强化学习《奖励函数设计: Reward Shaping》详细解读
深度强化学习实验室
作者: 网易伏羲实验室
编辑:DeepRL
一、整体介绍
在强化学习中,智能体的目标被形式化表征为一种特殊信号,称为收益,它通过环境传递给智能体。在每个时刻,收益都是一个单一标量数值。非正式地说,智能体的目标是最大化其收到的总收益。这意味着需要最大化的不是当前收益,而是长期的累积收益。我们可以将这种非正式想法清楚地表述为收益假设:
我们所有的“目标”或“目的”都可以归结为:最大化智能体接收到的标量信号(称之为收益)累积和的概率期望值。
使用收益信号来形式化目标是强化学习最显著的特征之一。
智能体总是学习如何最大化收益。如果我们想要它为我们做某件事,我们提供收益的方式必须要使得智能体在最大化收益的同时也实现我们的目标。因此,至关重要的一点就是,我们设立收益的方式要能真正表明我们的目标。特别地,收益信号并不是传授智能体如何实现目标的先验知识。例如、国际象棋智能体只有当最终获胜时才能获得收益,而并非达到某个子目标,比如吃掉对方的子或者控制中心区域。如果实现这些子目标也能得到收益,那么智能体可能会找到某种即使绕开最终目的也能实现这些子目标的方式。例如它可能会找到一种以输掉比赛为代价的方式来吃对方的子。收益信号只能用来传达什么是你想要实现的目标,而不是如何实现現这个目标。
这是Sutton在《Reinforcement learning: An introduction》中的一段话,清晰地展现了智能体是如何通过奖励信号沟通智能体与我们的目标。而奖励设计实际上是MDP中的一个关键元素 



但在实际工程中,奖励设计是一个深不见底的大坑,里面埋葬了很多工程师的大量时间。在大部分情况下,我们都要小心翼翼地不断调整参数,还要防止agent投机取巧找到刷分技巧。听说的一些比较有意思的案例有,用强化学习模仿作画,结果agent学会了白色大笔一挥,然后用小黑笔不断在画布上戳,以此刷分;还有用强化学习让机器人学习叠积木,把奖励设计在积木的底面高度上,结果机器人学会了把积木直接打翻成底面向上,就拿到了奖励。
而在实际工程中,即使没有出现agent刷分这样糟糕的情形,为了算法的效果,我们也需要对环境的奖励不断调优。特别是有关战斗AI,或者某种游戏的胜负,这样的场景中如果只用最终的结果作为奖励很可能太过于稀疏,导致最终训练效果不佳。而如果你为了解决这个问题开始针对具体问题设计奖励函数了,那么恭喜你,你接下来的很长一段时间都将在,训练-微调奖励函数-训练-微调奖励函数这样的循环中度过。
为了解决这个问题,一群世界上最聪明的小脑袋瓜开始思考,有没有什么奖励设计的方法,可以尽量减少调奖励函数的工作量呢。答案当然是有的,本篇文章就会从三个部分分别讲述奖励设计的一些方法。
Quick View
Reward Shaping
Intrinsically Motivated Reinforcement Learning
Optimal Rewards and Reward Design
本文的第一个内容是奖励塑造,主要会介绍基于势能的奖励塑造,这个方法要解决什么样的问题,又是怎样保证策略不变性,最后这个框架可以怎样应用。
第二个内容是内在激励的强化学习,当然目前的主要目标还是鼓励探索,现在的方法主要集中在两块吧,一个是基于预测误差的,一个是基于计数的。
第三个内容是最优奖励设计问题,其实是第二个内容的进一步扩展,是将试错搜索过程自动化以找到最优奖励。这类算法通常是双层优化问题,外层通过优化内层参数的方式来最大化外在奖励,内层是传统意义上的强化学习模型,使用外层提供的参数进行训练。
当然还有一些不属于以上三块的奖励设计方法,之后也会举几个例子。
Reward Shaping
通常来说,我们的强化学习算法会在某个马尔库夫决策过程(MDP)下运行,这个MDP可能会比较难,比如下面这个场景:
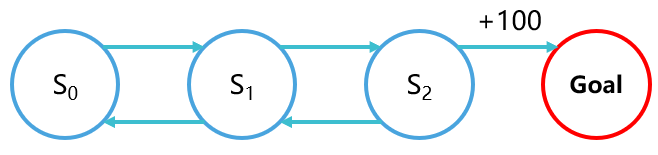
如果智能体从 

