

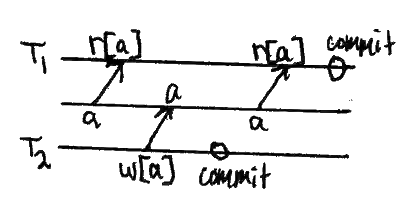

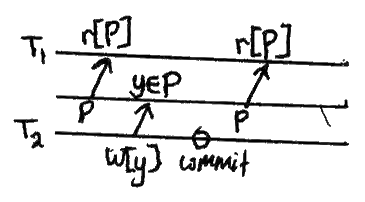


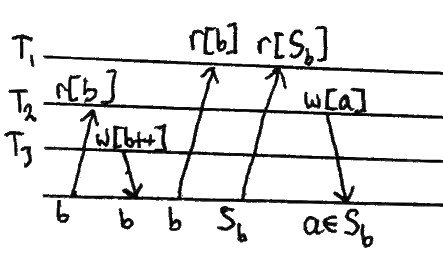


长按识别二维码享更多精彩
↑ 点击上方蓝字关注我们,和小伙伴一起聊技术!
您可能已经在数据库的文档中看到了隔离级别,感到有些手足无措。很少有日常使用事务的例子真正提到了隔离。大多数使用数据库的默认隔离级别,并希望获得最好的隔离级别。这是一个需要理解的基本话题,如果你花点时间来研究这个指南,你会对SQL事务隔离有深入的认识。
基本的定义
为了正确地理解SQL隔离级别,我们首先应该考虑事务本身。交易的概念来自合同法:法律交易必须是原子的(要么所有的条款都适用,要么没有),一致的(遵守法律协议),并且是持久的(在承诺之后,各方不能收回他们的承诺)。这些属性是数据库管理系统中流行的“ACID”缩写中的A、C和D。最后的字母“I”是孤立的,这是这篇文章的全部内容。
在数据库中,与法律相反,事务是一组操作,将数据库从一个一致的状态转换为另一个。这意味着,如果在运行事务之前所有的数据库一致性约束都得到了满足,那么之后它们仍然会保持一致性约束。
数据库是否能够进一步推动这个想法,不使用可用的SQL命令,并在每个SQL数据修改语句中强制执行约束?。SQL命令不足以让用户在每一步都保持一致性。例如,将资金从一个银行账户转到另一个银行账户的经典任务,涉及到在一个账户扣除之后但在记入另一个账户之前暂时不一致的状态。由于这个原因,事务,不是语句,被视为保持一致性的基本单位。
此时,我们可以想象在数据库上连续运行的事务,每一个都在等待对数据的独占访问。在这个有序的世界里,通过短暂的无害的不一致性,数据库将从一个一致的状态转移到另一个一致状态。
然而,几乎对于任何多用户的数据库系统来说,理想化的序列化事务都是不可行的。假设有一个航空公司的数据库锁定每个人的访问,而有一个客户在预定航班。
庆幸的是,真正序列化的事务执行通常是不必要的。许多事务与其他事务无关,因为它们更新或读取完全独立的信息。同时运行这些事务的最终结果 - 交织其命令 - 这与选择在另一个之前运行一个完整的事务是不可区分的。 在这种情况下,我们称之为可序列化。
然而,同时运行事务也会带来冲突的危险。如果没有数据库管理,事务就会干扰彼此的工作数据,并且可以观察到不正确的数据库状态。这可能导致不正确的查询结果和违反约束。
现代数据库提供了在事务中自动和有选择性地延迟或重试命令的方法,以防止干扰。该数据库提供了几种增强这种预防的方法,称为隔离级别。“更高”级别采用了更有效但更昂贵的措施来检测或解决冲突。
在不同的隔离级别上运行并发事务,允许应用程序设计人员平衡并发性和吞吐量。较低的隔离级别会增加事务并发性,但可能会出现某些类型不正确的数据库状态的事务。
选择正确的级别需要了解哪些并发交互对应用程序要求的查询构成威胁。正如我们将看到的,有时应用程序可以通过像使用显式锁这样的手工操作来获得低于正常的隔离级别。
在研究隔离级别之前,让我们在动物园停下来看看被囚禁的事务问题。文献称这些问题为“事务现象”。
事务现象动物园
对于每一种现象,我们都检查交错命令的指示模式,看看它是如何损坏的,并且注意到它可以被容忍甚至是有意地用于急需效果的时间。
我们将使用一个简短的符号来表示两个事务T1和T2的操作。下面是一些例子:
r1[x] – T1 reads value/row x
w2[y] – T2 writes value/row y
c1 – T1 commits
a2 – T2 aborts
