事理图谱:事件演化的规律和模式
原创作者:丁效,李忠阳,刘挺
2016年7月,哈工大社会计算与信息检索研究中心(HIT-SCIR)开始启动事理图谱的研究工作。
2017年10月,研究中心主任刘挺教授在中国计算机大会(CNCC)上正式提出事理图谱的概念。
2018年9月,在研究中心丁效老师的主持下,研制出中文金融事理图谱1.0版本,2019年7月更新为2.0版。
本文是对2016年7月以来工作的最新总结,敬请各位同行指正。
引言
事件是人类社会的核心概念之一,人们的社会活动往往是事件驱动的。事件之间在时间、空间上相继发生的演化规律和模式是一种十分有价值的知识。然而,现有的典型知识图谱均以实体及其属性和关系为研究核心,缺乏对事理逻辑这一重要人类知识的刻画。
为了弥补这一不足,事理图谱应运而生,它能够揭示事件的演化规律和发展逻辑,刻画和记录人类行为活动。在图结构上,事理图谱是一个有向有环图,其中节点表示事件,有向边表示事件之间的演化关系。现实世界中事件演化规律的复杂性决定了我们必须采用这种复杂的图结构。本质上,事理图谱是一个事理逻辑知识库,描述了事件之间的演化规律和模式。
1. 研究背景及意义
随着深度学习的兴起,人工智能迎来了新的发展高潮。人工智能的一个发展瓶颈在于,如何让机器掌握人类知识。例如,人类能轻易理解“吃过饭”后,就“不饿”了这样的常识知识,而让机器理解并掌握大量这样的知识是一件极其困难的事情,而这也是通往强人工智能的必由之路。在众多类型的人类知识中,事理逻辑是一种非常重要且普遍存在的知识。
许多人工智能应用依赖于对事理逻辑知识的深刻理解。以隐式消费意图识别以及隐式情感分析为例,只有让机器知道“结婚”事件伴随着后续一系列消费事件,例如“买房子”、“买汽车”和“去旅行”,我们才能在观察到“结婚”事件的时候,准确地识别出用户潜在的隐式消费意图,进而向目标用户做出精准的产品推荐。只有让机器掌握“考试不及格”会引起“情绪低落”这样的常识事理,才能从显式事件当中挖掘出用户背后的隐式情感。
现有的对话生成系统大多从大规模对话语料中以最大似然估计进行训练。然而人类对话的语义和语境是复杂多变的,这样得到的对话系统很难深入理解对话上下文的前因后果,而只是对训练语料中特定问答模式的记忆。只有让机器理解了“吃过饭”之后“人不饿了”,“看电影”之前要“先买票”这样的常识事理,对话系统才能根据不同的问答语境,做出更加智能的回复。
股市一般伴随着短期内随机的小波动,以及长期内重大事件驱动的大波动。例如,近来随着人工智能迎来发展高潮,以及“国家将人工智能列为国家发展战略”,科大讯飞等人工智能企业股价迎来了一波大涨。
事件驱动的股市预测悄然兴起。从金融文本中挖掘“粮食减产”导致“农产品价格上涨”,再导致“通胀”,进而导致“股市下跌”这样的远距离事件依赖,对于事件驱动的股市涨跌预测非常有价值。事理逻辑知识的挖掘与知识库构建迫在眉睫,这将极大地推动多项人工智能应用的发展。
事件是人类社会的核心概念之一,人们的社会活动往往是事件驱动的。事件之间在时间上相继发生的演化规律和模式是一种十分有价值的知识,挖掘这种事理逻辑知识对我们认识人类行为和社会发展变化规律非常有意义。
然而,当前无论是知识图谱还是语义网络等知识库的核心研究对象都不是事件。尽管传统知识图谱在现代搜索引擎中(例如Google、Bing、Baidu等商业搜索引擎)得到了广泛应用,但是其聚焦于实体和实体之间的关系,缺乏对事理逻辑知识的挖掘。我们认为事理逻辑知识,包括事件之间的顺承、因果、条件和上下位等关系,对于人工智能领域的多种任务具有非常巨大的价值。
