最高的商用数据库—— Oracle 并没有明显短板的情况下,各种全新的数据库依旧如雨后春笋般层出不穷。如今,DB-Engines 上已有超过 300 余种数据库参与排名。
应用场景的不断扩张,加速了数据库碎片化的进程,数据库的架构、协议、功能、适用场景也愈加多样化。在数据库架构方面,基于单机系统演进而来的集中式数据库与原生面向分布式的新一代数据库并存;在数据库协议方面,MySQL 和 PostgreSQL 这两大主要开源生态以及周边厂商所提供的服务生态也在全球数据库体系中各自占有一席之地;每种数据库的独特功能和适用场景,也在相关的领域大放异彩。
在企业的应用现状中,数据库的多元并存已是常态。在互联网行业中,以 MySQL + 数据分片中间件作为核心业务存储的架构模式为主,以 GreenPlum、HBase、Elasticsearch、Clickhouse 等其他大数据生态作为分析型数据的计算引擎为辅助。与此同时,一些遗留系统(如:通过 .NET 转型时遗留的 SQLServer、或通过外采而遗留的 Oracle)的数据库仍在运行;在金融行业中,核心交易系统仍然大量使用 Oracle 或 DB2,新业务向 MySQL 或 PostgreSQL 迁移,部分业务则逐渐尝试使用自主研发的数据库。除了交易型数据库,分析型数据库的种类则更加繁多。
因此,碎片化是数据库领域的大势所趋,单一品类的数据库无法适用于所有场景,只能适用于某一种或某几种擅长的场景。
![]()
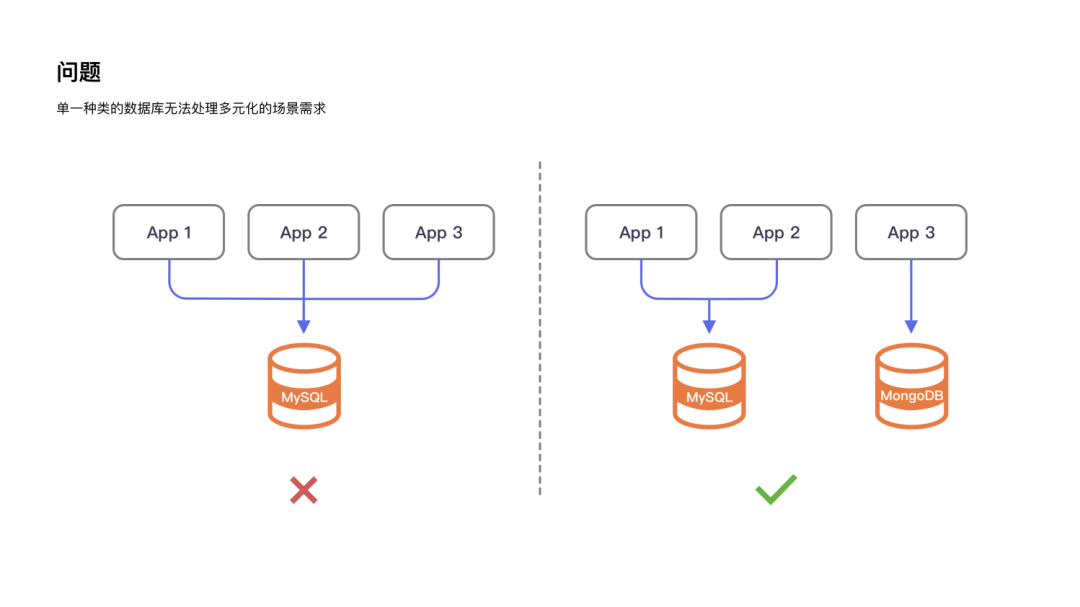
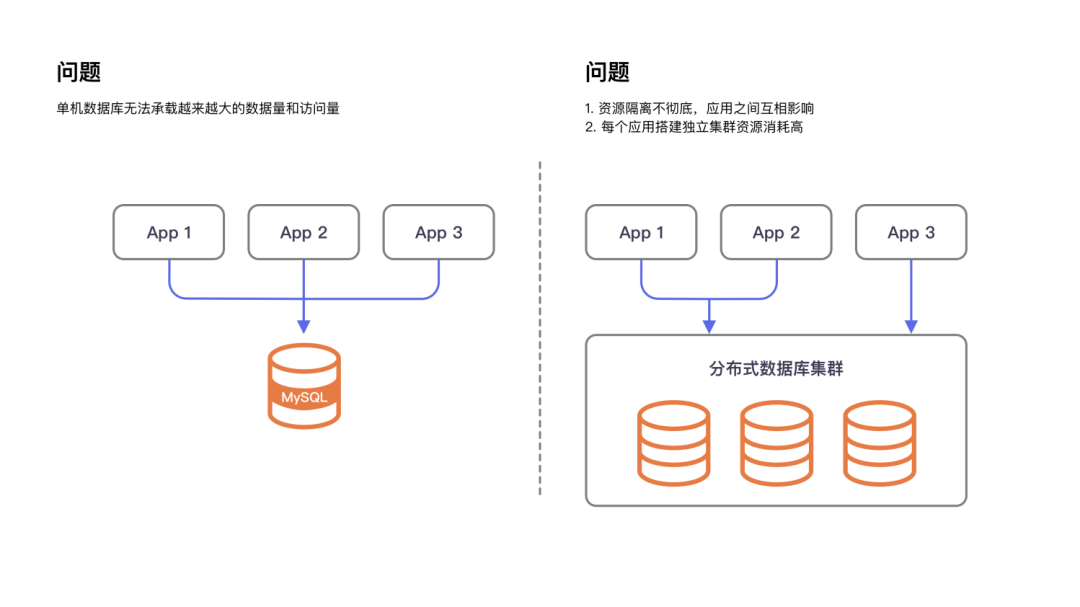
数据库碎片化带来的问题

