机器学习 pipeline 的可视化

极市导读
本文集合了多个有趣的技术,可用于机器学习pipeline不同部分的可视化。>>加入极市CV技术交流群,走在计算机视觉的最前沿
引言
如果有可能使分析中的机器学习部分尽可能直观,那不是很好吗?
技巧
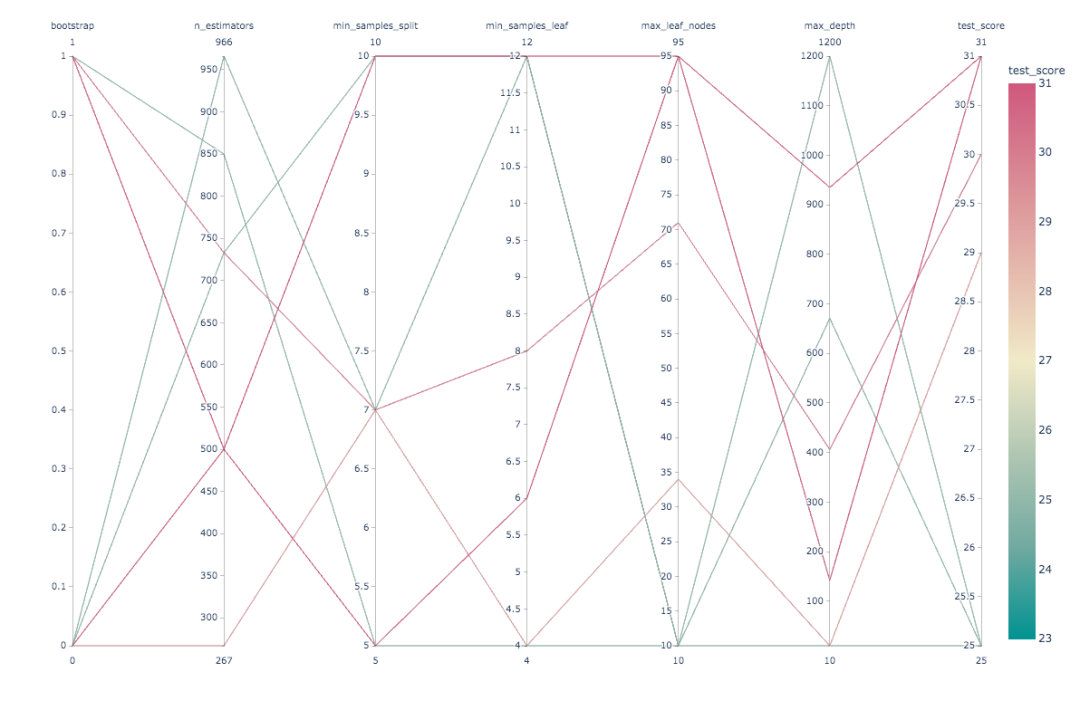
超参数优化
import plotly.express as px
fig = px.parallel_coordinates(df2, color="mean_test_score",
labels=dict(zip(list(df2.columns),
list(['_'.join(i.split('_')[1:]) for i in df2.columns]))),
color_continuous_scale=px.colors.diverging.Tealrose,
color_continuous_midpoint=27)
fig.show()
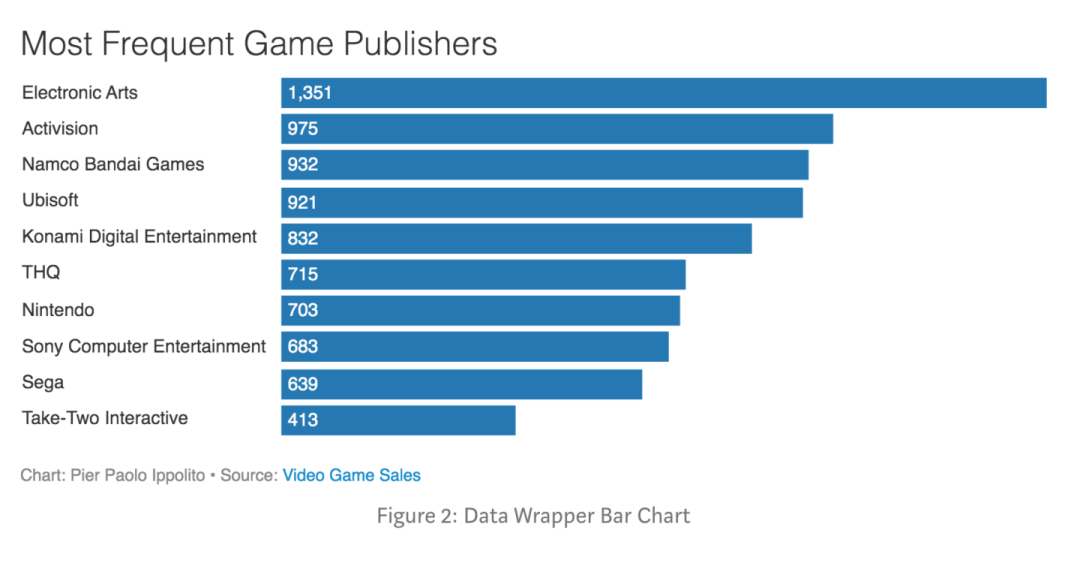
pip install datawrapper
from datawrapper import Datawrapper
dw = Datawrapper(access_token = "TODO")
games_chart = dw.create_chart(title = "Most Frequent Game Publishers", chart_type = 'd3-bars', data = df)
dw.update_description(
games_chart['id'],
source_name = 'Video Game Sales',
source_url = 'https://www.kaggle.com/gregorut/videogamesales',
byline = 'Pier Paolo Ippolito',
)
dw.publish_chart(games_chart['id'])
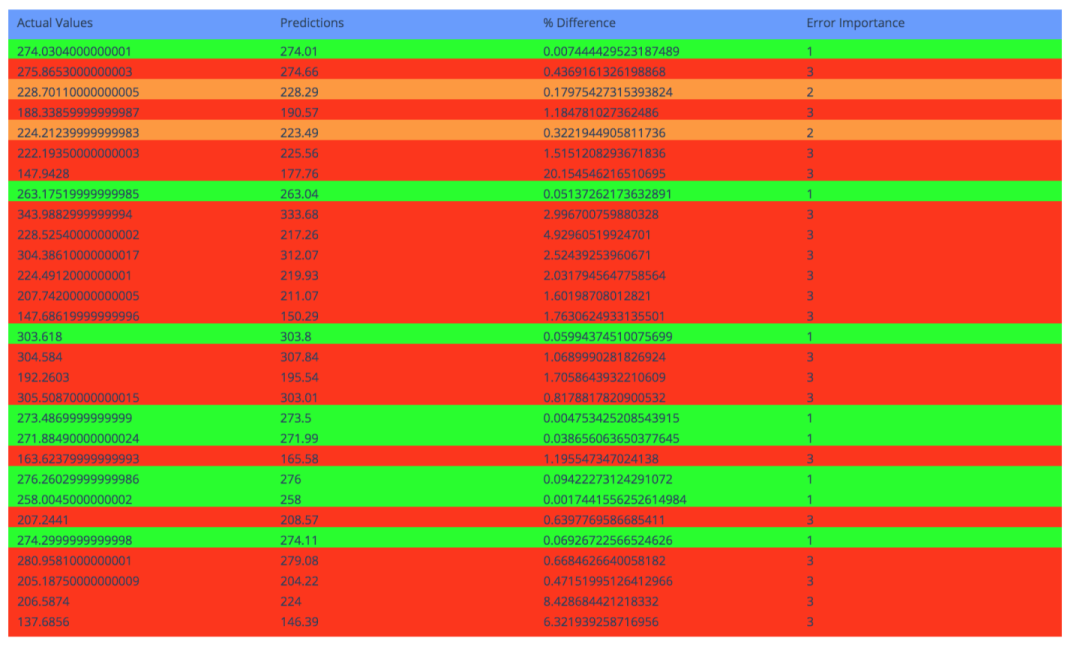
import chart_studio.plotly as py
import plotly.graph_objs as go
