分布式机器学习框架与高维实时推荐系统


分享嘉宾:刘一鸣 第四范式
编辑整理:白木其尔、Hoh
内容来源:第四范式 | 先荐
出品平台:DataFunTalk
注:转载请在后台留言“转载”。
导读:随着互联网的高速发展和信息技术的普及,企业经营过程中产生的数据量呈指数级增长,AI 模型愈发复杂,在摩尔定律已经失效的今天,AI 的落地面临着各种各样的困难。本次分享的主题是分布式机器学习框架如何助力高维实时推荐系统。机器学习本质上是一个高维函数的拟合,可以通过概率转换做分类和回归。而推荐的本质是二分类问题,推荐或者不推荐,即筛选出有意愿的用户进行推荐。本文将从工程的角度,讲述推荐系统在模型训练与预估上面临的挑战,并介绍第四范式分布式机器学习框架 GDBT 是如何应对这些工程问题的。
主要内容包括:
推荐系统对于机器学习基础架构的挑战
大规模分布式机器学习场景下,不同算法的性能瓶颈和解决思路
第四范式分布式机器学习框架 GDBT
-
面临的网络压力及优化方向
01
推荐系统对于机器学习基础架构的挑战
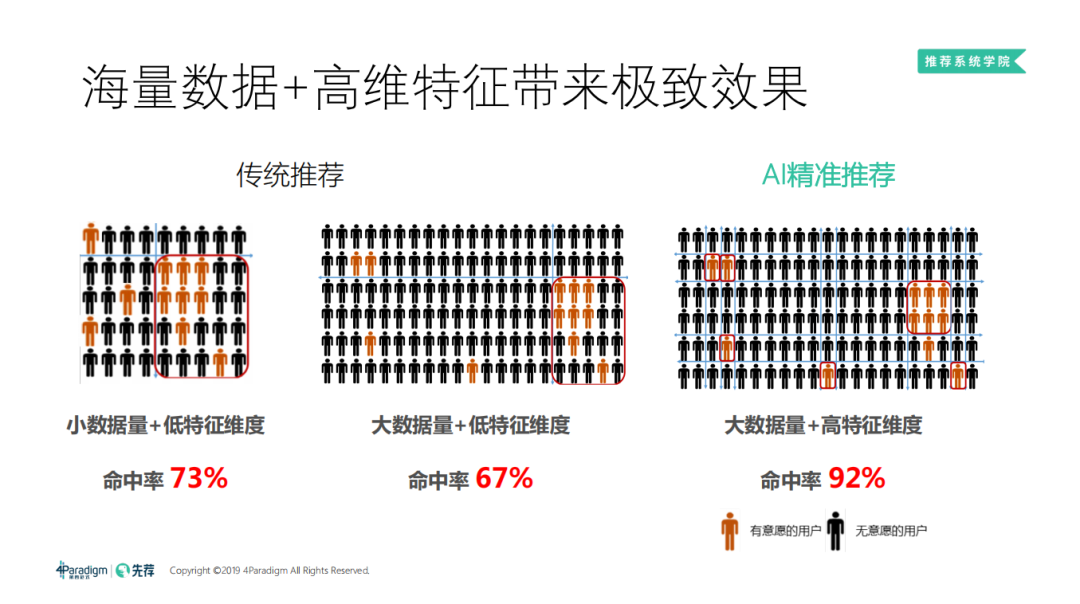
传统的推荐系统中,我们只用简单的模型或者规则来拟合数据,就可以得到一个很好的效果 ( 因为使用复杂的模型,很容易过拟合,效果反而越来越差 )。但是当数据量增加到一定的数量级时,还用简单的模型或者规则来拟合数据,并不能充分的利用数据的价值,因为数据量增大,推荐的效果上限也随之提升。这时,为了追求精准的效果,我们会把模型构建的越来越复杂,对于推荐系统而言,由于存在大量的离散特征,如用户 ID、物品 ID 以及各种组合,于是我们采用高维的模型来做分类/排序。
2. 强时效性带来场景价值
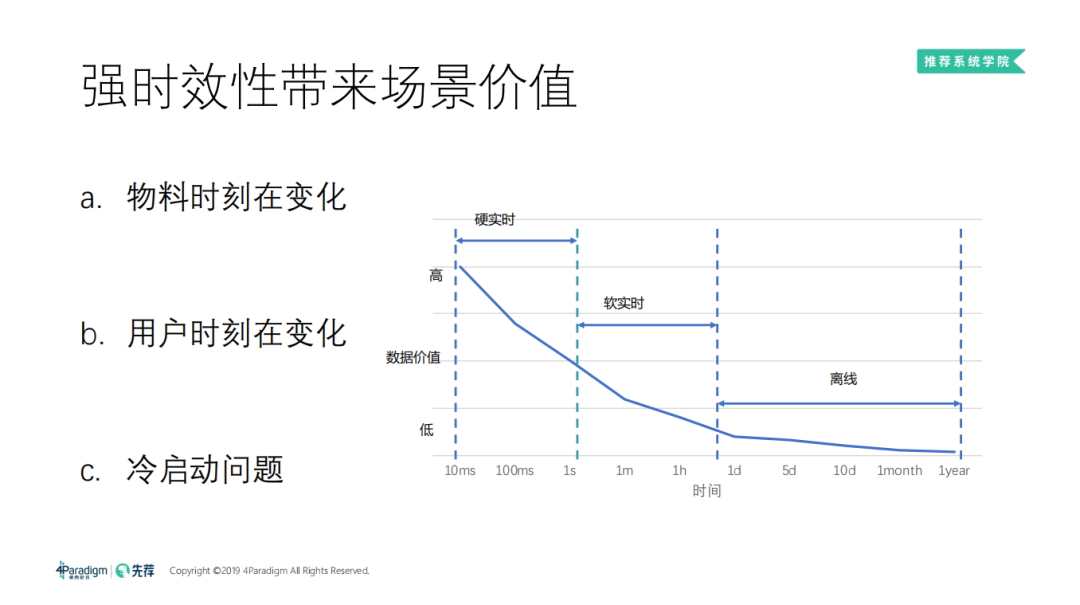
随着时间的推移,推荐场景面临的问题也在发生着变化,尤其是新闻、信息类的推荐,物料的变化非常快。同时,用户的兴趣和意愿也在时刻发生着变化。我们的模型都是根据历史数据总结出来的规律,距离当前时间越近的数据,对于预测越有指导意义。为了增强线上效果,就需要增加模型的时效性,按照数据价值的高低,将时效性分为:硬实时、软实时、离线,这里重点介绍下硬实时和软实时。
硬实时:
硬实时是指毫秒级到秒级的特征。这类特征往往具有指导性意义,同时对系统的挑战也是最大的,很难做到毫秒级或秒级的更新模型。通常的做法是通过快速的更新特征数据库,获取实时特征,来抓取秒级别的变化。尤其是新用户冷启动问题,当新用户登陆 APP,如果在几秒内,特征数据库就能收集到用户的实时行为,从而快速的抓取到用户的兴趣爱好,可以在一定程度上解决冷启动问题。
软实时:
软实时是指小时级到天级别的时间段。这时有足够的时间做批量的模型训练,可以周期性的更新模型的权重,使模型有更好的时效性。同时软实时对算力的消耗也是最大的,因为天级别的更新和周级别的更新模型,效果差距非常大。
3. 充分发挥数据的价值
02
大规模分布式机器学习场景下,不同算法的性能瓶颈和解决思路

当前面临的算力问题主要包括:
a. 数据量指数级增长,而摩尔定律已经失效。曾经有个玩笑,当程序员觉得程序跑得慢时,不需要优化代码,只需睡上一觉,换个新机器就好了。但现在摩尔定律已经失效,我们只能想方设法的优化代码和工程。
b. 模型维度高,单机内存难以承受,需要做分布式处理。
c. 模型时效性要求高,需要快迭代,会消耗大量的算力。这时,如何解决算力问题变得非常有价值。
2. 方案

可行的解决方案有:
分布式+异构计算解决扩展性问题:由于数据增长很快,单机的算力很难提升,尤其是 CPU 算力增长缓慢。我们可以用 GPU、加速卡来提供强有力的算力,用分布式的存储来更新模型,解决模型的扩展问题。
大规模参数服务器解决高维问题:当模型大到单机放不下时,我们就会使用参数服务器来解决高维问题。
流式计算解决时效性问题:对于模型的时效性有一种省算力的方法是用流式计算来解决,但是流式计算非常容易出错。
总结来说,就是如何优化模型训练速度,采用流式计算可以一定程度上解决这个问题。
3. 线性加速并非易事

03
分布式机器学习框架 GDBT
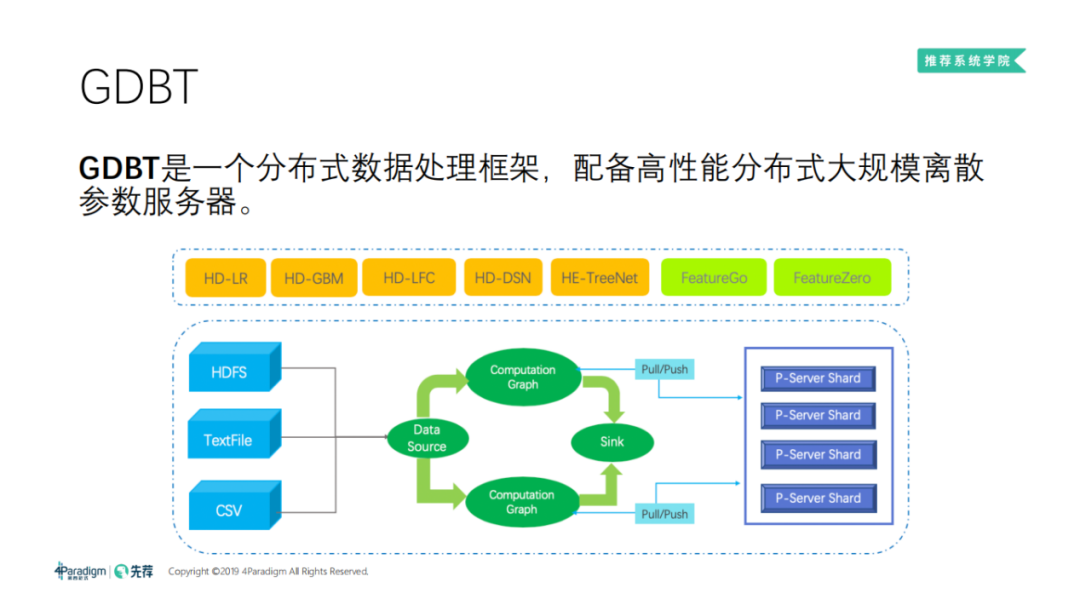
GDBT 是一个分布式数据处理框架,配备了高性能分布式大规模离散参数服务器。其核心组件包括:分布式数据源、参数服务器、计算图。基于 GDBT 框架我们实现了一系列的高维算法:如逻辑回归、GBM ( 树模型 )、DSN 等,以及自动特征和 AutoML 相关的算法。GDBT 的工作流程图如上图所示。
