数据库SQL和分布式不可兼得?这一架构也许是答案
分布式数据库技术发展多年,但是在应用、业务的驱动下,分布式数据库的架构一直在不断发展和演进。
开源金融级分布式数据库SequoiaDB,经过6年的研发,坚持从零开始打造数据库核心引擎。在技术探索中,选择了更适合云数据库场景的架构和引擎设计。本文也将详细展开,介绍目前SequoiaDB的架构与设计理念。
SequoiaDB近日也完成由嘉实投资领投的C轮融资。本轮的领投方为嘉实投资,启明创投与DCM作为早期投资方跟投。SequoiaDB巨杉数据库一直坚持技术驱动产品,专注打造金融级分布式数据库,成为中国首次入选Gartner数据库报告的数据库厂商。目前,巨杉数据库付费企业级客户与社区用户总数超过1000家,并已在超过50家500强级别的银行、保险、证券等大型金融机构核心生产业务上线。
Multimodel多模数据库引擎
在云计算与分布式时代,为单一结构化数据服务的传统关系型数据库也开始了不断地发展。从2007年IBM DB2支持XML以来,越来越多的关系型数据库开始支持XML与JSON等半结构化数据。因此,Gartner认为未来数据库的发展方向是多模式的时代,一款成熟的数据库产品需要利用分布式技术,支持除了关系型以外的多种访问方式。
SequoiaDB则是一款典型的多模(Multi-Model)数据库,全面覆盖了结构化、半结构化与非结构化数据,同时满足交易、影像存储业务、以及统计分析业务的需求。
SequoiaDB通过其计算存储分离架构,在NewSQL结构化数据领域有效利用MySQL、SparkSQL与PGSQL解析执行器,在保持行业标准100%兼容的同时,完美实现了在线交易与离线分析的HTAP混合交易分析负载的支撑。同时SequoiaDB使用API满足企业对半结构化JSON数据的支持,以及通过兼容Posix文件系统以及S3接口实现了非结构化数据的存储与访问。
