全球第三!超星未来在顶会CVPR 2020低功耗视觉竞赛斩获佳绩

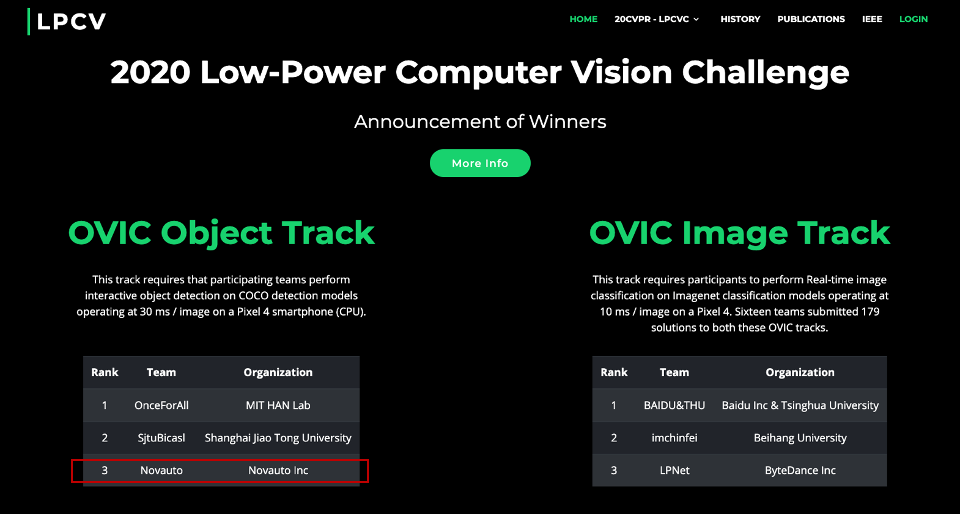
(大赛官网公布的竞赛结果[1])
CVPR2020低功耗计算机视觉竞赛(LPCVC)近期公布了竞赛结果,超星未来在四十六支团队、四个赛道提交的378个解决方案中脱颖而出,荣获低功耗计算机视觉竞赛全球第三名的好成绩,竞赛的第一名由MIT摘取。
低功耗计算机视觉竞赛(LPCVC)始于2015年,旨在推动高效利用能源的计算机视觉技术的发展,涵盖多个计算机视觉方向的尖端前沿挑战,例如目标检测、图片分类等。
今年的LPCVC在被誉为计算机视觉领域“奥斯卡”——CVPR2020(2020年国际计算机视觉与模式识别会议)的研讨会中举办。
本次超星未来参加的竞赛单元是目标检测赛道。目标检测,是目前计算机视觉技术创新中极为重要的基础问题,也是解决分割、跟踪等问题的基础,在自动驾驶等领域有着重要应用。
参赛方被要求在Google Pixel 4智能手机的CPU(单核模式)上实时运行COCO检测模型,处理速度需要达到30ms/image。比赛组委会根据往年比赛的最优结果和Google MobileNet系列模型来确定帕累托边界,用于评价和比较不同参赛方案的好坏,衡量性能的提高。
如何让深度学习模型在资源受限的边缘计算设备上实现实时运行是一个巨大的挑战。
超星未来参赛团队通过模型架构搜索、剪枝、蒸馏、量化等技术,设计端到端的高能效轻量化神经网络架构,并成功部署到高通骁龙855CPU上。实现了22.7% mAP的精度,将模型运行时间压缩到24ms。
这标志着超星未来在轻量化神经网络架构设计领域达到全球一流水平。
超星未来的技术模型
01
轻量化的模型架构
1.1 深度分离卷积
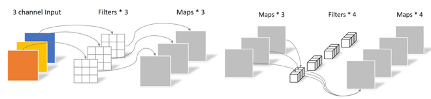
我们通过深度可分离卷积(depthwise separable convolution)来替换常规卷积,以实现轻量化的神经网络架构。深度可分离卷积通常由depthwise convolution和pointwise convolution两个部分组成,用来提取图像特征[2]。相比常规卷积操作,深度可分离卷积的参数数量和运算成本较低,因此在CPU这类的边缘计算设备上的执行效率较高。
(DepthWise Convolution & PointWise Convolution)
对于同样效果的常规卷积(例:输入维度为3,输出维度为4),需要3x3x3x4=108个参数,而分离卷积只需要3x3x3 + 1x1x3x4 = 39个参数,大大减少了参数量和计算量。
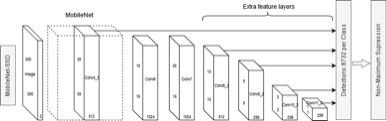
1.2 MobileNetV3+SSD(Single-shot Detection)架构
