PyTorch一周年战绩总结:是否比TensorFlow来势凶猛?
选自PyTorch
机器之心编译
今天 PyTorch 刚好一周年。自发布以来,由于调试、编译等多方面的优势,它成为 2017 年热度极高的框架之一。本文内容介绍了开源一周年以来,PyTorch 取得的成绩。在一些指标上,PyTorch 也与 TensorFlow 做了同期对比。PyTorch 是不是 2017 年的明星框架?
Yann LeCun Twitter
截止到今天,PyTorch 已公开发行一周年。一年以来,我们致力于打造一个灵活的深度学习研究平台。一年以来,PyTorch 社区中的用户不断做出贡献和优化,在此深表感谢。
通过此文,我们打算对 PyTorch 一年的发展历程做一个总结:PyTorch 的进展、新闻以及社区亮点。
社区
我们很幸运,PyTorch 团队有一批强大、饱含热情的研究者和工程师,核心团队的工程师和研究者来自不同的国家、公司和大学,没有他们的付出就不会有今天的 PyTorch。
研究论文、工具包、GitHub
PyTorch 才发行几天,社区用户已经开始借助 PyTorch 实现其最喜爱的研究论文,并把代码公布在 GitHub 上。开源代码对当今的研究者来说是一个主要而核心的工具。
人们一起创建了 torchtext、torchvision 和 torchaudio,以便利化平民化不同领域的研究。
首个 PyTorch 社区工具包(被命名为 Block)来自 Brandon Amo,有助于更轻松地处理块矩阵(block matrix)。来自 CMU 的 Locus 实验室后来继续公布 PyTorch 工具包及其大部分研究的实现。首个研究论文代码来自 Sergey Zagoruyko,论文名称为《Paying more attention to attention》。
来自 U.C.Berkeley 的 Jun-Yan Zhu、Taesung Park、Phillip Isola、Alyosha Efros 及团队发布了非常流行的 Cycle-GAN 和 pix2pix,用于图像转换。

HarvardNLP 和 Systran 的研究者开始使用 PyTorch 开发和提升 OpenNMT,它最初开始于 Facebook Adam Lerer 的 [Lua]Torch 代码最初的再实现。
来自 Twitter 的 MagicPony 团队贡献了其超分辨率研究示例的 PyTorch 实现。
