RocketMQ 一行代码造成大量消息发送失败


作者 | 丁威
来源 | 中间件兴趣圈

问题现象
首先接到项目反馈使用 RocketMQ 会出现如下错误:
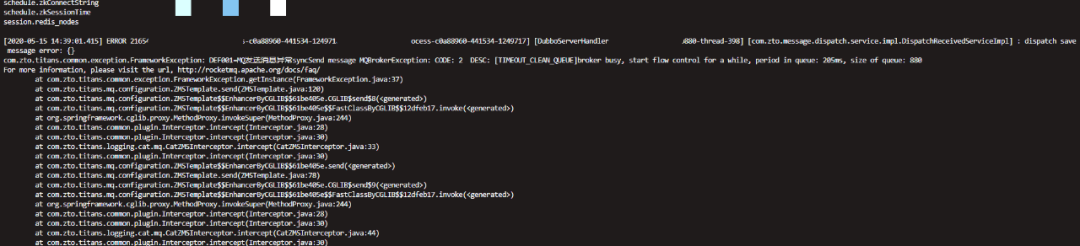
错误信息关键点:MQBrokerException:CODE:2DESC:[TIMEOUT_CLEAN_QUEUE]broker busy,start flow control for a while,period in queue:205ms,size of queue:880。
由于项目组并没有对消息发送失败做任何补偿,导致丢失消息发送失败,故需要对这个问题进行深层次的探讨,并加以解决。

问题分析
首先我们根据关键字:TIMEOUT_CLEAN_QUEUE 去 RocketMQ 中查询,去探究在什么时候会抛出如上错误。根据全文搜索如下图所示:
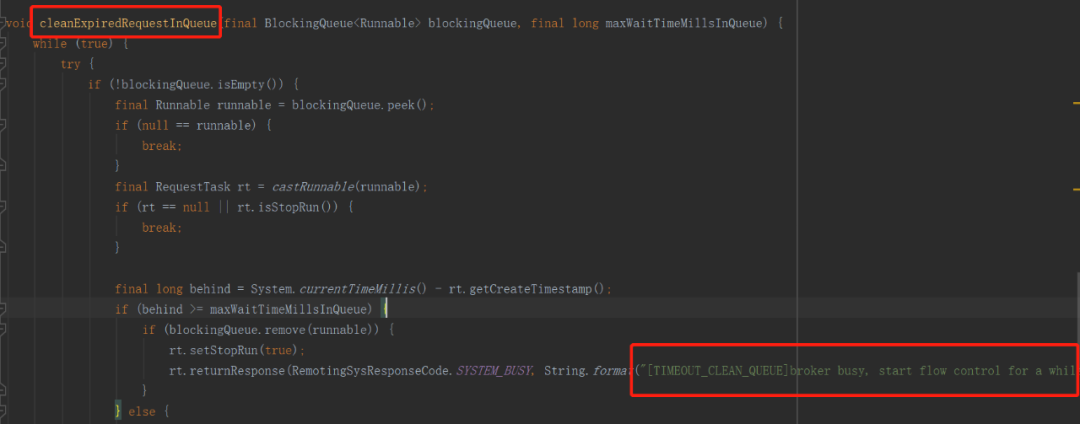
该方法是在BrokerFastFailure中定义的,通过名称即可以看成其设计目的:Broker端快速失败机制。
Broker端快速失败其原理图如下:
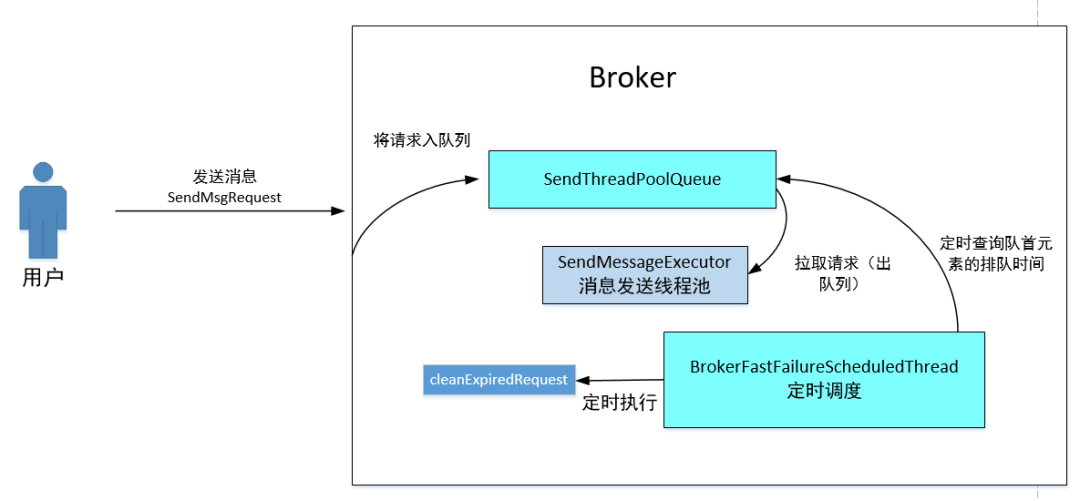
消息发送者向 Broker 发送消息写入请求,Broker 端在接收到请求后会首先放入一个队列中(SendThreadPoolQueue),默认容量为 10000。
Broker会专门使用一个线程池(SendMessageExecutor)去从队列中获取任务并执行消息写入请求,为了保证消息的顺序处理,该线程池默认线程个数为1。
如果Broker端受到垃圾回收等等因素造成单条写入数据发生抖动,单个 Broker 端积压的请求太多从而得不到及时处理,会极大的造成客户端消息发送的时间延长。