接下来,选择 GDBT 框架中的几个核心组件为大家详细介绍下:
2. 分布式数据源 ( 数据并行 )

分布式数据源 ( DataSource ) 是做数据并行的必备组件,是 GDBT 框架的入口。DataSource 最重要的一点是做负载均衡。负载均衡有很多种做法,这里设计了一套争抢机制,因为在线程调度中,线程池会采用 work stealing 机制,我们的做法和它类似:数据在一个大池子中,在每一个节点都尽可能读属于自己的数据,当消费完自己的数据时,就会去抢其它节点的数据,这样就避免了节点处理完数据后的空置时间,规避了"一核有难八核围观"的现象。
由于 DataSource 也是对外的入口,因此我们会积极的拥抱开源生态,支持多种数据源,并尽可能多的支持主流数据格式。
最后,我们还优化了 DataSource 的吞吐性能,以求更好的效率。因为有的算法计算量实际上很低,尤其是逻辑回归这种比较简单的机器学习算法,对 DataSource 的挑战是比较大的。
实验结果:
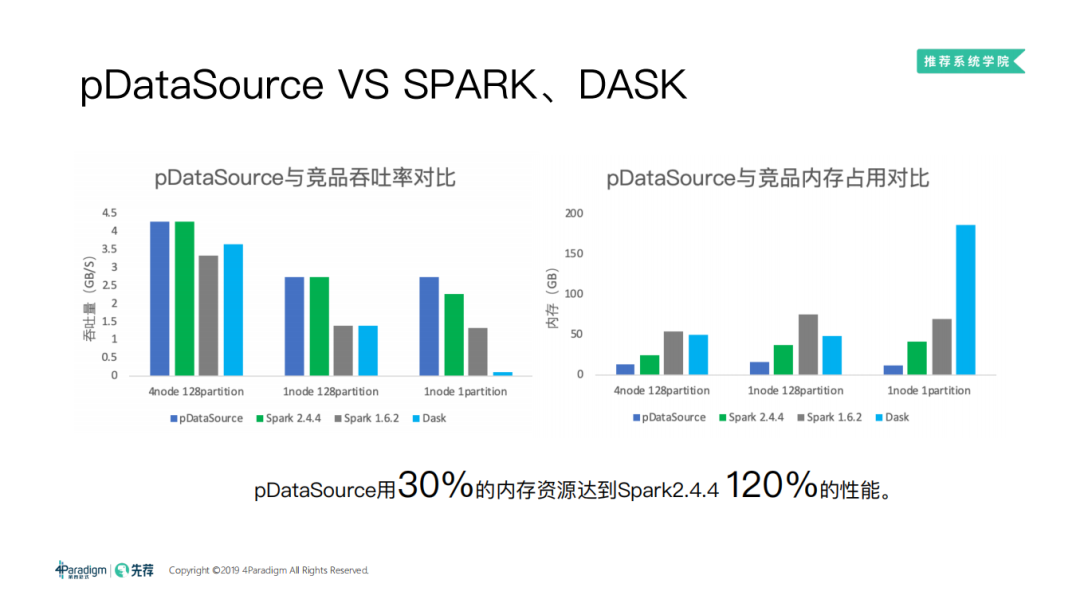
这里我们用 pDataSource 对比了 Spark 和 Dask。Spark 大家都比较熟悉,Dask 类似 python 版的 Spark,Dask 最开始是一个分布式的 DataFrame,渐渐地发展成了一个分布式的框架。如上图所示,由于我们在内存上的优化,通过对比吞吐量和内存占用,pDataSource 用30%的内存资源就可以达到 Spark2.4.4 120% 的性能。
3. 参数服务器
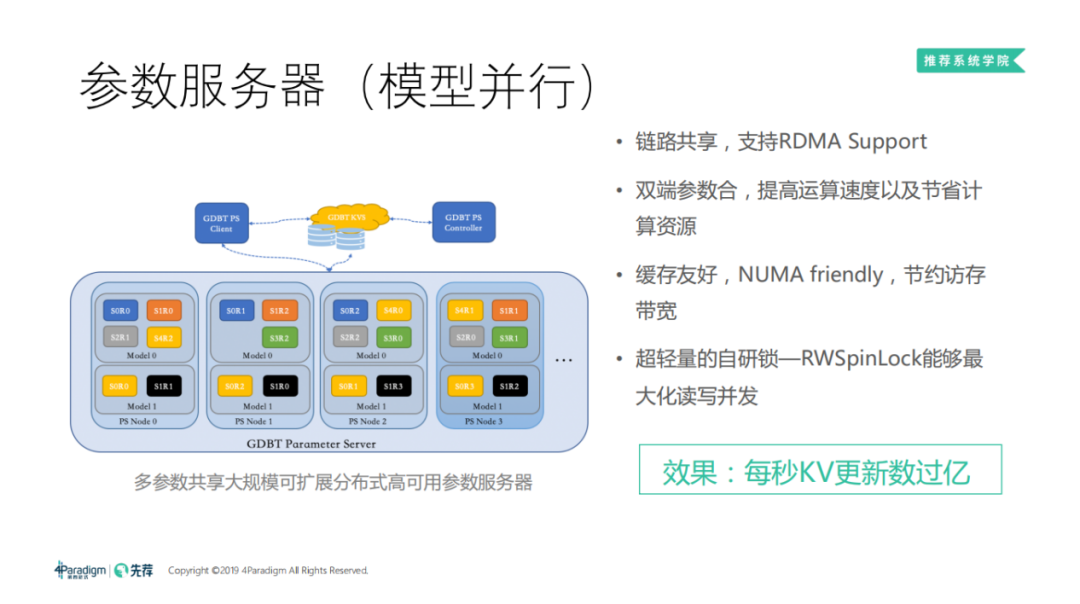
参数服务器类似于分布式的内存数据库,用来存储和更新模型。参数服务器会对模型进行切片,每个节点只存储参数的一部分。一般数据库都会针对 workload 进行优化,在我们的机器学习训练场景下,参数服务器的读写比例各占50%,其训练的过程是不断的读取权重、更新权重,不断的迭代。
对于大部分高维机器学习训练,参数服务器的压力都很大。参数服务器虽然自身是分布式的,但参数服务器往往会制约整个分布式任务的扩展性。主要是由于高频的特征和网络压力,因为所有的机器都会往参数服务器推送梯度、拉取权重。在实际测试中,网络压力非常大,TCP 已经不能满足我们的需求,所以我们使用 RDMA 来加速。
