ACL 2022 主会长文论文分类整理
本文对ACL 2022接受列表中的的602篇主会长文论文,按不同的研究主题进行分类整理(分类标准参考 ACL 官方投稿主题),以供参考。文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
导读
ACL 2022是CCF A类会议,人工智能领域自然语言处理(Natural Language Processing,NLP)方向最权威的国际会议之一。第60届计算语言学协会计划于今年5月22日-5月27日在爱尔兰都柏林召开。官方发布的接收论文列表:
目录
Adversarial attack and Robustness【对抗攻击和鲁棒性】
Dialogue and Interactive Systems【对话与交互系统】
Discourse and Pragmatics【语篇和语用学】
Data Augmentation【数据增广】
Generation【文本生成】
Information Extraction【信息抽取】
Information Retrieval and Text Mining【信息检索与文本挖掘】
Interpretability and Analysis of Models for NLP【NLP模型的可解释性与分析】
Language Model【语言模型】
Machine Learning for NLP【NLP中的机器学习】
Machine Translation and Multilinguality【机器翻译与多语】
Question Answering【问答与理解】
Resources and Evaluation【数据集与评估方法】
Sentence-level Semantics, Textual Classification, and Other Areas【句子级语义和文本关系推理】
Semantics and Syntax Parsing【语义与句法解析】
Speech and Multimodality【语音与多模态】
Summation【摘要】
Knowledge Graph【知识图谱】
Special Track【特殊任务】
Adversarial attack and Robustness【对抗攻击和鲁棒性】
Adversarial Authorship Attribution for Deobfuscation
Adversarial Soft Prompt Tuning for Cross-Domain Sentiment Analysis
Flooding-X: Improving BERT's Resistance to Adversarial Attacks via LossRestricted Fine-Tuning
From the Detection of Toxic Spans in Online Discussions to the Analysis of Toxic-to-Civil Transfer
Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost
ParaDetox: Detoxification with Parallel Data
Pass off Fish Eyes for Pearls: Attacking Model Selection of Pre-trained Models
SHIELD: Defending Textual Neural Networks against Multiple Black-Box
Adversarial Attacks with Stochastic Multi-Expert Patcher
Towards Robustness of Text-to-SQL Models Against Natural and Realistic Adversarial Table Perturbation
ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
Dialogue and Interactive Systems【对话与交互系统】
A Model-agnostic Data Manipulation Method for Persona-based Dialogue Generation
A Taxonomy of Empathetic Questions in Social Dialogs
Achieving Conversational Goals with Unsupervised Post-hoc Knowledge Injection
Achieving Reliable Human Assessment of Open-Domain Dialogue Systems
An Interpretable Neuro-Symbolic Reasoning Framework for Task-Oriented Dialogue Generation
Beyond Goldfish Memory: Long-Term Open-Domain Conversation
Beyond the Granularity: Multi-Perspective Dialogue Collaborative Selection for Dialogue State Tracking
CASPI Causal-aware Safe Policy Improvement for Task-oriented Dialogue
ChatMatch: Evaluating Chatbots by Autonomous Chat Tournaments
CICERO: A Dataset for Contextualized Commonsense Inference in Dialogues
Contextual Fine-to-Coarse Distillation for Coarse-grained Response Selection in Open-Domain Conversations
Continual Prompt Tuning for Dialog State Tracking
DEAM: Dialogue Coherence Evaluation using AMR-based Semantic Manipulations
DialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation
Dynamic Schema Graph Fusion Network for Multi-Domain Dialogue State Tracking
GlobalWoZ: Globalizing MultiWoZ to Develop Multilingual Task-Oriented Dialogue Systems
HeterMPC: A Heterogeneous Graph Neural Network for Response Generation in Multi-Party Conversations
Improving Multi-label Malevolence Detection in Dialogues through Multifaceted Label Correlation Enhancement
Interactive Word Completion for Plains Cree
Internet-Augmented Dialogue Generation
Knowledge Enhanced Reflection Generation for Counseling Dialogues
M3ED: Multi-modal Multi-scene Multi-label Emotional Dialogue Database
MISC: A Mixed Strategy-Aware Model integrating COMET for Emotional Support Conversation
Multi-Party Empathetic Dialogue Generation: A New Task for Dialog Systems
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multimodal Dialogue Response Generation
Online Semantic Parsing for Latency Reduction in Task-Oriented Dialogue
Other Roles Matter! Enhancing Role-Oriented Dialogue Summarization via Role Interactions
ProphetChat: Enhancing Dialogue Generation with Simulation of Future Conversation
QAConv: Question Answering on Informative Conversations
SaFeRDialogues: Taking Feedback Gracefully after Conversational Safety Failures
SafetyKit: First Aid for Measuring Safety in Open-domain Conversational Systems
SalesBot: Transitioning from Chit-Chat to Task-Oriented Dialogues
Should a Chatbot be Sarcastic? Understanding User Preferences Towards Sarcasm Generation
Situated Dialogue Learning through Procedural Environment Generation
Structural Characterization for Dialogue Disentanglement
The AI Doctor Is In: A Survey of Task-Oriented Dialogue Systems for Healthcare Applications
There Are a Thousand Hamlets in a Thousand People's Eyes: Enhancing Knowledge-grounded Dialogue with Personal Memory
Think Before You Speak: Explicitly Generating Implicit Commonsense Knowledge for Response Generation
UniTranSeR: A Unified Transformer Semantic Representation Framework for Multimodal Task-Oriented Dialog System
What does the sea say to the shore? A BERT based DST style approach for speaker to dialogue attribution in novels
Where to Go for the Holidays: Towards Mixed-Type Dialogs for Clarification of User Goals
Speaker Information Can Guide Models to Better Inductive Biases: A Case Study On Predicting Code-Switching
Discourse and Pragmatics【语篇和语用学】
CoCoLM: Complex Commonsense Enhanced Language Model with Discourse Relations
Context Matters: A Pragmatic Study of PLMs’ Negation Understanding
Learning to Mediate Disparities Towards Pragmatic Communication
Modeling Persuasive Discourse to Adaptively Support Students' Argumentative Writing
Neural reality of argument structure constructions
Probing for Predicate Argument Structures in Pretrained Language Models
RST Discourse Parsing with Second-Stage EDU-Level Pre-training
Data Augmentation【数据增广】
An Investigation of the (In)effectiveness of Counterfactually Augmented Data
CipherDAug: Ciphertext based Data Augmentation for Neural Machine Translation
Continual Few-shot Relation Learning via Embedding Space Regularization and Data Augmentation
Deduplicating Training Data Makes Language Models Better
FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning
Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets
Keywords and Instances: A Hierarchical Contrastive Learning Framework Unifying Hybrid Granularities for Text Generation
MELM: Data Augmentation with Masked Entity Language Modeling for LowResource NER
PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
Synthetic Question Value Estimation for Domain Adaptation of Question Answering
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data
Generation【文本生成】
A Token-level Reference-free Hallucination Detection Benchmark for Freeform Text Generation
A Well-Composed Text is Half Done! Composition Sampling for Diverse Conditional Generation
Accurate Online Posterior Alignments for Principled Lexically-Constrained Decoding
Active Evaluation: Efficient NLG Evaluation with Few Pairwise Comparisons
AraT5: Text-to-Text Transformers for Arabic Language Generation
Continual Sequence Generation with Adaptive Compositional Modules
Controllable Dictionary Example Generation: Generating Example Sentences for Specific Targeted Audiences
CTRLEval: An Unsupervised Reference-Free Metric for Evaluating Controlled Text Generation
Few-shot Controllable Style Transfer for Low-Resource Multilingual Settings
Fine-Grained Controllable Text Generation Using Non-Residual Prompting
Flexible Generation from Fragmentary Linguistic Input
FrugalScore: Learning Cheaper, Lighter and Faster Evaluation Metrics for Automatic Text Generation
Generating Scientific Definitions with Controllable Complexity
Hierarchical Sketch Induction for Paraphrase Generation
How Do Seq2Seq Models Perform on End-to-End Data-to-Text Generation?
