基于视觉控制,40美元玩转无传感器机械臂(已开源)
机器之心发布
来源: 北京大学前沿计算研究中心
本文是计算机视觉领域顶级会议 CVPR 2019 入选论文《CRAVES: Controlling Robotic Arm with a Vision-based, Economic System》的解读。本文由约翰霍普金斯大学、清华大学和北京大学王亦洲课题组共同合作完成。
本文提出了一种基于视觉的机械臂控制系统,可以应用在价值 40 美元、完全没有传感器的廉价机械臂上。仅借助一个额外的摄像头,系统使用深度卷积神经网络,实时估计机械臂的三维姿态,并通过强化学习训练的智能体输出控制信号。进而,系统可以实现控制机械臂到达空间中任意给定三维坐标。基于此,我们还实现了自动抓取骰子的任务。此外,姿态估计和强化学习的训练完全依赖在虚拟环境中生成的数据,不需要人为进行标注与监督。

项目网站:https://craves.ai(含代码和数据)
论文地址:https://arxiv.org/abs/1812.00725
简介
如何赋予机器人视觉,让其在多变的环境中完成复杂的任务,近年来吸引了越来越多研究者的关注。然而,以往的研究大多使用昂贵的工业级机器人(价值一万美元以上),这无疑限制了一般的研究者进入这个领域。因此,本文希望通过低成本的硬件来搭建一个机器人研究和教育的平台,以降低相关领域研究的硬件门槛。
我们选用了 OWI-535 机械臂,因为其:
非常廉价,只需要 40 美元左右;
易于获得,在淘宝网或亚马逊上就可以买到;
非常流行,在 Youtube 上有大量用户上传相关的改装与操作的视频。
与此同时,其缺点也非常明显:没有任何传感器,因此无法获得反馈信号并对其进行精确控制。但人可以通过观察机械臂,通过遥控器完成一些高级机械臂才能完成的任务, 例如叠筛子。如何用视觉算法像人一样对没有传感器的机械臂进行控制是本文关注的焦点。
我们选择使用一个外部的 RGB 摄像头作为视觉传感器,实时估计机械臂的三维姿态,并生成反馈控制信号。系统框图如下图所示:
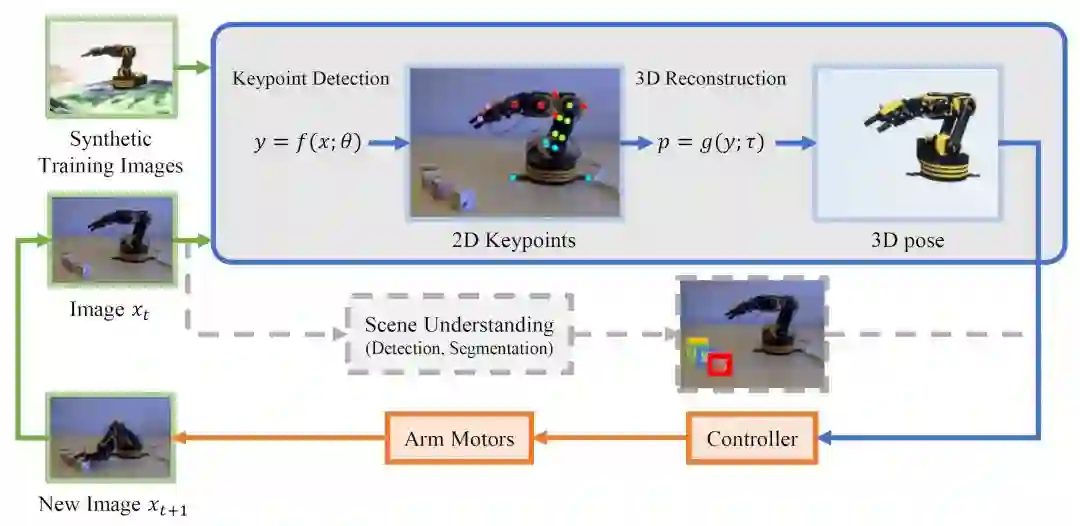
系统首先读入输入 RGB 视频流中的一帧(图中绿色部分),将其输入到姿态估计网络当中(图中蓝色部分),还原机械臂的三维姿态信息。最后,由强化学习智能体构成的控制器(图中橙色部分)接收三维姿态信息,生成控制信号,控制机械臂的电机运动。
本文的主要贡献包括:
设计了一个低成本的、无传感器的机械臂系统的实现方案;
提出了一种结合几何先验的半监督域适应方法, 实现机械臂位姿估计模块从虚拟到真实的迁移;
提供了三个带标注的数据集和一个虚拟环境,以促进未来该领域研究的发展。
相关代码和数据均已开源,可从项目主页(https://craves.ai,点「阅读原文」跳转)获取。
下面将分别介绍数据集收集、姿态估计模块和实验结果。
数据集收集
因为获取带有精确标注的真实数据代价十分高昂,所以我们构建了一个虚拟环境来自动生成标注数据,用于训练。为了验证模型在真实场景的性能,我们额外收集了两个真实数据集,并进行了人工标注。三个数据集及虚拟环境均开放下载。
第一个数据集是虚拟数据集(Virtual Dataset)。我们使用了虚幻 4 引擎及其插件 Unrealcv[2] 来进行场景的渲染和数据采集。在生成训练数据时,我们对摄像机的位置、场景光照和背景进行随机化,以增强网络在真实场景中的泛化能力。我们共采集了 5000 张图片作为训练数据。虚拟数据集的标注自动生成,包括三维姿态信息。
第二个数据集是实验室数据集(Lab Dataset)。我们在实验室环境拍摄了机械臂的图片,标定了相机的内外参数和机械臂的三维姿态。实验室数据集由 500 张左右图片构成,只用于测试。
第三个数据集是 YouTube 数据集。我们爬取了 YouTube 中 OWI-535 机械臂的相关视频,并进行了手工标注,由于相机内外参数未知,因此我们只标注了二维关键点的位置。YouTube 数据集由 500 张左右图片构成,只用于测试。
数据集样例图片见下图:

上两行:虚拟数据;第三行:实验室数据;最后一行:YouTube 数据
可迁移的三维姿态估计
机械臂三维姿态估计模块是系统的核心组成部分。其输入是 RGB 图像,输出是机械臂的三维姿态,也即各个转轴的角度。具体而言,其由两个子模块构成:第一个子模块是二维关键点估计神经网络,由输入图像还原出二维关键点坐标;第二个子模块依据二维关键点还原出三维姿态。
二维关键点估计神经网络使用的是 Stacked Hourglass Network[1],网络采用全卷积结构。我们预先定义好机械臂上的 17 个关键点,网络的输出是与其对应的 17 个通道的热点图。在预测时,我们取热点图上响应最明显的位置作为预测结果。
获取了二维姿态后,第二个子模块进行三维还原。我们将机械臂建模为一个 4 个自由度的多刚体模型,因此 17 个关键点的位置满足一定的约束关系。我们通过在线的解一个优化方程,即最小化二维关键点的预测位置和三维模型重投影位置之间的误差,来获得机械臂各转轴角度的最优解。
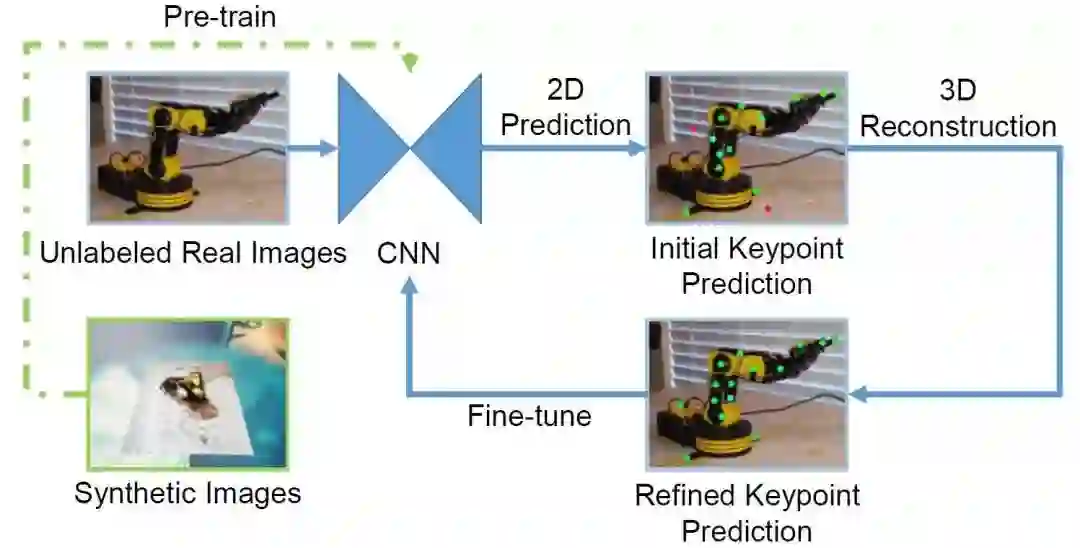
此外,我们提出了新的半监督域迁移算法。只使用虚拟数据进行训练的网络,在真实图片上的表现不够好,而采用了我们的算法之后,泛化性能有大幅度提升。下图展示了我们的域迁移算法框图。我们首先使用虚拟图片对神经网络进行预训练。之后,我们将没有标注过的真实图片送入网络,生成初始预测结果。由于域间的差异,初始预测结果可能会产生错误。我们基于初始预测结果进行三维重建,并将此结果投影回二维,就获得了优化后的关键点预测结果。由于在此过程中引入了机械臂刚性结构的强先验信息,所以优化后的预测结果会好于初始预测结果。最后,我们用真实图片及用这种方法生成的虚假标签来对神经网络进行微调。
实验结果
二维关键点预测结果
如下表所示,我们证明了在实验室环境下,我们提出的半监督域迁移算法(最后一行)相比于只使用虚拟数据训练的网络(第一行)性能有很大提升。且此方法优于其他的无监督域迁移算法,包括 CycleGAN[3] 等。参与对比的几种域迁移方法都以 Lab 数据集作为目标域。其在从未见过的 YouTube 数据上的准确率相对其他方法有更大提高,说明网络整体泛化能力获得提升。
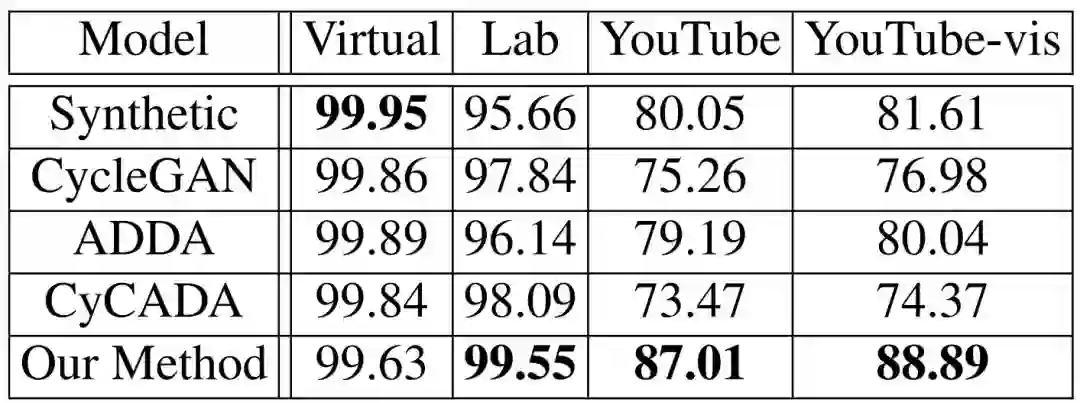
