Flink在AI流程中的应用

分享嘉宾:涂轶文 阿里 开发工程师
编辑整理:杜红光
出品平台:DataFunTalk、AI启蒙者
01
Flink构建AI生态的背景
1. Lambda架构
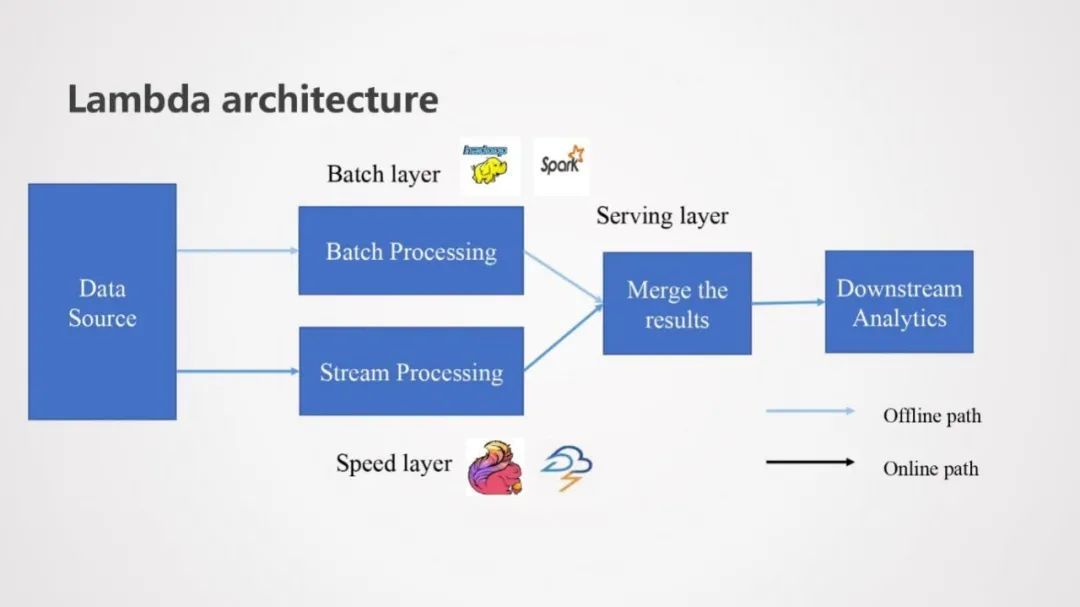
首先为大家介绍下大数据处理领域经典的Lambda架构。Lambda架构通过结合代表批模式的Batch layer和代表流模式的Speed layer,使业务在计算成本和计算实时性等方面达到一个平衡。实现Lambda架构需要为批模式和流模式各自维护一套相同处理逻辑的代码,开发和维护成本都比较高,这也是Flink作为大数据处理框架能够脱颖而出的一个原因,通过Flink流批一体的机制,用户可以很方便的通过同一套代码逻辑来实现Lambda架构。
2. AI任务的处理流程
在AI领域,AI任务的处理流程一般分为三个部分,即数据预处理阶段、训练阶段和推理预测阶段,应用场景中的各个阶段都有实时性方面的需求。
数据预处理阶段:该阶段主要工作是特征工程和样本拼接,是后续模型训练和预测的前置阶段,这个阶段更多的是大数据处理的过程。我们考虑一个离线训练和在线预测的AI场景,对于一个模型来说,批训练和流预测都有一个前置的数据预处理阶段,他们的预处理逻辑一般来说是一致的,为了避免维护两套不同计算引擎和代码,一个批流统一的计算引擎是非常必要的。
训练阶段:说到训练阶段,一般是通过训练离线样本来产生一个静态模型的过程,然而,使用静态模型也会遇到一些问题,第一个问题就是样本的分布性的问题,也就是说应用到训练的样本和预测的样本在分布性上可能会产生偏移,从而是模型的预测效果变差,这就要求每隔一定时间要对模型重新训练,并实时监控这个模型的效果;另一个问题是,在一个高频搜索场景中,训练样本和预测样本没有相关性,如微博热搜和阿里双十一等场景下,仅仅通过定时来训练模型已经不能满足实时性的要求,这就需要对模型进行在线训练来对模型进行在线更新。
推理预测阶段:无论是离线推理、在线推理或者近线推理中,对时延都有较高的要求。
以上可知,AI的三个典型阶段都对实时性有着一定的需求,我们思考一个在线训练 + 在线预测的机器学习场景,该场景下通常会将需要预处理的实时消息写入到消息队列中进行在线训练,期间会不断的动态产生模型,然后推送给在线推理模块进行在线推理,与离线训练 + 在线预测架构不同的是,样本的实时产生不仅用于在线预测,还用于在线训练。
3. 为什么选择Flink?