为了揭示事件的演化规律和发展模式,我们提出了事理图谱的概念,旨在将事件的演化规律和模式构建成一个有向图形式的事理知识库,用于刻画和记录人类行为活动和事件客观演化规律。
2. 事理图谱的定义
事理图谱(Event Logic Graph,缩写ELG)是一个事理逻辑知识库,描述了事件之间的演化规律和模式。结构上,事理图谱是一个有向有环图,其中节点代表事件,有向边代表事件之间的顺承、因果、条件和上下位等事理逻辑关系。
理论上,事理图谱中的事件是具有一定抽象程度的泛化事件。表示为抽象、语义完备的谓词短语或句子,也可以表示为可变长度的、结构化的(主体、事件词、客体)多元组,其中必然包含一个事件词,标志事件的发生,例如:“跑步”,而事件的主体和客体都可以在不同的应用场景下被省略,例如:“(元首,出访)”可以省略事件的客体,“(购买,机票)”可以省略事件的主体。一般情况下,事件以及事件的抽象程度与该事件发生的场景紧密关联在一起,脱离了具体的场景,一个单独的事件可能变得过度抽象而难以理解。
例如,虽然脱离了具体的场景,但“吃火锅”, “看电影”, “去机场”,“地震” 仍是合理的事件表达;但“做事情”,“吃”等事件由于过度抽象,属于不合理或不完整的事件表达。
事件词可以是动词或名词,但是绝大多数事件都是动词触发的。其中,按动词的内容意义进行划分,可将事件分为动作类事件、状态类事件、关系类事件与能愿类事件四个大类。
2.1 事理图谱中的事件关系类型
我们认为,现实世界中有四种事理逻辑关系特别重要,也是我们提出的事理图谱中主要关注的事理逻辑关系,包括事件之间的顺承关系、因果关系、条件关系和上下位关系。
顺承关系是指两个事件在时间上相继发生的偏序关系。我们借鉴TimeML时序关系类别中的before和after偏序关系,在事理图谱中的顺承关系包括两种情况:一种情况是顺承的前序事件a结束后,后序事件b紧接着发生;另一种情况是前序事件a结束后,隔一段时间后序事件b才会发生,具体如图1所示。两个前后顺承的事件之间存在一个介于0到1之间的转移概率,表示从一个事件按时序顺承关系演化到下一事件的置信度。

因果关系是指两个事件之间,前一事件(原因)的发生导致后一事件(结果)的发生。在事理图谱中,因果关系满足原因事件在前,结果事件在后的时间上的偏序关系,因此在一定意义上,可以认为因果关系是顺承关系的子集。因果事件对之间存在一个介于0到1之间的因果强度值,表示该因果关系成立的置信度。
条件关系是指前一个事件是后一个事件发生的条件。条件关系属于思想中命题的某种逻辑关系,因果关系属于对客观事实的某种认识,我们认为“原因≠理由”,“原因”指的是事件之间的因果关系,是关于事实的,“理由”是前提与结论或论据与论点的内在联系,是关于逻辑的。举例来说,“如果买票的人多,那么电影好看”这一条件是成立的,而“因为买票的人多,所以电影好看”这一因果是不成立的。
上下位关系:事件之间的上下位关系有两种:名词性上下位关系和动词性上下位关系。例如,事件“食品价格上涨”与“蔬菜价格上涨”构成名词性上下位关系;事件“杀害”与“刺杀”互为动词性上下位关系。需要注意的是,上下位关系一般是没有疑义的确定知识,因此可认为该类关系的置信度为常数1或0,即表示该知识是正确的或者是错误的。
2.2 事理图谱中的事件属性
事理图谱除了关注事件之间的事理逻辑关系外,还关注事件自身的属性。事件属性用来描述事件发生的程度、持续时间等。
