2017年数据库技术盘点
作者 | 那海蓝蓝,小编0.7,大米
责编 | 仲培艺
在数据库领域,回顾2017这一年,精彩纷呈,热点不断,而且不乏标志性的事件发生。
如Oracle提出的自治数据库这样的概念,把数据库技术带入一个新世界。其实AI技术应用于数据库由来已久,如AI技术调优数据库的性能、AI技术优化SQL、AI技术自动创建数据库索引(Learned Index)等。但是能把AI和数据库结合使之进入大众视野的,还非“自治数据库”莫属。
再如NDBC(中国计算机学会数据库学术年会)庆祝四十华诞、阿里入股MariaDB、国内类Aurora架构的产品争相发布、数据库事务处理等核心技术的原创书籍出版、社区活动遍地开花……无一不在彰示着国内数据库界的精彩和繁荣。
我们将从学术界、工程界的角度,从国外到国内,从数据库内核技术到数据库运维等多种角度,一起来回顾精彩的2017。
百看不厌的数据库排行榜
截至2017年12月,在DB-Engines上排名的数据库引擎已多达361种。
从图1可见,Oracle、MySQL和Microsoft SQL Server稳居前三,一路遥遥领先。

但位于成熟期的同时,其成长空间也受到了一定的限制。Oracle虽保持第一,但处于明显下滑趋势;MySQL在2017年6月表现出色,几乎与Oracle持平,但后半年开始有所下滑;Microsoft SQL Server自2015年9月跌至谷底后一路回升,于2017年趋于稳定,但总体仍处于下滑趋势。虽说没有显著上升,但RDBMS三巨头雄踞排行榜top3已然且在不久的将来仍会是事实。
再把目光延伸至top20,就会惊人地发现,NoSQL家族正在爆炸式崛起。MongoDB、Redis、Cassandra、HBase和Hive年轻气盛,一路飙升,从2014年到2017年均已实现分值翻倍(图2)。稳坐非关系型数据库第一把交椅的MongoDB,从2009年的首度推出到现在不过十年,便已跻身top5,其发展潜力让人期待。

数据库产品的起起伏伏,是数据库工程界的一个风向标,但不是数据库界的全部。2017这一年,数据库的理论界也因AI而亮点多多。接下来,让我们睁眼看看世界,然后瞪大眼睛反观一下国内的情景。
地球就那么大,世界的大门早已打开
以前,国内数据库技术一直在跟跑国外的数据库技术,学术研究队伍如此,工程实践队伍也如此。可以说,在数据库技术的世界里,我们前30多年一直在学习、一直在探索。而国际的前沿技术引路者,还在不断引领数据库技术的潮流。2017这一年,世界上的一些重大事件如自治数据库的概念推出、Aurora相关技术的论文发表、Spanner用论文宣告成为关系型数据库系统等,都在影响着国内的技术圈子。
Oracle,开启自治数据库时代
2017年的Oracle Open World大会上,Oracle总裁拉里·埃里森公布了新杀器,Oracle自治数据库云。这款全球首款“自动驾驶”的数据库,集成了人工智能和自适应的机器学习技术,实现全面自动化。
自治数据库云的实现,是基于Oracle Database 18c的。对比目前的Oracle数据库,Oracle 18c在性能、内存优化、可用性、安全性、数据仓库等方面都作出优化提升,向HTAP数据库的目标更进一步。
Oracle自治数据库云,消除了复杂性、人为错误和人工管理,能够以更低的成本提供更高的可靠性、安全性和运营效率。通过融合机器学习技术,自治数据库云具备这些特点:
自主驱动:完全自动化的打补丁、升级、备份和可用性架构,可执行所有日常数据库维护任务,无需任何人工干预。
消除人为错误:
自动恢复功能可自动检测并应用纠正措施,Oracle 自治数据库云将自动实施 Oracle Real Application Clusters (RAC) 和跨区域 Oracle Active Data Guard,确保持续的可用性。
Oracle SLA确保99.995%的可靠性和可用性,把代价高昂的计划内和计划外停机控制在每年30分钟内。
无需手动性能调优:采用自适应机器学习技术,自动激活列式缓存、存储索引、压缩和资源优先排序,根据负载所执行的实际工作分配资源,避免代价高昂的过度供应。
Oracle推出Oracle 18c和自治数据库云,正指出了数据库领域的发展趋势:数据库HTAP化,和人工智能结合,机器学习代替人工完成繁琐的数据库操作。放眼看去,如卡内基·梅隆的ottertune,一些开源项目顺应潮流,向智能化、自动化数据库靠近。
另外,这一年,Oracle发布12c R2版本,也就是12.2.0.1,多方面得到提升,包括:
可用性方面:数据保护、逻辑复制、在线操作、分片等的表现得到提升,同时简化了升级操作。
大数据和数据仓库:完善大数据管理系统结构、提供数据库内的多维度分析、加强查询处理和优化等。
性能方面:优化共享队列,全局共享Oracle云连接池,增强Java虚拟机上Oracle数据库的性能,完善内存数据库,简单支持非结构化数据存取等。
压缩、管理、公有云、安全性、空间和图等特性得到增强。
在数据库的世界里,Oracle依旧是独占鳌头。
AWS Aurora,启动计算与存储分离的热潮