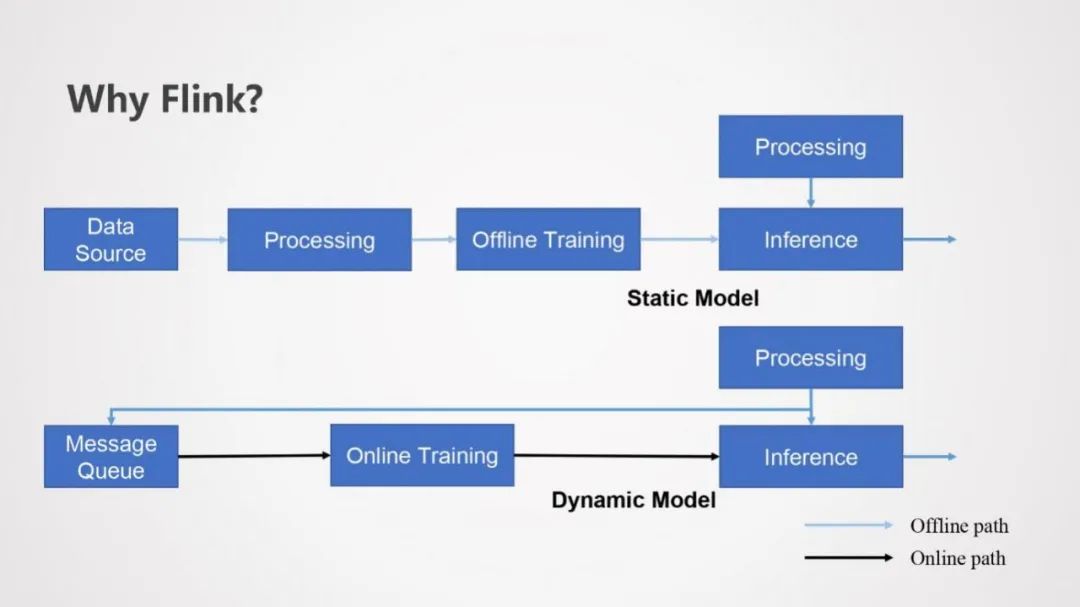
为了兼顾在线和离线训练的AI场景,我们将两个场景的架构图合并在一起,我们希望在在线和离线的数据预处理上有一个批流一体的引擎来维护,那么Flink是一个非常好选择。此外,在线和离线训练中经常会使用深度模型框架,Flink中可以运行 tensorflow、pytorch进行模型训练,也就是说Flink提供统一的技术同时支持离线和在线数据预处理、模型训练和推理预测。
02
AI Flow
1. Why AI Flow?
在AI领域中,包括数据处理、样本拼接、模型训练、模型评估和模型预测等阶段,AI Flow就是通过Pipeline将这些流程串联起来,提供一个端到端的服务,给AI Flow下一个定义就是:
管理机器学习流水线生命周期的库
-
对AI + 大数据场景的工作流的顶层抽象
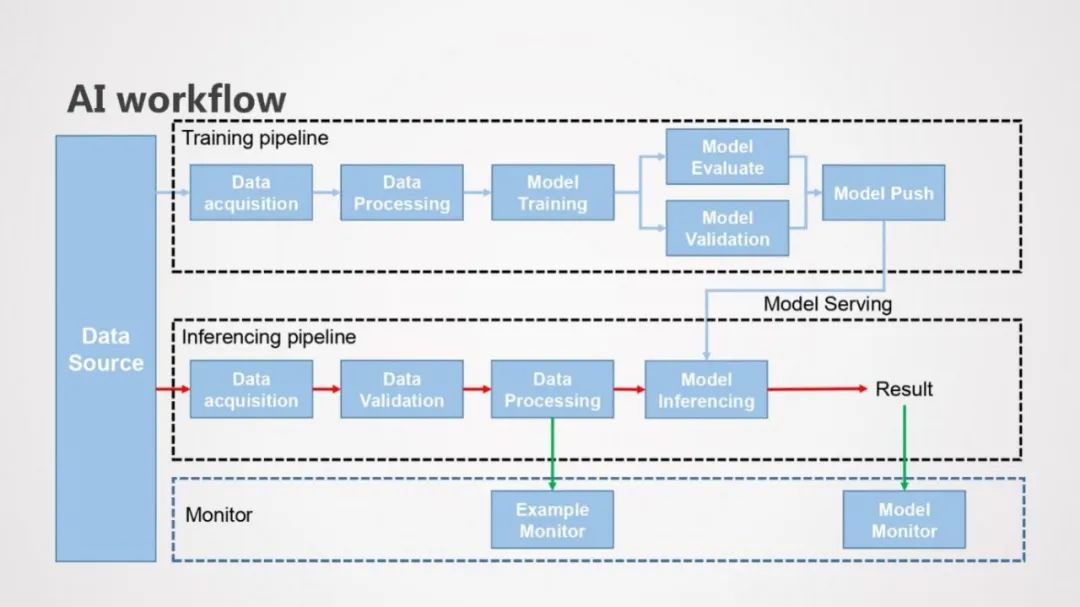
AI Flow的基本流程图如上,包括训练Pipeline, 推理Pipeline和监控模块。
训练Pipeline:输入数据经过数据预处理、模型训练和模型评估的流程,最后将模型发到线上推理服务
推理Pipeline:输入数据经过数据预处理和模型推理,生成推理结果数据
监控模块:Example Monitor用来监控预测样本和训练样本分布是否一致,Model Monitor用来监控模型预测的效果
2. AI Graph