为了让这个MDP变得简单,我们希望把从
这样看起来学习难度就低了很多,你很满意,agent也很满意,一切看起来都是那么的美好。
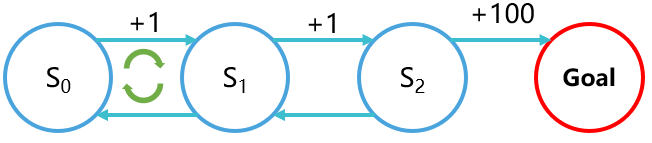
直到你发现一个问题,


吴恩达在1999年回答了这个问题。
1. Potential-based reward shaping(PBRS)
中文可以翻译为基于势能的奖励塑造,首先给一个定义

PBRS认为,如果奖励塑造函数是这样一种形式,就可以保证,

所以新的 


我们回到之前的那个问题来解释这种方法
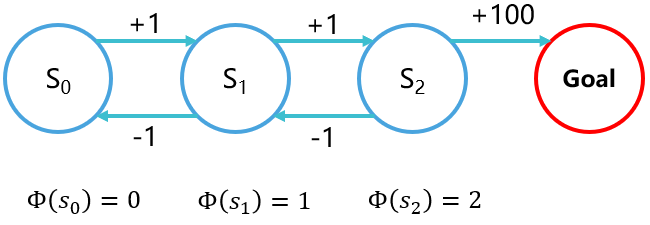
这相当于给每个状态一个势能,从势能低的地方到势能高的地方给正奖励,而从势能高的地方回势能低的地方给负奖励,这样就避免了之前的
这种方法可以保证最优策略的一致性,论文从充分性和必要性两个方面进行了证明:
(充分性)如果
是一个基于势能的奖励函数,那么任意
的最优策略也是
里的最优策略,反之亦然
(必要性)如果
不是一个基于势能的奖励函数,那么存在一个状态转移函数
和一个奖励函数
,可以使在
里的最优策略都不是是
里的最优策略


这里简单介绍充分性的证明,必要性的证明可以参考原论文。
在原Bellman方程两边同时减去一个 

因此,就可以得到策略一致的保证

Ng A Y, Harada D, Russell S. Policy invariance under reward transformations: Theory and application to reward shaping[C]//ICML. 1999, 99: 278-287.
Wiewiora E. Potential-based shaping and Q-value initialization are equivalent[J]. Journal of Artificial Intelligence Research, 2003, 19: 205-208.
2.Roadmap of Potential-based Reward Shaping
而基于势能的奖励塑造的发展路径有这样两个
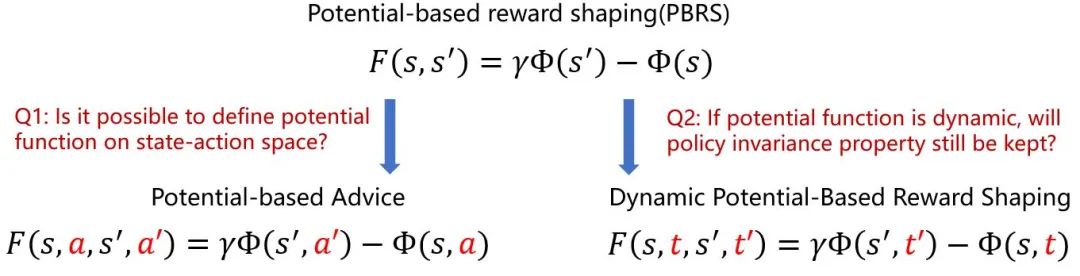
一个考虑为势能函数加入动作,这样就变成了基于势能的建议;一个允许势能函数随时间变化,这样就有了训练一个势能函数的可能性。
所以接下来就可以开始考虑这样的问题,PBRS要求必须有基于势能的先验知识,如果没有这个知识怎样去构造奖励函数呢,本文介绍三种思路:
From Reward Functions to Dynamic Potentials
Inverse Reinforcement Learning
Reward Shaping via Meta-Learning
Wiewiora E, Cottrell G W, Elkan C. Principled methods for advising reinforcement learning agents[C]//Proceedings of the 20th International Conference on Machine Learning (ICML-03). 2003: 792-799.
Devlin S M, Kudenko D. Dynamic potential-based reward shaping[C]//Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems. IFAAMAS, 2012: 433-440.
3.From Reward Functions to Dynamic Potentials
第一个思路源于这样一个思想,如果有一个任意的奖励函数,能不能把它改造成基于势能的奖励函数。
首先,他把之前讲到的Potential-based Advice和Dynamic Potential-Based Reward Shaping结合起来,得到了Dynamic Potential-Based Advice

