赛尔原创@ACL 2022 | 基于事理图谱增强的BERT模型的事件预测
论文名称:A Graph Enhanced BERT Model for Event Prediction 论文作者:杜理,丁效,张岳,熊凯,刘挺,秦兵 原创作者:杜理,丁效 论文链接:https://arxiv.org/abs/2205.10822 转载须标注出处:哈工大SCIR
1. 简介
事件预测任务要求模型在充分理解事件间存在的复杂关系的基础上,预测可能发生后续事件。为增进对于事件间关系的理解,前期方法提出从事件图中,检索出事件关系信息,并将其融入预训练模型中。然而,事件图固有的稀疏性将限制此类方法的性能。为此,我们提出利用预训练模型,学习自动预测事件图结构信息,从而在测试阶段,无论事件是否被事件图覆盖,均可预测出相应事件图结构信息以服务于下游预测任务。
2. 动机
事件预测任务要求为给定的事件上下文选择合适的后续事件(如图1~(a)所示)。这一任务需要模型充分理解事件之间的关系。为此,部分前期工作提出建模事件对关系[1,2,3]与事件间链状关系[4,5],以预测给定的事件上下文的后续事件。
但是,为有效预测后续事件,模型可能还需进一步理解事件间的图结构的密集连接关系 [7,8,9]。如图1~(a)所示,给定事件上下文Jason 在工作中过度紧张、他决定换工作和Jason 找到新工作,相比于Jason 对他的新工作感到压力很大,Jason 对他的新工作感到满意是一个更合理的后续事件。这可以通过理解他寻找新工作的原因是工作压力这一事实来推断。为此,Li 等人[7]与Guan 等人[8]提出构建事件演化图谱描述事件间关系,并利用表示学习算法得到事件关系特征,从而支持预测过程。
然而,此类方法的表现高度依赖于事件图谱的覆盖度。如图1 (b)所示,给定任一事件对,此类方法需要从事件图中检索到相应的结构特征,并将其融入下游推理任务 [9,10]。但是,如果事件未能被事件图所覆盖,则此类方法无从获得相应的结构特征。例如,如图1 (b) 所示,feel hungry和be starving是同一事件的不同表达,feel hungry位于训练集中,be starving位于测试集中。然而,be starving这一表达可能并未被事件图覆盖。因而,在测试过程中,这一事件的结构信息是无法被检索得到的。结构信息的缺失将极大影响模型的性能。然而,实际情况中,几乎不可能构建一个覆盖绝大多数可能事件的事件图谱。这是因为,事件是由多个语义元素组成的复杂语义单位。这种的复杂性使得对于同一语义的事件对应多种表达方式,这使得事件图可能难以完全覆盖所有事件。这一特性为检索式地利用事件图信息带来了困难。
所以,为解决这一问题,我们提出了一个能够自动预测图结构信息,并有效利用构图结构信息的框架GraphBERT。顾名思义,GraphBERT是Graph与语言模型BERT两部分的融合。BERT能够利用预训练过程中获得的丰富语言学知识,充分理解各个事件的语义。在训练过程中,Graph部分则以事件图结构为监督信号,学习如何自动,预测事件图描绘的事件间邻接关系。在测试过程中,在没有事件图信息存在的情况下,Graph部分也能够预测出任意两个事件间之间的邻接关系。从而预测出的事件间邻接关系则可服务于事件预测任务。
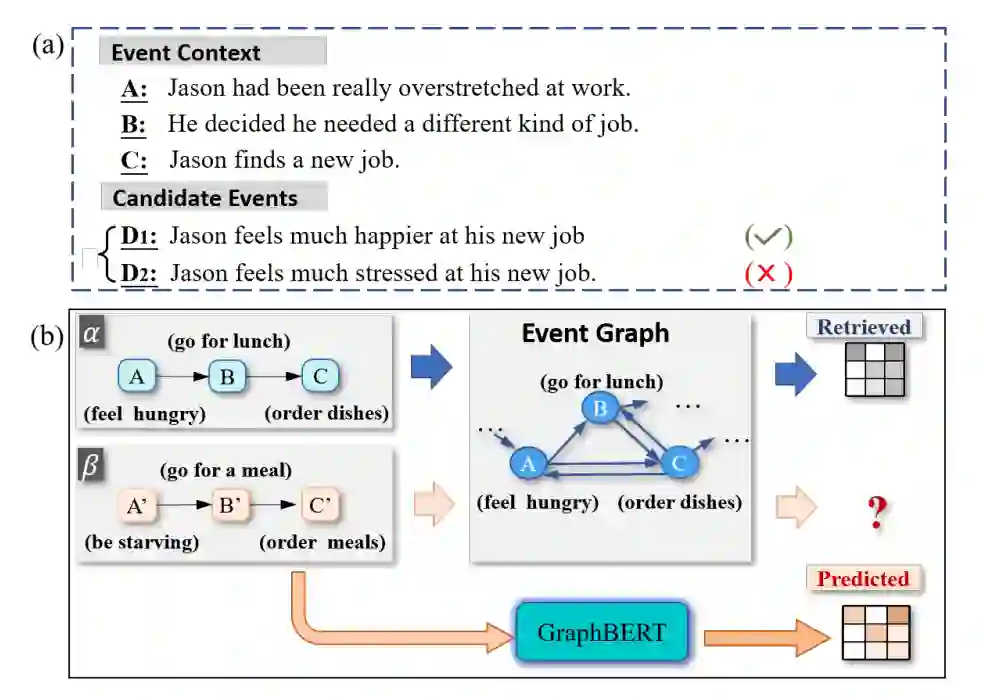