先简单介绍下AI Graph的概念,AI Flow的本质是针对不同AI场景构造一个DAG ( 有向无环图 ),我们把这个DAG称作AI Graph,由AI Node和AI Edge组成:
AI Node:是构成AI Graph的最小逻辑执行单元,有多种类型的节点类型,如表示数据摄入节点、数据处理节点、模型训练节点、模型预测节点和模型评估节点等等。
AI Edge:AI Edge又分为Data Edge和Control Edge,Data Edge表示通过这条边相连的节点具有数据依赖关系,具有数据依赖关系的节点会被AI Flow翻译成一个Job;Control Edge表示通过这条边相连的节点具有控制依赖的关系,比如start before代表一个AI Node会在某个AI Node 开始后启动,stop before代表一个AI Node会在某个AI Node结束后启动,periodic表示某个AI Node会周期性的运行,conditional代表AI Node会根据用户自定义的一些条件启动,控制依赖的边一般是链接不同AI Node的桥梁,AI Flow会根据不同控制依赖来进行工作流的调度。
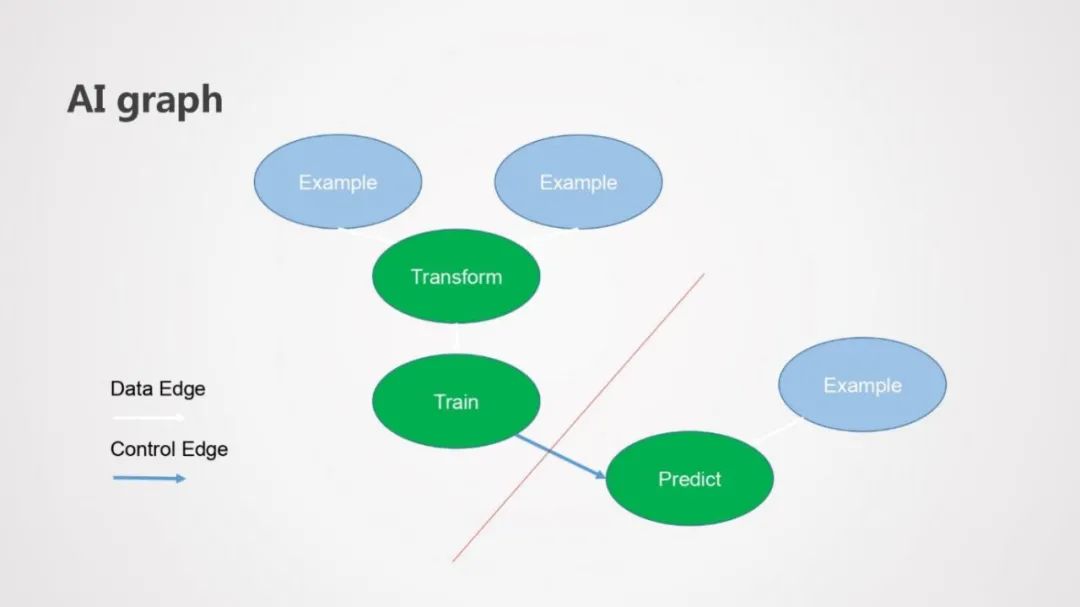
如上图所示,AI Flow会将图中的AI Graph拆成两个Job,通过控制节点来确定两个Job的调度关系。
3. AI Flow工作原理
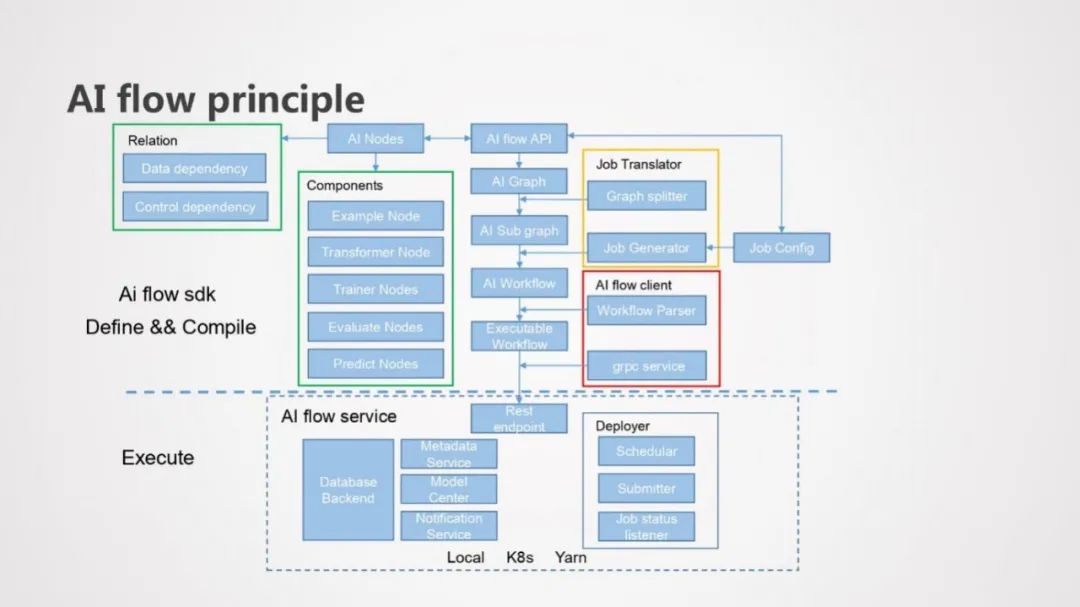