1.架构选型困难
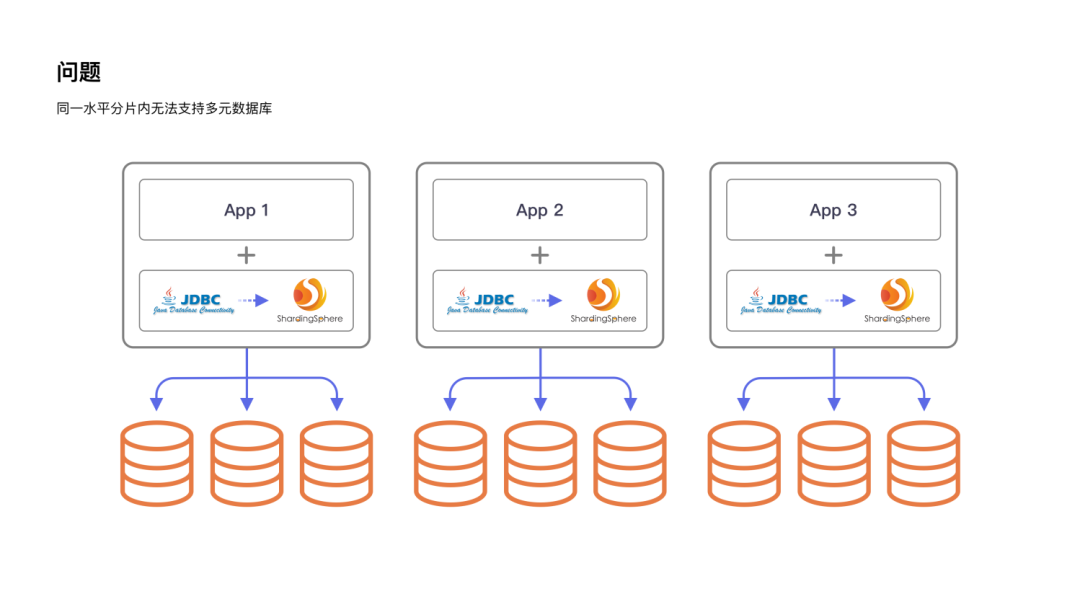
2、技术挑战众多
3、运维复杂度高
4、数据库间缺乏协作和统管能力

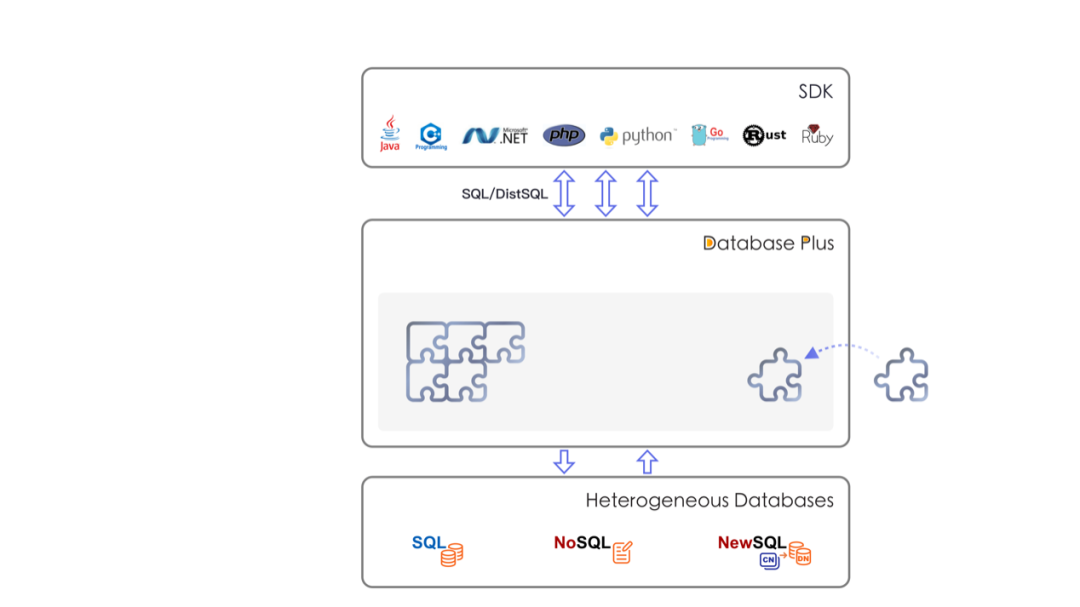
1、连接:打造数据库上层标准
2、增强:数据库计算增强引擎
3、可插拔:构建数据库功能生态
![]()
ShardingSphere 在 Database Plus 方向的探索