设想一下,如果由于Broker压力增大,写入一条消息需要500ms甚至超过1s,并且队列中积压了5000条消息,消息发送端的默认超时时间为3s,如果按照这样的速度,这些请求在轮到 Broker 执行写入请求时,客户端已经将这个请求超时了,这样不仅会造成大量的无效处理,还会导致客户端发送超时。
故 RocketMQ 为了解决该问题,引入 Broker 端快速失败机制,即开启一个定时调度线程,每隔10毫秒去检查队列中的第一个排队节点,如果该节点的排队时间已经超过了 200ms,就会取消该队列中所有已超过 200ms 的请求,立即向客户端返回失败,这样客户端能尽快进行重试,因为 Broker都是集群部署,下次重试可以发送到其他 Broker 上,这样能最大程度保证消息发送在默认 3s 的时间内经过重试机制,能有效避免某一台 Broker 由于瞬时压力大而造成的消息发送不可用,从而实现消息发送的高可用。
从 Broker 端快速失败机制引入的初衷来看,快速失败后会发起重试,除非同一时刻集群内所有的 Broker 都繁忙,不然消息会发送成功,用户是不会感知这个错误的,那为什么用户感知了呢?难道 TIMEOUT_ CLEAN _ QUEUE 错误,Broker 不重试?
为了解开这个谜团,接下来会采用源码分析的手段去探究真相。接下来将以消息同步发送为例揭示其消息发送处理流程中的核心关键点。
MQClient 消息发送端首先会利用网络通道将请求发送到 Broker,然后接收到请求结果后并调用 ProcessSendResponse 方法对响应结果进行解析,如下图所示:
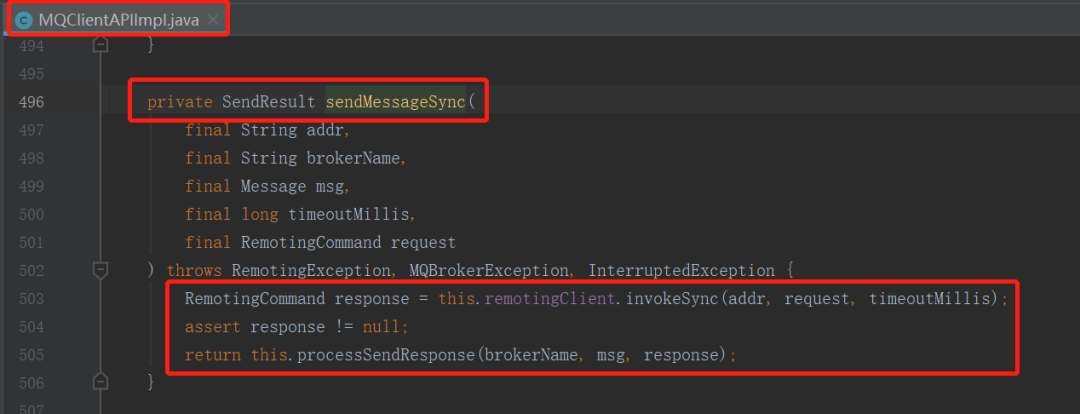