2017年,Amazon在SIGMOD上发表了论文《Amazon Aurora: Design Considerations for High Throughput Cloud Native Relational Databases》,描述了Amazon的云数据库Aurora的架构。基于MySQL的Aurora对于单点写多点读的主从架构做了进一步的发展,使得事务和存储引擎分离,为数据库架构的发展提供了具有实战意义的已实践用例。其主要特点如下:
实践了“日志即数据库”(参考《High Performance Transactions in Deuteronomy》) 的理念。
事务引擎和存储引擎分离。
数据缓冲区提前预热。REDO日志从事务引擎中剥离,归并到存储引擎中。
储存层可以有6个副本,多个副本之间通过Gossip协议可以保障数据的“自愈”能力。
主备服务的备机可达15份,提供强大的读服务能力。
持续可靠的云数据库服务能力。
数据存储跨多个区:提供了多级别容灾能力。
数据容灾能力:数据冗余、备份、实时恢复等多种能力集成到云服务,提高数据保障能力。
万能数据库的概念呼之欲出。
而2017年尾,AWS的技术大会上,又爆料称AWS支持:multi write、类TureTime、Serveless等,这些都和最新的趋势紧密相融,前两者对应分布式数据库,后者对应数据库云化。
Aurora对国内的计算与存储分离的产品研发影响深远,阿里的PolarDB、X-DB,华为的FusionInsight系列等都在向Aurora对齐。相传,腾讯、京东等都跃跃欲试准备做类Aurora的产品。可见Aurora对国内的影响深远。
Spanner,引领分布式数据库潮流
2012年的《Spanner: Google’s Globally-Distributed Database》论文描述了基于KV系统(《Bigtable: A Distributed Storage System for Structured Data》)实现的一个半数据库式的“分布式系统”(《Spanner: Becoming a SQL System》:Spanner is built on ideas from both the systems and database communities.) ,这个系统具备了大规模的扩展性,具有如下几个方面的特色:可扩展性、自动分片、容错性、一致性复制、外部一致性,和数据广域分布。这些特色是通过提供了多行事务、外部一致性、跨数据中心的透明故障转移等功能实现的。Spanner开创了NoSQL分布式数据库的新时代,主要解决了如下问题:
1. 数据分布
2. 多副本高可用:failover
3. 分布式事务处理:外部一致
4. 计算分布(通过F1支持SQL,松耦合结构)
5. KV存储模型
2017年,Google发表了一篇题为《Spanner: Becoming a SQL System》的论文。这篇论文描述了查询执行的切分、瞬态故障情况下查询重新执行、驱动查询做路由和索引查找的范围查询,以及改进的基于块的列存等分布式查询优化技术。
较之2012年的Spanner,本篇论文提到新增功能为:强类型的模式管理系统、查询处理器和关系模型存储及列存系统,并论述了2012年以来,Spanner系统向关系型数据库演进的历程,新论文愉快地表示Spanner从一个NoSQL系统已经全面演进为了一个关系型分布式数据库系统。
这篇论文表明如下几点事实:
1. 有分布式基因的NoSQL是可以进化为NewSQL的,进化的途径可参考Spanner的发展历程,而Spanner也给出了进化方式的建议(有了分布式处理能力后及早向关系型演进)。
2. 这种进化具有“快乐”的“进步”意义。快乐如论文标题宣称“成为了”一个SQL系统,口气十分自豪;进步如论文标题宣称Spanner已经是一个“SQL”系统了,即具备了关系存储和关系运算的能力。
3. NewSQL的一个特征是支持混合数据类型存储,如Spanner支持NoSQL也支持关系存储模型。而支持关系模型将是NewSQL系统的一个重要特征。
4. Spanner的另外一个特征是由松耦合的系统进化到一个高效的紧耦合系统,这样的系统能够处理各种类型的大数据。与此不同的是目前的大数据处理组件因松耦合而导致三难(选型难、使用难、维护难)。这表明大数据处理的技术架构可能从松耦合向紧耦合演进。
从Spanner的演化,我们可以感知关系型数据库的春天重返故里,而分布式关系型数据库已经踏着数据库前进的节拍走到了我们眼前。现在,已经不是潮流来临,而是在席卷2017年的我们,并继续横扫2018。以此来观察数据库界,这一年,OceanBase、TDSQL、TiDB、CockroachDB等主流分布式数据库即NewSQL系统正如火如荼地发展着,技术层面不断向Spanner靠拢。
NoSQL、图数据库、流数据库等场景化明显
随着互联网Web2.0网站的兴起,传统的关系数据库在应付超大规模和高并发的SNS类型的纯动态网站时已经显得力不从心,而NoSQL数据库由于其本身的特点得到了非常迅速的发展。