这样,发现 


并且这种方法也有策略一致性保证

Harutyunyan A, Devlin S, Vrancx P, et al. Expressing arbitrary reward functions as potential-based advice[C]//Twenty-Ninth AAAI Conference on Artificial Intelligence. 2015.
4.Relative Entropy Inverse Reinforcement Learning (RE-IRL)
这种方法的思想很简单,上面第三种方法已经提供了将任意的奖励函数转换为Potential-based Reward Shaping 的方法,而逆强化学习又可以从专家数据中学习奖励函数,所以很自然的

直接将逆强化学习学到的奖励函数转换一下
Suay H B, Brys T, Taylor M E, et al. Learning from demonstration for shaping through inverse reinforcement learning[C]//Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems. 2016: 429-437.
5.Reward Shaping via Meta-Learning
基于元学习的奖励设计源于这样一个结论 

但这样是比较困难的,因此实际上的学习目标是

然后在使用Potential Function Prior进行Meta-Testing时

Zou H, Ren T, Yan D, et al. Reward shaping via meta-learning[J]. arXiv preprint arXiv:1901.09330, 2019.
6.小结
关于Potential-based reward shaping(PBRS)的介绍就先到这里,这个方法因为性质特别好,所以很多奖励设计的方法都是这类方法的延申,只是这类方法只保证了最优策略不变,并没有保证在新的奖励函数的帮助下agent学习会变得简单。事实上,学习是不是变得简单完全依赖于给出的奖励函数好不好,这等同于从一个深坑跳到了另一个深坑,因此坑底的一些聪明的小脑袋瓜开始思考,是不是有什么别的奖励设计方法呢……
Intrinsically motivated reinforcement learning
Sutton R S 在他的书里说(其实我觉得大概是另一个作者Barto A G说的,这个人是做奖励设计的大牛)
……强化学习智能体并不一定是一个完整的生物或机器人,它可以是一个更大的行为系统的一部分。这意味着收益信号可能被更大的行动智能体内部的事情所影响,例如动机、记忆、想法甚至幻觉。收益信号可能也依赖于学习过程本身的一些性质,比如衡量学习中进步了多少。让收益信号对这样的内部信息敏感,可以使智能体作为“认知架构”的一部分,学习如何控制认知架构,同时也可以获取一些特定的知识和技能,这些技能很难只依赖于外部的收益信号学习到。这种可能性导致了“内在激励的强化学习”这个思想……
Intrinsically motivated reinforcement learning,也就是内在激励的强化学习,是由Singh、 Barto和 Chentenez在2005年提出,在他们的论文中,内在激励由对下一个状态的预测误差给出: 
而类似的想法也经过很多讨论,比如Schmidhuber(1991a,b)讨论了收益信号是关于智能体的环境改善得有多快的一个函数。由 Klyubin、 Polani和 Nehaniv(2005)将智能体控制环境的能力作为内在的收益信号。而近年来,这类奖励函数主要分为两类:
Curiosity,好奇心,通过对状态转移的预测误差给出奖励信号
Visitation counts,访问计数,通过智能体对当前状态的访问次数给出奖励信号
Chentanez N, Barto A G, Singh S P. Intrinsically motivated reinforcement learning[C]//Advances in neural information processing systems. 2005: 1281-1288.
Schmidhuber J. Curious model-building control systems[C]//Proc. international joint conference on neural networks. 1991a: 1458-1463.
Schmidhuber J. A possibility for implementing curiosity and boredom in model-building neural controllers[C]//Proc. of the international conference on simulation of adaptive behavior: From animals to animats. 1991b: 222-227.
Klyubin A S, Polani D, Nehaniv C L. Empowerment: A universal agent-centric measure of control[C]//2005 IEEE Congress on Evolutionary Computation. IEEE, 2005, 1: 128-135.
1.Curiosity Driven Exploration in Reinforcement Learning
1.1 Variational information maximizing exploration(VIME)
在这个思路下的一个比较知名的工作是VIME,它的想法是将学习动态中的信息增益作为内在奖励信号。方法的核心是建模环境的状态转移概率 

