这家研究院太年轻,竟跟世界级选手“叫板”
金磊 发自 宇宙中心
量子位 报道 | 公众号 QbitAI
一家AI研究院的“打开方式”,是这样的;
支持学者发表国际顶会顶刊论文
8个月打造当时全球最大的超大规模智能模型“悟道”
年年都有图灵奖得主前来参会
汇聚AI一流学者94人,人才团队近260人
……
或许你会说,这就是一个研究院该有的样子。
但如果我说它仅仅成立了3年呢?
而且就拿打造大模型这事来说,放眼国内外,它还是全球唯一不是背靠大厂的那种非营利性机构。
不仅如此,与它同台竞技的,还都是“世界级选手”——DeepMind、OpenAI等等。

即便是在这种高手林立的大模型赛道上,这家研究院还做到了实力上的碾压,更是引发了国内外科研圈、媒体的关注。

至此,围绕这家如此年轻却又“战绩斐然”的研究院,便产生了不少的疑问:
它是谁?
又是怎么做到的?
一家成立刚满3年的研究机构
这家研究机构,名叫北京智源人工智能研究院 (简称智源研究院)。
或许它现在的名气倒是不小,但讲真,若是放到三年前提起这个名字,很多人都是不知道的。

关于智源研究院的成立,其实是由一场2018年的会议开始。
参会专家横跨产业、高校以及研究机构,原微软亚太研发集团首席技术官张宏江博士、原国家自然科学基金委员会主任杨卫院士、清华大学药学院鲁白教授等出席并发表了重要意见。
北京在人工智能方面已积累了人才、科研、产业方面的优势地位,和世界领先水平基本同步。但如何在“跟得很好、用得很好”的基础上,做出更多突破性研究,拿出更多引领国际潮流的创新贡献?
专家们聚在一起要商讨的核心问题便是:
如何在人工智能基础设施建设、科研组织模式、数据开放、场景开放、人才培养、国际合作等方面,推动北京人工智能创新工作的发展。
在经过长达数小时的激烈讨论,他们提出以下的六项建议:
建设“北京智源”等人工智能软硬件计算平台
建立“产学研用”联合创新的人工智能基础研究模式
积极推动政府数据和企业数据开放共享
开放人工智能应用场景和加大基础保障
加大人才培养、引进和完善保障措施
加大国际交流力度
而要实现上述的目标,就需要一个“载体”来统筹规划。
于是,北京人工智能领域的新型研发机构——北京智源人工智能研究院应运而生。

但也正如一般创业公司那般,智源研究在成立之初可以说是举步维艰:一间办公室、几个人,就这样开始了新一段人工智能的征程。

但在智源研究院成立之初,虽说艰难,但它还是立下了这样一个flag:
支撑北京在2028年率先成为国际领先的人工智能创新中心。
为此,一个名叫“顶天”和“立地”的科研布局图,就此诞生。
研究布局主要分为了“学术自由探索”和“目标导向的重大科研任务”两大方向。
结合科研布局的名称来看,可以推测出,就是不仅要在最前沿技术上做研究,还要让研究能够真真切切的用起来。
而要完成这些个目标,人才,成为了首要解决的问题。
为此,智源研究院在2019年4月便推出了“智源学者计划”。

三年时间来,已遴选智源学者近百人,其中38岁以下的青年科学家就有40位。
主要涉及的研究方向包括人工智能的数理基础、人工智能的认知神经基础、机器学习、自然语言处理、智能信息检索与挖掘、智能系统架构与芯片等。
“智囊团”组建完毕,智源研究院锁定了三大人工智能的可行路径——“信息、生命和物理”,前后分别研发了超大规模模型。
例如在信息方面,智源研究院发布了连创中国首个、世界最大纪录的悟道大模型。