在这里返回的Code 为 RemotingSysResponseCode .SYSTEM_BUSY。
我们从proccessSendResponse方法中可以得知如果Code为SYSTEM_BUSY,该方法会抛出MQBrokerException,响应Code为 SYSTEM_BUSY,其错误描述为开头部分的错误信息。
那我们沿着该方法的调用链路,可以找到其直接调用方:DefaultMQProducerImpl 的 SendKernelImpl,我们重点考虑如果底层方法抛出 MQBrokerException 该方法会如何处理。
其关键代码如下图所示:
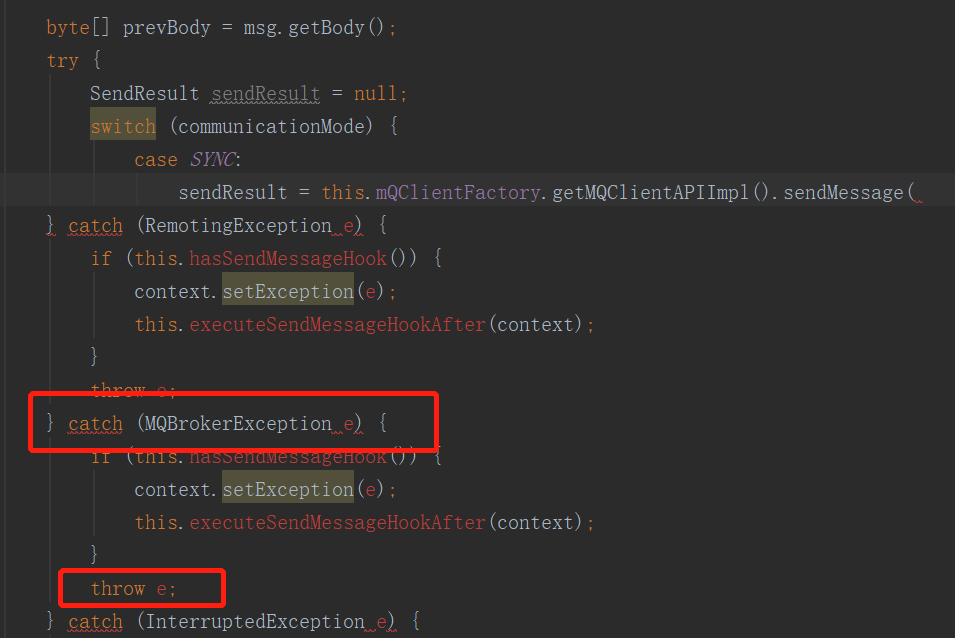
可以看出在SendKernelImpl方法中首先会捕捉异常,先执行注册的钩子函数,即就算执行失败,对应的消息发送后置钩子函数也会执行,然后再原封不动的将该异常向上抛出。
SendKernelImpl方法被DefaultMQProducerImpl 的 SendDefaultImpl 方法调用,下面是其核心实现截图:
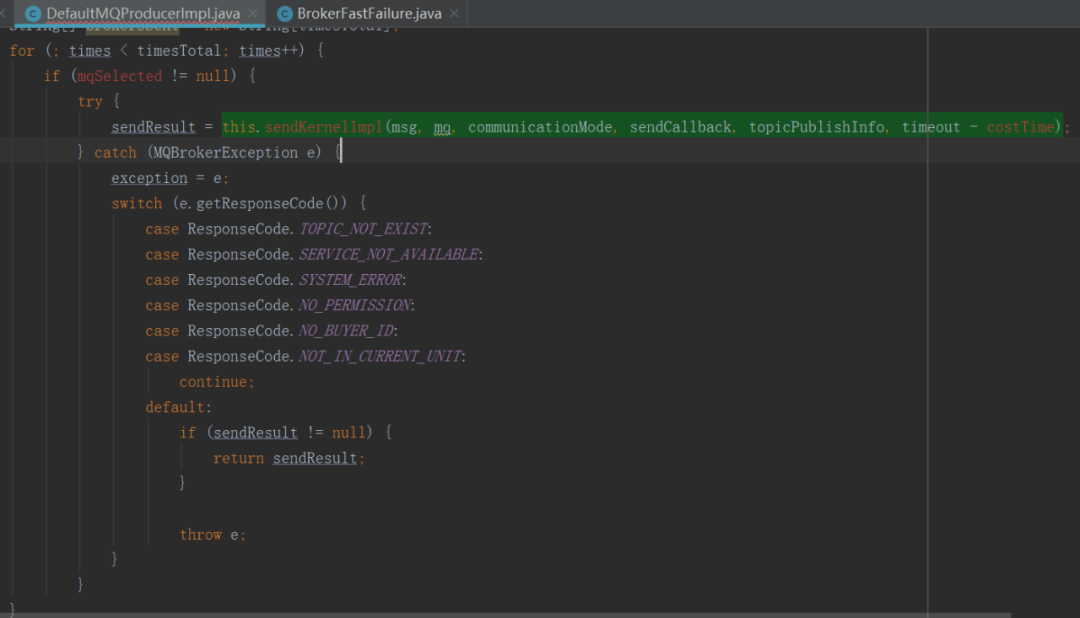
从这里可以看出 RocketMQ 消息发送高可用设计一个非常关键的点,重试机制,其实现是在 For 循环中使用 Try Catch 将SendKernelImpl 方法包裹,就可以保证该方法抛出异常后能继续重试。从上文可知,如果 SYSTEM_BUSY 会抛出 MQBrokerException,但发现只有上述几个错误码才会重试,因为如果不是上述错误码,会继续向外抛出异常,此时For循环会被中断,即不会重试。