Hybrid Semantics for Goal-Directed Natural Language Generation
Improving Compositional Generalization with Self-Training for Data-to-Text Generation
Improving Personalized Explanation Generation through Visualization
Inducing Positive Perspectives with Text Reframing
latent-GLAT: Glancing at Latent Variables for Parallel Text Generation
Lexical Knowledge Internalization for Neural Dialog Generation
Mix and Match: Learning-free Controllable Text Generationusing Energy Language Models
Multitasking Framework for Unsupervised Simple Definition Generation
Neural Pipeline for Zero-Shot Data-to-Text Generation
Non-neural Models Matter: a Re-evaluation of Neural Referring Expression Generation Systems
ODE Transformer: An Ordinary Differential Equation-Inspired Model for Sequence Generation
Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages
PLANET: Dynamic Content Planning in Autoregressive Transformers for Long-form Text Generation
Predicate-Argument Based Bi-Encoder for Paraphrase Identification
Principled Paraphrase Generation with Parallel Corpora
Quality Controlled Paraphrase Generation
Rare Tokens Degenerate All Tokens: Improving Neural Text Generation via Adaptive Gradient Gating for Rare Token Embeddings
RoMe: A Robust Metric for Evaluating Natural Language Generation
Semi-Supervised Formality Style Transfer with Consistency Training
So Different Yet So Alike! Constrained Unsupervised Text Style Transfer
Spurious Correlations in Reference-Free Evaluation of Text Generation
Tailor: Generating and Perturbing Text with Semantic Controls
Towards Better Characterization of Paraphrases
Uncertainty Determines the Adequacy of the Mode and the Tractability of Decoding in Sequence-to-Sequence Models
An Imitation Learning Curriculum for Text Editing with Non-Autoregressive Models
Understanding Iterative Revision from Human-Written Text
Information Extraction【信息抽取】
Alignment-Augmented Consistent Translation for Multilingual Open Information Extraction
Automatic Error Analysis for Document-level Information Extraction
BenchIE: A Framework for Multi-Faceted Fact-Based Open Information Extraction Evaluation
Dynamic Global Memory for Document-level Argument Extraction
Dynamic Prefix-Tuning for Generative Template-based Event Extraction
FaVIQ: FAct Verification from Information-seeking Questions
FormNet: Structural Encoding beyond Sequential Modeling in Form Document Information Extraction
Generating Scientific Claims for Zero-Shot Scientific Fact Checking
JointCL: A Joint Contrastive Learning Framework for Zero-Shot Stance Detection
KNN-Contrastive Learning for Out-of-Domain Intent Classification
Legal Judgment Prediction via Event Extraction with Constraints
MILIE: Modular & Iterative Multilingual Open Information Extraction
Modeling U.S. State-Level Policies by Extracting Winners and Losers from Legislative Texts
OIE@OIA: an Adaptable and Efficient Open Information Extraction Framework
Packed Levitated Marker for Entity and Relation Extraction
Pre-training to Match for Unified Low-shot Relation Extraction
Prompt for Extraction? PAIE: Prompting Argument Interaction for Event Argument Extraction
Retrieval-guided Counterfactual Generation for QA
Right for the Right Reason: Evidence Extraction for Trustworthy Tabular Reasoning
Saliency as Evidence: Event Detection with Trigger Saliency Attribution
Text-to-Table: A New Way of Information Extraction
Toward Interpretable Semantic Textual Similarity via Optimal Transportbased Contrastive Sentence Learning
Transkimmer: Transformer Learns to Layer-wise Skim
Unified Structure Generation for Universal Information Extraction
Information Retrieval and Text Mining【信息检索与文本挖掘】
Automatic Identification and Classification of Bragging in Social Media
Bilingual alignment transfers to multilingual alignment for unsupervised parallel text mining
Can Unsupervised Knowledge Transfer from Social Discussions Help Argument Mining?
ClarET: Pre-training a Correlation-Aware Context-To-Event Transformer for Event-Centric Generation and Classification
Cross-Lingual Phrase Retrieval
Learning to Rank Visual Stories From Human Ranking Data
Multi-View Document Representation Learning for Open-Domain Dense Retrieval
New Intent Discovery with Pre-training and Contrastive Learning
Pre-training and Fine-tuning Neural Topic Model: A Simple yet Effective Approach to Incorporating External Knowledge
RELiC: Retrieving Evidence for Literary Claims
Retrieval-guided Counterfactual Generation for QA
SDR: Efficient Neural Re-ranking using Succinct Document Representation
Sentence-aware Contrastive Learning for Open-Domain Passage Retrieval
Show Me More Details: Discovering Hierarchies of Procedures from Semistructured Web Data
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data
UCTopic: Unsupervised Contrastive Learning for Phrase Representations and Topic Mining
Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval
Zoom Out and Observe: News Environment Perception for Fake News Detection
Interpretability and Analysis of Models for NLP【NLP模型的可解释性与分析】
A Closer Look at How Fine-tuning Changes BERT
A Comparative Study of Faithfulness Metrics for Model Interpretability Methods
A Comparison of Strategies for Source-Free Domain Adaptation
Active Evaluation: Efficient NLG Evaluation with Few Pairwise Comparisons
Adaptive Testing and Debugging of NLP Models
An Empirical Study of Memorization in NLP
An Empirical Study on Explanations in Out-of-Domain Settings
An Empirical Survey of the Effectiveness of Debiasing Techniques for Pretrained Language Models
An Investigation of the (In)effectiveness of Counterfactually Augmented Data
Can Explanations Be Useful for Calibrating Black Box Models?