我们采用了轻量化的MobileNet作为骨干网络,与轻量化的SSD检测网络结合,具有内存占用少、运算成本低等优点。
02
知识蒸馏
知识蒸馏是通过将精度较高的Teacher网络的知识迁移到Student网络,在保证Student网络体积较小前提下,提升其性能的一种方法。
对于分类网络,只需要对最终的分类结果进行蒸馏即可 [3]
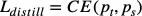
其中,p_t和p_s分别为Teacher网络和Student网络的输出,CE为CrossEntropyLoss函数,即要求Student网络学习Teacher网络的预测结果。
而对于Anchor-based的检测网络,最终会输出数千个Anchors的分类和回归结果,直接对所有预测结果计算分类的Distillation Loss会产生严重的类别不平衡问题,我们采用了Adaptive Distillation[4]来进行蒸馏:
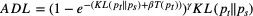
其中
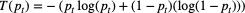
表示Teacher输出的熵,即Teacher的输出越不确定,该项loss的权重越大;
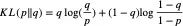
表示Teacher和Student输出的分布之间的距离,即如果Student的预测结果与Teacher相差越远,该项loss的权重越大。
从而解决了检测任务的知识蒸馏中类别不平衡的问题,能在原始网络基础上进一步提升性能。
03
模型压缩
为了缓解模型计算量与边缘计算设备算力差距的问题,模型压缩是目前主流的优化手段。模型压缩包括剪枝、量化等技术,主要解决的问题是在减少模型计算量的同时尽量降低模型精度损失。我们采用了结构化剪枝的策略,并基于敏感度分析的结果对目标检测模型进行自动剪枝。我们将自动剪枝与知识蒸馏相结合,实现了一套完整的模型压缩流程。
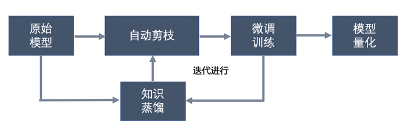
轻量化神经网络架构设计的落地应用场景
如今,深度神经网络在自动驾驶任务中得到了广泛的应用,例如图像目标检测、图像分割、点云目标检测、点云分割等多元算法。越来越强大的神经网络模型被研究人员设计出来,自动驾驶边缘计算设备的算力瓶颈也逐渐凸显,并导致神经网络模型部署后难以达到实时性要求。
没有一个统一的模型架构能够适用于不同类型的边缘计算设备,我们应该结合硬件的特性,为不同的设备提供最适合的模型。综合考虑模型精度、速度、功耗等指标,通过硬件友好的模型优化,充分挖掘硬件算力,实现软硬件协同优化。
基于此,超星未来开发了NOVA-X自动模型优化工具链
NOVA-X自动模型优化工具链
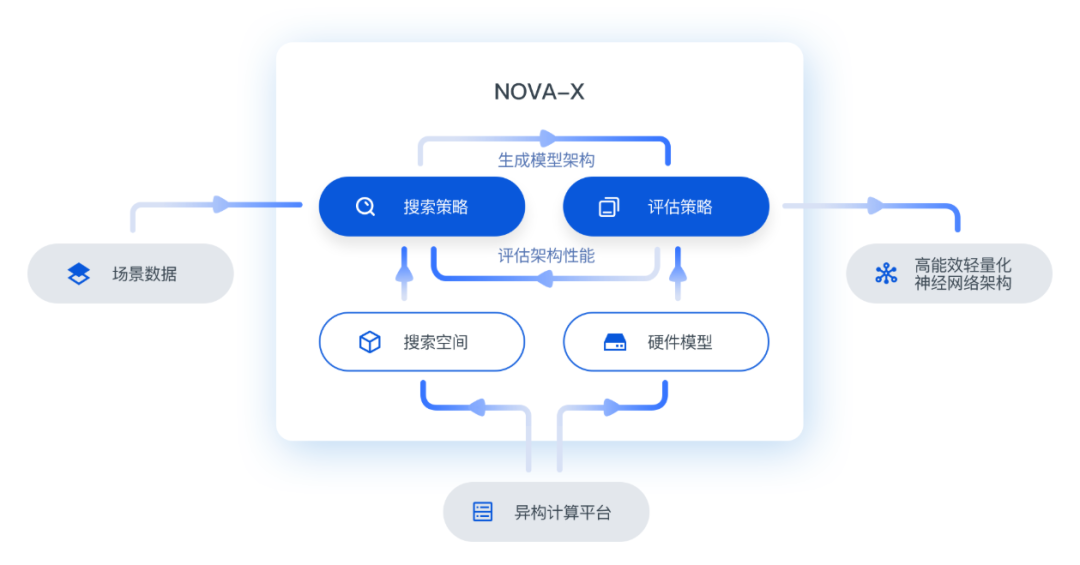