SequoiaDB存储使用双引擎架构,将文件大对象与数据记录分别以最优的结构进行解析与存放,上层辅以统一的事务管理、集群管控、同步复制、会话管理等机制,支持数据与会话的逻辑与物理隔离,使其最大化满足云时代的分布式管理与混合业务负载需求。
2017年底SequoiaDB发布了其3.0版本。在其发展路径中可以看到,SequoiaDB的每一个大版本迭代均在之前的版本上进行了巨大的扩展与增强。其中,2013年正式发布的1.0版本作为单纯的JSON数据库,提供了对半结构化数据的支撑能力。而到了2015年的2.0版本,SequoiaDB开始完全支持了对象存储。直到2017年底发布的3.0版本更是提供了对MySQL、PGSQL与SparkSQL的完美对接与100%兼容,全面支持NewSQL的分布式事务处理能力。
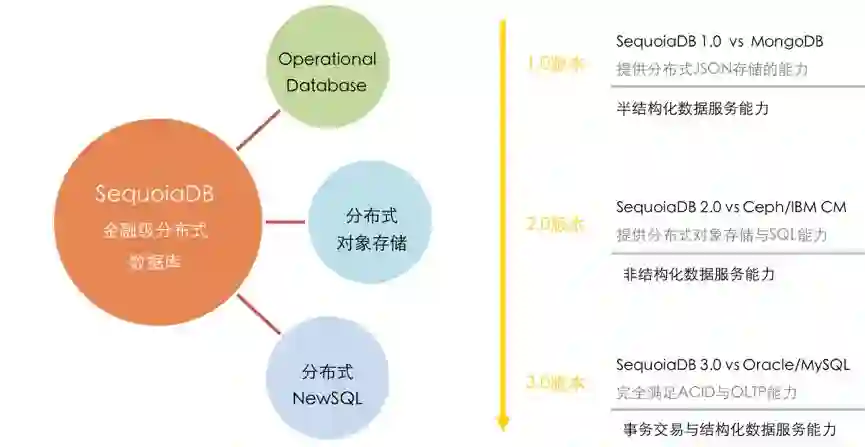
SequoiaDB产品 发展历程
计算-存储分离架构
当前业界中常见的分布式架构包括分库分表与计算存储分离两类。其中分库分表架构以应用中间件切分或MyCat等产品为代表。而如果说分库分表架构是基于传统数据库进行简单的上层封装,真正的计算存储分离架构则意味着在SQL解析与底层的数据存储均可进行自由的弹性扩展。
当前行业中最主流的云数据库实现(例如AWS的Aurora、阿里云的PolarDB等)即通过将MySQL服务器直接构建在底层的分布式高性能存储之上,通过定制化标准的SQL引擎与底层数据通讯接口,实现底层分布式存储与上层的SQL解析执行器完全松耦合,两者均可自由动态伸缩。
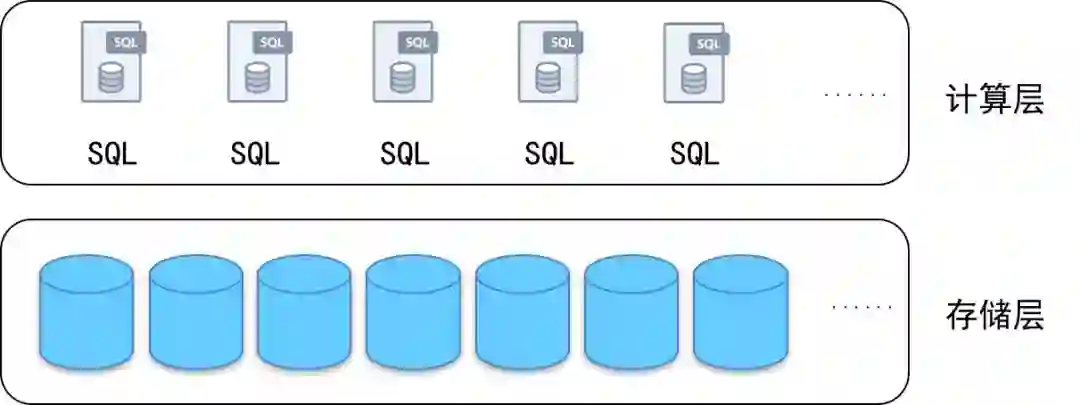