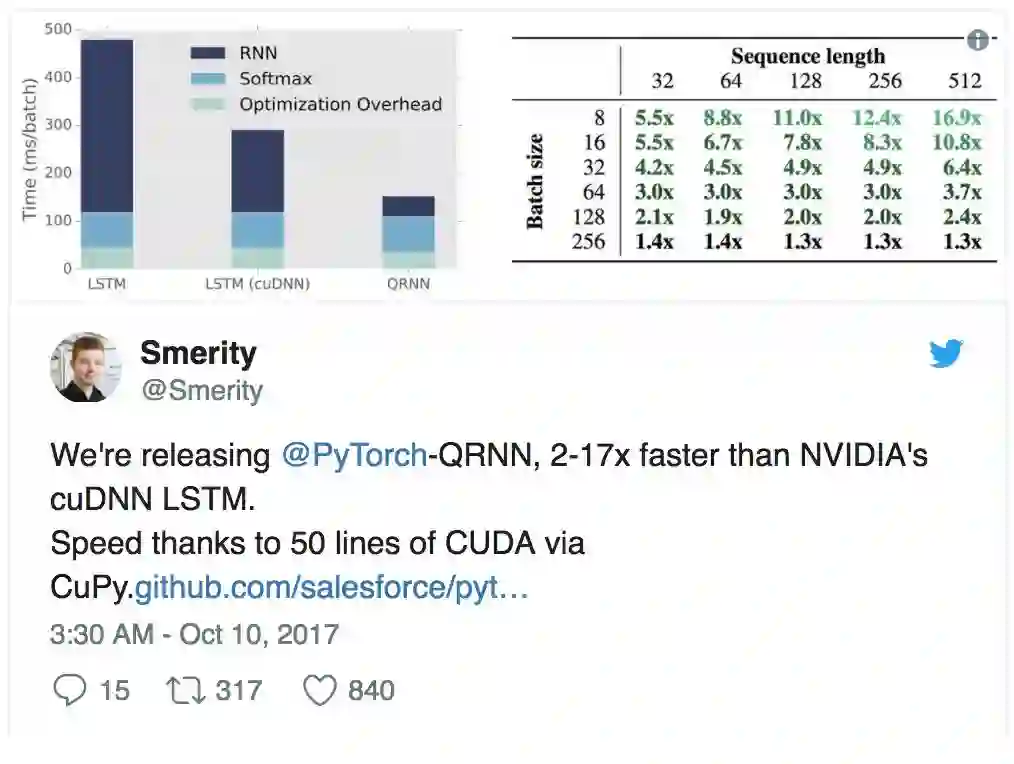
Salesforce 发布了若干个工具包,包括其亮点成果 PyTorch-QRNN,这是一种新型 RNN,相比于 CuDNN 优化的标准 LSTM 可提速 2 到 17 倍。James Bradbury 及其团队是 PyTorch 社区中最活跃和最有吸引力的团队之一。
来自 Uber、Northeaster、Stanford 的研究者围绕着其工具包 Pyro 和 ProbTorch,形成了一个活跃的概率编程社区。他们正在积极开发 torch.distributions 核心工具包。该社区非常活跃,快速发展,我们联合 Fritz Obermeyer、Noah Goodman、Jan-Willem van de Meent、Brooks Paige、Dustin Tran 及其他 22 名参会者在 NIPS 2017 上举办了首次 PyTorch 概率编程会议,共同探讨如何使世界贝叶斯化。

英伟达研究者发布了三个高质量 repo,实现了 pix2pix-HD、Sentiment Neuron 和 FlowNet2。对 PyTorch 中不同数据并行模型的扩展性分析对整个社区都很有益。

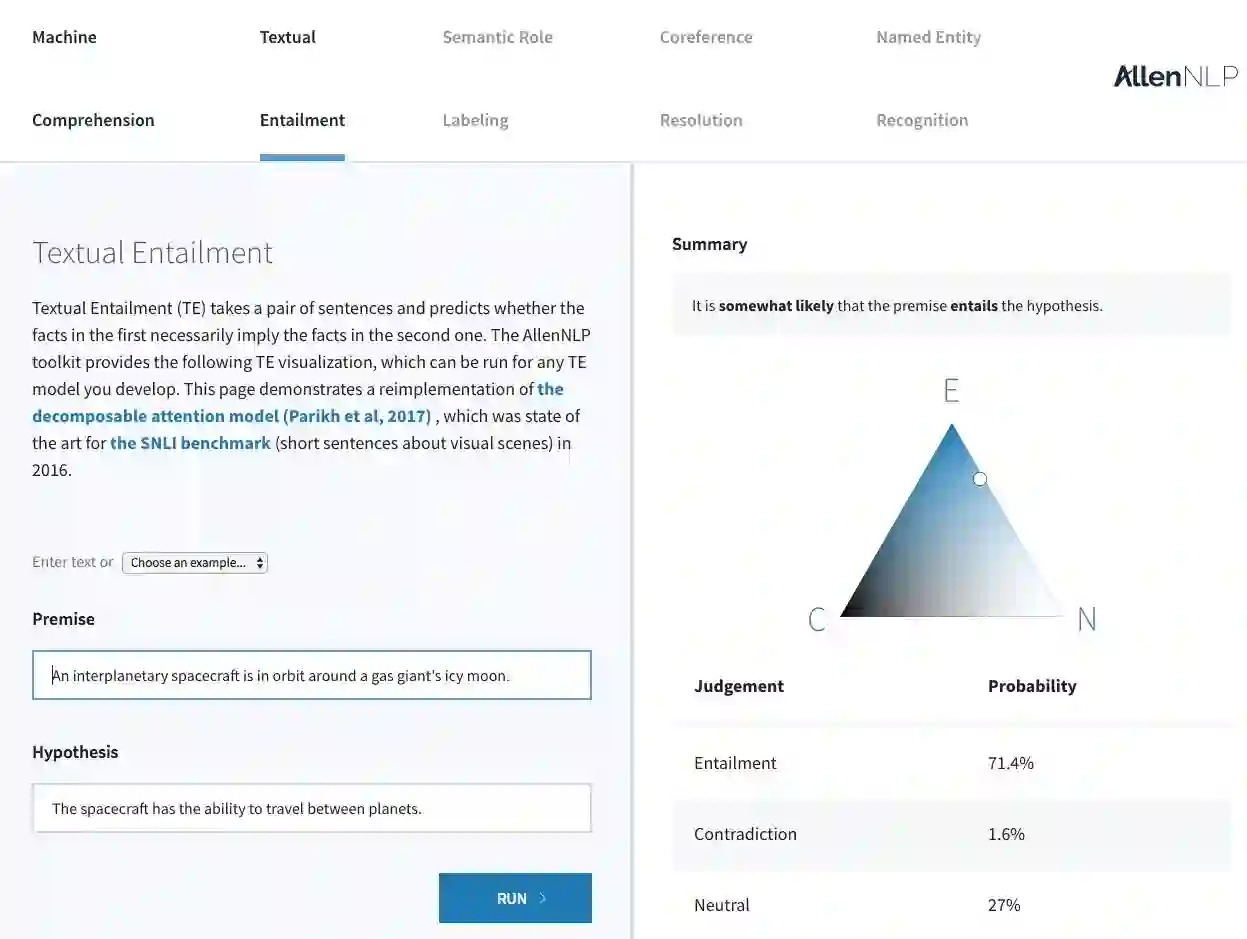
艾伦人工智能研究所发布 AllenNLP,包括多个 NLP 先进模型:标准 NLP 任务的参考实现和易用 web demo。
六月份,我们还首次取得了 Kaggle 竞赛冠军(团队 grt123)。他们获得了 2017 数据科学杯(关于肺癌检测)的冠军,后来公开了其 PyTorch 实现。
在可视化方面,Tzu-Wei Huang 实现了 TensorBoard-PyTorch 插件,Facebook AI Research 发布了与 PyTorch 兼容的 visdom 可视化包。
最后,Facebook AI Research 发布了多个项目,如 ParlAI、fairseq-py、VoiceLoop 和 FaderNetworks,在多个领域中实现了先进的模型和接口数据集。由于空间有限,这里就不将优秀项目一一列出,详细列表可参阅:https://github.com/soumith?tab=stars。
我们还要感谢那些在论坛中积极帮助别人的用户。你们提供了无比珍贵的服务,非常感谢!