Can Pre-trained Language Models Interpret Similes as Smart as Human?
Can Prompt Probe Pretrained Language Models? Understanding the Invisible Risks from a Causal View
Can Synthetic Translations Improve Bitext Quality?
Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation
Causal Probing for Grammatical Number: From Encoding to Usage
Coherence boosting: When your pretrained language model is not paying enough attention
Context Matters: A Pragmatic Study of PLMs’ Negation Understanding
Cross-Lingual Ability of Multilingual Masked Language Models: A Study of Language Structure
Dataset Geography: Mapping Language Data to Language Users
Do Transformer Models Show Similar Attention Patterns to Task-Specific Human Gaze?
Does Recommend-Revise Produce Reliable Annotations? An Analysis on Missing Instances in DocRED
Explanation Graph Generation via Pre-trained Language Models: An Empirical Study with Contrastive Learning
Finding Structural Knowledge in Multimodal-BERT
Generating Biographies on Wikipedia: The Impact of Gender Bias on the Retrieval-Based Generation of Women Biographies
GPT-D: Inducing Dementia-related Linguistic Anomalies by Deliberate Degradation of Artificial Neural Language Models
How can NLP Help Revitalize Endangered Languages? A Case Study and Roadmap for the Cherokee Language
ILDAE: Instance-Level Difficulty Analysis of Evaluation Data
IMPLI: Investigating NLI Models' Performance on Figurative Language
Improving Generalizability in Implicitly Abusive Language Detection with Concept Activation Vectors
Interpretability for Language Learners Using Example-Based Grammatical Error Correction
Interpreting Character Embeddings With Perceptual Representations: The Case of Shape, Sound, and Color
Investigating Failures of Automatic Translation in the Case of Unambiguous Gender
Investigating Non-local Features for Neural Constituency Parsing
Is Attention Explanation? An Introduction to the Debate
Life after BERT: What do Other Muppets Understand about Language?
Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice
Measuring Fairness of Text Classifiers via Prediction Sensitivity
Memorisation versus Generalisation in Pre-trained Language Models
Metaphors in Pre-Trained Language Models: Probing and Generalization Across Datasets and Languages
On the Sensitivity and Stability of Model Interpretations in NLP
Pretraining with Artificial Language: Studying Transferable Knowledge in Language Models
Probing as Quantifying Inductive Bias
Probing Simile Knowledge from Pre-trained Language Models
ProtoTEx: Explaining Model Decisions with Prototype Tensors
Reports of personal experiences and stories in argumentation: datasets and analysis
Rewire-then-Probe: A Contrastive Recipe for Probing Biomedical Knowledge of Pre-trained Language Models
Sense Embeddings are also Biased -- Evaluating Social Biases in Static and Contextualised Sense Embeddings
Signal in Noise: Exploring Meaning Encoded in Random Character Sequences with Character-Aware Language Models
Systematic Inequalities in Language Technology Performance across the World’s Languages
That Is a Suspicious Reaction!: Interpreting Logits Variation to Detect NLP Adversarial Attacks
The Dangers of Underclaiming: Reasons for Caution When Reporting How NLP Systems Fail
The Moral Debater: A Study on the Computational Generation of Morally Framed Arguments
The Paradox of the Compositionality of Natural Language: A Neural Machine Translation Case Study
Things not Written in Text: Exploring Spatial Commonsense from Visual Signals
Toward Interpretable Semantic Textual Similarity via Optimal Transportbased Contrastive Sentence Learning
Transformers in the loop: Polarity in neural models of language
Upstream Mitigation Is Not All You Need: Testing the Bias Transfer Hypothesis in Pre-Trained Language Models
When did you become so smart, oh wise one?! Sarcasm Explanation in Multi-modal Multi-party Dialogues
Where to Go for the Holidays: Towards Mixed-Type Dialogs for Clarification of User Goals
Which side are you on? Insider-Outsider classification in conspiracy theoretic social media
Word Order Does Matter and Shuffled Language Models Know It
Language Model【语言模型】
模型结构
ABC: Attention with Bounded-memory Control
AdapLeR: Speeding up Inference by Adaptive Length Reduction
AlephBERT: Language Model Pre-training and Evaluation from Sub-Word to Sentence Level
Better Language Model with Hypernym Class Prediction
CAMERO: Consistency Regularized Ensemble of Perturbed Language Models with Weight Sharing
ClarET: Pre-training a Correlation-Aware Context-To-Event Transformer for Event-Centric Generation and Classification
ClusterFormer: Neural Clustering Attention for Efficient and Effective Transformer
Dependency-based Mixture Language Models
E-LANG: Energy-Based Joint Inferencing of Super and Swift Language Models
EPT-X: An Expression-Pointer Transformer model that generates eXplanations for numbers
Exploring and Adapting Chinese GPT to Pinyin Input Method
Few-Shot Tabular Data Enrichment Using Fine-Tuned Transformer Architectures
Fine- and Coarse-Granularity Hybrid Self-Attention for Efficient BERT
FORTAP: Using Formulas for Numerical-Reasoning-Aware Table Pretraining
Fully Hyperbolic Neural Networks
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
infty-former: Infinite Memory Transformer
KinyaBERT: a Morphology-aware Kinyarwanda Language Model
Knowledge Neurons in Pretrained Transformers
LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding
Long-range Sequence Modeling with Predictable Sparse Attention
Low-Rank Softmax Can Have Unargmaxable Classes in Theory but Rarely in Practice
Making Transformers Solve Compositional Tasks
Pyramid-BERT: Reducing Complexity via Successive Core-set based Token Selection
SkipBERT: Efficient Inference with Shallow Layer Skipping
Sparsifying Transformer Models with Trainable Representation Pooling
StableMoE: Stable Routing Strategy for Mixture of Experts
TableFormer: Robust Transformer Modeling for Table-Text Encoding
Transkimmer: Transformer Learns to Layer-wise Skim
训练策略
The Trade-offs of Domain Adaptation for Neural Language Models
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
Feeding What You Need by Understanding What You Learned
Distinguishing Non-natural from Natural Adversarial Samples for More Robust Pre-trained Language Model
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data
ELLE: Efficient Lifelong Pre-training for Emerging Data
LinkBERT: Pretraining Language Models with Document Links
CoCoLM: Complex Commonsense Enhanced Language Model with Discourse Relations
Coherence boosting: When your pretrained language model is not paying enough attention
Feeding What You Need by Understanding What You Learned
LinkBERT: Pretraining Language Models with Document Links
MarkupLM: Pre-training of Text and Markup Language for Visually Rich Document Understanding
Sparse Progressive Distillation: Resolving Overfitting under Pretrain-andFinetune Paradigm
Token Dropping for Efficient BERT Pretraining
XLM-E: Cross-lingual Language Model Pre-training via ELECTRA
模型压缩
Compression of Generative Pre-trained Language Models via Quantization
BERT Learns to Teach: Knowledge Distillation with Meta Learning
Multi-Granularity Structural Knowledge Distillation for Language Model Compression
Structured Pruning Learns Compact and Accurate Models
微调策略
A Closer Look at How Fine-tuning Changes BERT
A Good Prompt Is Worth Millions of Parameters: Low-resource Promptbased Learning for Vision-Language Models
Adversarial Soft Prompt Tuning for Cross-Domain Sentiment Analysis
An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
Are Prompt-based Models Clueless?