“悟道”模型的参数规模达到1.75万亿,是GPT-3的10倍,打破了之前由Google Switch Transformer预训练模型创造的1.6万亿参数记录。
同时,它还是首个在100%国产超算上训练的万亿模型,“悟道2.0”系列模型在国际公认benchmark取得9项精准记录,达到世界先进智能水平。
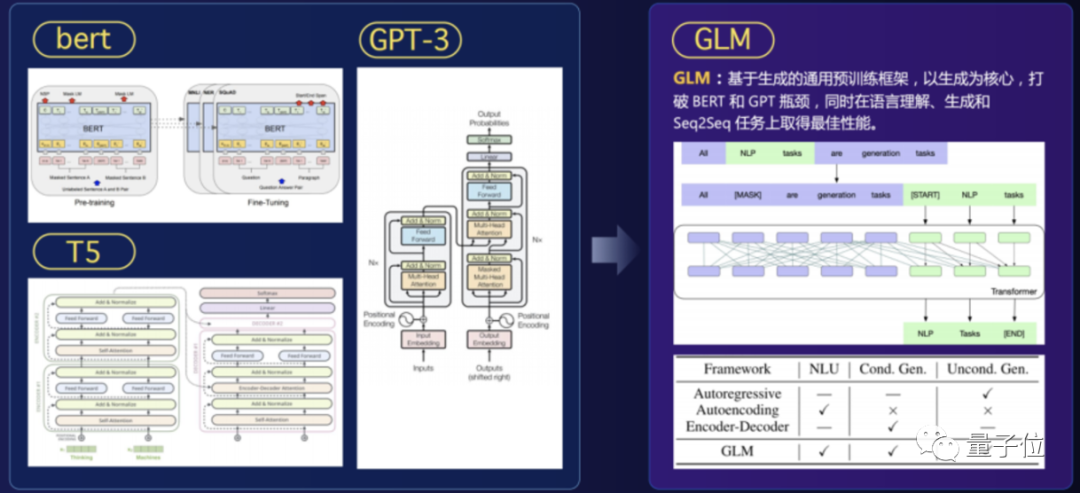
不仅仅是在参数量,更是在模型架构方面取得了突破,智源研究院提出的GLM2.0,首次打破BERT和GPT壁垒,以单一模型同时实现自然语言理解与生成任务。
在脑模拟与类脑智能研究方向上,智源研究院启动了“天演”生命智能模型建设,通过逐步搭建世界运行效率最高、模拟级别最精细的生物神经网络仿真软硬件系统,构建生命智能模型并挖掘生物智能机制机理,推动信息科学从计算范式到仿脑范式的跨越。
除了重大科研任务外,智源研究院学术探索中也是成绩斐然。
三年来,自由探索和目标导向相结合的体制机制展现出勃勃生机,实现科研成果的量质并重,智源研究院发表或支持发表国际AI顶会顶刊论文1470余篇,其中,被AAAI、CVPR、ACL、ICLR、NIPS、SIGIR、TPAMI等国际顶级会议期刊收录论文约1060篇,占比逾七成,形成多个国际首创、首发重大成果。
同时,智源研究院重视重大科研任务的“沿途下蛋”,截至2021年10月,其已经申请中国专利78件,获得发明专利授权44件,登记软件著作权24项。
而学术生态,是智源研究院“狠抓”的另外一个重要方向。
通过建设智源社区、青源会等线上线下相结合的社区组织,每年举办一届北京智源大会,邀请全球人工智能领域顶尖专家,共同探讨人工智能前沿研究进展及产业发展热点。
……
而上述的这些,还只是智源研究院所取得成绩的一隅,更多相关内容可以点击这里查看。

但放在三年的时间线上来看,它的效率和质量着实有些快得惊人。
那么接下来的一个问题便是:
为何“智源模式”能有这样的速度?
印象中的智源研究院,似乎从成立之初开始,便每年都会发布让业界瞩目的科研成果,其规模也是朝着不断壮大的趋势在发展。
那么智源研究院,与其它的科研机构到底又有怎样的区别?为什么能做到如此的“快准狠”?
就在刚刚,它在“宇宙中心”五道口的智源大厦新址,举办了三周岁的“生日宴”。
而在这场活动中,与之相关的诸多谜底都得到了解释。