NoSQL家族主要分为键值(Key-Value)存储数据库、列存储数据库、文档型数据库和图数据库四大类,其产生就是为了解决大规模数据集合多重数据种类带来的挑战,故场景化也格外明显。
键值存储数据库适用于内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等。
列存储数据库适用于分布式的文件系统;文档型数据库适用于Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容)。
图数据库适用于社交网络、推荐系统等,专注于构建关系图谱,如果与AI结合起来,我们可以设想一下他们美好的未来。
NoSQL数据库并没有一个统一的架构,而是各有所长,一个成功的NoSQL必然特别适用于某些场合或者某些应用。
还有意思的是,Kafka今年终于正式迎来了1.0.0版本,不仅标识着各组件功能的稳定性,还引入了一些新的功能:Kafka Streams API的优化(增加了一些全新的操作算子如cogroup等);JMX监控指标的完善(引入很多集群健康度检查指标,对Kafka Connect监控体系做了较大程度的补足);优化SASL认证错误的处理;强化对JBOD磁盘崩溃的处理;幂等producer的优化。此外,Kafka新引入了KSQL引擎,使得其更像一个流数据库而存在。
2017年,从关系型数据库之外的其他数据库,我们看到,数据库正在朝场景化方向发展,不同类型的数据库适用于不同的场景,数据库产品只有做好自己的场景定位,才能谋取到更大的发展。
一些老牌数据库,在变革中渐渐老去
2017年5月,微软还发布了首款全球分布式多模型数据库Azure Cosmos DB,这是一款全球可用的JSON数据库平台。可以看到,关系数据库厂商抢占NoSQL市场的鏖战也将日趋激烈,几年前,PostgreSQL和MySQL已经支持了JSON类型数据,另外还有老牌的Infomix也是如此。
同在2017年5月,微软发布了SQL Server 2017 CTP2.1正式版。这是SQL Server历史上首次同时发布Windows和Linux版,并支持Docker部署。从数据库排行榜看,微软占据第三位,遥遥领先第四位PostgreSQL。SQL Server似乎风光依旧。
但是,在国内,SQL Server已经很难打开高端市场的局面了(几乎就是Oracle和MySQL的天下)。其实在国内,得益于在教育领域的耕耘和出色的产品易用性,SQL Server有着比较好的群众基础和亲和形象。但一直以来,SQL Server都给大部分人群留下“适用于中小企业”的陈旧印象,再加上缺乏本地技术社区的建设,SQL Server已经渐渐淡出“高端玩家”的视野。若想要反转局面,那么进一步塑造品牌、打造标杆案例、不断提升产品和建设本地技术社区是SQL Server浴火重生的必经之路。
无独有偶,起源于上世纪80年代的Informix,一个全球市场占有率曾经超过10%的元老级数据库,如今也面临着窘境。一个曾经是世界上最好的关系型数据库,却因为企业自身的经营问题,掩盖了技术上的成功。2001年,Informix被IBM公司接管,虽然一直保持更新,但是销售始终不尽人意。终于在2017年5月1日,印度的HCL公司宣布正式接管Informix研发和支持团队,这将重写Informix与国内三家公司的关系。在此之前,IBM公司将Informix授权给了南大通用、华胜信泰和福建星瑞格这三家中国数据库厂商以期合作。现在变数未定。Informix或许再也不能恢复当年的辉煌,但我们有理由相信,一定能够在众多国内知名数据库里看到Informix的影子,看到它的技术精华被传承下去。
其实在IBM公司接管Informix期间,就融合了Informix的技术成就了DB2数据库。到了2017年6月22日,DB2已经发布了V11.1 Mod Pack 2 and Fix Pack 2版本,增强了crash recovery和SQL直接对JSON格式的数据进行操作的能力,包含了更多函数的支持。在DB-Engines上,DB2也有着排名第六的不错成绩。相较Informix,DB2显然更受IBM公司的青睐,但这仍掩盖不了DB2在中国销售不佳的事实(主要集中于金融行业)。DB2因其入门慢、市场推广差,往往不是用户的第一,甚至第二选择。
2017年9月,SAP发布了HANA 2.0 SPS 02最新版本,为支持使用最新内存技术运行业务,主要新增了以下四大功能:一是数据库功能的增强,包括高可用性和灾难恢复等。二是提供了高级分析处理能力,如使用SAP HANA预测分析库(PAL),以简化调用算法的方式加速预测性应用程序开发,并能够使用SAP Web HANA for SAP HANA开发预测性和机器学习模型等。三是应用程序开发和工具增强。四是数据管理功能增强等。但HANA在国内的表现,尚在普通之列。
一些开源数据库,前途光明灿烂
让我们来看看2017年,开源数据库都有哪些精彩的表现。
MySQL
10月发布最新的稳定版本5.7.20,修复很多bug,针对审计、Docker、安全、插件、复制、参数配置和管理等方面做了更新和调整。