在进行推理时,事件属性会起到非常重要的作用,例如,从金融文本中可以抽取到“货币超发”会导致“汇率贬值”,“汇率贬值”又会导致“货币紧缩”,而实际上“货币持续超发”才会导致“汇率贬值”,而“汇率大幅贬值”才会导致“货币紧缩”,这里面“持续”和“大幅”作为事件的属性,可以影响到事件未来的走势情况。此外,“股票下跌/上涨”的百分比也是事件重要的属性,股票上涨0.1%和上涨10%对未来事件的影响是有非常明显的区别的。
3. 事理图谱与知识图谱的关系
“知识图谱”这一术语有两层含义。如果认为“知识图谱”表示广义上的知识库,是一种用以存储知识的本体的话,那么“事理图谱”可以认为是一种存储事理逻辑关系的“知识图谱”;如果认为“知识图谱”特指狭义上现阶段谷歌、百度所构建的以实体为中心、用于提升用户搜索体验的知识库,以及Freebase、 YAGO、 DBpedia、ConceptNet和微软的Concept Graph等产品的话,那么“事理图谱”便是与“知识图谱”相并列的一种新型常识知识库。
表1 事理图谱与知识图谱的区别及联系
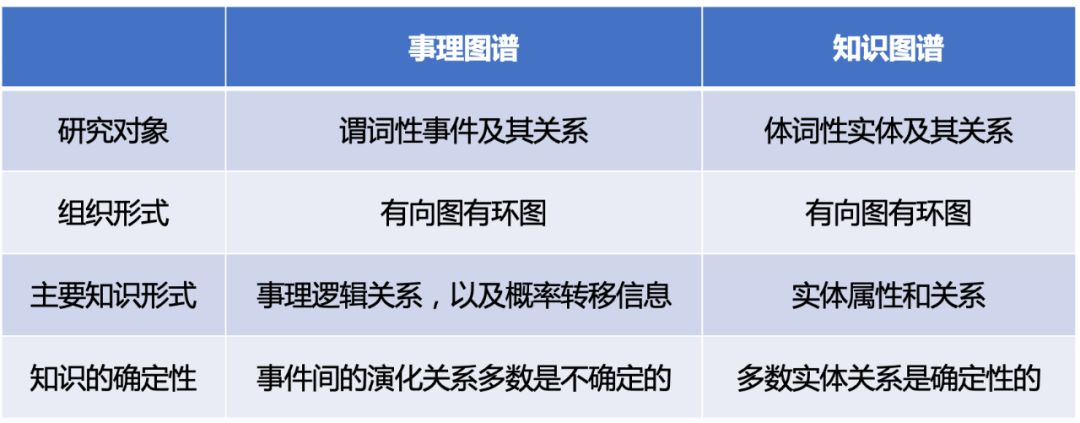
事理图谱与传统知识图谱有本质上的不同。如表1所示,事理图谱以事件为核心研究对象,有向边表示事理逻辑关系,即顺承、因果、条件和上下位;边上标注有概率信息说明事理图谱是一种事件间相继发生可能性的刻画,不是确定性关系。而知识图谱以实体为核心研究对象,实体属性以及实体间关系种类往往成千上万。知识图谱以客观真实性为目标,某一条属性或关系要么成立,要么不成立。
4. 事理图谱的构建
4.1 基本技术原理
事理图谱课题主要研究从大规模无结构化(或者结构化、半结构化)文本数据中自动获取事理逻辑知识,并将这些知识组织成有向有环图结构,用以描述事件之间的演化规律和模式。这样的知识库我们称之为“事理图谱”。
事理图谱项目包含“构建”、“推理”和“应用”三个关键技术点:
(1) 事理图谱的构建
事理图谱的构建主要用到以下具体的自然语言处理技术:事件定义、开放域或限定域事件抽取,事理关系抽取(包含事件顺承、因果、上下位关系抽取等),事理关系置信强度计算,事件相似度计算,事件抽象与泛化等。
(2) 事理图谱的推理
事理图谱的推理可以用于事件及关系的补全,主要涉及到的技术有:结构化事件表示学习,短语级、句子级事件表示学习,事理图谱图结构上的图神经网络技术等。
(3) 事理图谱的应用
事理图谱的应用是指将构建好的事理图谱用于下游任务,例如消费意图识别和商品推荐、对话系统回复生成、股市涨跌预测、未来事件预测等,帮助提升具体任务的效果。此阶段用到的技术主要有:事理图谱的存储与查询(事件的搜索与匹配),事件表示学习,事理图谱表示学习等。
4.2 主要技术领域及当前发展热点
与事理图谱项目密切相关的技术领域主要包含以下几个方面:
(1) 常识知识库资源构建
传统的常识知识库资源构建主要围绕实体及其关系展开。2012年谷歌成功将大规模知识图谱商业化,显著改善了搜索结果的呈现方式,并提升了搜索引擎的用户体验。之后以实体为中心的知识图谱获得了长足的发展以及广泛的应用。时至今日,知识图谱仍然是学术界的一个发展热点。知识图谱上的知识表示学习、实体链接、实体消歧、知识图谱补全等等研究方向仍然是当下研究的热点问题。
然而,已有研究者注意到事件常识的重要性,部分最新的研究工作开始研究以事件为中心的常识知识库构建。
(2) 统计脚本学习