1、连接层
2、增强层
3、可插拔层
小结
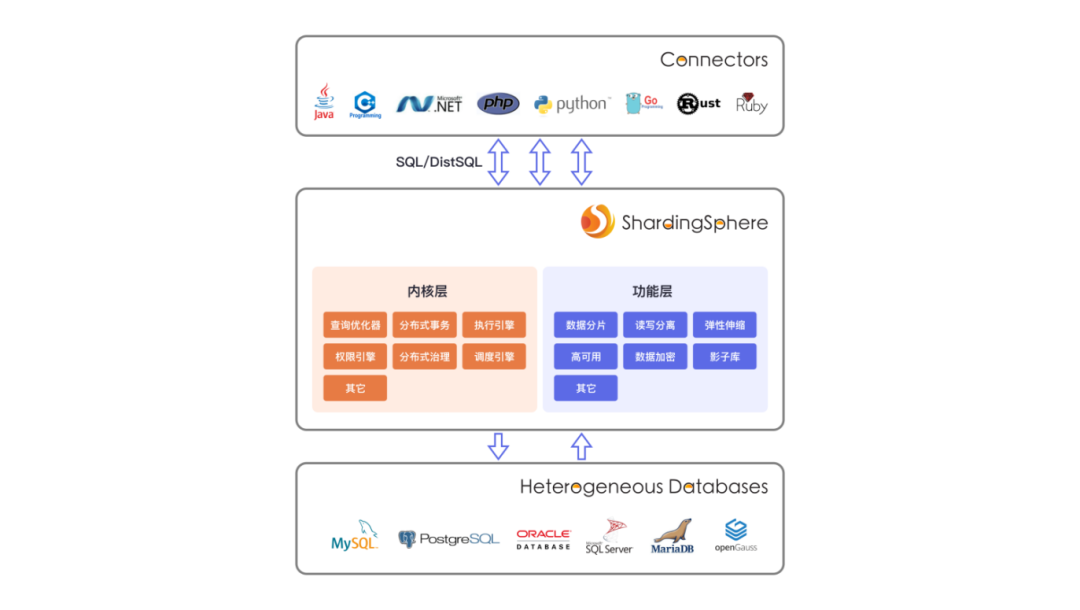

1、精细化适配灵活多变的应用场景
2、面向架构师的微服务后端支撑能力
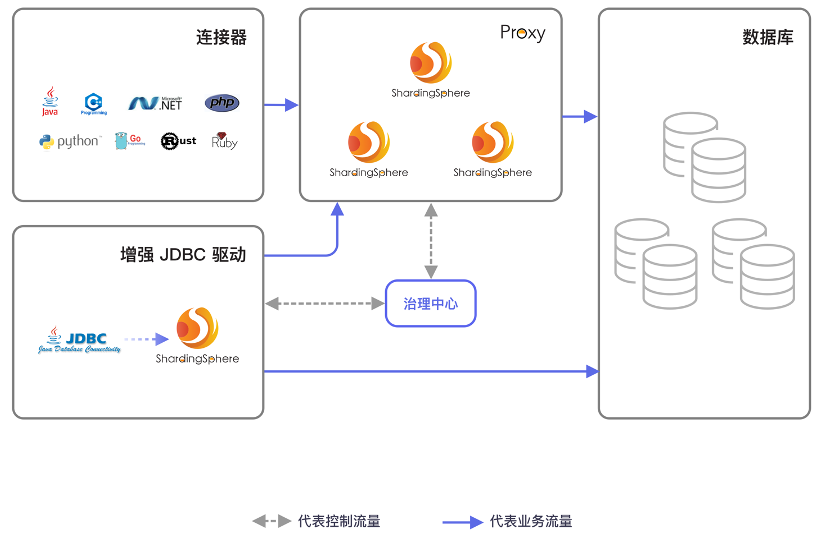
3、DistSQL 为 DBA 带来数据库原生操作体验
4、Proxyless 模式提升性能至极致
小结

1、数据库网关
2、异构联邦查询
写在最后
关于作者
登录查看更多
相关内容

数据库(
Database )或数据库管理系统(
Database management systems )是按照数据结构来组织、存储和管理数据的仓库。目前数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。
Arxiv
0+阅读 · 2022年6月22日



相关VIP内容
相关资讯