日志审计功能增强;安全功能增强;X plugin更新;复制功能增强和更新。
修复Docker中MySQL镜像丢失的bug。
弃用、去除了一些配置参数,比如tx_isolation和tx_read_only将被弃用。
9月发布最新MySQL 8.0.3 RC版本,此版本在账户管理、原子DDL、性能优化、安全等方面做出优化,并且修复了大量bug。
支持角色管理,角色是一系列权限的集合,可以给某个用户授予和回收角色,使用角色可以更方便进行权限管理。
InnoDB存储引擎支持原子DDL操作,包括表相关DDL和非表相关DDL。
采用新的数据字典,所有元数据都用InnoDB引擎存储,以解决DDL的原子性问题。
修复历史悠久的bug,8.0版本不再重置auto_increment值。
MariaDB
11月发布最新版本10.2.11,此版本在优化、系统变量、主备复制、存储引擎等方面做出补充和改进。
现在InnoDB作为默认存储引擎,添加MyRocks存储引擎的alpha版本。
引入窗口函数。
更新InnoDB到5.7.18版本。
更新TokuDB到5.6.7-82.2。
PostgreSQL
11月发布新版本10.1,PostgreSQL 10的重磅特性有并行计算、逻辑订阅、FDW pushdown和sharding等。
支持陈述性表分区。
支持预写日志支持哈希索引。
主备复制,支持逻辑复制,同步复制的仲裁提交。
性能提升,支持并行位图堆扫描、B-树索引扫描、合并连接。
TiDB
10月发布GA版本(TiDB1.0),该版本对 MySQL 兼容性、SQL 优化器、系统稳定性、性能等方面做了大量的工作:
SQL查询优化器(调整代价模型,Analyze下推,函数签名下推)。
优化内部数据格式,减小中间结果大小。
提升MySQL兼容性。
支持NO_SQL_CACHE语法,控制存储引擎对缓存的使用。
重构Hash Aggregator算子,降低内存使用。
支持Stream Aggregator算子。
MongoDB
于2017年10月19日在纳斯达克上市,11月发行最新版本3.6,伴随着MongoDB 3.6的 发布,MongoDB Team提供了一个方便开发者的指南社区。新版本主要提供以下几个功能:
Change stream,通过Oplog监听一个集合的DML事件,用来实现pubsub类型的场景。
Retryable writes,当集群出现换主现象时,写入操作会被自动重试从而保证应用端的透明。
Tunable consistency,MongoDB提供可调的一致性(一致或最终一致),并在query中定义。
Greater query and update expressivity,支持操作嵌套数组;提供新的聚合操作符,以及在查询语法中使用聚合表达式。
Apache Cassandra
最新版3.11.1,发布于2017年10月,此版本在完善功能、提高性能等方面做出大量工作,并且修复众多bug:
sstableloader忽略“ignore”选项。
实现分区边界的short read protection。
提升TRUNCATE性能、提升short read protection性能。
修复对SuperColumn表的支持。
总体上来看,在DB-Engines排名top5中,开源数据库就占了三席,分别为MySQL、PostgreSQL和MongoDB。这些开源的数据库,究其成功的根本原因,是在放弃部分著作权的前提下,赢得了三大好处:培养开源社区,获得更大的用户群体;降低该产品和相关产品的技术支持成本;通过开源社区得到更多的衍生作品,提供更好的生态环境。
我们相信,在2018乃至更长远的未来,开源数据库会越走越好。
CockroachDB,开源NewSQL
CockroachDB是一个分布式类Spanner架构的数据库,通过基于时间戳的MVCC技术,完整地支持了ACID语义。在隔离级别层面,支持SSI和SI,且SSI作为默认级别。
对于SSI,CockroachDB受“write-snapshot isolation ”(详情参见《数据库事务处理的艺术:事务管理与并发控制》6.3.4节)技术影响较大,着力于解决读-写冲突,以实现SSI。
CockroachDB支持外部一致性,支持有限的线性一致性。
2017年10月CockroachDB发布1.1版本,引入了快速并发导入数据的功能,主要做了三方面的工作:
1. 从遗留数据库进行无缝迁移 。
2. 简化集群管理。
3. 为云环境提高性能。
在《What’s Really New with NewSQL?》这篇论文里,如图3,NewSQL被分为了三种类型,CockroachDB、Spanner、TiDB归属第一类NewSQL。

TDSQL、DRDS等这样的产品归属第二类NewSQL,但是从2017年TDSQL的发展来看,TDSQL从架构上更加靠近第一类NewSQL。
而Aurora这样的产品,被划分为第三类NewSQL系统。但Aurora公布了multi write之后,其架构是否也会向第一类NewSQL靠近呢?