给出多个事件组成的上文,统计脚本学习研究下一个可能发生的事件是什么,可以认为是建模事件预测的能力。
传统方法多在无监督抽取的结构化事件链条上进行模型的搭建,这条技术路线仍然在发展当中,不断有新的模型涌现;最近,学者们提出故事结尾预测的评估方式,是对传统评估方法的进一步完善。
(3) 事件顺承关系抽取
由于语料标注的限制,事件时序关系抽取研究进展相当缓慢。虽然曾经连续举办多个技术评测,推动了该技术的发展,但是进步仍然十分有限。最近,时序关系抽取重新引起了学者的研究兴趣,有许多相关研究发表。从预料的构建,识别方法的改进等多个方面继续推动该研究走向使用阶段。目前,已有开放域的时序关系抽取系统发布。
(4) 事件因果关系抽取
文本中的因果关系抽取一直是一个难点。虽然学者们提出了许多方法,但是仍以因果模板匹配的方法抽取精确度最好。模板匹配的缺点在于召回率难以保证,许多有价值的因果关系无法召回。目前,高效准确的因果关系抽取方法仍然是一个难点及研究热点。
(5) 知识表示学习与网络表示学习
知识表示学习是指将知识图谱中的实体及关系映射到低维稠密向量,进而可以更加方便地用于后续任务当中。网络表示学习的研究对象不仅仅包含知识图谱这种网络,而是更广义上的网络。这两个研究方向都是当下研究的热点问题,属于事理图谱应用阶段的实用技术。
5. 金融事理图谱V2.0版本发布
2018年9月10日,HIT-SCIR正式对外发布金融事理图谱V1.0版本,经过近10个月的潜心研发,HIT-SCIR推出金融事理图谱V2.0版本,相对于V1.0版本,V2.0版本进行了如下的改进。
表2 金融事理图谱1.0版本与2.0版本对比
金融事理图谱v1.0 |
金融事理图谱v2.0 |
|
URL |
http://eeg.8wss.com/ |
http://elg.8wss.com/ |
数据源 |
北京语言大学新闻语料、腾讯、网易、股吧、和讯、Resset等网站的金融新闻 |
北京语言大学新闻语料、腾讯、网易、股吧、和讯、Resset、新浪、中财网、中金在线、证券之星等网站的金融新闻、金融领域微信公众号、研报 |
数据规模(文档数) |
11,653,062 |
12,121,279(增加100余万篇文档) |
具体事件数 |
1,348,459 |
2,187,086(增加80余万个事件) |
具体因果关系数 |
1,410,642 |
1,607,638(增加近20万个因果关系) |
抽象事件数 |
- |
2,021,289 |
抽象因果关系数 |
- |
414,777 |
上下位关系数 |
- |
1,883,792 |
因果关系抽取F值 |
59.54% |
85.12%(提升约26%) |
金融事理图谱V2.0版本扩充了数据源,扩大了数据规模,增加了事件节点数量以及因果关系数量,同时增加了事件上下位关系以及抽象事件和抽象因果关系,采用基于BERT+CRF的方法将因果关系抽取的F值由原来的59.54%提升到了85.12%。
结束语
知识图谱在各个领域精耕细作,逐渐显露价值。知识表示形式有待突破,推理能力有待提高。统计脚本学习和事件关系识别等事理图谱相关研究越来越吸引研究者关注。以“谓词性短语”为节点,以事件演化(顺承、因果、上下位等关系)为边的事理图谱方兴未艾。事理图谱必将在预测、对话等领域发挥重要作用,有力地提升人工智能系统的可解释性。
详细论文请参考:https://arxiv.org/pdf/1907.08015.pdf