然而,事件图谱可能无法完全覆盖测试集中出现的事件,从而导致相应结构信息的缺失。相比于检索式的方法,给定任意事件序列,我们提出的模型GraphBERT能够根据事件语义估计出事件的邻接关系。实验结果显示,相比于检索式基线方法,GraphBERT能够有效提升事件预测相关任务上的性能。
3. 背景
3.1 问题定义
如图1 (a) 所示,事件预测任务可做如下定义:给定事件上下文 和某一候选事件 构成的事件序列,模型需预测一个0-1之间的分数 ,以衡量该事件序列 的合理性。
3.2 事件图
我们将事件图 形式化为 ,其中 为节点集合, 为边集合。每个节点 对应一个事件 ,每条边 则对应于从事件 指向事件 的一条边。每条边带有一权重。其中, 为事件二元组 的频率。因而, 代表 是 的后续事件的概率。
3.3 检索式的基线系统
在介绍GraphBERT的具体结构之前,我们首先引入了一个检索式的基线系统。如图2 (a)所示,给定事件序列,这一基线系统从事件图谱 中检索出一系列事件的结构特征,并用于下游预测任务。具体而言,给定一个事件二元组 ,如果这个事件二元组被事件图 所覆盖,则我们能够从 中找到这两个事件的表示向量 与 ,以及相应的边的权重 。类似地,对于 中的所有事件,我们均可获取其相应的表示向量,以及边之间的权重。我们记事件的表示向量组成的表示矩阵为 ,并邻接矩阵为 。随后,我们以如下形式整合 与 :
其中 是一个权重矩阵; 是sigmoid函数; 则是结合了邻接信息的事件表示矩阵。
随后,该基线系统进一步将 整合至下游的预测任务中。具体地,我们利用注意力机制,从 中选取相关信息,以更新BERT内部Transformer层的隐含状态:
其中, 是BERT的第 层Transformer的隐含状态, 为与 相关的事件图信息。通过将 与 融合,得到了结合事件图信息后的 。通过将 作为后续推理过程的输入,后续推理过程能够得到事件图信息的增益。
此外,该基线系统可视作 Li等人[7]与koncel-Kedziorski 等人[9]的方法在预训练语言模型BERT上的实现。
4. GraphBERT模型结构
检索式系统的关键缺陷是其高度依赖于事件图的覆盖度。换言之,如果某一事件未能被事件图覆盖,则无法获取其表示向量,以及与其他事件的邻接关系。这将影响模型的性能。针对这一问题,我们提出了一个预测式的框架GraphBERT。GraphBERT能够利用BERT中Transformer层作为编码器,得到事件链中各个事件的表示向量,从而学习利用表示向量预测事件间关系。
为此,如图2所示,在检索式的基线系统的基础之上,我们引入了两个额外的模块:(1) 一个Aggregator以从BERT的Transformer层中得到事件语义表示向量;(2) 一个Inferer以利用事件语义表示,估计事件邻接关系。
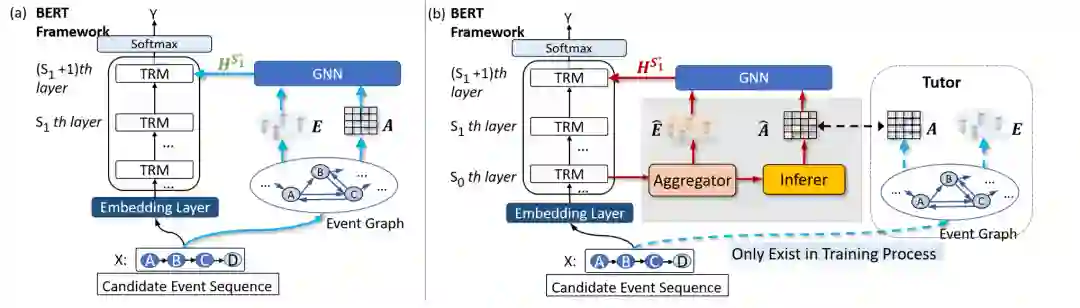
4.1 事件表示
给定事件序列 ,GraphBERT首先利用BERT的第1至 层Transformer作为编码器,得到事件所包含的各个token的编码向量。随后,利用Aggregator模块,得到事件的表示向量。
具体而言,对于 ,其中 为 中的一个事件,第 层Transformer能够给将 中包含的各个token编码为分布式表示向量,其中 是 中第 个token的表示向量。
随后,我们基于注意力机制实现了Aggregator模块。我们定义注意力机制中的Query为 的均值池化,即 ,同时令Key和Value矩阵均等于 。如此,事件 的向量表示可以按如下方式得到:
对于事件链 中的 个事件而言,他们的向量表示组成了一个表示矩阵 。注意到, 是从BERT内部的Transformer层中获得。以这种方法,我们能够利用BERT中蕴含的丰富语言学信息,得到高质量的事件表示。随后,我们利用这些(深度)事件表示估计事件间邻接关系。
4.2 事件间邻接关系的预测
给定事件表示矩阵 ,我们引入了一个Inferer模块,以利用 估计 中任两个事件间的邻接关系。Inferer模块的输出是一个 的矩阵 , 中每个元素 代表事件 与事件 之间的邻接关系。从而,在测试阶段对于任意两个事件,我们可以利用Inferer预测出其邻接关系。
为此,我们首先基于图注意力机制 \cite{velivckovic2017graph}升级事件表示。GAT需要已知每个节点的邻接节点。对于事件 ,因为其邻接关系事先未知,因而我们将 的邻域定义为 ,其中
其中 均为可训练参数, 为拼接操作。
随后,我们利用一个双线性机制预测两个事件之间的邻接关系:
其中 为可训练参数, 为转置操作。对于 中的所有 个事件,任意两个事件 与 间的关系强度系数 形成一个矩阵 。通过进一步将 归一化:
可得 。
因此,通过Aggregator模块和Inferer模块,我们可以得到任意事件的表示向量,以及任意两个事件间的邻接关系,不论这些事件是否被事件图所覆盖。通过将预测出的 与 按照 通过上述矩阵相乘操作, 中任一元素 描述了 的第 行与 的第 行之间的关系强度。注意到 的第 行与 的第 行是事件 与事件 的向量表示。因而, 可用于描述事件 与事件 之间的邻接关系强度。
4.3 Inferer模块的训练
在训练过程中,我们利用一个Tutor模块,从已构建的事件图中获取相应的事件间邻接关系信息,以有效指导Inferer模块。具体而言,给定事件链 ,我们按以下方式从事件图中获得一邻接矩阵 ,该矩阵描述 中任意两个事件的邻接关系:
其中, 和 是事件链 中第 个、第 个事件在事件图中对应的节点。
随后,我们标化 以使其行和等于1.因此, 中每个元素 代表事件链 中第 个事件是 中第 个事件的后续事件的概率。通过使得 与 尽量接近,Inferer模块能够从Tutor学习到事件间邻接关系。
4.4 模型的优化
因为在训练过程中我们利用事件图信息训练Inferer模块,从而使得 与 尽量接近,因而在事件预测误差项之外引入了一项额外的图重构损失。所以损失函数的形式如下:
其中,事件预测误差项为一交叉熵损失。图重构误差项的形式如下:
与 为 及 的第 行, 指多项分布。
5 实验
5.1 事件图的构建
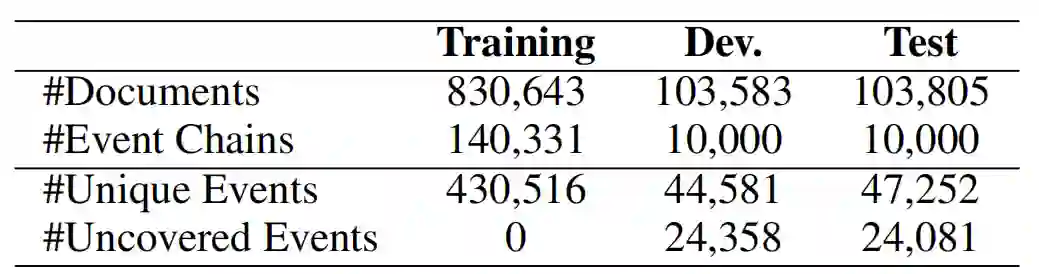
事件图的构建大致分为两步:(1) 从文档中抽取事件链;(2) 依据事件链生成图中边的权重。在步骤(1)中,我们使用与Granroth等人[3]相同的语料和方法抽取事件链。每个事件链由N个事件组成,每个事件则由四个元素:施事者、受事者、谓词、介词修饰成分构成。从表1可见,尽管事件已经以高度抽象的形式表达,测试集中仍然存在大量未被覆盖的事件。
表1 事件图对于MCNC数据集的覆盖率统计
5.2 实验结果
表2 实验结果
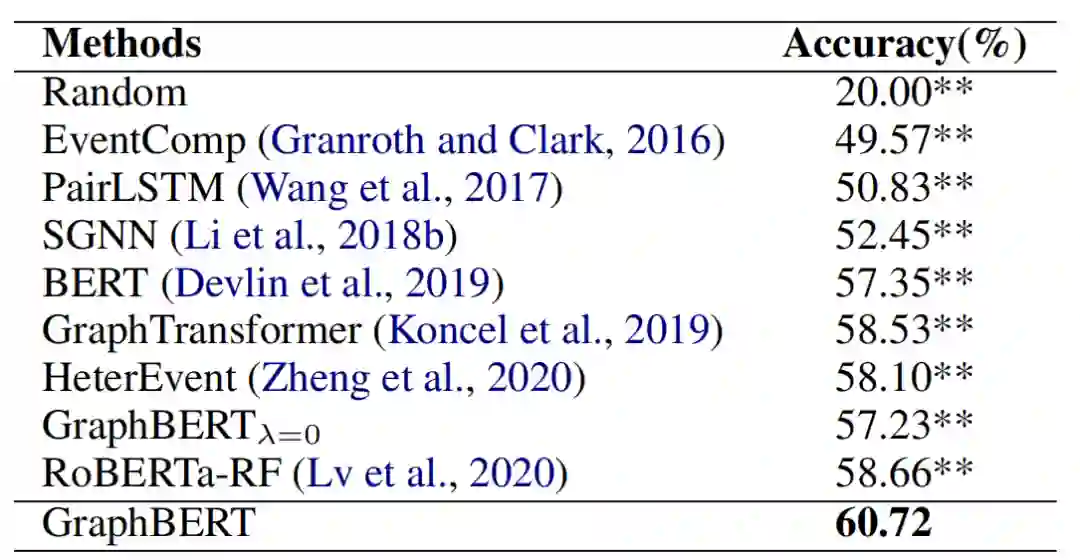
我们在脚本事件预测数据集MCNC [3]上进行了实验。实验结果见表2。从中我们可以得出如下结论:
(1) 相比于基于事件对的方法EventComp、基于事件链的方法PairLSTM,基于事件图的一系列方法,包括SGNN, SAM-Net, GraphTransformer以及GraphBERT均表现出了相对更优的性能。这说明了我们在事件预测任务中引入事件图信息的合理性。此外,GraphBERT超过了基于更强大的语言模型的、基于事件链的基线方法RoBERTa-RF。这确证了事件图结构信息对于事件预测任务的重要作用。
(2) 相比于未利用BERT的方法(EventComp, PairLSTM, SGNN以及SAM-Net),基于预训练语言模型BERT的方法GraphTransformer, BERT以及GraphBERT均达到了相对更高的预测准确率。这说明了我们利用预训练语言模型中蕴含的语言学知识来增强事件理解的合理性。
(3) 相比于BERT和未利用事件图知识的GraphBERT ,事件图知识增强的GraphTransformer和GraphBERT取得了较高准确率。这是因为事件图知识为预测任务提供了有力的支撑。
(4) 相比于检索式的方法GraphTransFormer,我们提出的生成式框架GraphBERT表现出了更优的性能。这显示,GraphBERT能够成功学习到事件图相关知识,并以预测式的方式缓解由于事理图谱的稀疏性带来的结构信息不可知问题,进而提高推理性能。
5.3 事件图覆盖率对于结果的影响
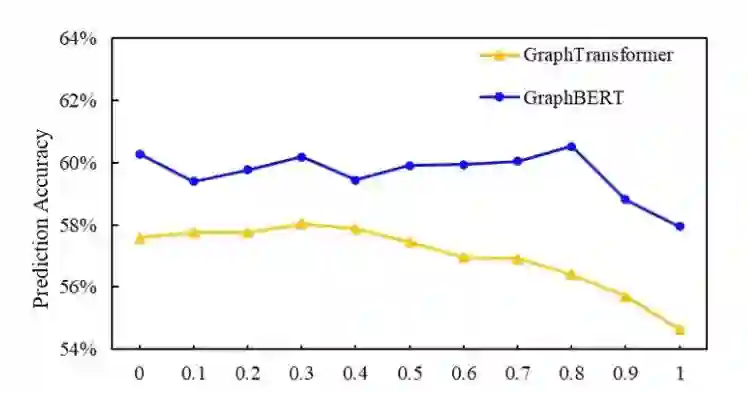
图3 事件图的覆盖率对于GraphBERT以及检索式基线方法GraphTransformer性能的影响
为研究事件图的覆盖率对于事件预测任务性能的影响,我们从MCNC数据集中利用随机采样方式构建了事件覆盖率从0-1的一系列测试集,并测试了GraphBERT与检索式基线方法GraphTransformer在这一系列测试数据集上的性能。结果如图3所示。随着测试集中未被事件图覆盖的事件比例的增加,检索式基线方法GraphTransformer的性能出现了持续下降。这是因为,随着测试集中未被事件图覆盖的事件比例的增加,对于检索式方法而言,无法获取结构信息的事件比例逐渐上升。而GraphBERT的性能保持相对稳定。这显示,在训练过程中,GraphBERT能够学习预测事件图知识,并在测试集上,预测未被事件图覆盖的事件的结构信息,从而提升事件预测任务的性能。
6. 总结
本节中,针对事件预测任务,我们提出了一个图知识增强的BERT模型。在BERT结构的基础上,GraphBERT引入了一个结构化变量,以从事件图中学习结构信息,并对事件上下文和候选后续事件之间的关系进行建模。与基于检索的方法相比,GraphBERT 能够预测所有事件之间的链接强度,从而避免事件图的(不可避免的)稀疏性。MCNC数据集上的实验结果表明,与先进的基线方法相比,GaphBERT 可以提高事件预测性能。此外,GraphBERT 还可以适用于其他图结构数据,例如知识图谱。
7. 参考文献
[1] Chambers N, Jurafsky D. Unsupervised learning of narrative event chains[C]//Proceedings of ACL-08: HLT. 2008: 789-797.