未来的世界,我们相信,NewSQL会继续引领数据库的潮流,每种类型的NewSQL会相互借鉴、不断融合、协同发展。
中国数据库起源与发展
NDBC大会,中国数据库四十年
2017年金秋十月,第34届中国数据库学术会议(NDBC 2017)在西子湖畔成功召开,大会聚集了全国数据处理技术领域的前辈、专家、学者、师生。
在四十年前,即1977年,中国数据库的开山鼻祖,萨师煊倡导召开了全国数据库技术研讨大会,中国数据库萌芽,数据库技术的研究和推广就此展开。
从当初老一辈专家萨师煊、王能斌、罗晓沛、施伯乐等播下数据库技术的火种,到杨冬青、马应章、王珊、尹良滨、冯玉才、李建中、何守才、何新贵、张大洋、张少润、张作民、郑怀远、郑振楣、周立柱、周龙骧、徐秋元、徐洁磐、唐世渭、唐常杰、姚卿达、童頫、董继润、瞿兆荣、岳丽华等专家教授奋发图强,再到新一代杜小勇、崔斌、高宏、李占怀、彭智勇、王国仁、周立柱、王建民、陈红、于戈等教授(还有很多专家教授没能一一列出,他们都是中国数据库的脊梁),中国数据库开始发展兴旺。
相较世界数据库技术,中国数据库技术从起步、跟踪、追赶,到并跑,凝结了数代老一辈专家的心血。
四十来,老一辈专家们培养了一批批的中国数据库人,他们或投身工业实践,或专心学术研究,或出国汲取经验,或开创国内数据库产品。这些人,正是中国数据库技术的脊梁,在众多数据库人的努力下,中国的数据库实现了:
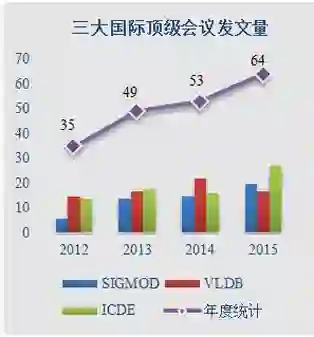
1. 科研国际化:论文发表直逼美国(如图4)、举办国际学术杂志/会议(如CODAS、WAIM、APWEB、DASFAA、PAKDD、WISE、CIKM 、E-R、VLDB等)、国际学术界获奖等。
2. 教学精品化:各种数据库教材层出不穷,引领了国内数据库技术的发展。例如,现在分布式数据库技术非常火热,而NDBC的老专家们1998年就开始研究并出版了一系列的分布式数据库技术书籍,如图5所示。

3. 成果产业化:科研成果转化为实际的产品服务于中国的市场,并为中国数据库界培养了一代又一代的数据库工程实践人才。如国内最早做数据研发的人大金仓、武汉达梦、神舟通用、南大通用等公司,其背后的技术源泉都是来自高校的数据库研究团队。
现在,活跃在中国的科研、教学一线的数据库、大数据专家们,如数据库领域的杰青包括哈尔滨工业大学的李建中教授、华东师范大学的周傲英教授、东北大学的王国仁教授、清华大学的王建民教授,都成绩斐然;入选国家千人计划的数据库人才如周晓方、樊文飞、张彦春、林学民、文继荣、王晓阳、申恒涛、武新,都领军一方;成为长江学者特聘教授与长江学者讲座教授如冯玲、周傲英、王国仁、崔斌、樊文飞、黄铭钧、熊辉,都成绩卓著。这些杰出的专家教授们,同时又培养出一代又一代的数据库人才。
现在,活跃在华为、腾讯、阿里、京东等公司的数据库核心研发人员,有很多专家、技术骨干,都是出自人大金仓、武汉达梦、神舟通用、南大通用等公司,从他们身上,我们可以看到NDBC四十年前点燃的星火、四十年里培养浇灌的树苗,现在已经成材,成为国内数据库研发的骨干栋梁。
春天里的数据库
百花齐放的数据库技术大会
越来越多的技术人,或专心数据库学术研究,或投身于数据库产品开发,各数据库技术大会在这样的背景下产生,为喜爱和从事数据库研究的技术人提供了交流、提高的平台。
国内规模较大的数据库学术会议有中国数据库技术学会(NDBC)和中国大数据技术大会(BDTC)。
今年,还有这些国际学术会议在国内召开:
DASFAA 2017(The 22nd International Conference on Database Systems for Advanced Applications):3月在苏州召开。
The Asia Pacific Web (APWeb) 和 Web-Age Information Management (WAIM) Joint Conference:6月在北京召开。
工业界规模较大的数据库技术大会,有中国数据库技术大会(DTCC)、Oracle数据技术大会,中国MySQL用户组年会(ACMUG)和MySQL技术嘉年华(IMG)、PostgreSQL中国用户大会(PCC)等。
这一年,我们还看到,其他的社区活动也精彩不断,CockroachDB社区成立,Redis、HBase等社区活动开展,这些活动为中国工程界的数据库技术增添了亮色。
百舸争流的数据库产品
1. 传统的数据库产品:
人大金仓(Kingbase):2017年8月,KingBaseES通用型数据库产品,成功入驻阿里云市场,具备适应当下云计算环境的数据库特征。
