WAIC2019——8月30日参会总结
作者:邱震宇(华泰证券股份有限公司 算法工程师)
知乎专栏:我的ai之路
本文为授权转载,原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/80492728
这次有幸参加上海世界人工智能大会,经过一天的时间,参加了两个主题论坛,分别是上午的达观数据和乐言科技主办的语言智能论坛和下午第四范式主办的国际前沿算法论坛。这两场论坛都是干货满满。本文挑选了我个人感触最深的几个点与大家分享一下。
语言智能
作为NLP相关的从业者,语言智能这场论坛是我最关注的。整个论坛以总论——学术理论——产业界——NLP与其他领域的集合这样一个节奏来进行。
总论
ACL终生成就奖得主李生教授提出虽然这两年随着BERT等大规模预训练模型的出现,使得NLP领域有着极大的发展,但是我们需要理解,目前这些方法说到底还是归纳,而不是演绎推理。正如之前“贝叶斯网络之父”Pearl老爷子提出的观点,目前人工智能大部分还是做相关性建模,而不是做因果性建模。而要实现最终的自然语言理解,必须要让模型具备演绎推理能力。
另外,目前的深度学习模型具备两个软肋:
对小样本数据的领域不能很好的建模。虽然few-shot learning是研究热度比较高的一个领域,但相比于具备大规模数据训练的模型来说,还不能很好地应用于工业产品。
对先验知识(人类常识)的利用能力不强。虽然现在有使用知识图谱或者基于树、图的方法来编码所谓的常识数据,但是这些方法并不具备普适性,对于某些复杂的垂直领域,还是很难去编码所有人类的常识,更多的是记住这些信息,而不是去理解。
另外李教授还提到了要借助脑科学,研究类脑智能,这是下个阶段人工智能研究发展的一个重要领域,同时他还介绍了脉冲神经网络。特意去搜了一下,脉冲神经网络是下一代的高级神经网络,相比于当前的人工神经网络,它还将时间概念纳入其中,是一种更高级别的模拟人脑智能的产物。它的核心是借鉴人脑的脉冲信号原理,具体的内容还没详细研究,但可想而知这个领域方向也会是今后研究的热点。
学术理论
学术理论方面,我对伊利诺伊大学香槟分校的终身教授Heng Ji女士提到的share and transfer理念比较感兴趣。她主要研究的是跨语言跨领域的信息抽取,虽然我日常工作中不会牵扯到跨语言,但是她提出的share and transfer理念感觉很fancy。这个理念的intuition是对于多语种NLP任务,无论是数据的标注还是单独学习,都是一件耗费成本的事情,有的小语种本身懂得人就不多,标注任务是难上加难,因此有必要研究一种跨语言的建模方法,不仅是去做NLP任务本身,也是为了能够节省标注的成本。简单说,这个理念分为两部分:
1、跨语言embedding表示学习。使用一些方法将两种不同语言的语料编码到公共的相似的向量空间中。
Heng Ji女士提到了利用语言学家的研究成果,利用语言的通用特征,比如词根,词性对应关系在不同语言中都是类似的,happy和unhappy的关系(在形容词前面增加un前缀表示反面)在其他外语中也能找到对应的例子。利用这种关系,将能够归纳出的所有类似特征编码到同一个语义空间中,然后对多个语言的语料进行表示空间的重构。
另外,她还提到了利用wiki百科或者其他结构化的开放知识库,将不同语言的实体进行对齐,得到两个对齐后的语言空间A和B,我们可以通过学习一个rotation矩阵,使得A通过这个矩阵总能旋转到与B非常接近的空间中。