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode(connected=True)
import plotly
def predreport(y_pred, Y_Test):
diff = y_pred.flatten() - Y_Test.flatten()
perc = (abs(diff)/y_pred.flatten())*100
priority = []
for i in perc:
if i > 0.4:
priority.append(3)
elif i> 0.1:
priority.append(2)
else:
priority.append(1)
print("Error Importance 1 reported in ", priority.count(1),
"cases\n")
print("Error Importance 2 reported in", priority.count(2),
"cases\n")
print("Error Importance 3 reported in ", priority.count(3),
"cases\n")
colors = ['rgb(102, 153, 255)','rgb(0, 255, 0)',
'rgb(255, 153, 51)', 'rgb(255, 51, 0)']
fig = go.Figure(data=[go.Table(header=
dict(
values=['Actual Values', 'Predictions',
'% Difference', "Error Importance"],
line_color=[np.array(colors)[0]],
fill_color=[np.array(colors)[0]],
align='left'),
cells=dict(
values=[y_pred.flatten(),Y_Test.flatten(),
perc, priority],
line_color=[np.array(colors)[priority]],
fill_color=[np.array(colors)[priority]],
align='left'))])
init_notebook_mode(connected=False)
py.plot(fig, filename = 'Predictions_Table', auto_open=True)