机器学习中的高频特征更新特别频繁时,参数服务器就会一直更新高频特征对应的一小段内存,这制约了参数服务器的扩展性。为了加速这个过程,由于机器学习都是一个 minibatch 更新,可以把一个 minibatch 当中所有高频 key 的梯度合并成一个 minibatch,交给参数服务器更新,可以有效的减轻高频 key 的压力。并且在两端都合并后再更新,可以显著减轻高频特征的压力。
对于大规模离散的模型,参数服务器往往要做的是大范围内存的 random massage。由于计算机访问内存是非常慢的,我们平常写代码时可能会觉得改内存挺快的,其实是因为 CPU 有分级缓存,命中缓存就不需要修改内存,从而达到加速。同时 CPU 还有分级的流水线,它的指令是乱序执行的,在读取内存时,可以有其它的指令插进来,会让人觉得访问内存和平常执行一条指令的时间差不多,实际上时间差了几十到几百倍。这对于执行一般的程序是可行的,但对于参数服务器的工作负载,是不可行的。因为其工作流程需要高频的访问内存,会导致大量的时间用在内存访问上。所以,如何增加命中率就显得尤为重要:
我们会修改整个参数服务器的数据结构。
我们做了 NUMA friendly。服务器往往不只一个 CPU,大多数是两个,有些高端的会有四个 CPU。CPU 周边会有内存,一个 CPU 就是一个 NUMA。我们尽量让参数服务器所有的内存绑在 NUMA 上,这样就不需要跨 CPU 访问内存,从而提升了性能。
还有个难点是如何保证线程安全。因为参数服务器是多线程的,面临的请求是高并发的,尤其是离线时,请求往往会把服务器压满。这时要保证模型的安全,就需要一个高效的锁。这里我们自研了 RWSpinLock,可以最大化读写并发。受限于篇幅,这里就不再进行展开。
最终的效果可以支持每秒 KV 更新数过亿。
4. 分布式机器学习框架的 Workload
① 分布式 SGD 的 workload
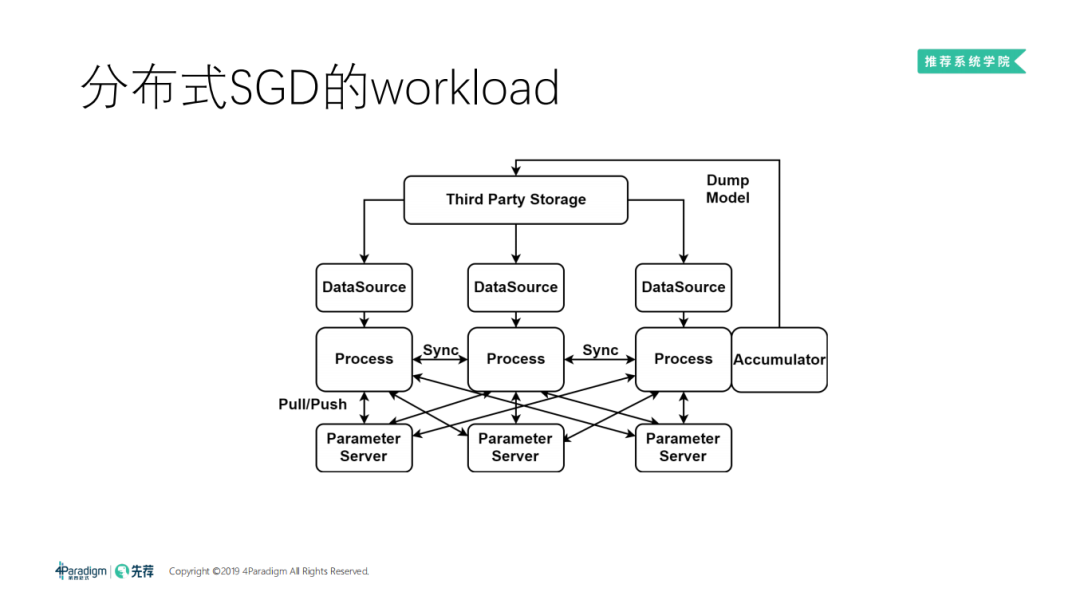
分布式 SGD 的 workload:
首先 DataSource 会从第三方的存储去读数据。这里画了三个机器,每个机器是一条流水线,数据源读完数据之后,会把数据交给 Process,由 Process 去执行计算图。计算图当中可能会有节点之间的同步,因为有时需要同步模式的训练。当计算图算出梯度之后,会和参数服务器进行交互,做 pull/push。最后 Process 通过 Accumulator 把模型 dump 回第三方存储 ( 主要是 HDFS )。
② 树模型的 workload
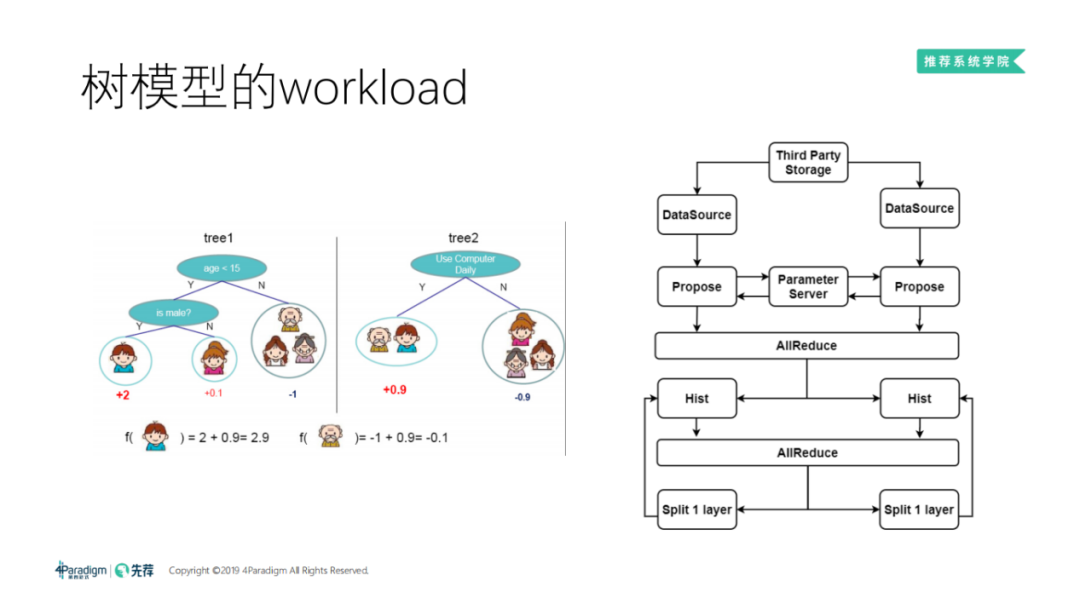
目前树模型的应用广泛,也有不少同学问到分布式的树模型怎么做。这里为大家分享下:
首先介绍下 GBDT ( Gradient Boost Decision Tree ),通过 GBDT 可以学出一系列的决策树。左图是一个简单的例子,用 GBDT 来预测用户是否打游戏。对于 Tree1,首先问年龄是否小于15岁,再对小于15岁的用户问是男性还是女性,如果是男性,会得到一个很高的分值+2。对于 Tree2,问用户是否每天使用电脑,如果每天都使用,也会得到一个分值+0.9,将 Tree1 和 Tree2 的结果相加得到用户的分值是2.9,是一个远大于零的数字,那么该用户很有可能打游戏。同理,如果用户是位老爷爷他的年龄分值是-1,且他每天也使用电脑,分值也是+0.9,所以对于老爷爷来说他的分值是-0.1,那么他很有可能不会打游戏。这里我们可以看出,树模型的关键点是找到合适的特征以及特征所对应的分裂点。如 Tree1,第一个问题是年龄小于15岁好,还是小于25岁好,然后找到这个分裂点,作为这个树的一个节点,再进行分裂。
树模型的两种主流训练方法:
❶ 基于排序:
往往很难做分布式的树模型。
❷ 基于 Histogram:
DataSource 先从第三方的存储当中读数据,然后 DataSource 给下游做 Propose,对特征进行统计,扫描所有特征,为每个特征选择合适的分类点。比如刚刚的例子,我们会用等距分桶,我们发现年龄基本上都是在0到100岁之间,可以以5岁为一个档,将年龄进行等分,作为后面 Propose 的方案。有了 Propose 的点之后,由于每个机器都只顾自己的数据,所以机器之间要做一次 All Reduce,让所有的机器都统一按照这些分裂点去尝试分裂,再后面就进入了一个高频更新、高频找特征的过程:
首先我们会执行 Histogram 过一遍数据,统计出某一个特征,如年龄小于15岁的增益是多少,把所有特征的 Propose 点的增益都求出来。由于机器还是只顾自己的数据,所以当所有机器过完自己的数据之后还会做一次 All Reduce,同步总的增益。然后找一个增益最大的,给它进行分裂,不断的执行这样的过程。
其实这个过程最开始时,尤其是 XGboost,计算量都用在如何统计 Histogram 上,因为 Histogram 过数据的次数特别多,而且也是一个内存 random massege 的过程,往往对内存的压力非常大。我们通常会做的优化是使用 GPU,因为显存比内存快很多,因此树模型可以用 GPU 加速。
04
面临的网络压力及优化方向

a. 模型同步,网络延迟成为瓶颈。首先分布式 SGD Workload 主要是模型同步,尤其是同步模式时,当机器把梯度都算好,然后同一时刻,几十个几百个节点同时发出 push 请求,来更新参数服务器,参数服务器承担的压力是巨大的,消息量和流量都非常大。
b. 计算加速,带宽成为瓶颈。我们可以用计算卡加速,计算卡加速之后,网络带宽成为了瓶颈。
c. 突发流量大。在机器学习中,主要难点是突发流量。因为它是同步完成之后,立刻做下一步,而且大家都齐刷刷的做。另一方面 profile 是非常难做的。当你跑这个任务时会发现,带宽并没有用完,计算也没有用完。这是因为该计算的时候,没有用网络带宽,而用网络的时候没有做计算。
2. RDMA 硬件日渐成熟

随着 RDMA 硬件的日渐成熟,可以带来很大的好处:
低延迟:首先 RDMA 可以做到非常低的延迟,小于 1μs。1μs 是什么概念,如果是用传统的 TCP/IP 的话,大概从两个机器之间跑完整个协议栈,平均下来是 35μs 左右。
高宽带:RDMA 可以达到非常高的带宽,可以做到大于 100Gb/s 的速度。现在有 100G、200G 甚至要有 400G了,400G 其实已经超过了 PCIE 的带宽,一般我们只会在交换机上看到 400G 这个数字。
绕过内核:RDMA 可以绕过内核。
远端内存直接访问:RDMA 还可以做远端内存的直接访问,可以解放 CPU。