上表为不同迁移方法下得到的模型的二维关键点检测准确率。测试数据分别在虚拟数据集、实验室数据集、YouTube 数据集,其中 YouTube-vis 为只计算可见的关键点的结果。
三维重建结果
下图展示了三维重建的定性结果。上图是原始图片,下图是经过三维重建并渲染可视化的图片。可见,系统可以在复杂背景下对机械臂进行三维重建。实验室数据集上的定量结果表明,机械臂转角的重建误差约为 4.8 度。

机械臂控制结果
我们使用 DDPG 算法训练强化学习智能体,在虚拟环境中进行交互。智能体的输入是当前状态、目标状态和上一时刻的决策。输出是对 4 个电机马达的控制信号。我们在两个任务上进行了测试。

第一个任务是 Reach,即让机械臂的前端达到特定目标点的正上方。这是机械臂的「基本功」。通过测量终止位置和目标位置之间的水平距离来评价结果的好坏。上图是我们的实验装置示意图,下方参考板上的 9 个黑色圆点即为目标位置。在这个任务上,我们达到了与人类控制相近的精度。

在不同的视角、背景下也能很好地工作。

第二个任务是夹取骰子,现阶段骰子的三维空间位置由人工测量给定。

参考文献:
[1] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision, 2016.
[2] Weichao Qiu, Fangwei Zhong, Yi Zhang, Siyuan Qiao, Zihao Xiao, Tae Soo Kim, Yizhou Wang, and Alan Yuille. Unrealcv: Virtual worlds for computer vision. In Proceedings of the 25th ACM International Conference on Multimedia, 2017.
[3] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A.Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In International Conference on Computer Vision, 2017.
本文为机器之心发布,转载请联系原公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