其中, 
这一方法的内在奖励定义为信息增益,而信息增益可以理解为通过真实的状态转移 

在应用中,这一方法直接将内在奖励与外在奖励相加:

Houthooft R, Chen X, Duan Y, et al. Vime: Variational information maximizing exploration[C]//Advances in Neural Information Processing Systems. 2016: 1109-1117.
1.2 Large-Scale Study of Curiosity-Driven Learning
这篇论文讨论了不使用环境外在奖励完全依赖内在奖励,纯靠探索可以将策略学成什么样子。与之前论文类似,这篇文章将模型分为两个部分
一个网络负责将观察编码为
另一个网络负责预测


那么给定 

然后文章只依赖这一个奖励信号测试了很多环境

Burda Y, Edwards H, Pathak D, et al. Large-scale study of curiosity-driven learning[J]. arXiv preprint arXiv:1808.04355, 2018.
2.Count-based Exploration in Reinforcement Learning
2.1 Unifying Count-Based Exploration and Intrinsic Motivation
与大标题一样,基于计数的方法就是对访问过的状态计数,访问次数越少给的bonus越多。

但在深度学习中,状态可能非常多,那可能每一次的状态都有微微的不同,怎么办呢,虚拟计数。文章中讨论了一种从密度函数计算虚拟计数的方法,给定

其中 



所以这两个概率和虚拟计数的关系为

联立这两个方程,就可以得到

当然,这里的密度函数需要满足一些特殊要求,文章中称为Learning-positive density model,定义为
如果一个概率模型
,那么必须满足对任意的
和任意的
,都有




文章中采用的密度模型为CTS模型
Bellemare M, Srinivasan S, Ostrovski G, et al. Unifying count-based exploration and intrinsic motivation[C]//Advances in neural information processing systems. 2016: 1471-1479.
Bellemare M, Veness J, Talvitie E. Skip context tree switching[C]//International Conference on Machine Learning. 2014: 1458-1466.
2.2 Ex2: Exploration with exemplar models for deep reinforcement learning
EX2引入了GAN中的思路,通过分类器从以前看到的其他状态中区分一个给定状态的容易程度,来评估状态的新颖性。
算法的伪代码非常简单