指标
从数字上来看:
在 Github 上有 87769 行代码引入 Torch。
在 Github 上有 3983 个 repository 在名字或者描述中提到了 PyTorch。
PyTorch binary 下载量超过 50 万,具体数字是 651916。
在论坛上,有 5400 名用户发表了 21500 条讨论,涉及 5200 个主题。
自发布以来,在 Reddit 上的/r/machinelearning 主题中有 131 条讨论提到了 PyTorch。同期,TensorFlow 被提及的次数为 255。
参见:
研究指标
PyTorch 是一个专注于研究的框架。所以与衡量它的指标包括 PyTorch 在机器学习研究论文中的使用。
在 ICLR 2018 学术会议提交的论文中,有 87 篇提到了 PyTorch,相比之下 TensorFlow 228 篇,Keras 42 篇,Theano 和 Matlab 是 32 篇。
按照月度来看,arXiv 论文提到 PyTorch 框架的有 72 篇,TensorFlow 是 273 篇,Keras 100 篇,Caffe 94 篇,Theano 53 篇。
课程、教程与书籍
我们在发布 PyTorch 的时候,已经准备了很好的 API 文档,但教程有限,只有几个 ipython notebook,虽然有用但还不够。
Sasank Chilamkurthy 承担了改进教程的任务,教程详见:http://pytorch.org/tutorials/。
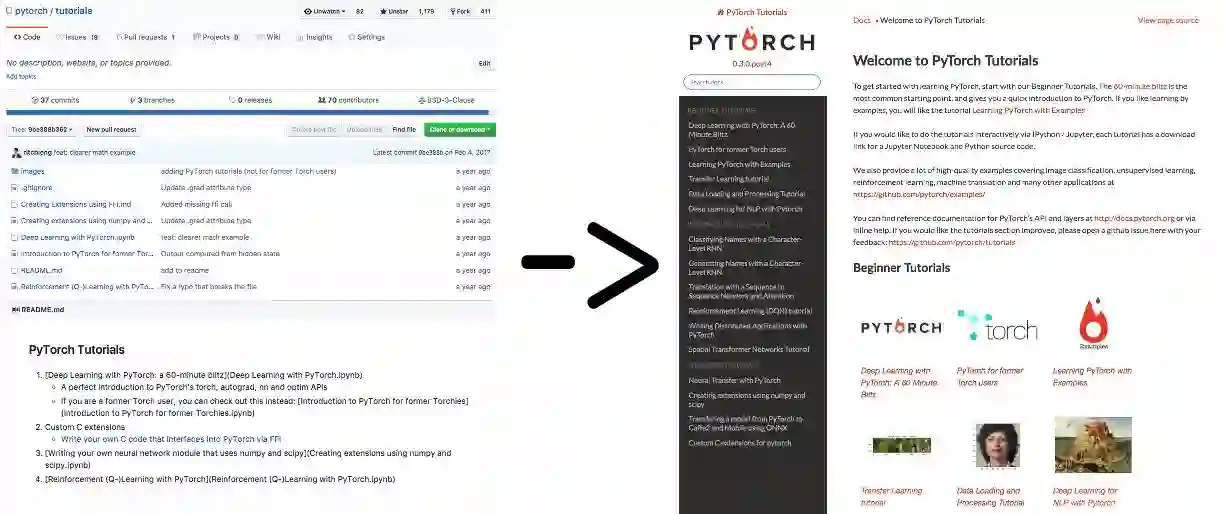
Sean Robertson 和 Justin Johnson 编写了 NLP 领域的全新教程,还有通过示例学习的教程。Yunjey Choi 写了用 30 行或者更少的代码部署大多数模型的教程。每个新教程都帮助用户用不同的学习方法更快地找到适合自己的学习路径。
Goku Mohandas 和 Delip Rao 把正在写的书中的代码做了改变,使用了 PyTorch。
我们看到,一些大学的机器学习课程是使用 PyTorch 作为主要工具讲授的,例如哈佛 CS 287。为了更进一步方便大众学习,我们还看到三个在线课程使用 PyTorch 讲授。
Fast.ai 的「Deep Learning for Coders」是个流行的在线课程。9 月份,Jeremy 和 Rachel 宣布下一个 fast.ai 的课程将几乎全部基于 PyTorch。
Ritchie Ng,在清华、新加坡国立大学都学习过的研究者,推出了名为「Practical Deep Learning with PyTorch」的 Udemy 课程。
来自香港科技大学的 Sung Kim 在 Yotube 上推出了面向普通观众的在线课程「PyTorch Zero to All」。
工程
去年 PyTorch 实现了多个功能,包括 board 上的性能、修复大量 bug 等。去年完成的任务清单详见:https://github.com/pytorch/pytorch/releases。下面是其中的几个亮点:
高阶梯度
随着多篇关于实现梯度罚项的论文的发表,以及二阶梯度法的不断研究发展,高阶梯度成为必需的热门功能。去年 8 月,我们实现了一个通用接口,可使用 n 阶导数,加快支持高阶梯度函数的收敛,截至写作本文时,几乎所有 ops 都支持此界面。