计算(SQL)-存储分离架构示意
计算存储分离体系的设计思想是以松耦合的方式将计算与存储层分别部署,通过标准接口或插件对各个模块和组件进行无缝替换,在计算层与存储层均可实现自由的弹性伸缩。MySQL与MariaDB的架构可以说是关系型数据库计算存储松耦合结构的代表。在MySQL 5.7及之前的版本中,其SQL解析引擎与后台的数据存储内核通过几百个C++函数进行通讯。因此,在MySQL数据库中,DBA可以选择InnoDB、MyISAM、NDB、Memory、甚至自己实现一套数据库引擎来与前端的SQL解析执行器进行对接。
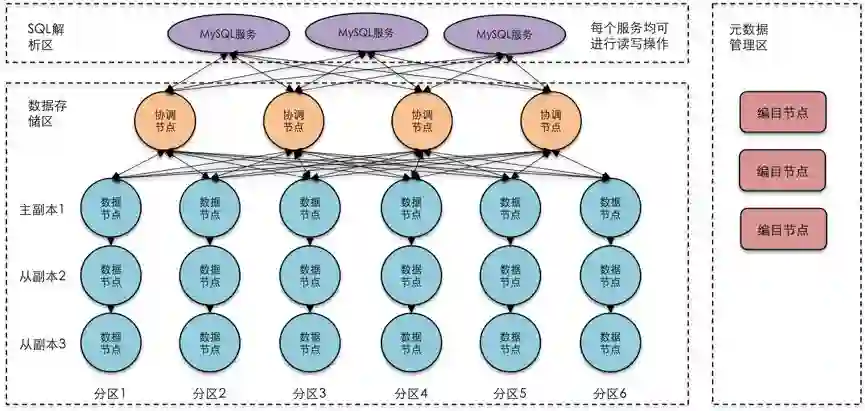
分布式数据库“计算-存储分离”架构详细示意
计算存储分离架构的优势之一在于,用户可以根据自身的业务特征自由选择面向交易的SQL解析器(例如MySQL或PGSQL),或面向统计分析的执行引擎(例如SparkSQL)。众所周知,使用不同的SQL优化与执行方式,数据库的访问性能可能会存在上千上万倍的差距。计算存储分离的核心思想便是在数据存储层面进行一体化存储,而计算层面则有效利用每种执行引擎的特点,针对不同的业务场景进行选择和优化。
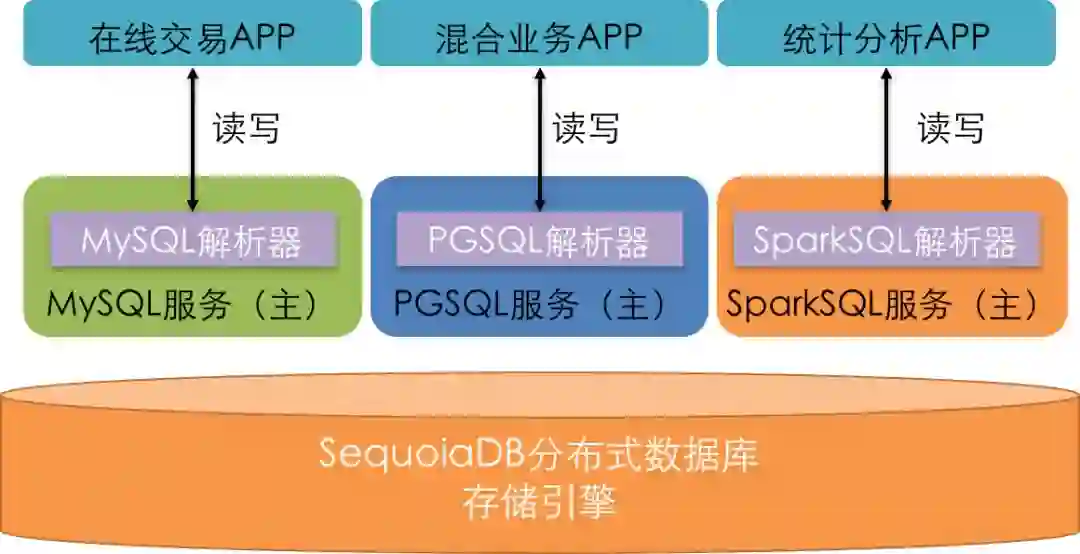
SequoiaDB架构示意
同时,由于数据存储层与计算层完全分离,用户完全可以在存储层进行逻辑与物理的隔离,将面向高频交易的前端业务,与面向高吞吐量的统计分析使用不同的硬件进行存储,确保在多类型数据访问时互不干扰,以真正达到生产环境可用的多租户与HTAP能力。
