转载公众号 | PaperWeekly
概念是人类认知世界的基石。比如对于“哪吒好看吗?”,“哪吒铭文搭配建议”两句话,人可以结合概念知识理解第一个哪吒是一部电影,第二个哪吒是王者荣耀的英雄。
然而机器能理解吗?
针对这一问题,浙江大学和阿里巴巴的算法工程师们一起提出了一种全新的自动化概念图谱构建方法,其能够自动的从海量文本及半结构化数据中构建细粒度的中文概念层次结构,相关技术的论文已经被国际顶会 KDD 2021 录用。
![]()
AliCG: Fine-grained and Evolvable Conceptual Graph Construction for Semantic Search at Alibaba
https://arxiv.org/abs/2106.01686
提出的相关技术同时支持了阿里巴巴商品知识图谱的建设,应用于细粒度商品标签的获取、挖掘和更新等任务。
阿里巴巴商品知识图谱拥有千亿级别的实体和关系,为不同业务商品数据的组织和管理起到了重要作用,并获得了 2020 年度钱伟长中文信息处理科学技术奖和 2020 年度 ECR 中国零售供应协会创新项目奖。
![]()
背景
概念是人类认知从具体进入抽象的第一步,也是人类认知世界的基石。概念知识图谱是一种特殊的知识图谱,在语义搜索、自动问答等场景具有广泛的应用价值。例如,微软开发了 Microsoft Concept Graph
[1]
可以帮助机器更好地理解人类语言进而提升语义理解效果。网络搜索引擎(如谷歌和必应)利用概念分类来更好地理解用户查询并提高搜索质量。
此外许多电商平台(如阿里巴巴
[2]
和亚马逊)将产品分为不同粒度的层次结构,以便客户可以轻松地搜索和导航不同分类,找到他们想要购买的商品。然而,以往的概念图谱构造方法
[3]
通常只从文本中抽取高频率、粗粒度和静态的概念实例。在实际应用中,其较难覆盖长尾和细粒度概念信息,且存在更新困难的问题。
细粒度概念获取。
不同于粗粒度概念,细粒度的概念有助于提升搜索的召回率。例如,“围巾”是一件“服饰”,我们较难获取“围巾”的细粒度上级概念“保暖服饰”,这些细粒度概念很少被现有的概念图谱所覆盖。
长尾概念挖掘。
传统的概念抽取方法通常是基于 Hearst 模板提取概念。然而,这些方法较难从带噪声的开放语料中提取长尾概念。
自动概念更新。
传统的方法无法随着时间的推移更新概念的信息。例如,“哪吒”在不同的时期有着不同的含义,可以指神话作品人物或者上映影片。因此,必须将时间演化纳入概念分类体系构建中。随着时间的变化,我们需要对齐概念图谱中具有相同含义的节点,并估计给定实例中概念的置信度分布。