达梦数据库(DM):2017年,DM与多省展开合作,为四川地质环境信息建设、广西电子政务等提供数据库服务。
南大通用(GBASE):2017年3月,旗下的通用型数据库登录青云App Center 2.0平台,提供云化数据库服务。
2. 分布式数据库:
国内分布式数据库的代表有腾讯分布式数据库TDSQL、阿里云(DRDS)、OceanBase、TiDB等,这些产品代表了国内分布式数据库的水平:
腾讯分布式数据库TDSQL:
一款企业级面向金融类业务的数据库产品。
支撑了腾讯自己的计费业务。
输出到诸如微众银行等企业,稳定运行了三年之久。
2017年发布了分布式事务、分布式JOIN、多种数据分区、多级数据分区、热点更新等特性。
阿里数据库产品家族:
云栖大会前夕,推出新一代高性能数据库PolarDB、X-Cluster等,均采用分布式存储引擎设计。
OceanBase,2017年发布1.4.51版本,提供了副本只读、前后端协议checksum机制、同义词功能和回收站等功能。
TiDB:
与腾讯云和Ucloud先后达成合作。
发布GA版(TiDB 1.0),对MySQL兼容性、SQL优化器、系统稳定性、性能等做了大量工作。
硅谷Office落地,此举标志着PingCAP进一步在全球布局云计算产业。
SequoiaDB:
SequoiaDB发布v2.8.3企业版。
“热热闹闹”的数据库市场,产品众多,篇幅有限我们不再一一罗列。但我们可以从这些产品的共性着手,看到其中的一些端倪。2017年国产数据库发布的新品、新特性,似乎还不是很多,不很精彩。个中缘由,如果从“人”着手思考,相信你懂的。
百马奔腾的数据库研发团队
现如今,国内的数据库研发队伍已经颇具规模。
从拥有200余人规模的阿里数据库技术团队(阿里云、蚂蚁金服和阿里集团数据库事业部),到人数300+的“中国最神秘研究基地”——华为2012高斯实验室,以及腾讯的TEG金融云、腾讯云,百度的搜索架构团队、京东的京东云等,国内数据库研发无不展现出一派生机勃勃的景象。
这些研发队伍,不仅积极为开源社区添砖加瓦,也大力投入自主研发。
在此,让我们罗列一下已知的数据库引擎研发团队(尚不完整),与他们一起见证国产数据库研发的繁荣,也让我们思考一下繁荣的背后,为什么我们还没有世界级产品?
1. 大型通用数据库系列:人大金仓、达梦、神州通用、南大通用
2. 腾讯系:TDSQL、TXSQL、Tbase、PhxSQL
3. 阿里系三个团队:阿里巴巴集团数据库事业部、阿里云、Oceanbase
4. 其他互联网:京东云、百度、小米
5. 华为系三个团队:2012高斯、2012分布式实验室、华为云(IT企业产品线)
6. DB2中国研发团队(曾经的存在)、EsgynDB中国团队、国家电网、中国移动苏州研究院、中国电信广州团队(尚存在否?)
7. NewSQL系列:PingCAP、巨杉
8. PostgreSQL系:HighGo DB、亚信南京AntDB、中兴GoldenDB 、Greenplum中国团队、飞象
9. MySQL系列:爱可生、上海热璞、万里开源、MySQL中国区研发成员、OneSQL
10. 分析型系列/大数据系列:柏睿数据RapidsDB、酷克数据、偶数科技、Kylin创业团队Kyligence、星环科技
11. Informix系列:华胜信泰、福建星瑞格、南大通用(重复)
12. 其他:Haisql、许继集团SG-RDB、Cedar、上容、天曦TXDB、HHDB、博阳数据管理系统、东方国信、优炫云数据库、新华三、鼎天盛华Huayisoft、HUABASE
双11,源自中国的需求大于技术突破的意义
每年电商双11大促,中国单一群体的巨量行为(同一文化氛围下的同一种行为相较世界其他民族,有着不可预估的量,是不可预估的群体行为),对阿里、京东等电商的数据库团队都是一次巨大考验。
经过9年的发展,双十一场景对数据库的稳定性、性能提出非常高的要求,尤其是零点高峰,无论国内国外,都难得一见。
面对交易洪流,阿里集团的数据库扛住一波波洪峰,阿里的OceanBase扛住了交易洪峰,整个阿里交易创建峰值32.5万笔/秒,支付成功峰值25.6万笔/秒,数据库处理峰值4200万次/秒。而京东的交易,也是一路攀升。这些成绩背后支撑业务发展的幕后英雄之一是数据库技术。
双11的成绩,宣告的不仅是商业的胜利,也不仅是数据库技术获得“巨大”突破的胜利,而是中国式需求对数据库技术提出的场景考验,这种场景的考验将持续不断地对数据库技术发出新的考题,促使在中国做数据库研发的技术人员“被迫”进步,数据库技术“被迫”创新。互联网场景将引发多行业的创新场景,也许正是国产数据库单点突破所在。