其中,

分类器的loss函数如下

Fu J, Co-Reyes J, Levine S. Ex2: Exploration with exemplar models for deep reinforcement learning[C]//Advances in neural information processing systems. 2017: 2577-2587.
3.小结
内在激励的强化学习认为,我们应当给予智能体一些动机,鼓励智能体尝试去探索。从实验效果来看,这类方法成本低效果好,虽然没有策略一致性保证,但充分训练后bonus几乎都会趋于0,所以几乎也不用担心训练出来的策略不是原问题的最优策略。但为了解决这一问题,如果可以提供一个外在目标,以此为目标来设计内在奖励是不是就能保证内在奖励的最终目标,仍然是原问题的目标,这就引申出了第三部分的内容,Optimal Rewards and Reward Design。
Optimal Rewards and Reward Design
另一个找到好的收益信号的方法,是将试错搜索过程自动化以找到好的信号。从应用角度来说,收益信号是学习算法的一个参数。正如我们可以对算法的其他参数所做的那样,我们可以自定义可行的搜索空间,然后用优化算法自动优化这些收益信号。优化算法是这样评估每一个候选收益信号的:以该收益信号运行强化学习算法若干步,然后用一个包含设计者真实目标的“高级”目标函数来计算评分,不需要考虑该智能体的局限。甚至可以通过在线梯度上升来提升收益信号,其中梯度来自于高级的目标函数(Sorg、 Lewis和 Singh,2010)。把这个算法与真实世界相联系的话,优化高级目标函数可以类比为进化,其中高级优化函数代表动物的进化适应程度,这通过能活到繁殖年龄的后代数量来衡量。
这种具有上下两层优化算法(一层类似手进化,另一层是智能体个体的强化学习)的计算实验已经证实,直觉本身并不总足以用来设计一个好的收益信号( Singh、 lewis和 Barto,2009)。利用高级目标函数所衡量的强化学习智能体的性能表现,可能会对智能体收益信号的某些细节方面特別敏感,这些敏感性来源于智能体本身的局限以及它在其中活动和学习的环境。这些实验也表明一个智能体的目标不应该总是与智能体设计者的目标一致
最初这件事情显得很反直觉,但是对于一个智能体而言,它不可能不管收益信号是什么就达到设计者的目标。智能体需要在很多限制下学习,例如有限的计算能耗、有限的环境信息或者有限的学习时间。当有这样那样的限制的时候,学习去达成一个与设计者目标不同的目标,而不是直接去追求设计者的目标,这可能有时会更加接近于设计者的初衷。
在详细解释这类方法的动机之前,我们先做一些概念说明
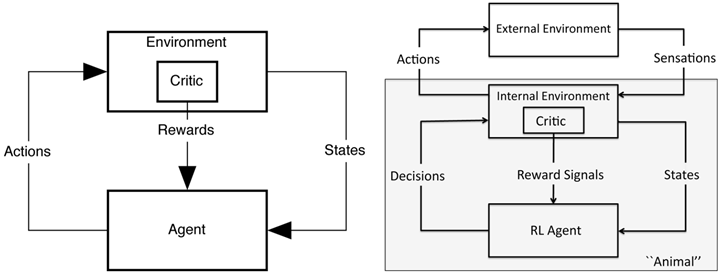
首先智能体的奖励信号会分为外部奖励和内部奖励,外部奖励在某些论文中会以适应性函数fitness function的形式给出,智能体的目标就是最大化这个fitness。而最优奖励函数 
那为什么通过学习另一个目标可以比直接学习原来的目标学的更好呢,这件事确实很反直觉,因此我们在这里举一个例子,这个例子是论文Where do rewards come from中的一个实验,实验名为Hungry-Thirsty Domain,它描述了这样一件事,智能体需要在一个grid world中寻找食物,agent的目标是智能体不要在Hungry状态(每一个时刻处于not Hungry状态fitness会增加1),喝水不会有任何奖励或惩罚,但如果agent状态是Thirsty的,会导致在食物处也无法进食。