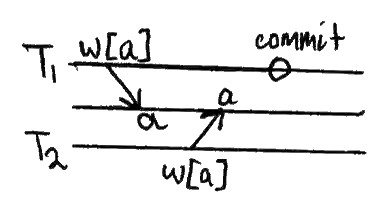
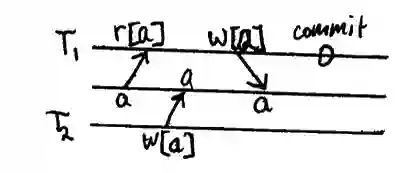
脏写
事务T1修改一个条目,T2在T1提交或回滚之前进一步修改它。
模式
如果允许脏写操作,那么数据库就不可能总对事务进行回滚。考虑:
{db in state A}
w1[x]
{db in state B}
w2[x]
{db in state C}
a1
我们应该回到A状态吗?不,因为那将会失去w2[x]。所以我们仍然在状态C,如果c2发生,我们就很好了。但是如果a2发生了什么呢?我们不能选择B或者它会撤消a1。但我们不能选C,因为那样就会抵消a2。归谬法。
因为脏写打破了事务的原子性,所以没有关系数据库允许它们在最低的隔离级别上。抽象地思考这个问题是很有启发意义的。
脏写也允许违反一致性。例如,假设约束是x=y。事务T1和T2可能会单独维护约束,但是与脏写一起运行会违反规则:
start, x = y = 0
w1[x=1] … w2[x=2] … w2[y=2] … w1[y=1]
now x = 2 ≠ 1 = y
合法的使用
没有任何脏写是有用的,即使是一条捷径。因此没有数据库允许它们。
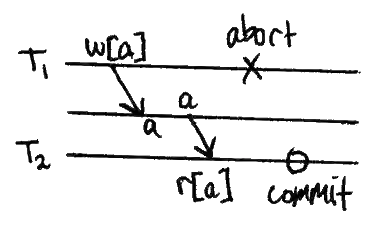
脏读
事务读取由并发未提交的事务写入的数据。(在前面的现象中,未提交的数据被称为“脏”。)
模式
危险
假设T1修改了一行,T2读取,然后T1回滚。现在T2有一个“从未存在过”的行。“基于不存在的数据来制定未来的决策可能是一个糟糕的主意。
脏读也打开了违反约束的门。假设约束x = y。假设T1给x和y增加了100,而T2使两者都加倍。任何一个事务单独保存x=y。然而,然而,w1 [x + = 100],w2 [x * = 2],w2 [y * = 2],w1 [y + = 100]的脏读违反约束条件。
最后,即使没有并发事务回滚,在另一个操作中开始的事务可能会脏读不一致的数据库状态。我们希望事务可以依赖于一个一致的状态下启动。
合法的使用
当一个事务想要监视另一个事务时,脏读是很有用的,例如在调试或进程监视期间。例如,在一个事务上的表上重复运行COUNT(*),而另一个将数据输入到它中,可以显示摄入速度/进度,但前提是允许脏读。
这种现象不会发生在对历史信息的查询中,因为历史信息早就停止了变化。没有写就没有问题。
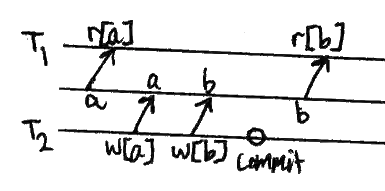
不可重复读和读偏
事务重新读取它之前读取的数据,并发现数据已被另一个事务修改(自初始读取以来已提交)。
请注意,这与其他事务已提交的脏读不同。这一现象也需要两种解读才能体现出来。
模式
包含两个值的表单称为读斜:
不可重复读取是b = a的退化情况。
危险
与脏读一样,不可重复的读取允许事务读取一个不一致的状态。它以一种稍微不同的方式发生。例如假设约束是x=y。
start, x = y = 0
r1[x] … w2[x=1] … w2[y=1] … c2 … r1[y]
从T1的角度, x = 0 ≠ 1 = y
T1从不读取任何脏数据,但是T2却在T1的读取中加入了进来,改变了值并提交了数据。注意,这一违规甚至没有涉及到T1重新读取相同的值。
读斜可以导致两个相关元素之间违反约束。例如,假设约束x+y大于0。然后:
start, x = y = 50
r1[x] … r1[y] … r2[x] … r2[y] … w1[y=-40] … w2[x=-40] … c1 … c2
T1和T2分别观察x+y=10,但它们加起来是-80.