这里非常令人意外的是连SYSTEM_ERROR都会重试,却没有包含 SYSTEM_BUSY,显然违背了快速失败的设计初衷,故笔者断定,这是RocketMQ 的一个BUG,将SYSTEM_BUSY 遗漏了,后续会提一个PR,增加一行代码,将 SYSTEM_BUSY 加上即可。
问题分析到这里,该问题应该就非常明了。

解决方案
如果大家在网上搜索 TIMEOUT_CLEAN_QUEUE 的解决方法,大家不约而同提出的解决方案是增加WaitTimeMillsInSendQueue的值,该值默认为200ms,例如将其设置为1000s等等,以前我是反对的,因为我的认知里 Broker 会重试,但现在发现 Broker不会重试,所以我现在认为该 BUG未解决的情况下适当提高该值能有效的缓解。
但这是并不是好的解决方案,我会在近期向官方提交一个PR,将这个问题修复,建议大家在公司尽量对自己使用的版本进行修改,重新打一个包即可,因为这已经违背了 Broker 端快速失败的设计初衷。
但在消息发送的业务方,尽量自己实现消息的重试机制,即不依赖RocketMQ 本身提供的重试机制,因为受制于网络等因素,消息发送不可能百分之百成功,建议大家在消息发送时捕获一下异常,如果发送失败,可以将消息存入数据库,再结合定时任务对消息进行重试,尽最大程度保证消息不丢失。

更多精彩推荐
☞
国产数据库 OceanBase 二次刷榜 TPC-C,7 亿 tpmC
☞
平安科技王健宗:所有 AI 前沿技术,都可以在联邦学习中大展身手
☞
踢翻这碗狗粮:程序员花 7 个月敲出 eBay,只因女票喜欢糖果盒
☞
我佛了!用KNN实现验证码识别,又 Get 到一招
☞
如何使用 SQL Server FILESTREAM 存储非结构化数据?这篇文章告诉你
☞
加密价格更新周期:看似杂乱无章,实际内藏玄机
![]()
你点的每个“在看”,我都认真当成了喜欢