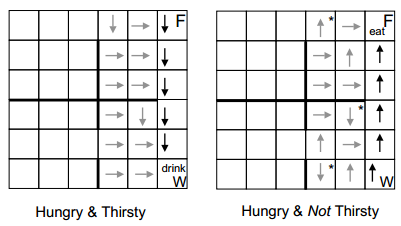
作者检验了这么几类reward
simple fitness-based reward functions,仅在fitness增加时给一个正奖励(也就是not Hungry状态给正奖励)
fitness-based reward functions ,在fitness增加时给某个奖励,其他状态某个奖励
other reward functions,其他形式的奖励函数
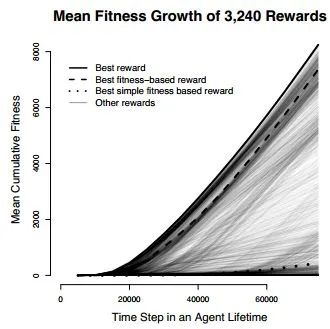
然后作者开始穷举这些奖励参数,实验之后发现,对于simple fitness-based reward functions,即使是最好的参数agent表现也非常糟糕。最好的奖励函数是
ht : hungry and thirsty, -0.05
hnt : hungry and not thirsty, -0.01
nht : not hungry and thirsty, 1.0
nhnt : not hungry and not thirsty, 0.5
智能体的表现与Hungry时对Thirsty的惩罚有关(hnt - ht),最优的惩罚效果在0.04处取得,但需要注意的是只有一小部分惩罚会比惩罚为0.0的表现要好
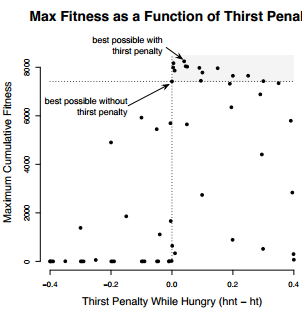
这样就说明了这一件事,外在奖励很可能会缺失某些必要的信息,而内在奖励可以通过填补这些信息提高agent在fitness函数的表现。
Singh S, Lewis R L, Barto A G. Where do rewards come from[C]//Proceedings of the annual conference of the cognitive science society. Cognitive Science Society, 2009: 2601-2606.
Singh S, Lewis R L, Barto A G, et al. Intrinsically motivated reinforcement learning: An evolutionary perspective[J]. IEEE Transactions on Autonomous Mental Development, 2010, 2(2): 70-82.
1. Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
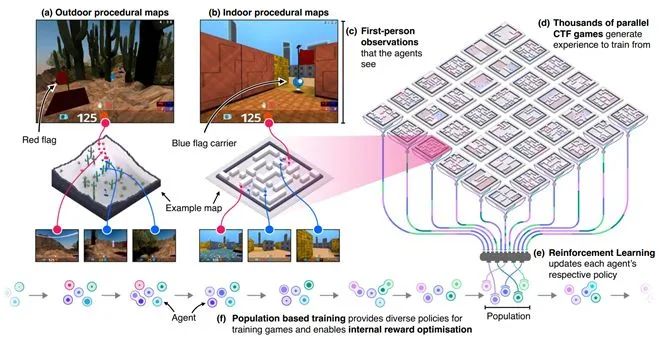
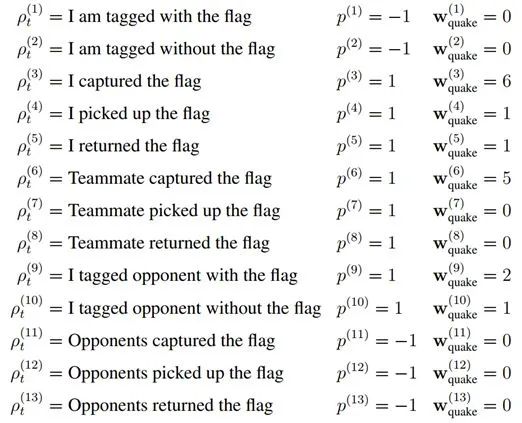
事实上,Deepmind也意识到,奖励函数的设计是一个深坑,能不能通过进化计算的方式去得到一个最好的奖励函数呢,他们在一个FPS游戏Quake III Arena Capture the Flag上实现了这一思路,当然Deepmind并不只优化了奖励参数,他们也一同优化了智能体的超参数,这个算法的优化目标可以表示为