得益于SequoiaDB 3.0的分离架构,整个数据库可以通过自由对接不同的执行引擎,对同一份数据以不同的接口进行访问。同时,SequoiaDB可以通过配置,指定在线业务访问三副本中的两份,而另一份则专门供SparkSQL进行统计分析,从而做到对同一份数据的访问,在线应用与统计业务在物理硬件层面完全隔离。
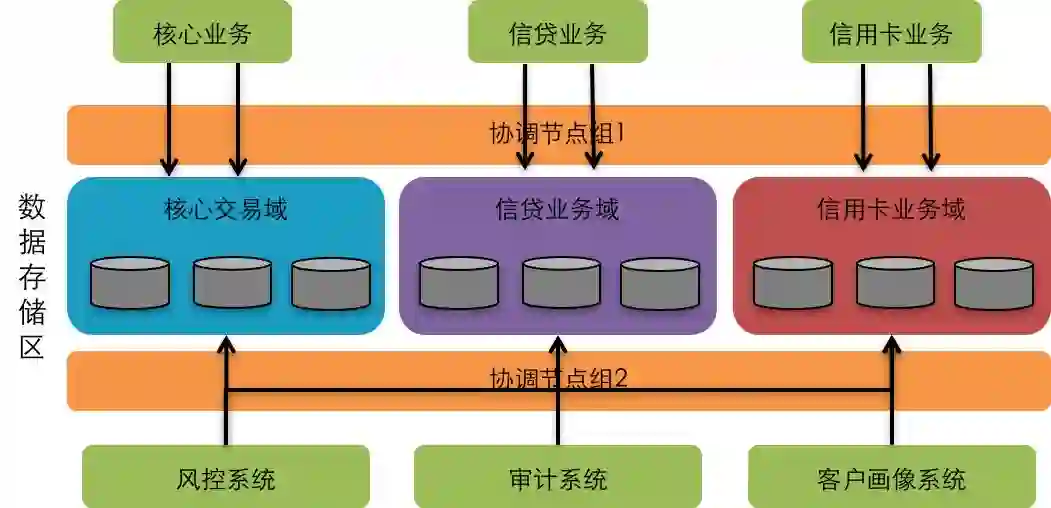
计算-存储分离架构下的业务灵活隔离划分
对于在线交易业务来说,由于所有的分布式事务、锁、索引等机制都是直接在底层的分布式引擎完成,上层使用任何SQL解析器都可以做到完全的ACID。
弹性伸缩
在云计算的时代,任何应用程序与中间件早已经通过微服务架构实现了动态扩容缩容。例如,企业可以在双十一高峰前大规模租赁AWS或阿里云的服务器,将应用程序的计算与处理能力几十倍地扩张。
但是,不同于应用程序,数据层面的弹性伸缩能力往往是应用程序扩展性最大的制约。例如,应用程序可以在一天内不停机地从3个Tomcat服务器扩展到30个,但底层的数据分库分表机制几乎不可能轻松自如地增减数据库的服务节点。
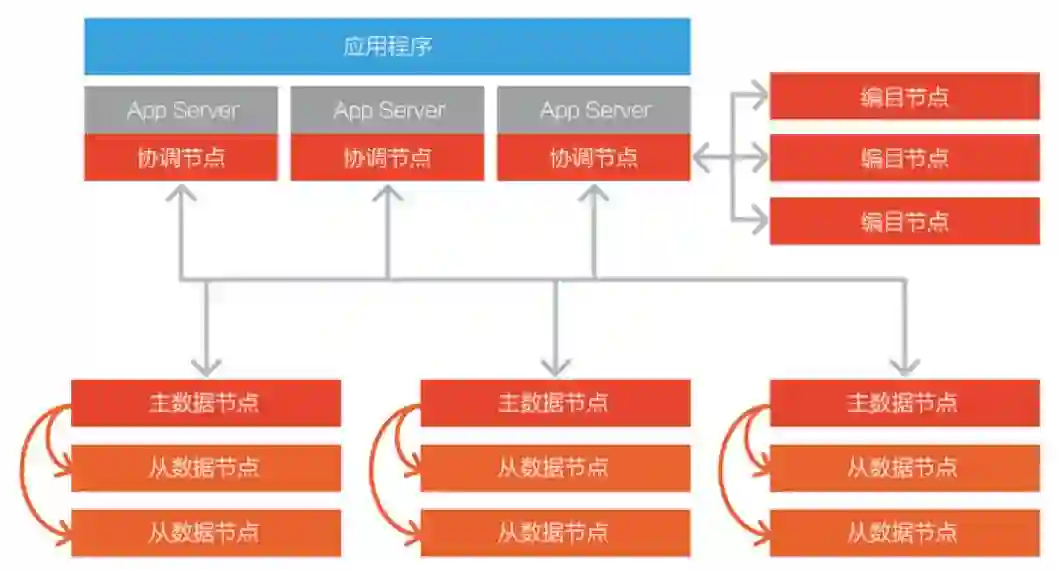
SequoiaDB存储引擎原生分布式架构
SequoiaDB通过一致性散列等机制,对底层数据库扩容缩容做到完全在线且对应用透明无感知。对于需要存放大量数据的流水类业务,SequoiaDB甚至能够提供“零数据迁移”策略,确保增加节点后系统不会产生任何需要产生大量I/O的后台重平衡操作。
SequoiaDB可以通过增加数据分区与数据节点数量,对整个集群的存储容量与计算能力进行弹性水平横向扩张。
MySQL全兼容
SequoiaDB通过“计算-存储分离”架构,提供了应用程序层面的MySQL全兼容能力。SequoiaDB直接利用在MySQL官网下载的MySQL Server,通过其存储引擎插件的能力,提供了平行于InnoDB的SequoiaDB分布式存储引擎插件。
