11年,从亏损6个亿到盈利6千万!DeepMind不止于AlphaGo和AlphaFold

新智元报道
新智元报道
来源:网络
编辑:小咸鱼
【新智元导读】AI研究实验室DeepMind收购并开源了MuJoCo,多关节动力学(MuJoCo)可以为DeepMind的机器人研究提供新的动力。这篇文章将追溯DeepMind是如何一直在机器人领域努力突破极限的。
DeepMind 终于逆袭了!
这家总部位于伦敦的AI研究公司在过去几年亏损数亿美元后,有史以来第一次实现了盈利!

DeepMind收购MuJoCo
DeepMind收购MuJoCo
在2020年,DeepMind实现了5960万美元的利润。
而仅在一年前的2019年,DeepMind交出的还是一份高达6.49亿美元(约42亿人民币)的亏损账单。

作为一家人工智能初创公司,DeepMind成立十几年来,研发了不少明星产品,比如AlphaGo,AlphaFold2,不断光环加身。但光环背后,它的商业化之路一直走得有点艰辛。
近期,DeepMind在宣布史上首次实现盈利之后,第一次开始出手收购。
10月19号,DeepMind宣布,将机器人模拟器平台MuJoCo收购,并准备将其作为一个预编译的开源库发布,免费提供给研究人员。

DeepMind表示,预计将在2022年发布MuJoCo的代码库,并在Apache 2.0许可下将其作为开源软件「继续改进」。
「我们的机器人团队一直在使用MuJoCo作为各种项目的模拟平台。我们致力于开发和维护MuJoCo。MuJoCo作为一个免费的、开源的、社区驱动的项目,具有一流的能力。我们目前正在努力为MuJoCo的全面开源做准备。」DeepMind表示。

DeepMind创始人Demis Hassabis表示,公司的初衷就是用人工智能推动科学发展,造福于人类。
DeepMind在机器人领域的进展
DeepMind在机器人领域的进展
此次收购MuJoCo,并将其作为开源平台开放给所有研究人员,并不是DeepMind第一次在机器人领域作出贡献。
所以,DeepMind是如何一直在机器人领域努力突破极限的呢?
深度强化学习训练机器人
2016年,DeepMind的研究人员展示了深度强化学习如何训练真正的物理机器人。
研究表明,基于deep Q-functions的强化学习算法可以扩展到复杂的三维操作任务,并有效地学习深度神经网络策略。
DeepMind进一步表明,通过在异步共享策略更新的多个机器人之间进行算法并行化,可以进一步减少训练机器人的时间。

所提出的方法可以在模拟中学习各种3D操作技能和开门技能(通常被认为是在机器人训练中比较复杂的任务),而无需手动设计行为表示。
产生灵活的行为
2018年,DeepMind发表了三篇主要论文,展示了机器人可以实现灵活自然的行为,来适应和解决任务。

科学家用各种模拟身体训练agent,让他们在不同的地形上跳跃、转身和蹲伏。结果表明,agent在没有收到具体指示的情况下学会了这些技能。
另一篇论文展示了一种训练策略网络的方法,该网络模拟人类行为的动作捕捉数据,以预先学习诸如行走、从地面起身、转弯和跑步等技能。

然后,这些行为经过调整,可以改变用途,并解决其他任务,如爬楼梯和通过有墙壁的走廊。
第三篇论文提出了一个基于最先进的生成模型的神经网络体系结构。
这项研究展示了这种架构如何能够学习不同行为之间的关系,并模仿向agent展示的特定动作。

经过训练后,这些系统可以编码一个观察到的动作,并创造一个新的动作。
扩展数据驱动的机器人技术
DeepMind研究了一个数据驱动的机器人框架,该框架使用大量的机器人体验数据集,然后使用学习奖励函数将其扩展到几个任务。
该框架可用于在真实机器人平台上完成三种不同的物体操纵任务。