[2] Jans B, Bethard S, Vulic I, et al. Skip n-grams and ranking functions for predicting script events[C]//Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2012). ACL; East Stroudsburg, PA, 2012: 336-344.
[3] Granroth-Wilding M, Clark S. What happens next? event prediction using a compositional neural network model[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2016, 30(1).
[4] Pichotta K, Mooney R. Using Sentence-Level LSTM Language Models for Script Inference[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016: 279-289.
[5] Pichotta K, Mooney R. Learning statistical scripts with LSTM recurrent neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2016, 30(1).
[6] Mostafazadeh N, Chambers N, He X, et al. A corpus and cloze evaluation for deeper understanding of commonsense stories[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 839-849.
[7] Li Z, Ding X, Liu T. Constructing Narrative Event Evolutionary Graph for Script Event Prediction[C]//IJCAI. 2018.
[8] Guan J, Wang Y, Huang M. Story ending generation with incremental encoding and commonsense knowledge[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 6473-6480.
[9] Koncel-Kedziorski R, Bekal D, Luan Y, et al. Text Generation from Knowledge Graphs with Graph Transformers[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 2284-2293.
[10] Zhang Z, Han X, Liu Z, et al. ERNIE: Enhanced Language Representation with Informative Entities[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 1441-1451.
本期责任编辑:冯骁骋
理解语言,认知社会
以中文技术,助民族复兴