用好这一系列的能力,可以把网络问题解决掉。
3. 传统网络传输
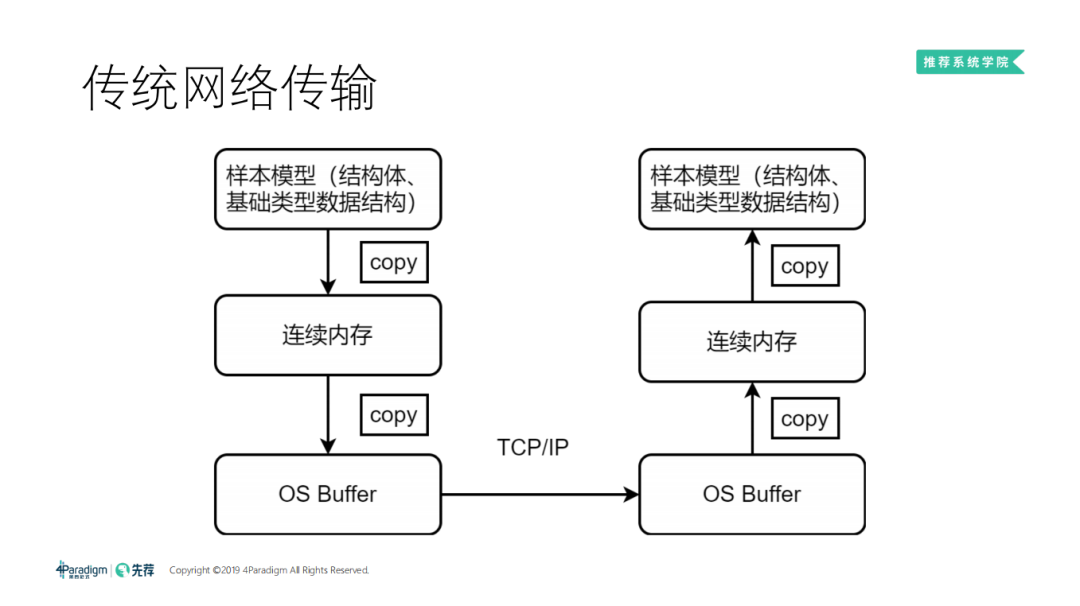
传统网络传输是从左边发一条消息发到右边:
首先把样本模型序列化,copy 到一段连续的内存中,形成一个完整的消息。我们再把消息通过 TCP 的协议栈 copy 到操作系统,操作系统再通过 TCP 协议栈,把消息发到对面的操作系统。对面的 application 从 OS buffer 把信息收回,收到一段连续的内存里,再经过一次反序列化,生成自己的样本模型,供后续使用。
我们可以看到,在传统的网络传输中,共发生了四次 copy,且这四次 copy 是不能并行的,序列化之前也不能发送,没发过去时,对方也不能反序列化。由于 CPU 主频已达瓶颈,不能无限高,这时你的延迟主要就卡在这个流程上了。
4. 第一步优化
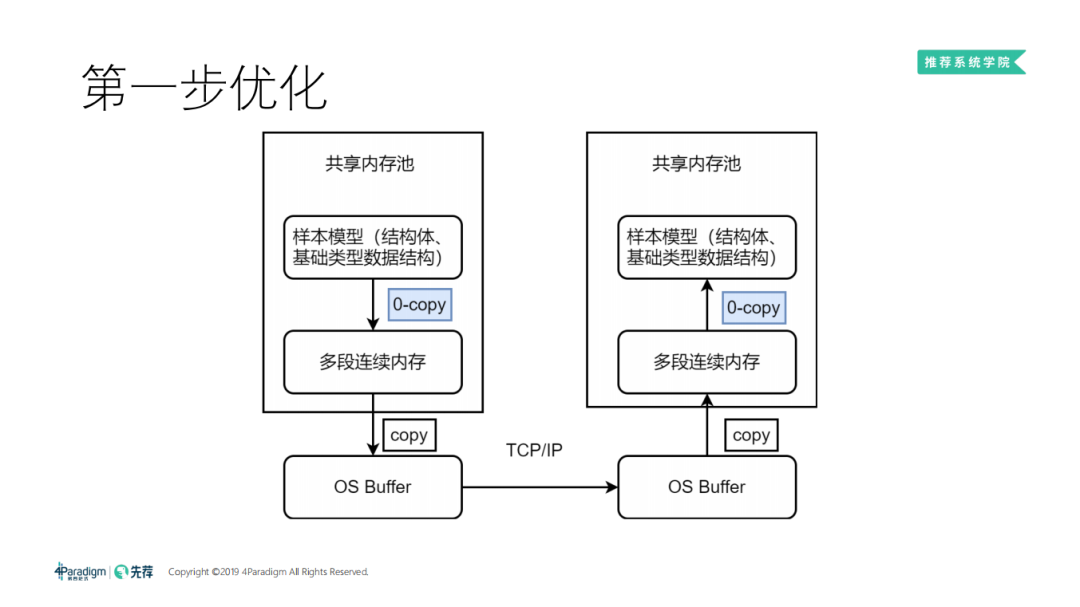
第一步优化是我们自研的序列化框架。我们一开始把样本模型放在内存池中。而这个内存池是多段连续的内存,使任何数据结构都可以变成多段连续的内存。这个序列化的过程,其实就是打一个标记,标明这个样本模型要发送,是一个 zero copy 的过程。可以瞬间拿到序列化后的信息,由网络层通过 TCP 协议栈发到对端,对端收的时候也是不会收成一段大的内存,而是多段连续的内存。通过共享内存池的方式,可以减少两次 copy,让速度提升很多,但还是治标不治本。
5. 引入 RDMA
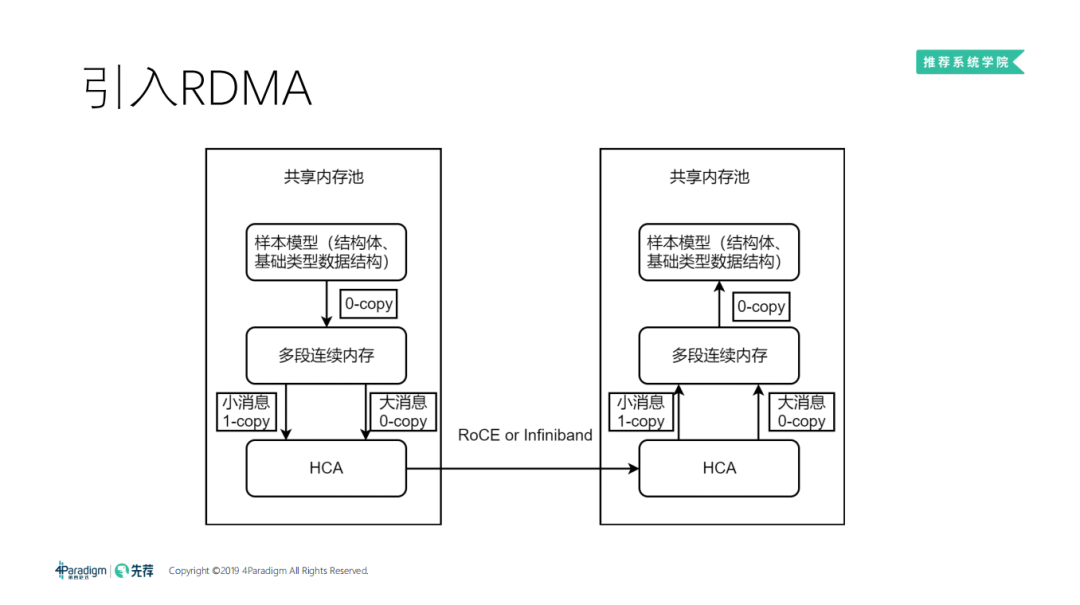
进而我们引入了 RDMA:
RDMA 可以直接绕过内核,通过另一种 API 直接去和网卡做交互,能把最后一次 copy 直接省掉。所以我们引入 RDMA 之后,可以变成一个大的共享内存池,网卡也有了修改操作内存的能力。我们只需要产生自己的样本模型后,去戳一下网卡,网卡就可以传输到对面。对面可以直接拿来做训练、做参数、做计算,整个流程变得非常快,吞吐也可以做到非常大。
6. 底层网络 PRPC
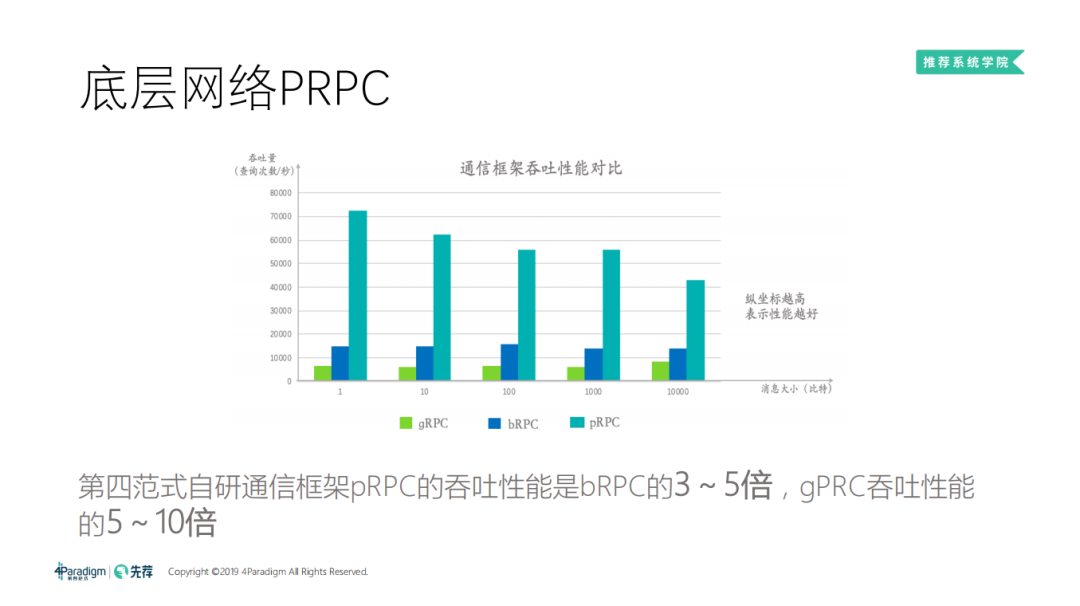