bert2BERT: Towards Reusable Pretrained Language Models
CogTaskonomy: Cognitively Inspired Task Taxonomy Is Beneficial to Transfer Learning in NLP
Composable Sparse Fine-Tuning for Cross-Lingual Transfer
ConTinTin: Continual Learning from Task Instructions
Cross-Task Generalization via Natural Language Crowdsourcing Instructions
Efficient Unsupervised Sentence Compression by Fine-tuning Transformers with Reinforcement Learning
Enhancing Cross-lingual Natural Language Inference by Prompt-learning from Cross-lingual Templates
Fantastically Ordered Prompts and Where to Find Them: Overcoming FewShot Prompt Order Sensitivity
Few-Shot Learning with Siamese Networks and Label Tuning
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
On Continual Model Refinement in Out-of-Distribution Data Streams
Overcoming Catastrophic Forgetting beyond Continual Learning: Balanced Training for Neural Machine Translation
PPT: Pre-trained Prompt Tuning for Few-shot Learning
Prompt-Based Rule Discovery and Boosting for Interactive WeaklySupervised Learning
Prompt for Extraction? PAIE: Prompting Argument Interaction for Event Argument Extraction
Prompt-free and Efficient Few-shot Learning with Language Models
Prototypical Verbalizer for Prompt-based Few-shot Tuning
Turning Tables: Generating Examples from Semi-structured Tables for Endowing Language Models with Reasoning Skills
UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
表示学习
A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-wise Perspective in Angular Space
Auto-Debias: Debiasing Masked Language Models with Automated Biased Prompts
Compact Token Representations with Contextual Quantization for Efficient Document Re-ranking
Contextual Representation Learning beyond Masked Language Modeling
Contrastive Visual Semantic Pretraining Magnifies the Semantics of Natural Language Representations
Cross-Lingual Contrastive Learning for Fine-Grained Entity Typing for LowResource Languages
Cross-Modal Discrete Representation Learning
Debiased Contrastive Learning of Unsupervised Sentence Representations
Enhancing Chinese Pre-trained Language Model via Heterogeneous Linguistics Graph
GL-CLeF: A Global--Local Contrastive Learning Framework for Crosslingual Spoken Language Understanding
Improving Event Representation via Simultaneous Weakly Supervised Contrastive Learning and Clustering
Just Rank: Rethinking Evaluation with Word and Sentence Similarities
Language-agnostic BERT Sentence Embedding
Learning Disentangled Representations of Negation and Uncertainty
Learning Disentangled Textual Representations via Statistical Measures of Similarity
Multilingual Molecular Representation Learning via Contrastive Pre-training
Nibbling at the Hard Core of Word Sense Disambiguation
Noisy Channel Language Model Prompting for Few-Shot Text Classification
Rare and Zero-shot Word Sense Disambiguation using Z-Reweighting
Sentence-level Privacy for Document Embeddings
Softmax Bottleneck Makes Language Models Unable to Represent Multimode Word Distributions
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
Tackling Fake News Detection by Continually Improving Social Context Representations using Graph Neural Networks
The Grammar-Learning Trajectories of Neural Language Models
Using Context-to-Vector with Graph Retrofitting to Improve Word Embeddings
Machine Learning for NLP【NLP中的机器学习】
A Rationale-Centric Framework for Human-in-the-loop Machine Learning
Bias Mitigation in Machine Translation Quality Estimation
Disentangled Sequence to Sequence Learning for Compositional Generalization
DoCoGen: Domain Counterfactual Generation for Low Resource Domain Adaptation
Domain Adaptation in Multilingual and Multi-Domain Monolingual Settings for Complex Word Identification
Domain Knowledge Transferring for Pre-trained Language Model via Calibrated Activation Boundary Distillation
Learning Functional Distributional Semantics with Visual Data
Leveraging Relaxed Equilibrium by Lazy Transition for Sequence Modeling
Local Languages, Third Spaces, and other High-Resource Scenarios
Meta-learning via Language Model In-context Tuning
MPII: Multi-Level Mutual Promotion for Inference and Interpretation
On the Calibration of Pre-trained Language Models using Mixup Guided by Area Under the Margin and Saliency
Overcoming a Theoretical Limitation of Self-Attention
Rethinking Negative Sampling for Handling Missing Entity Annotations
Rethinking Self-Supervision Objectives for Generalizable Coherence Modeling
Robust Lottery Tickets for Pre-trained Language Models
Sharpness-Aware Minimization Improves Language Model Generalization
Skill Induction and Planning with Latent Language
The Trade-offs of Domain Adaptation for Neural Language Models
Distributionally Robust Finetuning BERT for Covariate Drift in Spoken Language Understanding
Learning to Imagine: Integrating Counterfactual Thinking in Neural Discrete Reasoning
Machine Translation and Multilinguality【机器翻译与多语】
翻译
Alignment-Augmented Consistent Translation for Multilingual Open Information Extraction
Alternative Input Signals Ease Transfer in Multilingual Machine Translation
BiTIIMT: A Bilingual Text-infilling Method for Interactive Machine Translation
Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation
Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation
CipherDAug: Ciphertext based Data Augmentation for Neural Machine Translation
Conditional Bilingual Mutual Information Based Adaptive Training for Neural Machine Translation
Confidence Based Bidirectional Global Context Aware Training Framework for Neural Machine Translation
DEEP: DEnoising Entity Pre-training for Neural Machine Translation
DiBiMT: A Novel Benchmark for Measuring Word Sense Disambiguation Biases in Machine Translation
Divide and Rule: Effective Pre-Training for Context-Aware Multi-Encoder Translation Models
EAG: Extract and Generate Multi-way Aligned Corpus for Complete Multilingual Neural Machine Translation
Efficient Cluster-Based k-Nearest-Neighbor Machine Translation
Flow-Adapter Architecture for Unsupervised Machine Translation
From Simultaneous to Streaming Machine Translation by Leveraging Streaming History
Improving Word Translation via Two-Stage Contrastive Learning