![]()
AliCG
![]()
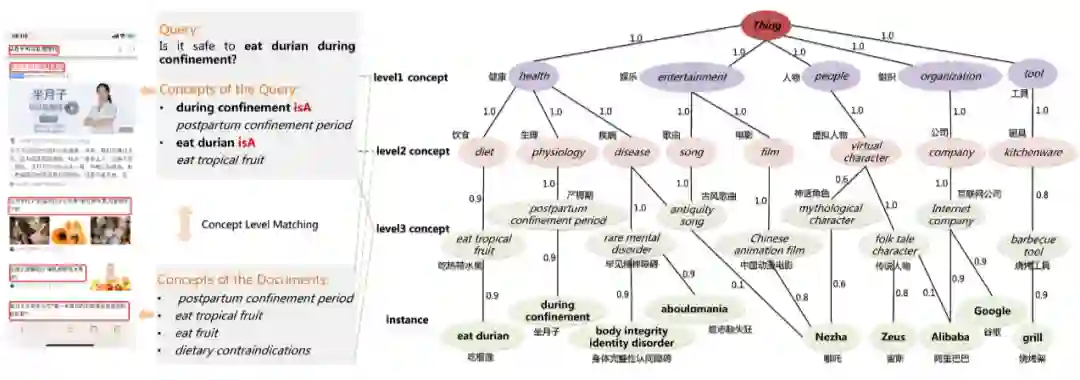
阿里巴巴的概念图谱 AliCG 由海量的概念核心实例、数万的细粒度概念和概念-实例三元组组成,这些数据包括了常见的人物、地点等通用实例。
相较于传统的知识图谱,AliCG 包含大量中文细粒度概念,且具备自动更新、自动扩充的能力。比如对于“刘德华”这一实例,AliCG 不仅包含“香港歌手”、“演员”等传统概念,还具有“华语歌坛不老男歌手”、“娱乐圈绝世好男人”等细粒度标签。
如图所示,AliCG 分为四个级别的层次结构:Level1 层由表示这些实例所属的领域概念组成;Level2 层由实例类型或子类的概念组成;Level3 层由基础概念组成,这些概念是实例的细粒度概念化;Instance 层包括实体和非实体短语等所有实例。
![]()
![]()
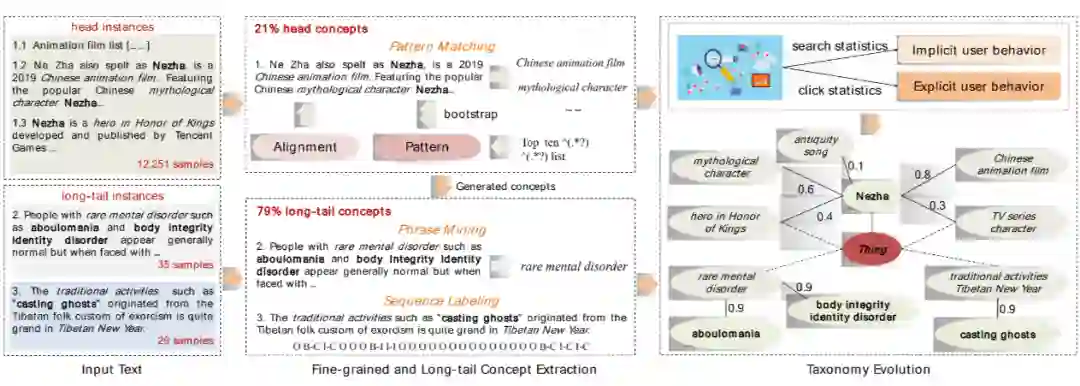
这一模块的目的是从包含噪声的海量开放语料中提取常见的细粒度概念,然后获取候选概念和实例,并通过概率推理和概念匹配将候选概念和实例与相应的概念联系起来。我们定义了一组精准的模板来从高置信度的匹配查询中利用 Bootstrapping 方法提取概念短语。例如,“十大XXX”是一种可用于提取种子概念的模式。基于这种模式,我们可以抽取出“十大手机游戏”等概念。
这一模块的目的是通过短语挖掘和自训练从有带噪的搜索日志中提取长尾概念。我们首先基于短语挖掘算法,并利用外部领域知识图谱中的术语进行长尾的概念挖掘。具体来说,我们首先过滤停止词,然后使用现成的短语挖掘工具 AutoPhrase 在无监督的情况下对语料库进行短语挖掘。我们同时采用了一种基于自训练的序列标注算法,用于长尾概念的挖掘,进一步提取一些分散的概念。
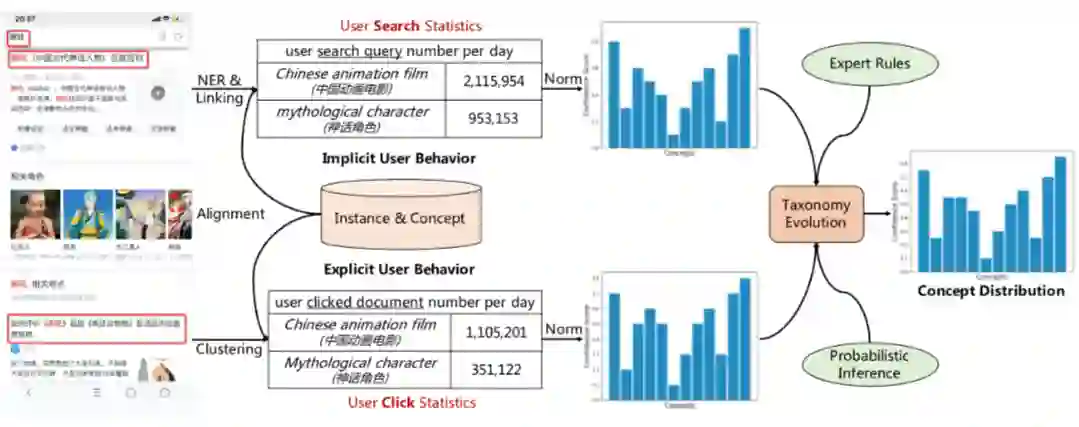
这一模块的目的是随时间变化更新概念信息。我们首先将部分概念与预定义的同义词词典对齐。然后,我们通过通过每天的用户搜索实例热度计算置信度得分,并根据用户的点击行为来估计概念置信度分布。最后,我们将两个不同粒度的置信度得分联合构建实例-概念分类如下图所示。关于构建方法的细节可以参阅我们的论文原文。
![]()
![]()
我们对概念图谱构建系统和应用做了丰富的实验。如下图所示,实验结果表明,相比于传统的概念挖掘算法,我们能够获得更加细粒度的概念实例三元组,且具备对长尾概念的挖掘能力。
![]()