TiDB,国内开源界的一抹亮色
这一年,成立近3年的TiDB,亮点颇多(2017年10月份发布了GA V1.0版本,还提供了TiSpark查询方案),已然成为国内鲜有的数据库原创开源代表,甚至在国际上赢得颇多赞许(GitHub stars 11000+,contributors 155+,媲美CockroachDB)。
TiDB是PingCAP公司自主开发的开源分布式数据库产品,模型参考了Google的分布式数据库论文(Spanner / F1),解决了关系型数据库水平扩展的难题,具备水平弹性伸缩、强一致的分布式事务、基于Raft算法的多副本复制等特性。作为一个典型的SQL Above NoSQL的架构,TiDB底层是一个支持跨行事务和强一致性的分布式KV存储引擎,上层是支持SQL语法和查询的分布式执行引擎,这种存储和计算分层的架构具有更好的灵活性,可以根据不同的业务负载做弹性的水平伸缩。
从使用者角度来看,TiDB高度兼容MySQL协议,在大多数情况下,应用层不需要修改一行代码,就可以获得支持高并发的扩展能力,同时支持智能的数据调度和故障自恢复功能,用户迁移和维护成本都会非常低。
未来,TiDB会在数据库云的多租户和资源隔离、高效实时的查询分析引擎、新硬件下的新技术架构优化、完善智能的调度系统、HTAP等方面发力,为用户带来更多的价值。
因为有了OceanBase、TDSQL等,有了TiDB,国内数据库界有了“创新”的味道,而TiDB开源可能会使更多的人多方面受益,相较于一些产品从开源到闭源,这一点更有意义。
立言,原创有深度
一个领域内的图书出版量和销售量,往往能反映该领域的发展态势。
一个领域内出版的图书的质量,往往能反映该领域的深入程度。
让我们先来看看近几年国内几家出版社的数据库类图书出版量(如图6),可以发现,数据库类图书虽然在总出版量中占比不大,但还是有逐年上升的趋势,这其中大数据与数据分析类图书占据了相当大一部分,而数据库理论类图书则较低迷。
再来看看数据库类图书的销售情况。线上销售以亚马逊销售排行榜为例,截至2017年12月,在数据库类实时销售排行榜中,top3分别为《大数据时代:生活、工作与思维的大变革》、《SQL必知必会(第四版)》和《深入浅出数据分析》,而数据库理论类图书中仅《数据库索引设计与优化》与《数据库系统概念》两本跻身top10。这一现象在线下销售中得到了更充分的体现。
这难道是数据库领域已经不需要理论知识扎实的人才了吗?其实不然。在数据库行业中,刚入门的新手渴求的是一本涵盖全面的工具书,对理论类图书大都是望而却步;而已经摸爬滚打十几年的老手们,凭借丰富的经验和阅历,足以满足企业研发所需,自然就不需要这方面的书了,所以数据库理论类的书籍较少。
入门菜鸟希望得到老鸟的经验,国内的图书基本满足了入门的需要。
经验丰富的老鸟希望深入原理、深入代码让自己百尺竿头更进一步,可是这方面的书籍太少。
国内数据库原创书籍,深入到原理和源码层面的,经典的有《MySQL技术内幕:InnoDB存储引擎》、《PostgreSQL数据库内核分析》、《数据库查询优化器的艺术》这几本书,极高的质量和极佳的口碑为中国数据库界增色不少。
而2017年出版的数据库图书中,《MySQL运维内参:MySQL、Galera、Inception核心原理与最佳实》销量较好,《数据库事务处理的艺术:事务管理与并发控制》一书则直接深入到数据库最核心的技术——事务处理层面讨论了并发访问控制等核心技术,这种有深度的书籍折射出国内数据库研发的水准在向最核心部分攀登前进。
站在2017年尾,数据库界更加期盼,未来有更多高质量有深度的数据库原创书籍,来推高国内数据库研发、运维的水准。因为我们看到,国内数据库研发团队在日渐兴旺。

跨年之夜,我们一起进步
2017,前行中有很多不足
2017这一年,数据库界热闹的背后,不足更甚。浮光掠影,采摘一小点儿,权作纪念,莫负了这春光美景。
浮夸之风日盛
跟跑作为事实,使得很多人渴望突破,这本是好事。
而国内的一些媒体和自媒体在产品或成果的宣介上,往往用词宏大,举轻若重,笑话不断。如“事务的核心是锁和并发”、“破解世界性技术难题! XXX让分布式事务简单高效”等宣讲词,前者对事务的理解不到位,封锁机制是并发控制的技术之一,锁和并发并不能在此语境下处于同等地位;后者则更是夸大其词,夸张的词语之后显露出一颗浮躁的心。
这样的错误或极其夸大的词在公众中传播,危害甚大。技术来不得半点儿虚假,踏踏实实做技术,如实地说明成绩,以求实为本才是技术人员的本质。