另一个涉及两个值违反约束的情况是在一个外键和它的目标之间。读斜也会把它弄得一团糟。例如,T1可以读取表a指向表B的一行,然后T2可以从B中删除该行并提交。现在A认为这行存在于B中,但将无法读取。
如果在其他事务运行时进行数据库备份,这将是灾难性的,因为观察到的状态可能不一致且不适合恢复。
合法用途
执行不可重复的读取允许访问最新提交的数据。 对于大型(或频繁重复的)聚合报告,当它们可以容忍阅读短暂的约束违规时,这可能是有用的。
幻读
事务重新执行查询,返回满足搜索条件的一组行,并发现满足条件的行集由于最近提交的另一个事务而发生了变化。
这类似于不可重复的读取,除了它涉及到匹配谓词和不是单个项目的变化集合。
模式
危险
一种情况是当表包含表示资源分配(如员工及其工资)的行时,其中一个事务“调整器”会增加每行的资源,而另一个事务插入新行。 幻读将包括新行,导致调整程序降低预算。
举个相关的例子。有一个约束,它表示由predicate确定的一组作业任务不能超过8小时的总和。T1读取该predicate,确定总和仅为7个小时,并添加一个小时持续时间的新任务,而并发事务T2执行相同的操作。
合法的使用
页面翻页时,页面搜索结果取决于新的条目。通过插入或删除的条目可以实现在用户导航的页面上移动条目。
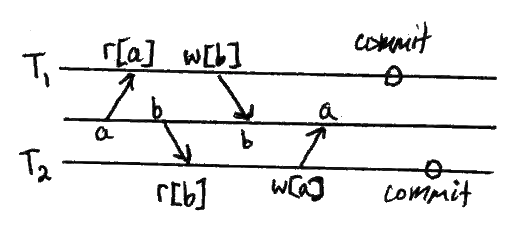
丢失更新
T1读取一个项目。 T2更新它。 T1可能会根据它所读取的内容进行更新,并提交。 T2的更新已经丢失。
模式
危险
在某些方面,这几乎不像是一种反常现象。但是它违反了数据库约束,因为最终的结果是有些工作根本没有执行。同样,它类似于应用程序盲目地更新相同的值两次。
然而,这毕竟是一个异常现象,因为任何其他事务都没有机会看到更新,而T2的提交行为就像回滚一样。在任何串行执行中,其他人都会看到这个变化,或者至少可以检查一下。
当应用程序在读取和写入之间的实际操作中执行操作时,丢失的更新会造成特别严重的影响。
例如,两个人同时尝试购买最后一张可用的机票,产生两个交易,读取剩余的一张售票。单独线程中的应用程序具有可打印票证的电子邮件队列,并将剩余票证计数更新为零。在这两个更新发生之后,剩余零票是正确的。然而,其中一个客户收到一封了包含重复机票的电子邮件。
最后,请注意,当应用程序(通常是通过ORM)更新一行中的所有列,而不仅仅是那些从读取后更改的列时,丢失更新的风险就会增加。
合法的使用
丢失的更新不会发生在原子读取更新语句中,比如更新foo SET bar=bar+1,id=123;因为在读取和增加bar之间,没有其他的事务可以滑动写入。当应用程序读取一个项,执行内部计算,然后写入一个新值时,就会出现这种现象。但我们稍后会讲到。
有时,应用程序在更新的历史记录中可能会丢失一些值。我们只想读取一个合理的最近的值,但传感器正在快速地覆盖多个线程的度量。这种情况虽然有点牵强,但可以容忍丢失的更新。
写偏
两个并发事务,每个都根据读取另一个事务正在写的数据中重叠部分的数据集来决定写什么。
模式 #
注意,如果b=a,那么我们就有一个丢失的更新。
危险
写偏创建非可序列化的事务。 这意味着没有办法一个接一个地运行事务,这将产生与病理交错相同的结果。
我所见过的最明显的例子就是黑白相间的行。从PostgreSQL wiki中逐字复制:在本例中,有一个包含“黑色”或“白色”的颜色栏。两个用户同时尝试让所有的行包含匹配的颜色值,但是他们的尝试方向相反。一种是尝试将所有的白行更新为黑色,另一种是尝试将所有的黑行更新为白色。
如果这些更新是串行的,那么所有颜色都将匹配。然而,如果没有任何数据库保护措施,交叉更新就会简单地相互反转,留下一种颜色的混合。
写偏也会打破约束。假设我们限制x+y 0。然后:
start, x = y = 100
r1[x] … r1[y] … r2[x] … r2[y] … w1[y=-y] … w2[x=-x]
now x+y = -200
两个事务都读取x和y的值为100,因此,每个事务单独取反一个值,总数仍然是非负数。 然而,取反两个值会导致x + y = -200,违反约束。 由于情绪上的重要性,这通常是根据银行帐户来设定的,只要总共持有的余额总和为非负数,账户余额就可以变为负数。
只读序列化异常
事务可能会看到更新的控制记录,以显示批处理已经完成,但是看不到批处理逻辑部分的详细记录,因为它读取了控制记录的早期版本。
尽管只有两个并发事务足以导致前面的异常,但这种情况需要三个。它在2004年的发现引起了人们的兴趣,因为它揭示了快照隔离级别的弱点(稍后讨论),这个弱点在三个不执行任何写入的唯一事务中显示。
模式
事务要做三件事:
T1:生成当前批次的报告
T2:向当前批次添加新收据
T3:使新的批次变成“当前”
危险
上面所演示的不是可序列化的。串行地运行事务具有不变的条件,即在报告事务显示特定批处理的总数之后,后续事务不能更改该总数。
数据库一致性在这种异常情况下仍然保持不变,但是报告的结果是不正确的。
合法的使用
考虑到直到2004年才有人注意到这一现象,它不像动物园里的先前现象那样容易引起问题。没有任何时间真的是可取的,但也可能不是很严重。
其他呢?
我们是否已经确定了所有可能的事务现象?这可能很难判断;ANSI sql-92标准认为他们已经涵盖了所有的内容,包括脏读、不可重复读和虚读。直到1995年,Berenson才发现了其他的串行化异常,直到2004年才注意到只读异常,只读异常才被记录下来。
第一个关系数据库使用锁定来管理并发。SQL标准以事务现象而不是锁的形式进行讨论,以允许非基于锁的标准实现。然而,标准作者未能发现其他异常现象的原因是,他们发现的那三个是“伪装的锁”。
我个人不知道是否有更多的没有被记录的事务现象,但这似乎值得怀疑。现在有大量的论文研究了可序列化性的属性,似乎理论基础已经就位。
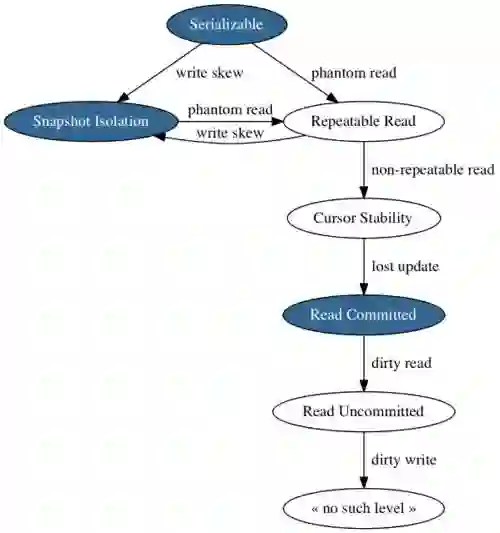
隔离级别
商业数据库提供了一系列隔离级别的并发控制,这些隔离级别实际上是控制序列化的。为了获得更高的性能,应用程序选择较低的级别。较高的性能意味着更好的事务执行率和较短的平均事务响应时间。
如果您已经理解了上一节中关于并发性问题的“zoo”,那么您就可以很好地了解如何明智地为您的应用程序选择适当的隔离级别。不用太深入了解这些级别如何防止不同现象的,下面是每个因素的预防。
在顶端,Serializable不允许任何现象。箭头后面移除了标记异常的保护。
蓝色的三个节点实际上是PostgreSQL提供的级别。令人困惑的是,SQL规范只识别了有限的级别,因此PostgreSQL将规范中的名称映射到支持的实际级别:
例如:开始隔离级别的可重复读取;现在我们处于快照隔离状态。读取提交是默认级别,所以如果您没有采取预防措施,那么您现有的应用程序可能正在经历的并发问题。
乐观VS悲观
正如前面提到的,我们不会深入讨论PostgreSQL的每个隔离级别如何防止并发现象,但是我们需要理解有两种通用的方法:乐观和悲观的并发控制。这很重要,因为每种方法都需要不同的应用程序编程技术。
悲观并发控制采用数据库行上的锁,以迫使事务等待它们的读和写。它是“悲观的”,因为如果有争用,它总是花时间去获取和释放锁。
乐观控制不需要费心去获取锁,它只是将每个事务放入数据库状态的单独快照中,并监视发生的任何争用。如果一个事务与另一个事务发生冲突,数据库就会中止该罪犯的工作,并消除其工作。当干扰很少时,这就会变得有效率。
冲突的数量取决于几个因素:
争用单个行。当试图更新同一行的事务数量增加时,冲突的可能性就会增加。
隔离级别中读取的行数,防止不可重复读取。读取的行越多,这些行通过并发事务更新的可能性就越大。
在隔离级别中使用的扫描范围的大小,可以防止幽灵读取。扫描范围越大,并发事务将引入幻象行的几率就越高。
在PostgreSQL中,两个级别使用乐观并发控制:可重复读取(实际上是快照隔离)和可序列化级别。这些级别不是魔法仙女的灰尘,你洒在不安全的应用程序来解决其问题。他们需要修改应用逻辑。
必须小心地构建一个与PostgreSQL交互具有乐观并发控制的隔离级别的应用程序。记住,在提交之前,没有什么是确定的,所有的工作都可以在一瞬间被清除。该应用程序必须准备好检测何时其查询已停止,并出现错误40001(也称为serialization_failure),然后重试该事务。在这样的事务中,应用程序不应该执行不可逆转的实际操作。应用程序必须使用悲观锁来保护这种行为,或者在成功交付结束时执行该动作。
也可以想象捕获序列化异常并在pl/pgsql函数中重试它们,但是重试不可能发生在那里。整个函数在一个事务中运行,在调用提交之前失去对执行的控制。不幸的是,当序列化错误发生时,大部分时间都是在提交的时候,而对于函数来说太晚了。
重试必须由数据库客户端进行。许多语言为任务提供了帮助程序库:
Haskell:hasql-transaction自动重试并运行在monad中,不允许不可重复的副作用
Python:psycopg2如何重试
Ruby:在sequel或transaction_retry gem中自动重试
因为重新进行事务可能是浪费,所以最好记住,在有限的时间内进行简单的事务在避免丢失的工作上是最有效的。
补偿低隔离水平
一般来说,最好使用隔离级别来防止任何可能干扰您的查询的异常。让数据库做最好的事情。但是,如果您认为在您的情况中只有某些异常会发生,那么您可以选择使用较低的隔离级别,并使用悲观锁定。
例如,我们可以通过在读取和更新之间的行上获取一个锁来防止丢失的更新。只需在select语句中添加“更新”。
BEGIN;
SELECT *
FROM player
WHERE id = 42
FOR UPDATE;
-- some kind of game logic here
UPDATE player
SET score = 853
WHERE id = 42;
COMMIT;
任何要选择更新该行的其他事务都将阻塞,直到第一个事务完成。这个选择更新技巧在可串行化的事务中甚至是有用的,以避免串行化错误,这需要重试,特别是当您想要执行non-idempotent应用程序时。
最后,你可以在较低的水平上承担计算风险。快照隔离采用的主要原因是它性能优于串行化,也避免了串行化能够避免的大多数并发性异常。如果在您的情况下不希望使用写偏移,那么您可以将这个级别转换为快照。
感谢一些在我写这篇文章时,给我提建议的人。
在#postgresql Freenode IRC频道:
Andrew Gierth(RhodiumToad)和Vik Fearing(xocolatl)
个人对话:
Marco Slot,Andres Freund,Samay Sharma和来自Citus Data的Daniel Farina
进一步阅读
Joe Celko的Smarties的SQL
ANSI SQL隔离级别的批判
PostgreSQL文档中的事务隔离
快照隔离下的只读事务异常
PostgreSQL中的可序列化快照隔离
PostgreSQL文档中的应用程序级别数据一致性检查
事务概念优点和局限性
原文:Practical Guide to SQL Transaction Isolation
作者:begriffs
翻译:lloog
长按识别二维码享更多精彩