简单易用NLP框架Flair发布新版本!
Flair 是 Zalando Research 开发的一款简单易用的 Python NLP 库,近日,Flair 0.4 版发布!
Flair 具备以下特征:
强大的 NLP 库。Flair 允许将当前最优自然语言处理(NLP)模型应用于文本,如命名实体识别(NER)、词性标注(PoS)、词义消歧和分类。
多语言。在 Flair 社区的支持下,该框架支持的语言种类快速增长。目前,Flair 还包括「one model, many languages」tagger,即一个模型可以预测不同语言输入文本的 PoS 或 NER 标记。
文本嵌入库。Flair 的接口简单,允许用户使用和结合不同的词嵌入和文档嵌入,包括 Flair 嵌入、BERT 嵌入和 ELMo 嵌入。
基于 Pytorch 的 NLP 框架。该框架直接在 Pytorch 之上构建,方便用户训练自己的模型,以及使用 Flair 嵌入与类试验新方法。
Flair 0.4 版本集成了更多新模型、大量新语言、实验性多语言模型、超参数选择方法、BERT 嵌入和 ELMo 嵌入等。
GitHub 链接:
https://github.com/zalandoresearch/flair
Flair 0.4 版本功能简介:
https://github.com/zalandoresearch/flair/releases
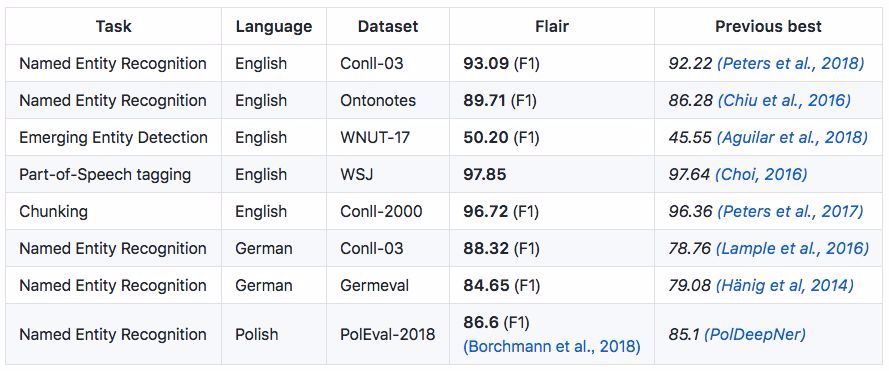
Flair 与其他最优方法的对比
Flair 在多项 NLP 任务上优于之前的最优方法:
近日,机器学习工程师 Tadej Magajna 撰文介绍了他使用 Flair 进行文本分类的过程,我们一起来看一下。

文本分类是将句子或文本文档分类为一或多个预定义类别的监督式机器学习方法。它是一种广泛使用的自然语言处理任务,在垃圾邮件过滤、情感分析、新闻篇章分类等问题中发挥重要作用。
目前主要的最优方法主要依赖于文本嵌入。它将文本转换成高维空间中的数值表征,允许文档、句子、单词、字符表示为该高维空间中的向量。
Zalando Research 近期发表的论文《Contextual String Embeddings for Sequence Labeling》提出了一种新方法,它持续优于之前的最优方法。这种方法基于 Flair 实现,并得到 Flair 的全力支持,该方法可用于构建文本分类器。
1. 准备
要安装 Flair,你需要先安装 Python 3.6。Python 3.6 安装指南:https://realpython.com/installing-python/
然后,运行以下命令安装 Flair:
pip install flair
这样就可以安装运行 Flair 所需全部包,包括 PyTorch。
2. 使用预训练分类模型
新发布的 Flair 0.4 版本包括两个预训练模型。一个是在 IMDB 数据集上训练的情感分析模型,另一个是「恶意语言检测」模型(目前仅支持德语)。
使用、下载和存储模型已被集成到一个方法中,这样使用预训练模型的过程更加直接便捷。
要使用情感分析模型,只需运行以下代码:
from flair.models import TextClassifier
from flair.data import Sentence
classifier = TextClassifier.load('en-sentiment')
sentence = Sentence('Flair is pretty neat!')