Integrating Vectorized Lexical Constraints for Neural Machine Translation
Investigating Failures of Automatic Translation in the Case of Unambiguous Gender
Learning Adaptive Segmentation Policy for End-to-End Simultaneous Translation
Learning Confidence for Transformer-based Neural Machine Translation
Learning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation
Learning When to Translate for Streaming Speech
Measuring and Mitigating Name Biases in Neural Machine Translation
Modeling Dual Read/Write Paths for Simultaneous Machine Translation
MSP: Multi-Stage Prompting for Making Pre-trained Language Models Better Translators
Multilingual Document-Level Translation Enables Zero-Shot Transfer From Sentences to Documents
Multilingual Mix: Example Interpolation Improves Multilingual Neural Machine Translation
Neural Machine Translation with Phrase-Level Universal Visual Representations
On Vision Features in Multimodal Machine Translation
Overcoming Catastrophic Forgetting beyond Continual Learning: Balanced Training for Neural Machine Translation
Prediction Difference Regularization against Perturbation for Neural Machine Translation
Redistributing Low-Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
Reducing Position Bias in Simultaneous Machine Translation with Length Aware Framework
Scheduled Multi-task Learning for Neural Chat Translation
The Paradox of the Compositionality of Natural Language: A Neural Machine Translation Case Study
Towards Making the Most of Cross-Lingual Transfer for Zero-Shot Neural Machine Translation
Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
Unified Speech-Text Pre-training for Speech Translation and Recognition
UniTE: Unified Translation Evaluation
Universal Conditional Masked Language Pre-training for Neural Machine Translation
多语
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Cross-Lingual Ability of Multilingual Masked Language Models: A Study of Language Structure
Domain Adaptation in Multilingual and Multi-Domain Monolingual Settings for Complex Word Identification
Expanding Pretrained Models to Thousands More Languages via Lexiconbased Adaptation
Match the Script, Adapt if Multilingual: Analyzing the Effect of Multilingual Pretraining on Cross-lingual Transferability
mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models
Multi Task Learning For Zero Shot Performance Prediction of Multilingual Models
Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction
Multilingual Knowledge Graph Completion with Self-Supervised Adaptive Graph Alignment
Multilingual Molecular Representation Learning via Contrastive Pre-training
Multilingual unsupervised sequence segmentation transfers to extremely low-resource languages
One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia
Prix-LM: Pretraining for Multilingual Knowledge Base Construction
Probing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency
Question Answering【问答与理解】
阅读理解
AdaLoGN: Adaptive Logic Graph Network for Reasoning-Based Machine Reading Comprehension
Deep Inductive Logic Reasoning for Multi-Hop Reading Comprehension
Improving Machine Reading Comprehension with Contextualized Commonsense Knowledge
Learning Disentangled Semantic Representations for Zero-Shot CrossLingual Transfer in Multilingual Machine Reading Comprehension
Lite Unified Modeling for Discriminative Reading Comprehension
Modeling Temporal-Modal Entity Graph for Procedural Multimodal Machine Comprehension
What Makes Reading Comprehension Questions Difficult?
MultiHiertt: Numerical Reasoning over Multi Hierarchical Tabular and Textual Data
问答
Answer-level Calibration for Free-form Multiple Choice Question Answering
Answering Open-Domain Multi-Answer Questions via a Recall-then-Verify Framework
CQG: A Simple and Effective Controlled Generation Framework for Multihop Question Generation
Ditch the Gold Standard: Re-evaluating Conversational Question Answering
Generated Knowledge Prompting for Commonsense Reasoning
How Do We Answer Complex Questions: Discourse Structure of Long-form Answers
Hypergraph Transformer: Weakly-Supervised Multi-hop Reasoning for Knowledge-based Visual Question Answering
Hyperlink-induced Pre-training for Passage Retrieval in Open-domain Question Answering
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
It is AI’s Turn to Ask Humans a Question: Question-Answer Pair Generation for Children's Story Books
KaFSP: Knowledge-Aware Fuzzy Semantic Parsing for Conversational Question Answering over a Large-Scale Knowledge Base
KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
MMCoQA: Conversational Question Answering over Text, Tables, and Images
Modeling Multi-hop Question Answering as Single Sequence Prediction
On the Robustness of Question Rewriting Systems to Questions of Varying Hardness
Open Domain Question Answering with A Unified Knowledge Interface
Program Transfer for Answering Complex Questions over Knowledge Bases
Retrieval-guided Counterfactual Generation for QA
RNG-KBQA: Generation Augmented Iterative Ranking for Knowledge Base Question Answering
Sequence-to-Sequence Knowledge Graph Completion and Question Answering
Simulating Bandit Learning from User Feedback for Extractive Question Answering
Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering
Synthetic Question Value Estimation for Domain Adaptation of Question Answering
Your Answer is Incorrect... Would you like to know why? Introducing a Bilingual Short Answer Feedback Dataset
Resources and Evaluation【数据集与评估方法】
数据集
A Statutory Article Retrieval Dataset in French
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Chart-to-Text: A Large-Scale Benchmark for Chart Summarization
CICERO: A Dataset for Contextualized Commonsense Inference in Dialogues
CLUES: A Benchmark for Learning Classifiers using Natural Language Explanations
ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers
Cree Corpus: A Collection of nêhiyawêwin Resources
Detecting Unassimilated Borrowings in Spanish: An Annotated Corpus and Approaches to Modeling
DialFact: A Benchmark for Fact-Checking in Dialogue
DiBiMT: A Novel Benchmark for Measuring Word Sense Disambiguation Biases in Machine Translation
