“男医生,女护士?”消除偏见,Google有大招
编译整理 | 若奇
出品 | AI科技大本营
如何消除 AI 带来的性别偏见是个令人头疼的问题,那究竟有没有方法去解决?
12 月 6 日,Google 宣布他们迈出了减少 Google 翻译中性别偏见的第一步,并且还详细介绍了如何为 Google 翻译上的性别中性词提供女性化和男性化两种翻译结果的技术原理。
过去几年,Google 翻译通过使用基于端到端的神经网络系统大大提高了翻译质量,但与此同时,模型的翻译结果呈现出了社会偏见,尤其是性别偏见。具体而言,由于 Google 翻译的结果一直都是从网上数以亿计的已翻译数据中学习得到,这造成的后果是,即使翻译结果可能具有女性化或男性化形式的倾向,但它也只为查询提供一种翻译。因而,这无可避免地复制了已有的性别偏见。例如,像“强壮”或“医生”这样的词语,它会生成偏向于男性化的翻译结果,而对于“护士”或“美丽”等词汇,则会生成偏向于女性化的翻译。
现在,Google 翻译解决了上述问题。当你把诸如“外科医生”这样的单字从英语翻译成法语、意大利语、葡萄牙语或西班牙语时,会得到的男性化和女性化的两种翻译结果。另外,当把短语和句子从土耳其语翻译成英语时,你也会得到这两类翻译,比如你用土耳其语输入“o bir doktor”,就会得到“she is a doctor”和“he is a doctor”这两种按性别翻译的结果。
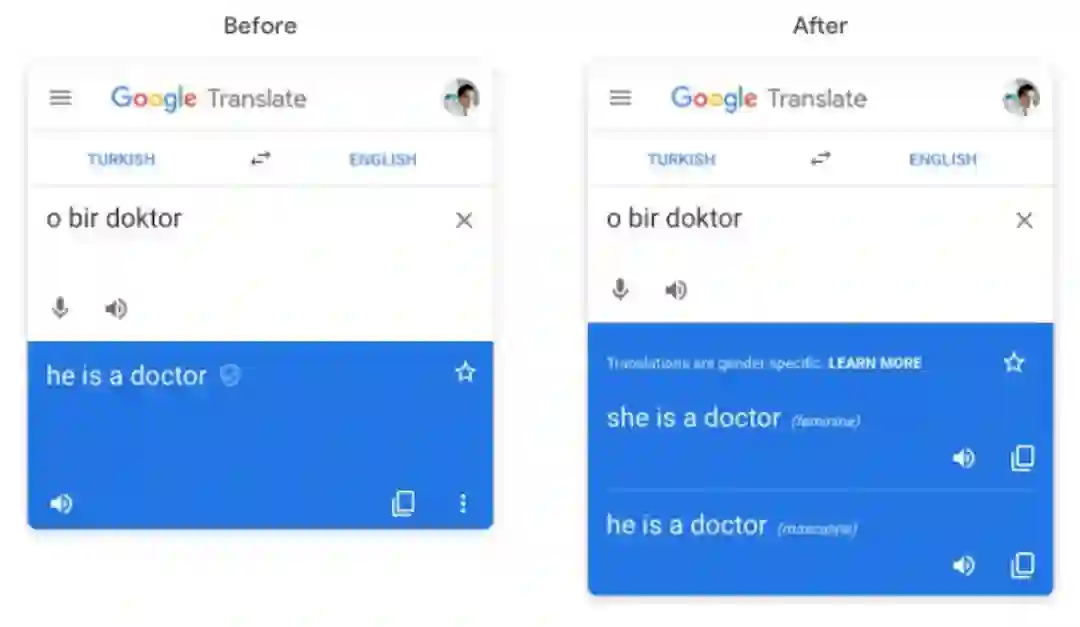
Google 翻译中有特定性别的翻译
Google 团队是如何做的?
要知道,支持单字查询的特定性别翻译涉及到用性别属性丰富 Google 的底层词库。支持较长(短语和句子)查询的性别翻译尤其具有挑战性,这甚至需要对翻译框架进行部分重构。对于这些较长的查询,他们最初将重点放在从土耳其语到英文的翻译上。总体而言,他们制订了三步法来解决土耳其语中性别中立查询的问题,即同时提供英文的男性化和女性化翻译结果。