科学家们使用人类注释作为监督,让agent学习奖励功能,并用任务不可知(task-agnostic)的记录经验来演示任务。这有助于agent处理现实世界中无法直接获得奖励信号的任务。
基于学习到的奖励和从不同任务中获得的大量经验数据集,使用批量强化学习离线学习机器人策略,这种方法可以训练agent执行具有挑战性的操作任务,如堆叠刚性物体。
堆叠的新基准
最近,DeepMind推出了RGB堆叠,作为基于视觉的机器人操作任务的新基准。
在这里,机器人必须学会如何抓住不同的物体,并使它们相互平衡。这不同于以前的工作,因为所用物体非常多样,为验证结果的准确性也需要进行各种经验评估。
结果表明,使用模拟和真实世界数据的组合可以学习复杂的多对象操作。
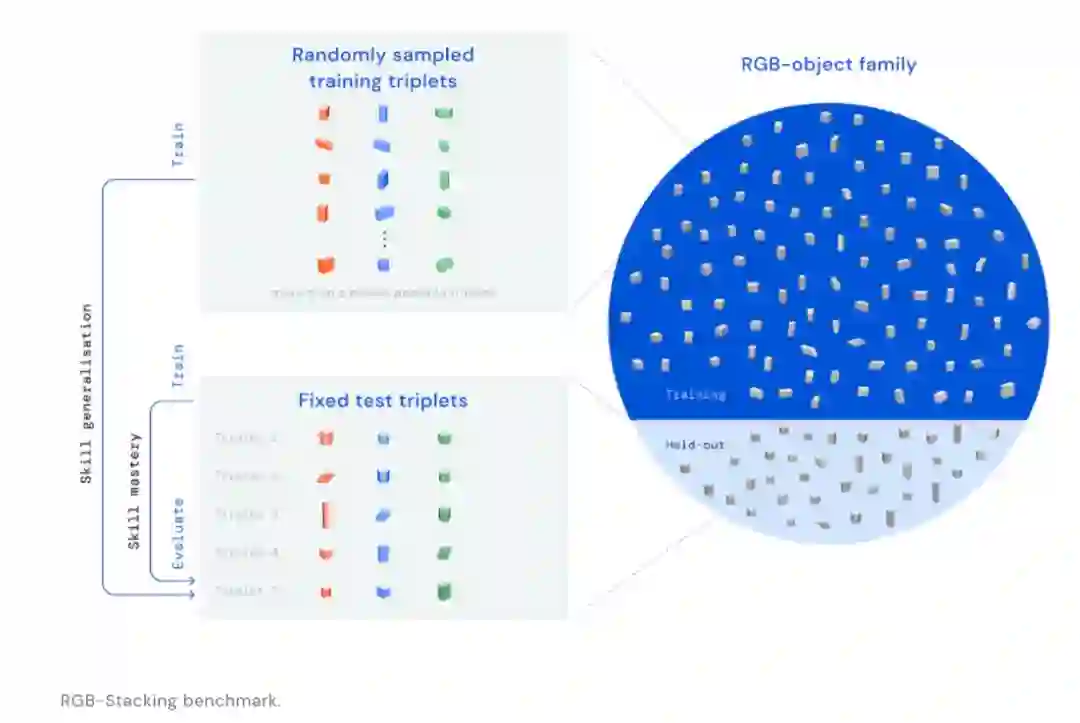
这个实验为新物体的概括提出一个强有力的基线,也被认为是DeepMind在制造通用机器人方面的一个重大进步。
DeepMind现在将致力于让机器人更好地理解不同几何形状物体间的相互作用。RGB堆叠基准已经与构建真实机器人的RGB堆叠环境、RGB对象的模型和3D打印信息的设计一起开源。
MuJoCo
最后,来聊聊这次DeepMind收购的MuJoCo。
MuJoCo(Multi-Joint Dynamics with Contact)是一款物理引擎模拟器,可促进机器人学、生物力学、图形、动画等需要快速准确模拟的领域的研发。
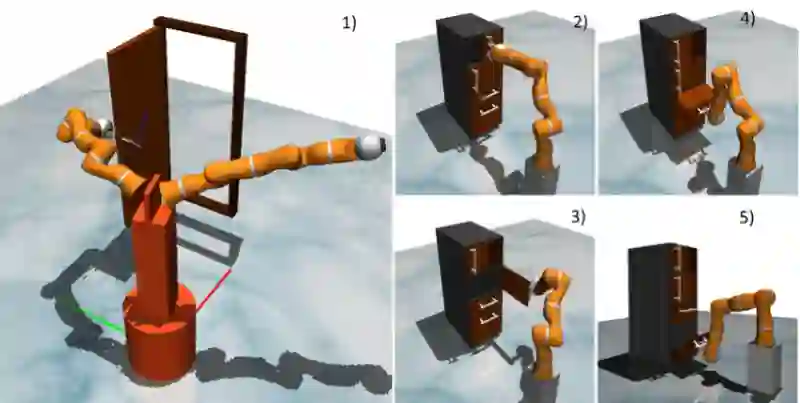
MuJoCo由Emo Todorov为Roboti LLC开发,是第一批全功能模拟器之一,从零开始设计,通过触点进行基于模型的优化。
在DeepMind被收购之前,2015年至2021年间,MuJoCo一直是一款商业产品,也就意味着需要收费,而且并不便宜。