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
e-CARE: a New Dataset for Exploring Explainable Causal Reasoning
EntSUM: A Data Set for Entity-Centric Extractive Summarization
ePiC: Employing Proverbs in Context as a Benchmark for Abstract Language Understanding
FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing
Fantastic Questions and Where to Find Them: FairytaleQA -- An Authentic Dataset for Narrative Comprehension
Few-Shot Tabular Data Enrichment Using Fine-Tuned Transformer Architectures
French CrowS-Pairs: Extending a challenge dataset for measuring social bias in masked language models to a language other than English
From text to talk: Harnessing conversational corpora for humane and diversity-aware language technology
HiTab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation
IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks
Image Retrieval from Contextual Descriptions
KQA Pro: A Dataset with Explicit Compositional Programs for Complex Question Answering over Knowledge Base
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
M3ED: Multi-modal Multi-scene Multi-label Emotional Dialogue Database
MSCTD: A Multimodal Sentiment Chat Translation Dataset
NumGLUE: A Suite of Fundamental yet Challenging Mathematical Reasoning Tasks
QuoteR: A Benchmark of Quote Recommendation for Writing
Reports of personal experiences and stories in argumentation: datasets and analysis
RNSum: A Large-Scale Dataset for Automatic Release Note Generation via Commit Logs Summarization
SciNLI: A Corpus for Natural Language Inference on Scientific Text
SummScreen: A Dataset for Abstractive Screenplay Summarization
SUPERB-SG: Enhanced Speech processing Universal PERformance Benchmark for Semantic and Generative Capabilities
Textomics: A Dataset for Genomics Data Summary Generation
The Moral Integrity Corpus: A Benchmark for Ethical Dialogue Systems
ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena
WatClaimCheck: A new Dataset for Claim Entailment and Inference
Your Answer is Incorrect... Would you like to know why? Introducing a Bilingual Short Answer Feedback Dataset
评估
Active Evaluation: Efficient NLG Evaluation with Few Pairwise Comparisons
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
BenchIE: A Framework for Multi-Faceted Fact-Based Open Information Extraction Evaluation
Bias Mitigation in Machine Translation Quality Estimation
CARETS: A Consistency And Robustness Evaluative Test Suite for VQA
ChatMatch: Evaluating Chatbots by Autonomous Chat Tournaments
CTRLEval: An Unsupervised Reference-Free Metric for Evaluating Controlled Text Generation
DEAM: Dialogue Coherence Evaluation using AMR-based Semantic Manipulations
Evaluating Factuality in Text Simplification
FIBER: Fill-in-the-Blanks as a Challenging Video Understanding Evaluation Framework
FrugalScore: Learning Cheaper, Lighter and Faster Evaluation Metrics for Automatic Text Generation
Generative Pretraining for Paraphrase Evaluation
Human Evaluation and Correlation with Automatic Metrics in Consultation Note Generation
Is GPT-3 Text Indistinguishable from Human Text? Scarecrow: A Framework for Scrutinizing Machine Text
Just Rank: Rethinking Evaluation with Word and Sentence Similarities
Logic Traps in Evaluating Attribution Scores
Quantified Reproducibility Assessment of NLP Results
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
RoMe: A Robust Metric for Evaluating Natural Language Generation
SRL4E – Semantic Role Labeling for Emotions: A Unified Evaluation Framework
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Under the Morphosyntactic Lens: A Multifaceted Evaluation of Gender Bias in Speech Translation
UniTE: Unified Translation Evaluation
Sentence-level Semantics, Textual Classification, and Other Areas【句子级语义和文本关系推理】
Incorporating Hierarchy into Text Encoder: a Contrastive Learning Approach for Hierarchical Text Classification
Adversarial Soft Prompt Tuning for Cross-Domain Sentiment Analysis
Bag-of-Words vs. Graph vs. Sequence in Text Classification: Questioning the Necessity of Text-Graphs and the Surprising Strength of a Wide MLP
Cluster & Tune: Boost Cold Start Performance in Text Classification
Discrete Opinion Tree Induction for Aspect-based Sentiment Analysis
Early Stopping Based on Unlabeled Samples in Text Classification
Effective Token Graph Modeling using a Novel Labeling Strategy for Structured Sentiment Analysis
Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction
Entailment Graph Learning with Textual Entailment and Soft Transitivity
Evaluating Extreme Hierarchical Multi-label Classification
FaiRR: Faithful and Robust Deductive Reasoning over Natural Language
Improving Meta-learning for Low-resource Text Classification and Generation via Memory Imitation
Incorporating Hierarchy into Text Encoder: a Contrastive Learning Approach for Hierarchical Text Classification
KenMeSH: Knowledge-enhanced End-to-end Biomedical Text Labelling
Label Semantic Aware Pre-training for Few-shot Text Classification
Learn to Adapt for Generalized Zero-Shot Text Classification
Leveraging Task Transferability to Meta-learning for Clinical Section Classification with Limited Data
Measuring Fairness of Text Classifiers via Prediction Sensitivity
On the Robustness of Offensive Language Classifiers
Toward Interpretable Semantic Textual Similarity via Optimal Transportbased Contrastive Sentence Learning
Towards Comprehensive Patent Approval Predictions:Beyond Traditional Document Classification
Semantics and Syntax Parsing【语义与句法解析】
语义解析
LAGr: Label Aligned Graphs for Better Systematic Generalization in Semantic Parsing
Fully-Semantic Parsing and Generation: the BabelNet Meaning Representation
Graph Pre-training for AMR Parsing and Generation
LAGr: Label Aligned Graphs for Better Systematic Generalization in Semantic Parsing
Learned Incremental Representations for Parsing
Learning to Generate Programs for Table Fact Verification via StructureAware Semantic Parsing
Modeling Syntactic-Semantic Dependency Correlations in Semantic Role Labeling Using Mixture Models
On The Ingredients of an Effective Zero-shot Semantic Parser
Semantic Composition with PSHRG for Derivation Tree Reconstruction from Graph-Based Meaning Representations