2、跨语言的迁移学习,这是另外一种建立跨语言模型的方法。Heng Ji女士提到了一种cross-lingual adversarial transfer learning方法。我自己搜到了这篇论文,其网络结构图如下:
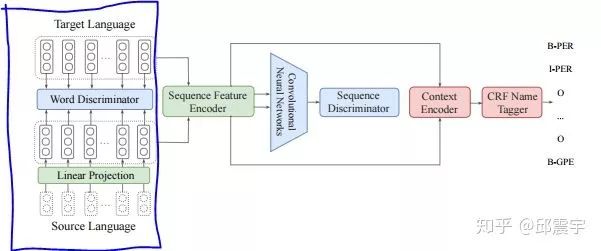
这是一个做跨语种序列标注问题的模型。左边蓝色框中的目的是在词级别上,将两个不同语种通过矩阵的变换,统一到一个相似的表示空间中,这是上面share的思想。而右边的部分则是为了做序列标注任务,不仅需要词级别的信息,还需要句子级别的信息,因此以变换空间后的词表示为基础,通过对抗式训练,在句子级别上,将两个语种统一到一个相似的表示空间中,同时训练标注任务的目标函数。
这样做的好处是即使有一个语种的标注语料很少,也能借助其他语种的语言信息做信息抽取任务。
除了Heng Ji女士的演讲外,来自苏州大学的张教授也分享了关于NLP的研究经验。其中我印象比较深刻是他提到了在NLP所有任务中,为何机器翻译的进展是最快的。他提到了三点:
1、机器翻译主要还是做的跨语种的语义映射问题,涉及理解的部分不多。
2、相对于其他生成式任务(如自动摘要)来说,机器翻译的源语种和目的语种的语料在长度上大致不会相差太多,因此做encoder-decoder时,不会损失太多的信息。
3、机器翻译的拥有大量具备广度和通用性的语料,这是其他任务无法比拟的,日常生活中的基本用语都可以作为翻译模型训练的语料。而在处理其他垂直领域的比较专业的语料时,机器翻译模型的性能也会降低。
产业界
论坛的产业界介绍部分主要是由达观数据和乐言科技来cover。虽然都是以NLP技术为基础,但是两家企业各自的业务重点不太一样。达观最近一段时间都在主推他们的RPA系统,今天看了他们放的演示,效果确实非常不错,结合了NLP,OCR以及其他办公自动化的技术,能够在文档录入、审阅、合同的处理、工单票据的处理等办公业务上取得非常好的实用效果,号称处理了速度是一个普通白领的30倍,且能保证100%的正确率,同时它有一个优点,就是不需要修改客户的办公系统,只需要通过简单的拖拽形式,就能完成场景复用,是一种非侵入式的技术模式。
关于RPA,其实这个概念很早就有了,现在之所以被很多公司拿出来做,还是因为目前NLP、图像方面的技术确实有大的进展,因此我觉得这应该是后续人工智能能够沉淀落地的一个比较好的场景。但是,我个人感觉做这个东西所需要的成本还是不小的,如果真的要做,还是要结合本公司的资源安排。
乐言科技重点放在认知智能上,以构建知识图谱为基础,将认知智能落地到实际的业务中。这个也是很多公司在做的事情。
NLP与其他领域的结合
论坛最后还是请了两位学术界的大咖来分享NLP与其他领域技术的结合场景。首先是来自复旦大学的黄宣菁教授分享了将NLP应用于社交媒体的工作。其重点在于不仅聚焦建模文本的语义空间,同时聚焦与构建社交用户的行为空间,将两个空间进行结合,做用户推荐、用户行为分析等工作。知乎貌似最近举办了一个比赛,是结合用户回答记录以及用户画像等信息,预测用户是否接受某个新问题的邀请,这个比赛的思想也是结合NLP和用户画像等信息做一些任务。个人感觉,NLP在这块可做的东西还有很多,发展潜力也很大。
最后是来自北邮的王小捷教授分享了NLP与CV结合的工作。个人对他介绍的一个东西印象非常深刻:结合图像做自编码。
通常,在NLP领域,对文本做自编码,能够无监督得获取文本的一些隐含信息。如果将图像的丰富信息也结合进来做自编码,应该可以得到一个信息密度非常大的模型。结合的方式有以下几种:
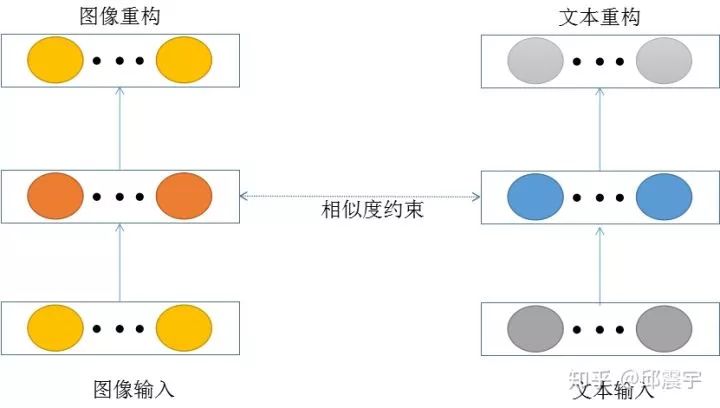