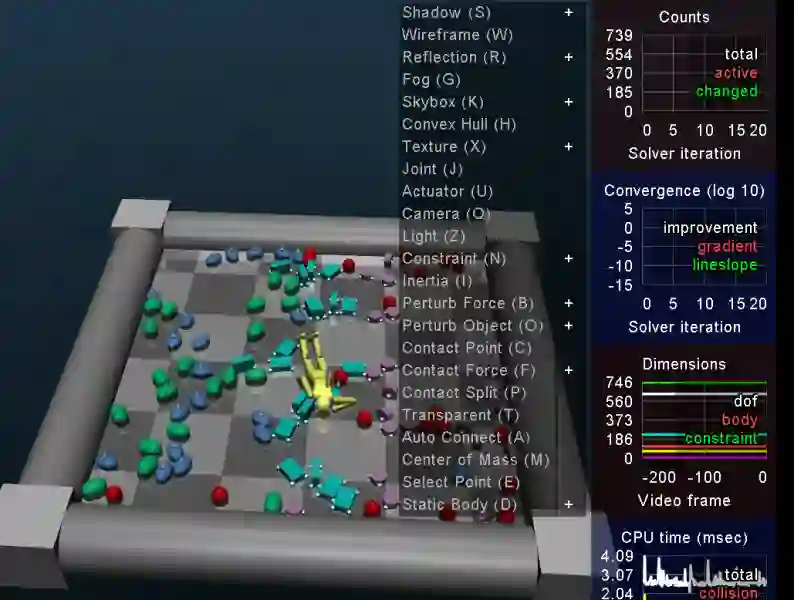
MuJoCo有助于提升计算密集型技术,如最佳控制、系统识别、物理一致状态估计和自动化机构设计,然后将其应用于具有丰富接触行为的复杂动态系统。

MuJoCo还有一些应用,比如,在物理机器人、游戏和交互式科学部署之前,经常会在MuJoCo上测试和验证控制方案。
机器人研究的未来
机器人研究的未来
今年,DeepMind的竞争对手OpenAI,在机器人领域投入多年的研究、资源和努力后,最终决定解散其机器人研究团队,将重点转移到数据更容易获得的领域。

在机器人研发行业,也有几家基于机器人技术的公司已经关门或者正在严重亏损。在这种情况下,机器人尽管是一个看似利润丰厚的行业,但却没有买家。
不过,有谷歌的真金白银的支持,再加上从不让人失望的DeepMind的研发实力和研究机器人的决心,机器人领域的未来还是非常值得期待的。
参考资料:
https://analyticsindiamag.com/deepminds-progress-over-the-years-in-robotics/
https://deepmind.com/blog/article/producing-flexible-behaviours-simulated-environments
https://deepmind.com/research/publications/2019/Scaling-data-driven-robotics-with-reward-sketching-and-batch-reinforcement-learning https://deepmind.com/blog/announcements/mujoco