Towards Robustness of Text-to-SQL Models Against Natural and Realistic Adversarial Table Perturbation
Word2Box: Capturing Set-Theoretic Semantics of Words using Box Embedding
句法分析
Investigating Non-local Features for Neural Constituency Parsing
Bottom-Up Constituency Parsing and Nested Named Entity Recognition with Pointer Networks
Compositional Generalization in Dependency Parsing
Dependency Parsing as MRC-based Span-Span Prediction
Headed-Span-Based Projective Dependency Parsing
Investigating Non-local Features for Neural Constituency Parsing
Meta-Learning for Fast Cross-Lingual Adaptation in Dependency Parsing
Phrase-aware Unsupervised Constituency Parsing
Probing for Labeled Dependency Trees
Semi-supervised Domain Adaptation for Dependency Parsing with Dynamic Matching Network
Substructure Distribution Projection for Zero-Shot Cross-Lingual Dependency Parsing
TwittIrish: A Universal Dependencies Treebank of Tweets in Modern Irish
Unsupervised Dependency Graph Network
命名实体识别
CONTaiNER: Few-Shot Named Entity Recognition via Contrastive Learning
De-Bias for Generative Extraction in Unified NER Task
Distantly Supervised Named Entity Recognition via Confidence-Based Multi-Class Positive and Unlabeled Learning
Few-Shot Class-Incremental Learning for Named Entity Recognition
Few-shot Named Entity Recognition with Self-describing Networks
Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER
MELM: Data Augmentation with Masked Entity Language Modeling for LowResource NER
MINER: Improving Out-of-Vocabulary Named Entity Recognition from an Information Theoretic Perspective
Nested Named Entity Recognition as Latent Lexicalized Constituency Parsing
Nested Named Entity Recognition with Span-level Graphs
Parallel Instance Query Network for Named Entity Recognition
指代消解
Adapting Coreference Resolution Models through Active Learning
Constrained Multi-Task Learning for Bridging Resolution
实体识别,对齐与消歧
ExtEnD: Extractive Entity Disambiguation
FiNER: Financial Numeric Entity Recognition for XBRL Tagging
Learning from Sibling Mentions with Scalable Graph Inference in FineGrained Entity Typing
An Effective and Efficient Entity Alignment Decoding Algorithm via Third-Order Tensor Isomorphism
Divide and Denoise: Learning from Noisy Labels in Fine-Grained Entity Typing with Cluster-Wise Loss Correction
其它
A Neural Network Architecture for Program Understanding Inspired by Human Behaviors
Bridging the Generalization Gap in Text-to-SQL Parsing with Schema Expansion
Fair and Argumentative Language Modeling for Computational Argumentation
LexSubCon: Integrating Knowledge from Lexical Resources into Contextual Embeddings for Lexical Substitution
Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages
Variational Graph Autoencoding as Cheap Supervision for AMR Coreference Resolution
Speech and Multimodality【语音与多模态】
多模态
Analyzing Generalization of Vision and Language Navigation to Unseen Outdoor Areas
CARETS: A Consistency And Robustness Evaluative Test Suite for VQA
CLIP Models are Few-Shot Learners: Empirical Studies on VQA and Visual Entailment
Contrastive Visual Semantic Pretraining Magnifies the Semantics of Natural Language Representations
End-to-End Modeling via Information Tree for One-Shot Natural Language Spatial Video Grounding
Guided Attention Multimodal Multitask Financial Forecasting with InterCompany Relationships and Global and Local News
Image Retrieval from Contextual Descriptions
Letters From the Past: Modeling Historical Sound Change Through Diachronic Character Embeddings
Leveraging Visual Knowledge in Language Tasks: An Empirical Study on Intermediate Pre-training for Cross-Modal Knowledge Transfer
Modeling Temporal-Modal Entity Graph for Procedural Multimodal Machine Comprehension
Multi-Modal Sarcasm Detection via Cross-Modal Graph Convolutional Network
Multimodal Dialogue Response Generation
Multimodal fusion via cortical network inspired losses
Multimodal Sarcasm Target Identification in Tweets
On Vision Features in Multimodal Machine Translation
OpenHands: Making Sign Language Recognition Accessible with Posebased Pretrained Models across Languages
Phone-ing it in: Towards Flexible Multi-Modal Language Model Training by Phonetic Representations of Data
Premise-based Multimodal Reasoning: Conditional Inference on Joint Textual and Visual Clues
RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining
There’s a Time and Place for Reasoning Beyond the Image
Things not Written in Text: Exploring Spatial Commonsense from Visual Signals
Understanding Multimodal Procedural Knowledge by Sequencing Multimodal Instructional Manuals
UniTranSeR: A Unified Transformer Semantic Representation Framework for Multimodal Task-Oriented Dialog System
Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions
Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
Visual-Language Navigation Pretraining via Prompt-based Environmental Self-exploration
WikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types
语音
Cross-Utterance Conditioned VAE for Non-Autoregressive Text-to-Speech
Decoding Part-of-Speech from Human EEG Signals
Direct Speech-to-Speech Translation With Discrete Units
Language-Agnostic Meta-Learning for Low-Resource Text-to-Speech with Articulatory Features
Leveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition
Requirements and Motivations of Low-Resource Speech Synthesis for Language Revitalization
Revisiting Over-Smoothness in Text to Speech
Self-supervised Semantic-driven Phoneme Discovery for Zero-resource Speech Recognition
SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing
STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation
Text-Free Prosody-Aware Generative Spoken Language Modeling
Do self-supervised speech models develop human-like perception biases?
Summation【摘要】
A Multi-Document Coverage Reward for RELAXed Multi-Document Summarization
A Variational Hierarchical Model for Neural Cross-Lingual Summarization
ASPECTNEWS: Aspect-Oriented Summarization of News Documents
Attention Temperature Matters in Abstractive Summarization Distillation
BRIO: Bringing Order to Abstractive Summarization
Chart-to-Text: A Large-Scale Benchmark for Chart Summarization