此外,我们在还展示了 AliCG 在四种不同场景下的潜在应用案例:
(1)交互式搜索系统,“哪吒”链接到概念层 level3 的浅层概念,可引导用户依据列出的概念进行实时交互,实现实体消歧,精准定位搜索内容,最终索引到“哪吒之魔童降世”内容,高层级的概念有助于帮助定位目的实例;
(2)开放式对话系统,可根据用户给定的实例联系概念知识图谱,实例-概念、概念-概念之间的链接通路使对话更有信息量,提高交互能力;
(3)阅读理解系统,可根据文本内容对链接到“李白”这一实例的概念进行置信度排序,向用户展示最有可能的理解输出,在这里系统根据上下文可以准确判断“李白”并不是指代高频概念“盛唐时期的诗人”,这说明了细粒度的概念知识图谱对于识别精度有很大帮助;
(4)广告推荐系统,根据用户历史购物信息,向中文概念图谱中索引高层次概念实例,多个概念之间进行组合推断,识别到“运动装备”、“工业产品”、“用具”,可以有效向用户推送户外相关产品,并给出推荐理由。
![]()
(5)在商品知识图谱中的应用,商品知识图谱包含大量商品标签用于描述商品,标签基于命名实体识别和新词发现两条链路生产。商品标签本质上也是概念,存在不同粒度的分层结构,同时也面临着长尾标签和更新的问题。文章提出的算法重点解决这几个问题,我们把对应的算法模块融到了商品知识图谱标签生产的流程之中。
![]()
在本文中,我们介绍了阿里巴巴概念图谱的构建及应用,并提出了一种并提出一种全新的自动化概念图谱构建方法,其能够自动的从海量文本及半结构化数据中构建细粒度的中文概念层次结构,并把相关技术应用在了阿里巴巴商品知识图谱中。
随着人工神经网络技术的不断发展,数据驱动渐入天花板。尽管超大规模的预训练语言模型如 GPT-3 取得了令人惊艳的效果,它仍然经常闹笑话。数据+知识是驱动未来认知 AI 的重要路线之一。我们的方法能够自动挖掘概念知识,并在真实场景中起到了较好的效果。
[1] Microsoft concept graph: Mining semantic concepts for short text understanding
[2] AliCoCo: Alibaba e-commerce cognitive concept net
[3] CN-Probase: a data-driven approach for large-scale Chinese taxonomy construction
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。
![]()
点击阅读原文,进入 OpenKG 网站。