我这里对比的是 BRPC 和 GRPC,BRPC 的性能是我现在看到的 RPC 当中最快的,但是因为它不支持 RDMA,所以被甩开了三到五倍。因为 GRPC 兼容性的工作特别多,所以 GRPC 的性能会更差一些。这个对比并不是非常的科学,因为我们最大的收益来源是 RDMA 带来的收益。
7. 线上预估
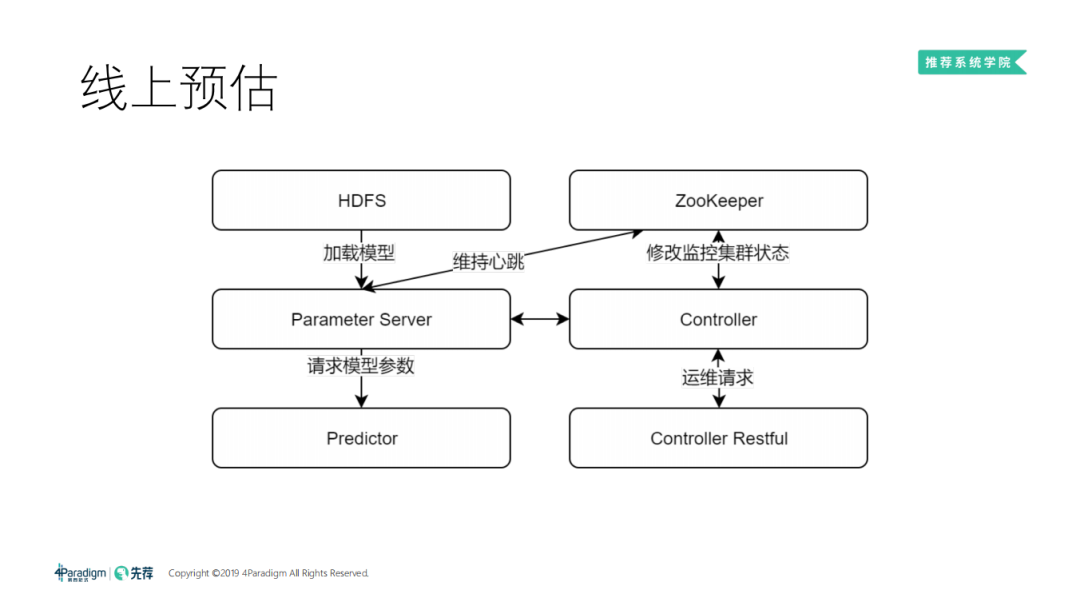
线上大部分时间,我们离线训练出的模型会放在 HDFS 上,然后把模型加载到参数服务器。会有一套 controller 去接受运维请求,参数服务器会给我们提供参数、预估服务对外暴露打分的接口。上图是一个最简单的线上预估的 Workload。
8. 流式更新、加速迭代
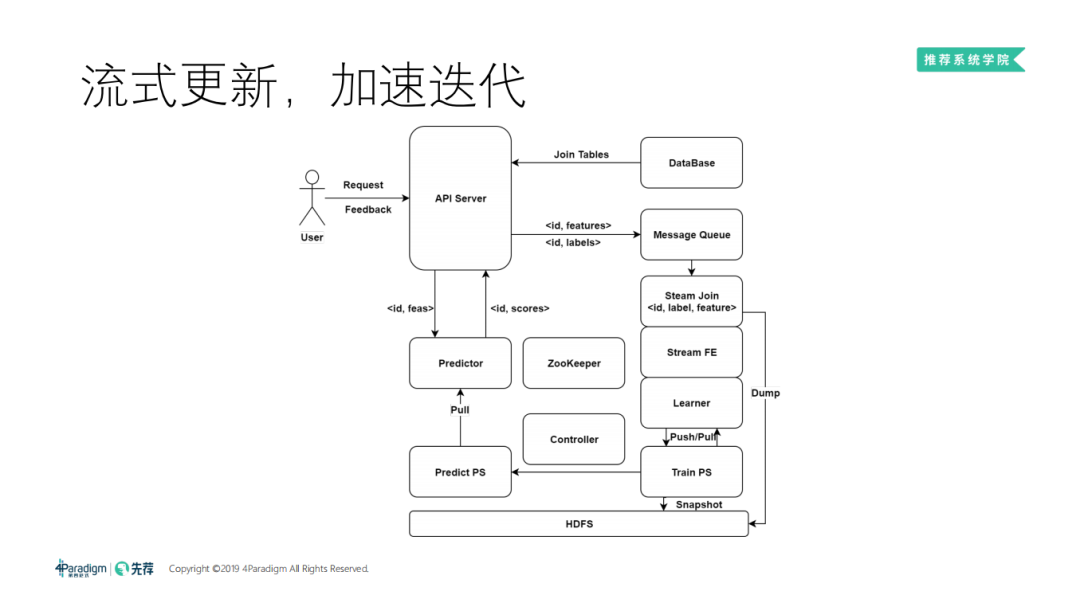
流式更新比较复杂:
大概是用户有请求过来,会有数据库把用户、物品的信息聚合起来,再去预估打分,和刚刚最简单的架构是一样的。打分之后要把做好的特征发送到 message Queue,再实时的做 join。这时 API server 会接受两种请求,一种是用户请求打分,还有一种是用户的 feedback ( 到底是赞,还是踩,还是别的什么请求 )。这时会想办法得到 label,通过 ID 去拼 label 和 feature,拼起来之后进一步要把特征变成高维向量,因为变成高维向量才能进入机器学习的环节,由 Learner pull/push 去更新训练的参数服务器,训练参数服务器再以一种机制同步到预估的参数服务器。
有了这样的一个架构,才能把流式给跑起来,虽然可以做到秒级别的模型更新,但是这个过程非常容易出错。
今天的分享就到这里,谢谢大家。
如果您喜欢本文,点击右上角,把文章分享到朋友圈~~
欢迎加入 DataFunTalk 推荐系统技术交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker),回复:推荐系统,逃课儿会自动拉你进群。

▬

刘一鸣
第四范式 | 机器学习基础架构负责人
第四范式先知平台独有的大规模分布式机器学习框架 GDBT 的设计者 ,主导落地了分布式大规模参数服务器和 RDMA 网络框架。主要研究领域为机器学习分布式系统设计及高性能优化。
关于我们:

一个在看,一段时光!👇