检测性别中立查询
许多土耳其语中提到人的句子都是性别中立的,但并不是全部都这样。检测哪些查询符合特定性别的翻译是一个难题,由于土耳其语在形态学上的很复杂,这意味着指代一个人可以是明确的性别中立代词(例如 O,Ona)或隐式编码。例如,“Biliyor mu?”没有明确的性别中立代名词,可以翻译为“她知道吗?”或“他知道吗?”这种复杂性导致我们不能使用简单的性别中性代词列表来检测性别中立的土耳其语查询,另外我们还需要一个机器学习系统。Google 团队估计大约有 10% 的土耳其语的翻译查询含糊不清,能同时符合女性化和男性化翻译的条件。
为了检测这些查询,他们使用了最先进的文本分类算法(与他们的云自然语言 API 中使用的算法相同)来构建一个系统,该系统能够检测给定的土耳其语查询何时是性别中立的。这就导致在翻译前新增了一个步骤,所以他们必须平衡模型在延迟时的复杂性。Google 团队对数千个土耳其人进行系统培训,要求这些人判断出一个给定的例子是否是性别中立的。而他们最终的分类系统是卷积神经网络,以此可以准确检测出需要按性别翻译的查询。
生成特定性别翻译
随后,Google 团队增强了基础神经机器翻译(NMT)系统,以便在需要时生成女性化和男性化翻译。当没有要求区分性别时,训练模型生成的是默认翻译。这主要包括:
识别并将平行训练数据划分为具有女性化词语、男性化词语和性别不明词语。
在句子的开头添加一个新增的输入标记,以指定要翻译的所需性别,类似于已构建的多语言 NMT 系统的方式:
<2MALE> O bir doktor→他是一名医生
<2FEMALE> O bir doktor→她是一名医生
训练增强的 NMT 模型对女性、男性和性别中立数据源的影响。他们对这些来源进行了各种混合比试验,使模型在这三个任务中的表现同样出色。
如果确定用户查询是性别中立的,他们会在翻译请求中添加性别前缀。对于这些要求,他们的最终 NMT 模型可以在 99% 情况下生成可靠的女性化和男性化性别的翻译结果。此外,系统在没有性别前缀的查询中还能保持翻译质量。
检查准确性
最后的一个步骤决定是否显示特定性别的翻译结果。由于产生男性化翻译的训练数据与产生女性化翻译的训练数据不同,因此在与性别无关的两种翻译间可能存在差异。如果确定特定性别的翻译质量低,则只显示单一的默认翻译。为了确定特定性别的句子翻译质量,他们进行以下验证:
要求的女性翻译是女性化的;
要求的男性化翻译是男性化的;
除了与性别相关的变化,如果女性化和男性化翻译完全相同,即使翻译结果间的措辞发生微小变化也会被系统过滤掉。

男性化和女性化翻译仅在性别方面有所不同,即“he”和“his”与“she”和“her”。因此,他们展示了特定性别的翻译。底部:男性化和女性化翻译在性别方面有所不同,即“he”与“she”。但是,从“really”到“actually”的变化与性别无关。因此,系统将过滤特定性别的翻译并显示默认翻译结果。
如果将所有内容放在一起,输入句子首先会通过分类器,分类器检测它们是否可以进行特定性别翻译。如果分类器说“是”,系统则向增强型 NMT 模型发送三个请求:女性化翻译请求、男性化翻译请求和性别中立翻译请求。最后一步考虑了所有的三个答案,并决定是否显示特定性别翻译或单个默认翻译。Google 团队认为,这一步仍然相当保守,为了最大限度提高所显示的特定性别的翻译质量,因此系统的整体召回率仅为 60% 左右。
对 Google来说,这只是他们解决机器翻译系统中性别偏见的第一步,未来,他们计划将特定性别的翻译扩展到更多语言,并解决自动完成查询等功能中的性别偏见问题。此外,他们已经在考虑如何在翻译中解决非二元性别的问题。
相关链接:
https://ai.googleblog.com/2018/12/providing-gender-specific-translations.html
本文为 AI科技大本营编译文章,转载请联系微信 1092722531。
◆
推荐
◆

推荐阅读
点击“阅读原文”,打开APP 阅读更顺畅