上图是AI Flow架构原理图, AI Flow分成两个模块,第一个模块是AI Flow SDK,提供工作流的定义和编译功能,用户通过SDK API编写相应的代码,AI Flow将用户的代码编译成可执行的工作流;第二个模块是AI Flow Service,是AI Flow提供的多种服务,包括执行定义好的工作流,并支持提交工作流到Local、K8s和Yarn上。
在AI Flow SDK模块,用户基于AI Flow的API定义多个AI Node,并指定AI Node之间的数据依赖和控制依赖关系,最后生成AI Graph;在编译阶段,Job Translator模块负责将AI Graph翻译成AI工作流,Graph Splitter 负责将AI Graph拆分成多个子图 ( AI Sub Graph ),Job Generator将每个AI Sub Graph翻译成对应的Job,Job Generator是可插拔可扩展的,可以将Job Generator设置为Python Generator、Flink Generator或者Spark Generator,最后生成的工作流中就会包括对应的Python Job、Flink Job和Spark Job;AI flow client将AI Workflow编译成可执行的Workflow,client将生成代码和代码所需的依赖到远程存储中,然后通过GRPC 服务将可执行的Workflow提交到远程的AI Flow Service中。
在AI Flow Service模块,包括三个服务,分别是Metadata Service,Model Center和Notification Service。
① Metadata Service

AI Flow管理元数据的服务,包括Project ( 实验项目 ),Example ( 输入数据集 ),Workflow Job ( 运行时信息 ),Model&Relations ( 模型和其他关联关系 ) 和Artifact ( 输出文件 ),通过这些信息可以方便的对实验、作业进行有效的监控和管理。
② Model Center
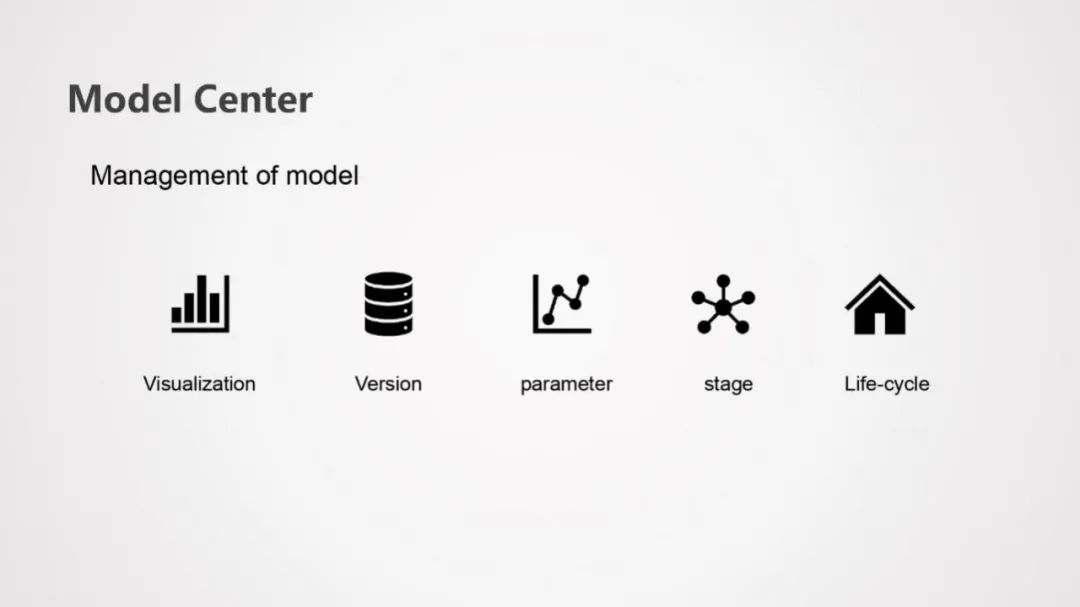
用来管理模型的服务,用来进行模型的可视化、多版本管理、参数管理、模型状态管理和模型生命周期的管理。
③ Notification Service
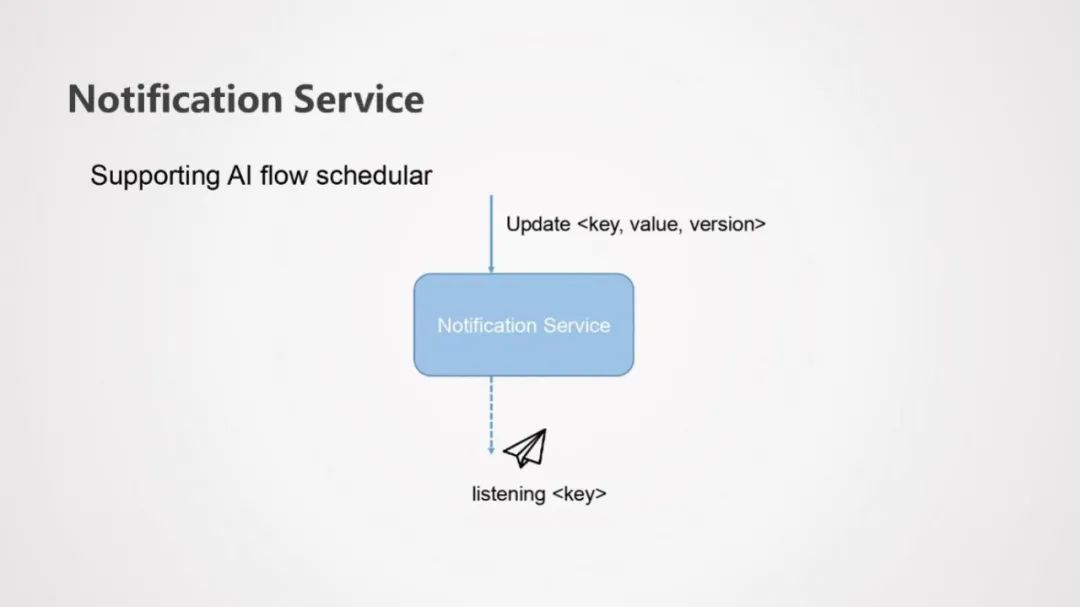
该服务主要为了支持AI Flow的调度,通常用于这样的场景,一个Job监听特定key上的更新,一旦有另一个Job更新了这个key,那么这个监听Job就可以收到通知来进行相应的操作。举个例子,一个节点产生了新的Model,通过Notification Service更新相应的信息,其他监控这个Model的Job就可以收到通知来进行模型评估或在线预测模型更新。
4. AI Flow 的价值
AI Flow用来提供一套部署生产环境中机器学习工作流端到端API,具体来说它具有以下的特点:
AI Flow支持在线场景
AI Flow与引擎无关,可以支持Python、Flink和Spark等多个计算引擎
AI Flow 与平台无关,可以部署在Local、k8s和yarn上
AI Flow组件与组件之间的关系以顶级抽象的方式定义AI的工作流
03
Flink AI Flow
Flink AI Flow 是AI Flow以Flink作为执行引擎的实现,Flink生态对AI强有力的支持使得用Flink实现AI Flow非常适合,目前Flink在AI领域生态包括:Flink ML Pipeline、Alink、Pyflink、TF/Pytorch on Flink。
1. Flink AI Flow架构图
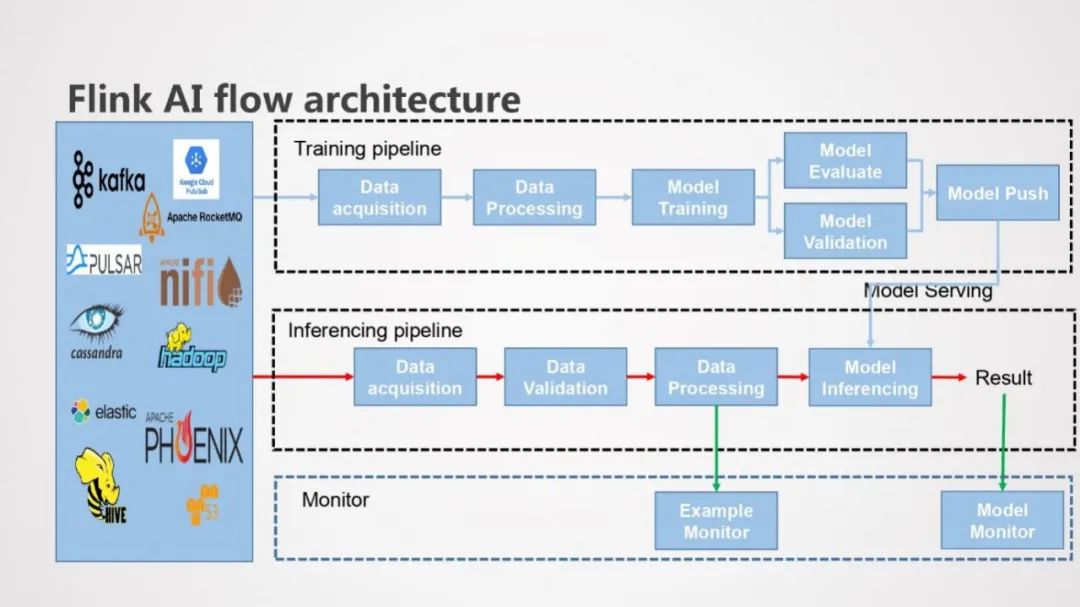
上面是Flink AI Flow的架构图,与之前看到到AI Flow的架构图不同的是Flink AI Flow有着丰富的数据源的支持。
2. Flink ML Pipeline 与 Alink
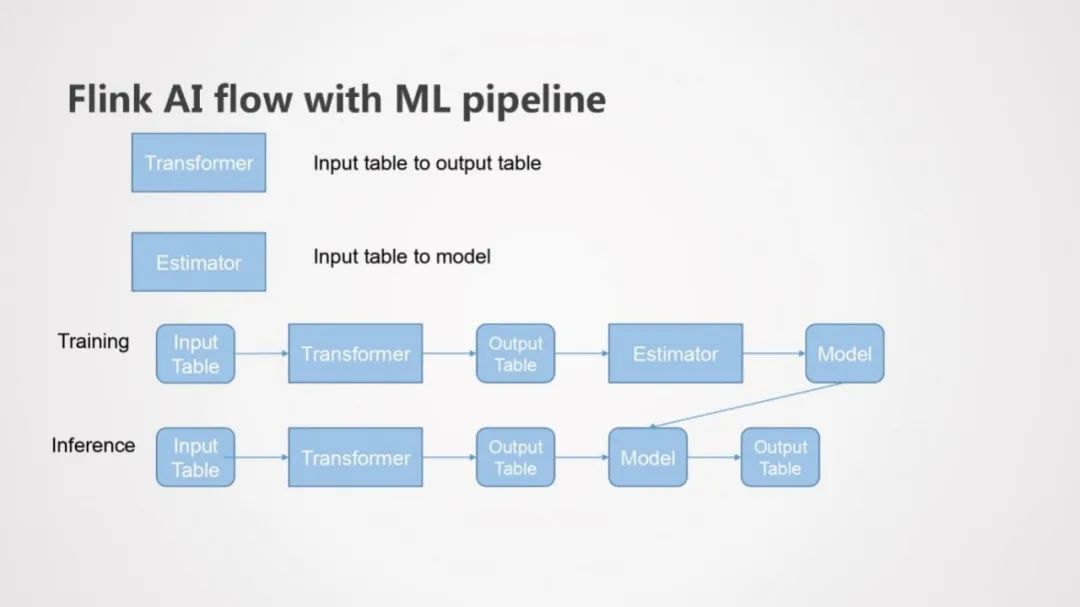
上图是Flink ML Pipeline的介绍,主要包括Transformer和Estimator两个接口的抽象,Transformer接口抽象主要用在数据处理过程,Estimator接口抽象主要用在模型训练过程。
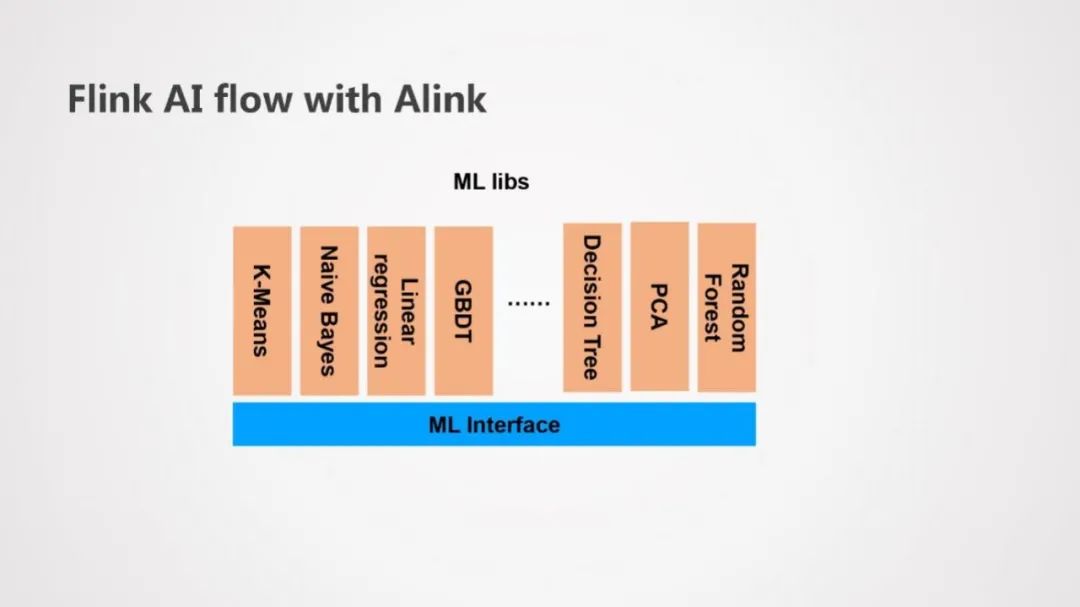