classifier.predict(sentence)
# print sentence with predicted labels
print('Sentence above is: ', sentence.labels)
第一次运行上述代码时,Flair 会下载该情感分析模型,并默认将其存储到主目录的.flair 子文件夹。该过程需要几分钟时间。
上述代码首先加载所需库,然后将情感分析模型加载到内存中,接下来在 0 到 1 的分数区间中预测句子「Flair is pretty neat!」的情感分数。最后的命令输出是:The sentence above is: [Positive (1.0)]。
现在你可以将代码整合到 REST api 中,这样就可以提供可与谷歌的 Cloud Natural Language API 情感分析相媲美的服务,而后者在应用于大量请求的生产过程中时较为昂贵。
3. 训练自定义文本分类器
要训练自定义文本分类器,我们首先需要一个标注数据集。Flair 的分类数据集格式基于 Facebook 的 FastText 格式。该格式需要在每一行的开头用前缀 __label__ 定义一或多个标签。格式如下所示:
__label__<class_1> <text>
__label__<class_2> <text>
本文将基于 Kaggle 的 SMS Spam Detection 数据集用 Flair 构建垃圾邮件分类器。该数据集适合学习,因为它只包含 5572 行,足够小,可以在 CPU 上几分钟内完成模型训练。
该数据集中的 SMS 信息被标注为垃圾(spam)或非垃圾(ham)。
3.1 预处理:构建数据集
首先下载数据集,以获取 spam.csv。然后,在数据集所在目录中运行以下预处理代码段,将数据集分割成训练集、开发集和测试集。
确保你的计算机上安装了 Pandas。如果没有安装,先运行 pip install pandas。
import pandas as pd
data = pd.read_csv("./spam.csv", encoding='latin-1').sample(frac=1).drop_duplicates()
data = data[['v1', 'v2']].rename(columns={"v1":"label", "v2":"text"})
data['label'] = '__label__' + data['label'].astype(str)
data.iloc[0:int(len(data)*0.8)].to_csv('train.csv', sep='\t', index = False, header = False)
data.iloc[int(len(data)*0.8):int(len(data)*0.9)].to_csv('test.csv', sep='\t', index = False, header = False)
data.iloc[int(len(data)*0.9):].to_csv('dev.csv', sep='\t', index = False, header = False);
这样可以移除数据集中的重复项,打乱(shuffle)数据集,按 80/10/10 将数据分割成训练集、开发集和测试集。
运行成功,你会看到 FastText 格式的 train.csv、test.csv 和 dev.csv,可以直接用于 Flair。
3.2 训练自定义文本分类模型
在生成数据集的目录中运行以下代码:
from flair.data_fetcher import NLPTaskDataFetcher
from flair.embeddings import WordEmbeddings, FlairEmbeddings, DocumentLSTMEmbeddings
from flair.models import TextClassifier
from flair.trainers import ModelTrainer
from pathlib import Path
corpus = NLPTaskDataFetcher.load_classification_corpus(Path('./'), test_file='train.csv', dev_file='dev.csv', train_file='test.csv')
word_embeddings = [WordEmbeddings('glove'), FlairEmbeddings('news-forward-fast'), FlairEmbeddings('news-backward-fast')]
document_embeddings = DocumentLSTMEmbeddings(word_embeddings, hidden_size=512, reproject_words=True, reproject_words_dimension=256)
classifier = TextClassifier(document_embeddings, label_dictionary=corpus.make_label_dictionary(), multi_label=False)
trainer = ModelTrainer(classifier, corpus)
trainer.train('./', max_epochs=20)
首次运行上述代码时,Flair 将下载所需的全部嵌入模型,这需要几分钟时间。接下来的整个训练过程需要 5 分钟时间。
该代码段先将所需的库和数据集加载到 corpus 对象中。
接下来,我们创建嵌入列表(两个 Flair contextual string 嵌入和一个 GloVe 词嵌入)。然后将该嵌入列表作为文档嵌入对象的输入。堆叠和文档嵌入(stacked and document embedding)是 Flair 中最有趣的概念之一,提供了将不同嵌入结合起来的方法。你可以使用传统词嵌入(如 GloVe、word2vec、ELMo)和 Flair contextual string 嵌入。上述例子使用基于 LSTM 的方法结合词嵌入和 contextual string 嵌入,以生成文档嵌入。
详见:
https://github.com/zalandoresearch/flair/blob/master/resources/docs/TUTORIAL_5_DOCUMENT_EMBEDDINGS.md
最后,上述代码训练模型输出 final-model.pt 和 best-model.pt 文件,表示存储的训练好的模型。
3.3 使用训练好的模型进行预测
在相同目录中运行以下代码,使用导出的模型生成预测结果:
from flair.models import TextClassifier
from flair.data import Sentence
classifier = TextClassifier.load_from_file('./best-model.pt')
sentence = Sentence('Hi. Yes mum, I will...')
classifier.predict(sentence)
print(sentence.labels)
输出结果是 [ham (1.0)],表示该模型 100% 确定示例信息并非垃圾消息。
参考链接:
https://towardsdatascience.com/text-classification-with-state-of-the-art-nlp-library-flair-b541d7add21f
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!
文章来源:机器之心

《机器读心术之文本挖掘与自然语言处理》课程在全国的独有性,以及将艰难知识通俗化讲授的能力,学完将熟悉文本挖掘与自然语言处理技术,懂得怎样运用到自己的实际工作,将数据挖掘能力从有限的结构化数据延伸到非结构化的海量文字材料。点击下方二维码报名课程