1、分别对文字和图像构建各自的自编码网络,在训练的时候,设计一个约束性训练函数,使得文字的自编码隐层和图像的自编码隐藏相似度尽可能得高,如图所示:
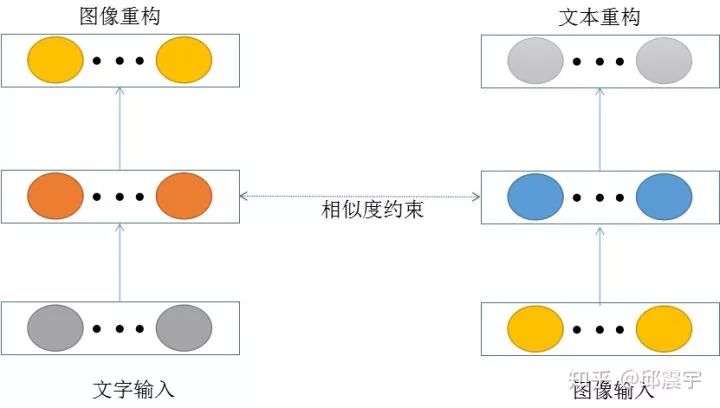
2、构建文字到图像的自编码网络以及图像到文字的自编码网络,训练方式与1相同。如图所示:
个人感觉通过上述方法,能够逼迫模型去学习图像和文字的公共表示空间信息,但是自编码隐层的维度大小也需要好好设计才行。
国际前沿算法论坛
本来下午这个论坛是非常感兴趣的,由包括机器学习届的泰斗Tom Mitchell等大咖的分享。但是由于上午结束的时间比较晚,等吃完饭去到会场发现会议室已经人太多,已经不让进了。原来是门口的人脸闸机出问题了,之前放了一些没有预约的人进去,导致很多后来有预约的同学都没办法进去,当时很多人在外面和主办方第四范式交涉了很久,最后似乎还是没有好的解决办法。因此前半段内容只能观看直播,到后半部分才进去。
由于听的断断续续的,所以就着重提一个我个人觉得比较新颖的议题,由北京大学信息学院教授王立威分析的对深度学习理论上的研究。
王教授的分享大致分为两个方面,分别是神经网络优化的数理证明以及如何利用数学理论指导设计神经网络。
神经网络优化的数理证明
王教授的分享提到,当前对于神经网络的优化能够找到最优解的前提有两个:
1、合适的参数初始化。
2、网络足够宽,足够深。
当具备这两个条件,可以使用数学理论证明能够找到神经网络优化的最优解。而且对于一些精心设计的网络,比如resnet,它是能够达到linear convergence rate。
另外,还需要将目光放到更远的地方,目前通用的优化的方法都是一阶优化方法,由于硬件性能、训练效率等等问题,一些二阶优化方法诸如牛顿法虽然在数学理论上相比于一阶优化方法有更快的收敛速度,但是在实际运用时仍然存在很多问题,因此这是一个需要被关注的研究点。
数理指导网络设计
这部分,王教授提到将神经网络设计与解微分方程联系起来。可以通过数学理论证明,resnet的设计与一阶微分方程的数值解是一致的。那如果是更加复杂的网络呢?
王教授举了transformer为例子。他提到transformer也有对应的微分方程,叫对流扩散方程,这个方程的数值解似乎不是很容易能够得到,有一些解方法,如Lie-Trottern,或者是Strang-Marchuk splitting方法。当然对于我这种数学小白,这些名字基本都不太懂,只能复述一下。王教授和他的团队通过理论的研究和实践,通过解对流扩散方程,设计出了一个类似于transformer的网络结构,其性能比transformer确实有一定的提升,这个网络结构被命名为Macaron Architecture。我搜了下这篇论文,论文名是:Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View。其网络结构如下图所示:
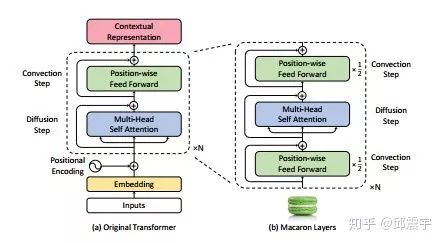
可以看到右边的网络结构就是通过解微分方程得到,整体结构与原始的transformer差不多,但是似乎比原始的transformer效果更好。
后记
以上就是参加30号一天的论坛的总结,总结了一下算法技术上的内容,但是没有过多的深入。通过参加这次会议,自己明确了以后研究的一些方向,也吸收了很多大咖精炼的思想理念。虽然有些遗憾,但是总体来说收获颇丰。希望能将今天的所学应用到 以后的工作与研究中。
另外31号还有一天的论坛会议,如果有不错的议题,我也会总结出来,供大家分享。