如上图,Flink ML Pipeline为Flink AI Flow提供了流水线的基础,Alink重写了Flink ML Pipeline大多数的机器学习的库。
3. Flink AI Flow和ML Pipeline关系
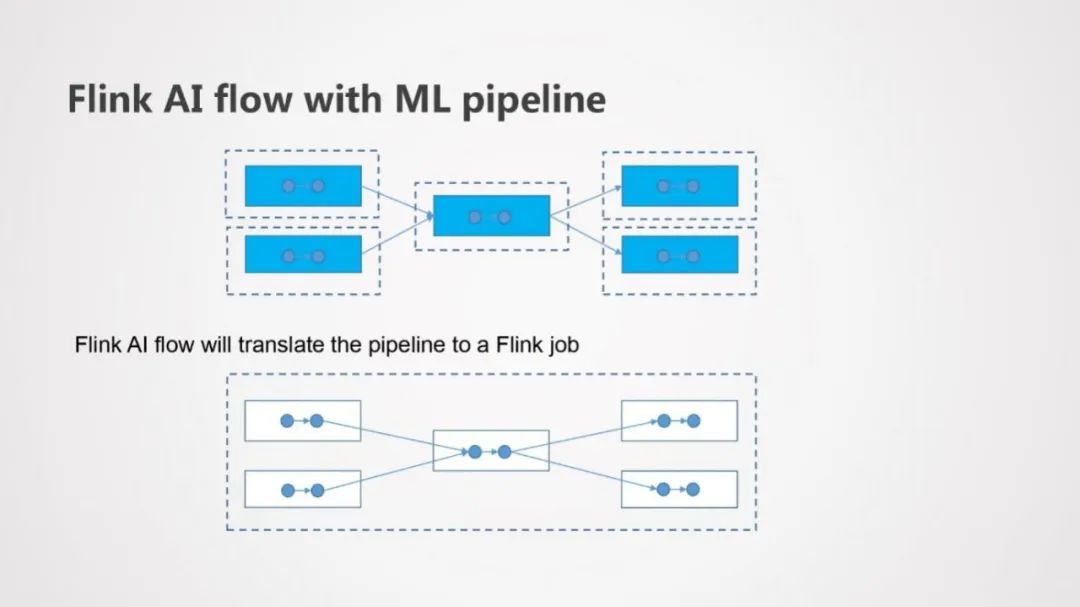
Flink AI Flow和ML Pipeline如何相互工作的?如上图所示,每个虚框都可以代表一个ML Pipeline,每个Pipeline都有一个或者多个AI Node构成,Pipeline之间存在上下游的依赖关系,Flink Job Generator会将这些Pipeline中的AI Node组合到一起,翻译成相应的Flink Job,Flink AI Flow就基于Flink ML Pipeline构成了一个DAG图。
4. AI Flow与Python关系
考虑到AI场景大多是基于Python开发的,AI Flow与Python的集成就显得尤为的重要,可以通过设置AI Flow的Job Config设置Job的运行的引擎为Python,不过本质上是运行一个Python的Job,这样会带来相应的不便,用户需要自己同connector打交道。解决这个问题可以通过设置Job的引擎为Flink,这样用户就可以在AI Flow中编写PyFlink,来使用Flink丰富的生态功能。
5. TF on Flink与Flink关系