-使用前沿的自动化机器学习技术解决计算平台的系统优化和效率问题,支持主流芯片方案及常见深度学习框架(Pytorch/TensorFlow/Caffe等)。
-实现硬件友好的网络模型架构优化,满足模型的精度、延迟和功耗等各项指标的优化要求,大幅降低对人工经验的设计依赖。
-支持包含视觉、点云感知及高精度定位等自动驾驶任务的优化,可在保证精度的前提下实现数量级的实时性能提升,处于国际领先水平。
NOVA-X自动模型优化工具链优化效果
测试平台:Nvidia Jetson AGX Xavier
测试模式:FP32

原始YoloV3目标检测
模型运行帧率 16 FPS

优化后的YoloV3目标检测
模型运行帧率 50 FPS
欢迎加入

深度学习算法优化工程师/实习生
岗位职责:
1. 实现模型结构搜索算法、参与开源框架的开发
2. 参与自动化神经网络剪枝工具的开发
职位要求:
1. 有扎实的编程基础,了解常用算法及数据结构,熟练使用Python/C++
2. 熟悉一种或几种主流机器学习框架及内核原理(如Pytorch/TensorFlow/Caffe)
满足以下条件者优先:
3. 有模型剪枝(ChannelPruning / FilterPruning)相关经历者优先
4. 有模型结构搜索(AutoML/NAS)相关经历者优先
5. 有检测/分割算法相关经历者优先
有兴趣的小伙伴请投递简历至邮箱:
tianyi.lu@novauto.com.cn
参考文献
[1]2020 Low-Power Computer Vision Challenge Announcement of Winners. https://lpcv.ai
[2]Howard, Andrew, et al. "Searching for mobilenetv3." Proceedings of the IEEE International Conference on Computer Vision. 2019.
[3]Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network."arXiv preprint arXiv:1503.02531(2015).
[4]Tang, Shitao, et al. "Learning efficient detector with semi-supervised adaptive distillation." arXiv preprint arXiv:1901.00366 (2019).
关于超星未来 (Novauto)
北京超星未来科技有限公司成立于2019年,是清华大学车辆与运载学院及清华大学电子工程系跨学科创新的成果。超星未来围绕异构硬件加速、智能驾驶中间件、自动模型优化工具链等核心技术进行了深入研究,希望通过具备自主知识产权的研究和开发,连接产业以及国内外市场上下游,为智能驾驶实现不同场景下的应用和落地赋能,让智能驾驶更简单。