在2018,期望:数据库界求实地回归技术,回归技术人员的朴实。
借东风片面式宣传日盛
在这一年,还广为流传过一篇文章《中国数据库四十年历史》,文章借中国数据库发展四十年的时节,借助萨师煊的名,宣传了个别公司、个别人。文章以“中国数据库四十年历史”为大背景,涵盖范围却极其有限,用意十分明显且可笑。
如果熟知中国数据库发展历程,可以看到作者一知半解的数据库知识和数据库历史,很好地在其文、其图中暴露。
我们需要看到业界的不足,继续倡导求实之风。
自说自话的背后
2017年,国内数据库产品热闹非凡的同时,我们依旧看不到有团队公开自家产品的TPC-C、TPC-H、TPC-D等验证方案以及结果数据。一方面传奇般地宣称自家产品的神奇,另一方面又对一些公认的标准三缄其口,不与国际接轨,这也是一种特色。更有甚者,用Sysbench的部分测试场景以展示特定场景下的特定测试数据,因场景特定而貌似很好的测试数据蒙蔽了大众的眼。这些行为,实是不该。
我们认为,营造一个诚信、诚实的行业范围,是很必要的。如果我们有实力真正做到了世界前列,相信未来必是:你若盛开蝴蝶自来。
人才的匮乏
国产数据库引擎的研发,貌似数据库研发团队众多,但人才寥寥,所以我们能够感受到跟跑的步伐而不是并跑,能看到产品发布的速度慢而新特性不多,能够看到产品的相似度高是因缺乏创新没有深度人才。
国产数据库研发,没有大师,只有普通或略微好一点的工程师。真正的大师,不是十年、二十年就能修炼而得的。在数据库这个行业中,内外兼修,坐得了冷板凳者,才有望成为大师。
而略微好一点的工程师的定义是:基本能独立承担模块的研发。
搞定个别问题,与掌握数据库内核的核心技术,相距甚远。莫让他人浮躁的言语荼毒听者的耳力。
人才匮乏,这在很长一段时间内是一个客观存在。
2018,我们清楚方向在哪里,但需要加速前行
AI对数据库的影响
数据库技术的发展,是一个众多技术集成的过程,数据库把编译原理、操作系统等众多技术“集合”在一起,开创了自己的时代。其特点是不断融合新技术到数据库体系内,让业务开发简化。所以,数据库融合人工智能技术,也将是一个趋势。目前,我们可以看到AI将对数据库技术的发展,产生较大影响,比如:
1. 现有数据库系统的调优,严重依赖DBA的经验。将人工智能应用于数据库调优,可以花费最低的人力,实现数据库最高的效率。
2. 现有的数据库系统,须严格遵循语法才能使用。利用自然语言处理技术,用户可以使用自然语言描述查询,经由Query Interface翻译为SQL语法,大大降低用户的学习难度。
3. 自数据库诞生以来,查询优化始终作为一大研究问题。目前查询优化,只能依靠数据库专家的经验,人工智能技术能够帮助更广泛地应用查询优化技术。
4. 人工智能技术能极大推动数据挖掘的发展,更充分地利用数据库中存储的信息。
人工智能究竟对数据库有多少益处,不能穷举。但肯定的是,不论是数据库开发还是数据库使用,人工智能都会帮助数据库技术获得长足的进步(除了功能外,架构方面的颠覆可能更甚),且AI技术会不断集成到数据库当中。
硬件对数据库的影响
云平台对于特定的硬件,可以进行定制。由于云数据库发展迅速,因此可以忽略一部分硬件对数据库的影响。但是,这不代表着硬件将不再会对数据库产生影响。
相反,硬件技术的发展对数据库带来的影响,依旧可能是革命性的。如图7所示,我们借用鹅厂内部的一次分享的页面,用NVM等对数据库产生的影响简述如下,一切尽在图之外……

未来是什么?卸载包袱,实践现在
写到这里,也该收尾了,一篇冗长而又缺乏喜感还敢说诸多不足的杂文,在一个偌大的背景下以区区万字就想回顾2017实在是螳臂当车之举。就让这些挂一漏万且还惹人烦的言语随着2017远去吧。
轻轻地,你挥一挥衣袖,作别2017的浮云。
默默地,你站在2018起头的日子,重重地撸起袖子,低下头去,在实践中求实,口里念叨着我尚不明白的一些词语:YugaByte、BigChainDB、Learned Index……
作者介绍:
那海蓝蓝,腾讯金融云数据库技术专家,熟悉PostgreSQL、MySQL、Informix等数据库内核技术,著有《数据库查询优化器的艺术》等,在业界皆享有“里程碑”式的评价。
小编0.7,毕业于北京邮电大学,MySQL社区Oracle Contributor,目前就职于腾讯TDSQL团队,研发分布式数据库。
大米,毕业于中国人民大学,目前就职于腾讯TDSQL团队,研发分布式数据库。
责编:仲培艺(zhongpy@csdn.net)
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅《程序员》。