Differentiable Multi-Agent Actor-Critic for Multi-Step Radiology Report Summarization
Discriminative Marginalized Probabilistic Neural Method for Multi-Document Summarization of Medical Literature
DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization
Educational Question Generation of Children Storybooks via Question Type Distribution Learning and Event-centric Summarization
EntSUM: A Data Set for Entity-Centric Extractive Summarization
Graph Enhanced Contrastive Learning for Radiology Findings Summarization
Hallucinated but Factual! Inspecting the Factuality of Hallucinations in Abstractive Summarization
HIBRIDS: Attention with Hierarchical Biases for Structure-aware Long Document Summarization
Learning Non-Autoregressive Models from Search for Unsupervised Sentence Summarization
Learning the Beauty in Songs: Neural Singing Voice Beautifier
Length Control in Abstractive Summarization by Pretraining Information Selection
MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes
Neural Label Search for Zero-Shot Multi-Lingual Extractive Summarization
Other Roles Matter! Enhancing Role-Oriented Dialogue Summarization via Role Interactions
Predicting Intervention Approval in Clinical Trials through Multi-Document Summarization
PRIMERA: Pyramid-based Masked Sentence Pre-training for Multidocument Summarization
Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
SummaReranker: A Multi-Task Mixture-of-Experts Re-ranking Framework for Abstractive Summarization
The patient is more dead than alive: exploring the current state of the multidocument summarisation of the biomedical literature
Towards Abstractive Grounded Summarization of Podcast Transcripts
Unsupervised Extractive Opinion Summarization Using Sparse Coding
Updated Headline Generation: Creating Updated Summaries for Evolving News Stories
Knowledge Graph【知识图谱】
CAKE: A Scalable Commonsense-Aware Framework For Multi-View Knowledge Graph Completion
Efficient Hyper-parameter Search for Knowledge Graph Embedding
KaFSP: Knowledge-Aware Fuzzy Semantic Parsing for Conversational Question Answering over a Large-Scale Knowledge Base
Multilingual Knowledge Graph Completion with Self-Supervised Adaptive Graph Alignment
Prix-LM: Pretraining for Multilingual Knowledge Base Construction
RotateQVS: Representing Temporal Information as Rotations in Quaternion Vector Space for Temporal Knowledge Graph Completion
Sequence-to-Sequence Knowledge Graph Completion and Question Answering
SimKGC: Simple Contrastive Knowledge Graph Completion with Pretrained Language Models
Understanding Gender Bias in Knowledge Base Embeddings
Special Track【特殊任务】
Code Relevant
Accelerating Code Search with Deep Hashing and Code Classification
Impact of Evaluation Methodologies on Code Summarization
Modeling Hierarchical Syntax Structure with Triplet Position for Source Code Summarization
Towards Learning (Dis)-Similarity of Source Code from Program Contrasts
UniXcoder: Unified Cross-Modal Pre-training for Code Representation
ReACC: A Retrieval-Augmented Code Completion Framework
Impact of Evaluation Methodologies on Code Summarization
Math Problem
Learning to Reason Deductively: Math Word Problem Solving as Complex Relation Extraction
Continual Pre-training of Language Models for Math Problem Understanding with Syntax-Aware Memory Network
NumGLUE: A Suite of Fundamental yet Challenging Mathematical Reasoning Tasks
Word / Sentence Segmentation
Weakly Supervised Word Segmentation for Computational Language Documentation
Word Segmentation as Unsupervised Constituency Parsing
That Slepen Al the Nyght with Open Ye! Cross-era Sequence Segmentation with Switch-memory
TopWORDS-Seg: Simultaneous Text Segmentation and Word Discovery for Open-Domain Chinese Texts via Bayesian Inference
Others
Automated Crossword Solving
CaMEL: Case Marker Extraction without Labels
Characterizing Idioms: Conventionality and Contingency
Challenges and Strategies in Cross-Cultural NLP
Clickbait Spoiling via Question Answering and Passage Retrieval
Computational Historical Linguistics and Language Diversity in South Asia
Doctor Recommendation in Online Health Forums via Expertise Learning
Ensembling and Knowledge Distilling of Large Sequence Taggers for Grammatical Error Correction
Entity-based Neural Local Coherence Modeling
Ethics Sheets for AI Tasks
HOLM: Hallucinating Objects with Language Models for Referring Expression Recognition in Partially-Observed Scenes
Identifying Chinese Opinion Expressions with Extremely-Noisy Crowdsourcing Annotations
Identifying Moments of Change from Longitudinal User Text
Identifying the Human Values behind Arguments
Improving the Generalizability of Depression Detection by Leveraging Clinical Questionnaires
Incorporating Stock Market Signals for Twitter Stance Detection
Inferring Rewards from Language in Context
Large Scale Substitution-based Word Sense Induction
Learning From Failure: Data Capture in an Australian Aboriginal Community
Leveraging Similar Users for Personalized Language Modeling with Limited Data
Leveraging Wikipedia article evolution for promotional tone detection
Misinfo Reaction Frames: Reasoning about Readers' Reactions to News Headlines
Multilingual Detection of Personal Employment Status on Twitter
Not always about you: Prioritizing community needs when developing endangered language technology
Perceiving the World: Question-guided Reinforcement Learning for Text-based Games
Reinforcement Guided Multi-Task Learning Framework for Low-Resource Stereotype Detection
Searching for fingerspelled content in American Sign Language
Slangvolution: A Causal Analysis of Semantic Change and Frequency Dynamics in Slang
Toward Annotator Group Bias in Crowdsourcing
Towards Afrocentric NLP for African Languages: Where We Are and Where We Can Go
Uncertainty Estimation of Transformer Predictions for Misclassification Detection
VALUE: Understanding Dialect Disparity in NLU
You might think about slightly revising the title: Identifying Hedges in Peertutoring Interactions
A Functionalist Account of Vowel System Typology
更多推荐

SIGIR 2022 | 推荐系统相关论文分类整理

让ML创造RS:推荐系统中的自动化机器学习
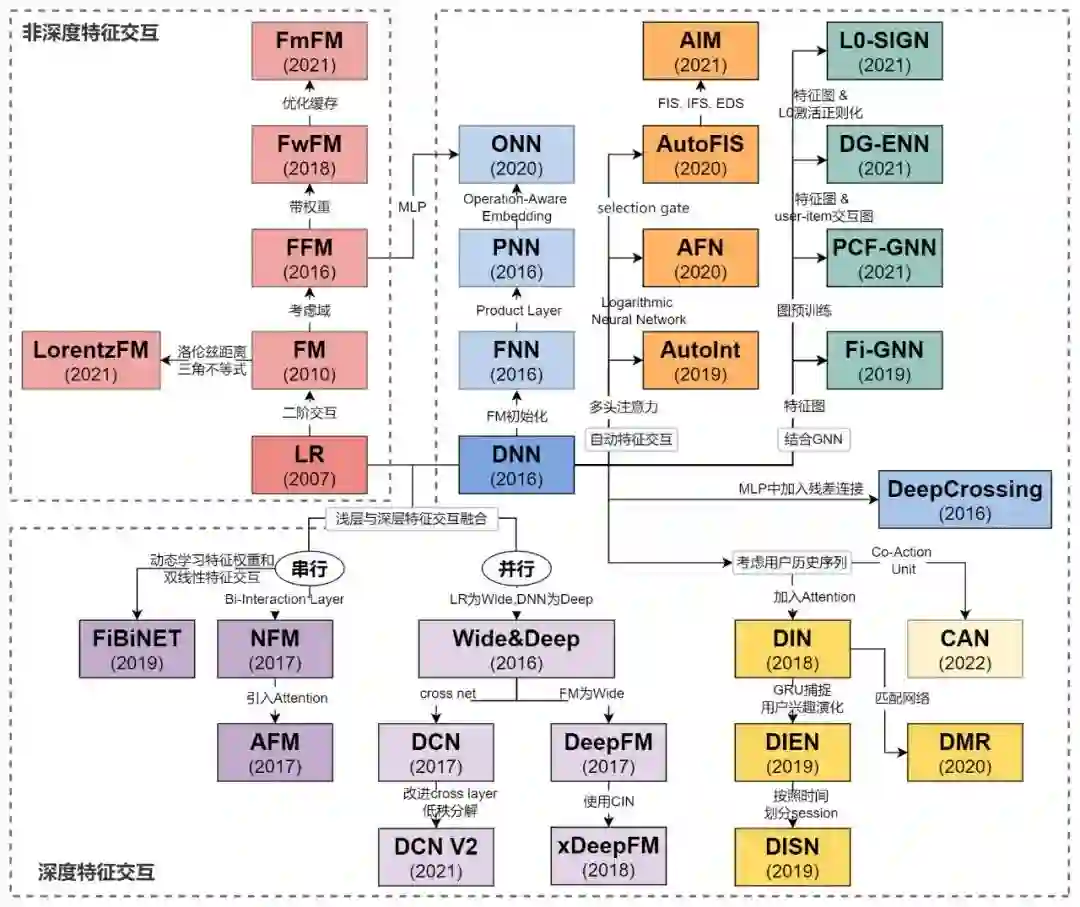
一文梳理推荐系统中的特征交互排序模型