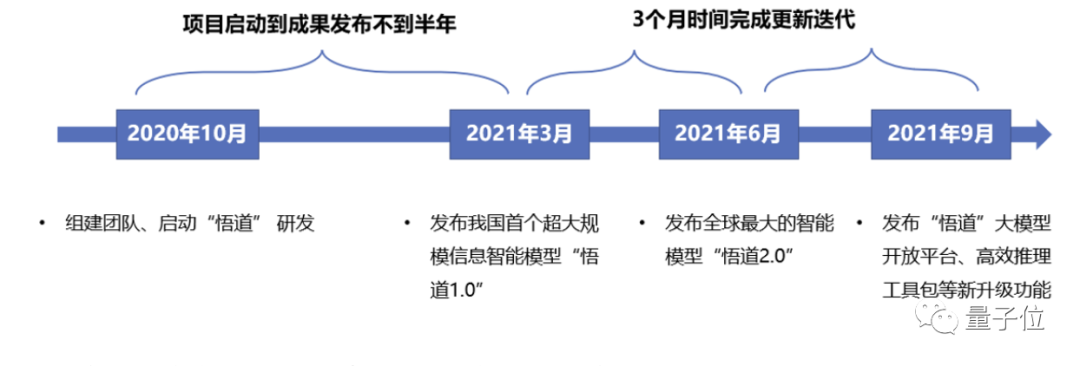
还是以悟道大模型为例,它的速度可以说是非常之快:
从立项到发布,只花了8个月时间。
而后的2次更新迭代,也各花费了3个月时间。
这种智源速度背后,一个非常重要的因素就是众智。
换言之,就是通过智源的“号召力”,把产学研各界的力量集中到了一起。
在短短时间内,智源便把来自10个不同机构近120人“聚”到了一起,汇聚资金、数据与算力。
而目标非常的明确且清晰,就是集中力量办大事——把这个大模型给搞出来。

而这种众智的背后,体现的正是智源研究院的独有模式——智源模式:
自由探索和目标导向。
自由探索,是指智源研究院能够赋予科学家最大的技术路线决定权和经费使用权。
换言之,就是只要在智源搞项目,那就大胆干、放心干,没有其他后顾之忧。
而刚才提到的“集中力量办大事”,便是目标导向的核心含义,即同时快速组建跨机构、大协作、高强度的科研团队,快速推进。
或许你会产生疑问:
智源研究院做的事情,为什么听着像是做一个“大杂烩”的事情?
但实则并不是如此,智源研究院所做的事情不是“N+1”,也就是在众多已有研究院的情况再来一个。
更符合实际的情况,应当是“1+X”,是将所有原有的研究优势汇聚成一个协同的联合体,为下一代人工智能的发展做一套新体系。
这是“智源模式”科研组织模式的展现,之于在人才发展模式上,智源研究院所支持的模式,便是“青年人才挑大梁当主角”。
大方向、大问题会由顶尖科学家来制定,而后由智源研究院的院务会快速做决策,有甚者五分钟就能拍板决定。
项目在启动之后,便是由真正的主角——青年学者来领衔了,在项目进行的过程中也是非常灵活,可以随时进行“微调”,而且不会有任何“门户之分”。
而这也正是智源研究院能够吸引众多年轻科研工作者的原因,毕竟谁又会拒绝一个自由且有权利的科研环境呢?
正如在智源研究院工作的一位算法工程师就曾这样描述:
智源是包容更开放的,不强调单一文化,就像一座动物园。可以包容任何一种性格的人,在这里找到自己感到舒服的姿势,做出贡献。
而且在智源研究院所做的成果,并不是一时的,而是要创造经得起时间检验的代表作,属于智源,更是属于年轻人自己的那种。
张宏江在“生日宴”现场还立下了这样一个flag:
智源研究院,永远要做最年轻的研究院。

最后一个重要的区别,便是智源研究院是开源、开放的。
智源研究院从注册开始,其单位性质便是完全中立的非营利性机构,而且还会坚持非营利的这种状态。
截至目前,大部分智源研究院所取得的科研成果,包括大模型等,均已全面向产学研各界开放使用。
正如张宏江所表述:
未来,大模型就像一个世纪前的发电厂一样,它会形成类似于电网一样的基础设施,在推动各行业智能化升级上发挥重要作用,具有非常广泛的应用前景。
智源的大模型更像是Linux,而像红帽所做的商业性工作,就交给其它大模型来吧。

而在我们来看,智源研究院所要做的事情,是要把自己也打造成一个“大模型”。
这种“大模型”是要汇聚中国的人口数据等红利、中国的人工智能顶尖人才、中国的最前沿技术。
而后智源要形成并找到一种最佳的“算法”——科研系统。
……
早在智源研究院成立之初便提出过一个观点:
世界AI看北京。
而站在三年后的现在来看,智源已然用创新的科研方式成功让AI探索走进“北京时间”。
但现在它目光所及,应当是要从北京走向全国乃至世界。
至于“智源模式”在接下来的过程中是否还是依旧正确,依旧具备创新性和价值性,就需要时代的发展来给出正解了。
— 完 —

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」「点赞」和「在看」
科技前沿进展日日相见 ~