分布式 PyTorch
去年 8 月,我们发布了一个小型分布式包,该包使用非常流行的 MPI 集合(MPI-collective)方法。它有多个后端,如 TCP、MPI、Gloo 和 NCCL2,以支持多种 CPU/GPU 集合操作和用例,这个包整合了 Infiniband 和 RoCE 等分布式技术。分布很难,我们在初始迭代时也有一些 bug。在后续版本中,我们作出了一些改进,使这个包更加稳定,性能也更强。
更接近 NumPy
用户最大的一个需求是他们熟悉的 NumPy 功能。Broadcasting 和 Advanced Indexing 等功能方便、简洁,节约用户的时间。我们实现了这些功能,开始使我们的 API 更接近 NumPy。随着时间的进展,我们希望在合适的地方越来越接近 NumPy 的 API。
性能
性能是一场仍在进行中的战斗,尤其对于想要最大化灵活性的动态框架 PyTorch 而言。去年,从核心 Tensor 库到神经网络算子,我们改善了 PyTorch 在 board 上的性能,能在 board 上更快的编写微优化。
我们添加了专门的 AVX 和 AVX2 内部函数,用于 Tensor 运算;
写更快的 GPU kernel,用于常用的工作负载,如级联和 Softmax;
为多个神经网络算子重写代码,如 nn.Embedding 和组卷积。
PyTorch 在 board 上的开销降低 10x
由于 PyTorch 是动态图框架,我们在训练循环的每次迭代时都要创建一个新图。因此,框架开销必须很低,或者工作负载必须足够大来隐藏框架开销。去年 8 月,DyNet 的作者(Graham Neubig 及其团队)展示了 DyNet 在一些小型 NLP 模型上的速度快于 PyTorch。这是很有意思的一个挑战,我们开始重写 PyTorch 内部构件,将框架开销从 10 微妙/算子降低到 1 微妙。
ATen
重新设计 PyTorch 内部构件的同时,我们也构建了 ATen C++11 库,该库现在主导 PyTorch 所有后端。ATen 具备一个类似 PyTorch Python API 的 API,使之成为便于 Tensor 计算的 C++库。ATen 可由 PyTorch 独立构建和使用。
输出模型用于生产:支持 ONNX 和 JIT 编译器
我们收到的一个普遍请求是将 PyTorch 模型输出到另一个框架。用户使用 PyTorch 进行快速研究,模型完成后,他们想将模型搭载到更大的项目中,而该项目只要求使用 C++。
因此我们构建了 tracer,可将 PyTorch 模型输出为中间表示。用户可使用后续的 tracer 更高效地运行当前的 PyTorch 模型,或将其转换成 ONNX 格式以输出至 Caffe2、MXNet、TensorFlow 等其他框架,或直接搭载至硬件加速库,如 CoreML 或 TensorRT。今年,我们将更多地利用 JIT 编译器提升性能。

原文链接:http://pytorch.org/2018/01/19/a-year-in.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



