想降低云服务的花销?或许深度强化学习能帮到你 | 论文
安妮 编译自 arXiv
量子位 出品 | 公众号 QbitAI
随着云计算的普遍应用,控制计算成本越来越重要,但有调查显示,30%-45%的云开销被浪费了。一些大企业通常咨询专家控制开支,但一些小企业或个人就无法节省费用了。
近日,研究人员发现深度强化学习算法能平衡云服务性能和开销,用户不用规划如何实现,只需设置他们想达到的效果即可。这项研究大大降低了控制云服务开销的专业门槛。
研究人员将这项研究的论文《Automated Cloud Provisioning on AWS using Deep Reinforcement Learning》发表在arXiv上,论文由微软的Zhiguang Wang、商业遥感卫星服务商BlackSky的Chul Gwon和Adam Iezzi以及美国马里兰大学的Tim Oates四名研究人员共同完成。
Double Deep Q-learning
为了让用户轻松减少开销,研究人员用了哪些方法呢?
在这篇论文里,研究人员探索了强化学习在云配给上的应用,用户可以制定基于性能和开销的奖励,强化学习算法计算如何去获取奖励。
研究人员用double deep Q-learning算法在CloudSim云计算仿真器上模拟运行效果,结果能够显示强化学习的效果和这种方法的相对优劣。
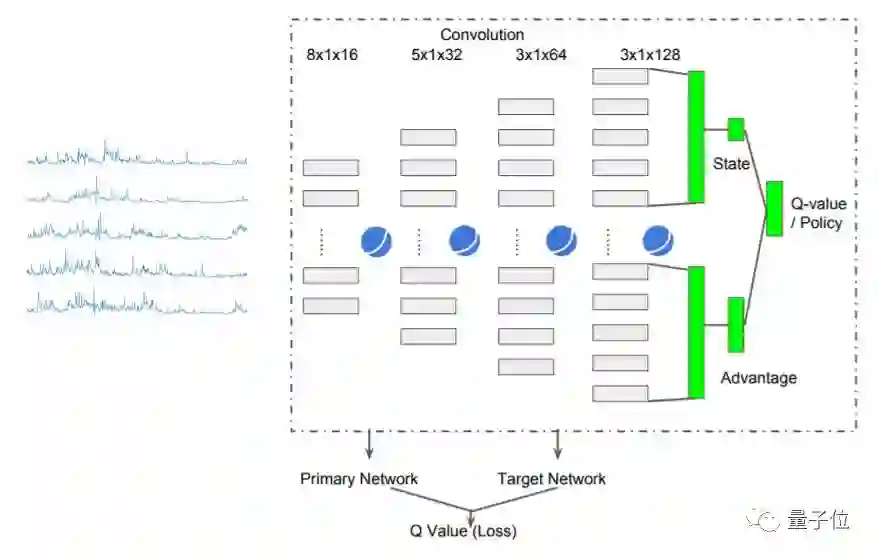
上图就是一张基于竞争架构的DDQN(double deep Q-learning network)结构图。SeLU函数激活了四个卷积层,并且没有进行池化操作。研究人员没有在最终输出前插入完全连接层,而是将最后卷积层的平坦特征图减半,以此计算状态和效果。
研究人员发现,这种架构有助于用更少的参数提高稳定性。
亚马逊AWS评测效果
亚马逊网络服务系统(Amazon Web Services,AWS)是亚马逊创建的云计算平台,它提供多种远程Web服务,Amazon EC2与Amazon S3都架构在这个平台上。
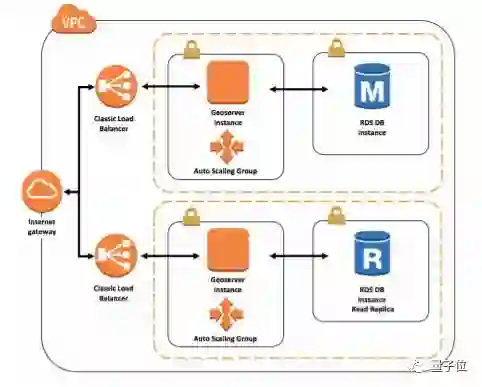
在论文中,研究人员展示了从简单的模拟器到CloudSim的迁移学习,之后再从CloudSim迁移到一个真实的AWS云环境的实例。
在AWS上的运行效果受到了运行时间的限制。研究人员在AWS系统上的运行阈值基线和DQN模型的时间只有3周,但运行D3QN的时间只有一个星期。为了帮助初始测试和开发AWS的环境,研究人员故意将tabular-based Q-learner的运行时间缩短了。
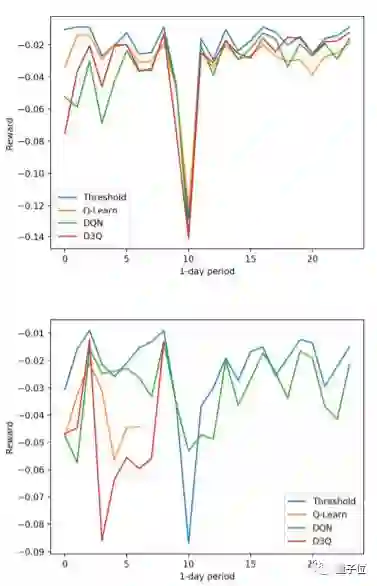
上图为运行结果,结果中包含用相同binning的模拟运行,方便研究人员与预期的结果进行比较。正如我们在模拟运行中所观察到的,如果leaner能在AWS上多运行一段时间,就能看到提高。
在实际的AWS环境中添加非零延迟值会影响结果。虽然很难看到奖励增多,随着时间的推移,奖励的变化明显减少了,这意味着性能是可以提高的。
商业机会
外国媒体Architecht在推荐这篇论文时,说它看起来像是个商业机会:
这是一个研究课题,如果有人想做,看起来又有些商业前景。这项研究的本质是训练一个系统,它能判断理想性价比和其他商业指标,比如“尽可能在平均用户响应时间增加不超过2%的情况下降低开销”。
这么有趣的事情,怎么能不看看论文呢?
论文获取地址:
https://arxiv.org/abs/1709.04305
— 完 —
活动报名

加入社群
量子位AI社群8群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot3入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot3,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态