SequoiaDB完全利用了大家多年来所习惯使用的MySQL数据库服务,对于应用程序开发人员与DBA来说并不需要学习任何新的知识与语法,便可以无缝地将其应用程序从传统的单点架构迁移到分布式数据库。在从InnoDB存储引擎向SequoiaDB分布式引擎切换时,所有的数据分区机制对上层应用程序完全透明零感知。同时SequoiaDB也提供了包括离线、在线、实时等多种迁移工具,供用户在不同场景下进行选择。
如今MySQL已经被大量互联网与企业级用户所使用。相比起需要重新构建SQL解析器与执行器的分库分表策略,SequoiaDB的计算-存储分离架构能够最大化重用开发人员与DBA的原有技能,同时与MySQL社区保持紧密结合互动,通过其分布式存储能力参与到MySQL的生态建设。
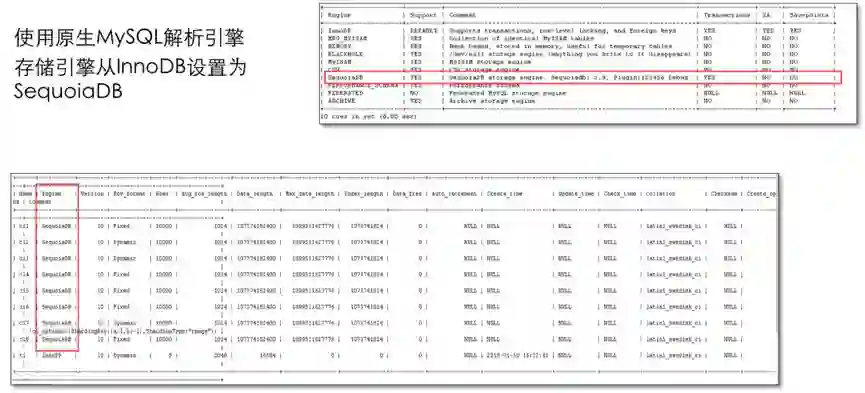
SequoiaDB对MySQL完整兼容示意
小结
以Multimodel多模数据存储引擎为基础,通过业界主流的计算-存储分离架构,实现引擎的分布式以及SQL层对于MySQL、PostgreSQL以及SparkSQL的完整兼容。这一整体架构设计相信是云数据发展的主流架构设计。
SequoiaDB正是应用了这一架构设计,实现了弹性扩张、多租户、HTAP支持、与MySQL全兼容等能力,这也使开源的SequoiaDB能够更加紧密地参与到社区建设中,为我国的数据库基础软件发展与MySQL社区的壮大贡献自己的力量!通过此次融资,巨杉数据库将持续投入核心研发与技术创新,立足于金融行业覆盖其他垂直领域市场,拓展更多企业级应用场景,加速国际化步伐,将巨杉数据库打造成为世界级的分布式数据库产品!