其中 
这篇文章提供了一个在复杂游戏中设计奖励函数的思路,只是进化计算的计算量可能会让大部分研究组织难以承受,因此接下来会介绍基于梯度的奖励函数优化算法。
Jaderberg M, Czarnecki W M, Dunning I, et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning[J]. Science, 2019, 364(6443): 859-865.
2.Policy Gradient for Reward Design
这篇文章的伪代码非常简单

我们主要介绍它是如何用外在奖励指导内在奖励更新的,首先,PGRD的优化问题表示为

总体的优化目标定义为 



PGRD的是基于动态规划(DP)的强化学习算法,其策略为

可以看到,策略是Q值的函数,而Q值是递归d层计算的

所以Q值是 




这个梯度分为两个部分,第一部分梯度 



这个梯度的计算方式来源于论文Apprenticeship learning using inverse reinforcement learning and gradient methods,这样的形式是使用了一个log技巧得到的。
接下来

Sorg J, Lewis R L, Singh S P. Reward design via online gradient ascent[C]//Advances in Neural Information Processing Systems. 2010: 2190-2198.
3.Policy-Gradient for Reward Design with Deep Learning
PGRD-DL是PGRD的深度版本,主要改进是内在奖励的参数修改为使用CNN计算,其总体奖励为

另外Q函数的计算方式改为UCT

这篇论文的梯度更新为

虽然形式略有区别,但和上面那篇论文基本一致, 

Guo X, Singh S, Lewis R, et al. Deep learning for reward design to improve monte carlo tree search in atari games[J]. arXiv preprint arXiv:1604.07095, 2016.
4.Learning Intrinsic Rewards for Policy Gradient
这篇论文的idea我非常喜欢,不同于上面两篇文章,这篇论文的算法几乎可以用于强化学习的大部分算法。
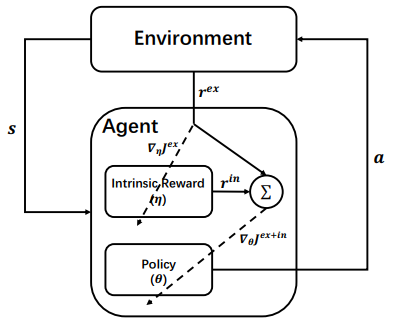
总的来说也是通过外在奖励优化内在奖励,并使用外在奖励和内在奖励的和更新策略,具体的符号约定如下

LIRPG通过更新动态来计算内在奖励的梯度,更新动态定义为一次更新的梯度变化

而梯度也通过更新动态产生

与PGRD类似,梯度也可以分为两个部分,一个是外在奖励对策略的梯度

而更新动态到内在奖励函数的梯度为

另外这篇文章的作者也做了一个后续的RNN版本,但和LIRPG区别不大就不详细介绍了
Zheng Z, Oh J, Singh S. On learning intrinsic rewards for policy gradient methods[C]//Advances in Neural Information Processing Systems. 2018: 4644-4654.
Zheng Z, Oh J, Hessel M, et al. What Can Learned Intrinsic Rewards Capture?[J]. arXiv preprint arXiv:1912.05500, 2019.
5.小结
到这里本次的分享就快要结束了,实际上这一部分的方法是我最喜欢的内容,因为双层优化的问题看起来十分漂亮,只是现在这个优化问题依然没有很好的解决思路,强如Deepmind在2019年Science上发的文章也依然是使用进化策略优化参数的。而近年来,LIRPG这样的论文只是看起来很美,我们在论文复现中发现,LIRPG由于所有的内在奖励都由同一个网络产生,一点小的变化都会引起一条episode的累积奖励的巨大变化,因此极易引起梯度爆炸等问题。论文本身在实验部分的结果也不是非常好,但不管怎么说,这篇论文还是提供了一个非常好的思路,并启发了这个方向的研究。
Conclusion
照例引用Sutton在《Reinforcement learning: An introduction》中的一段话作为结尾
收益信号并不是传授智能体如何实现目标的先验知识。收益信号只能用来传达什么是你想要实现的目标,而不是如何实现現这个目标。
奖励设计是一个被广泛研究的问题,但目前种种方法都有他们独特的优势和不可避免的弱点,大概这就是天下没有免费的午餐吧。
知乎地址:https://zhuanlan.zhihu.com/p/170523750
完
总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第77篇:深度强化学习工程师/研究员面试指南
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)