TF on Flink支持Tensorflow代码作为Flink的一个操作和Flink一起运行,这样可以借助Flink实时计算的能力来支持在线训练场景。
04
Flink AI Flow应用案例
广告搜索推荐在Flink AI Flow中的应用:
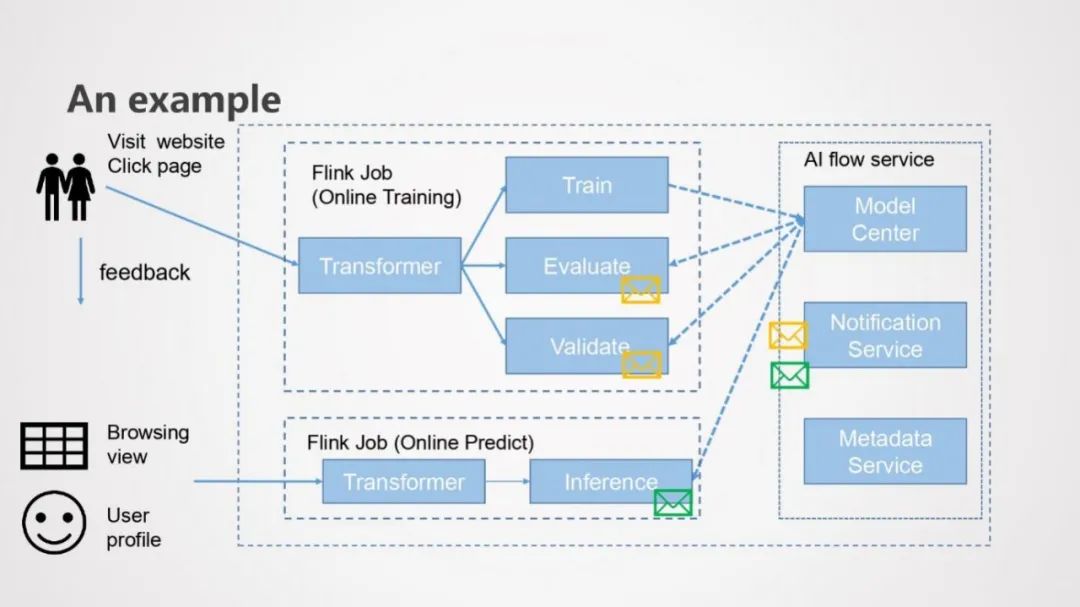
为了实时且准确的广告投放,当用户浏览网页点击鼠标后,用户行为数据作为样本实时投递到在线训练模块,样本数据经过数据处理以后,在训练模块实时到进行训练,每隔一个小时产生一个动态的模型版本,新产生的模型版本会被送入到Model Center中进行管理,此时,Notification Service会向Evaluate和Validate两个模块进行通知,Evaluate和Validate从Model Center中拿到模型进行验证和评估效果,同时也会通知在线预测模块获取最新训练好的模型进行在线预测。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~


“夺宝奇兵”活动火热开启中
Flink“潮牌”卫衣送送送
更有年度一折优惠
超低价格即可体验实时计算Flink
强大计算性能
看完这篇技术干货,你是否也想试试商业版-阿里云实时计算Flink来体验它强大的功能呢?机会来啦!参与夺宝奇兵活动,10分钟完成四步夺宝,你不仅能享受低至1折体验实时计算Flink,还能赢取Apache官方定制的潮牌卫衣!

夺宝奇兵计划已正式上线,还在等什么呢?快点击文末「阅读原文」立刻去夺宝吧~