fig.show()
Error Importance 1 reported in 34 cases
Error Importance 2 reported in 13 cases
Error Importance 3 reported in 53 cases
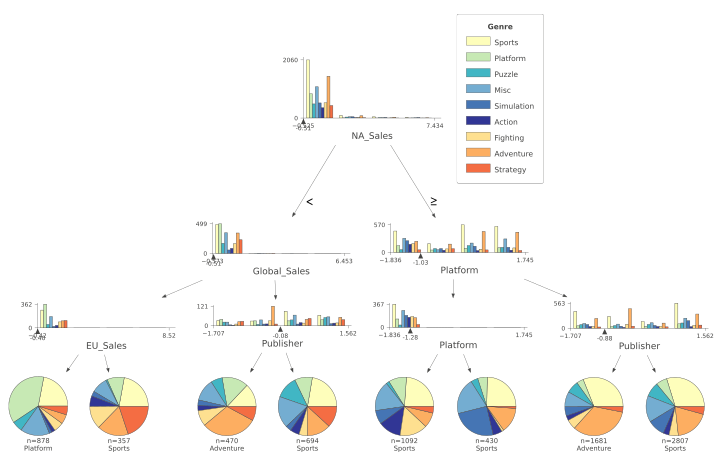
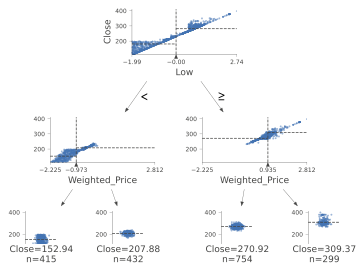
决策树
from dtreeviz.trees import *
viz = dtreeviz(clf,
X_train,
y_train.values,
target_name='Genre',
feature_names=list(X.columns),
class_names=list(labels.unique()),
histtype='bar',
orientation ='TD')
viz
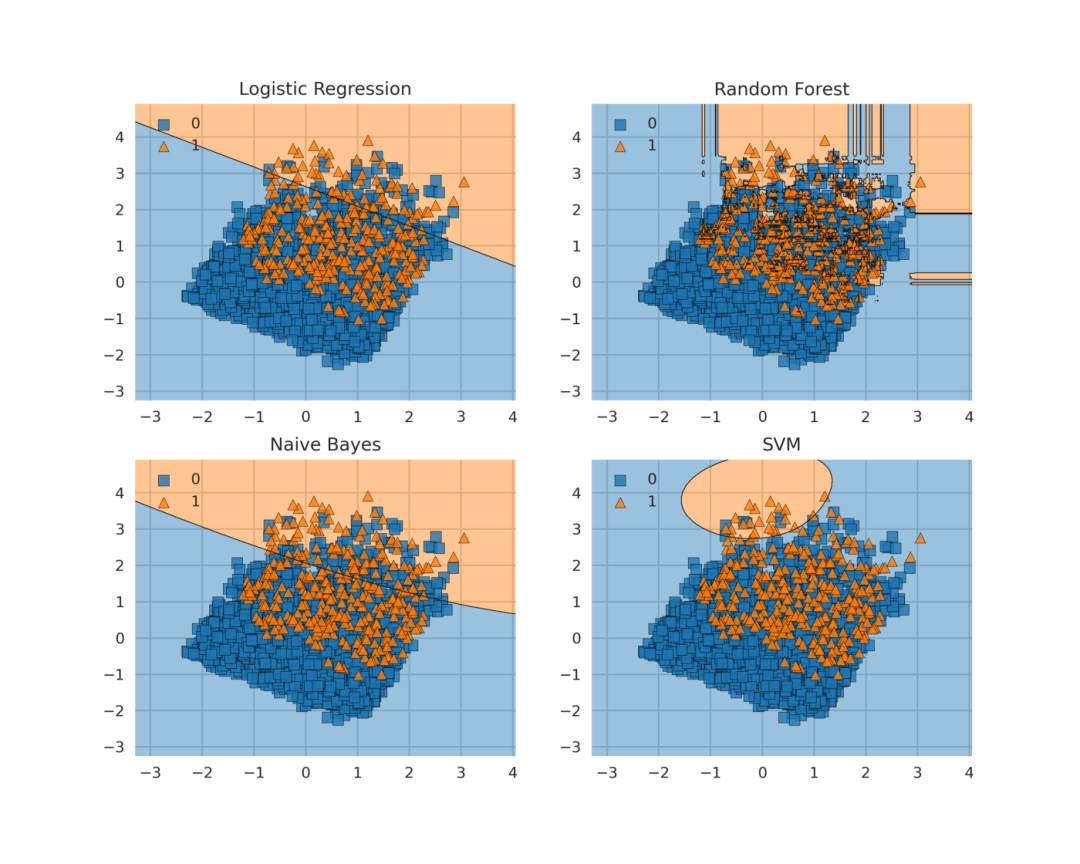
决策边界
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
clf1 = LogisticRegression(random_state=1,
solver='newton-cg',
multi_class='multinomial')
clf2 = RandomForestClassifier(random_state=1, n_estimators=100)
clf3 = GaussianNB()
clf4 = SVC(gamma='auto')
labels = ['Logistic Regression','Random Forest','Naive Bayes','SVM']
for clf, lab, grd in zip([clf1, clf2, clf3, clf4],
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X_Train, Y_Train)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X_Train, Y_Train, clf=clf, legend=2)
plt.title(lab)
plt.show()
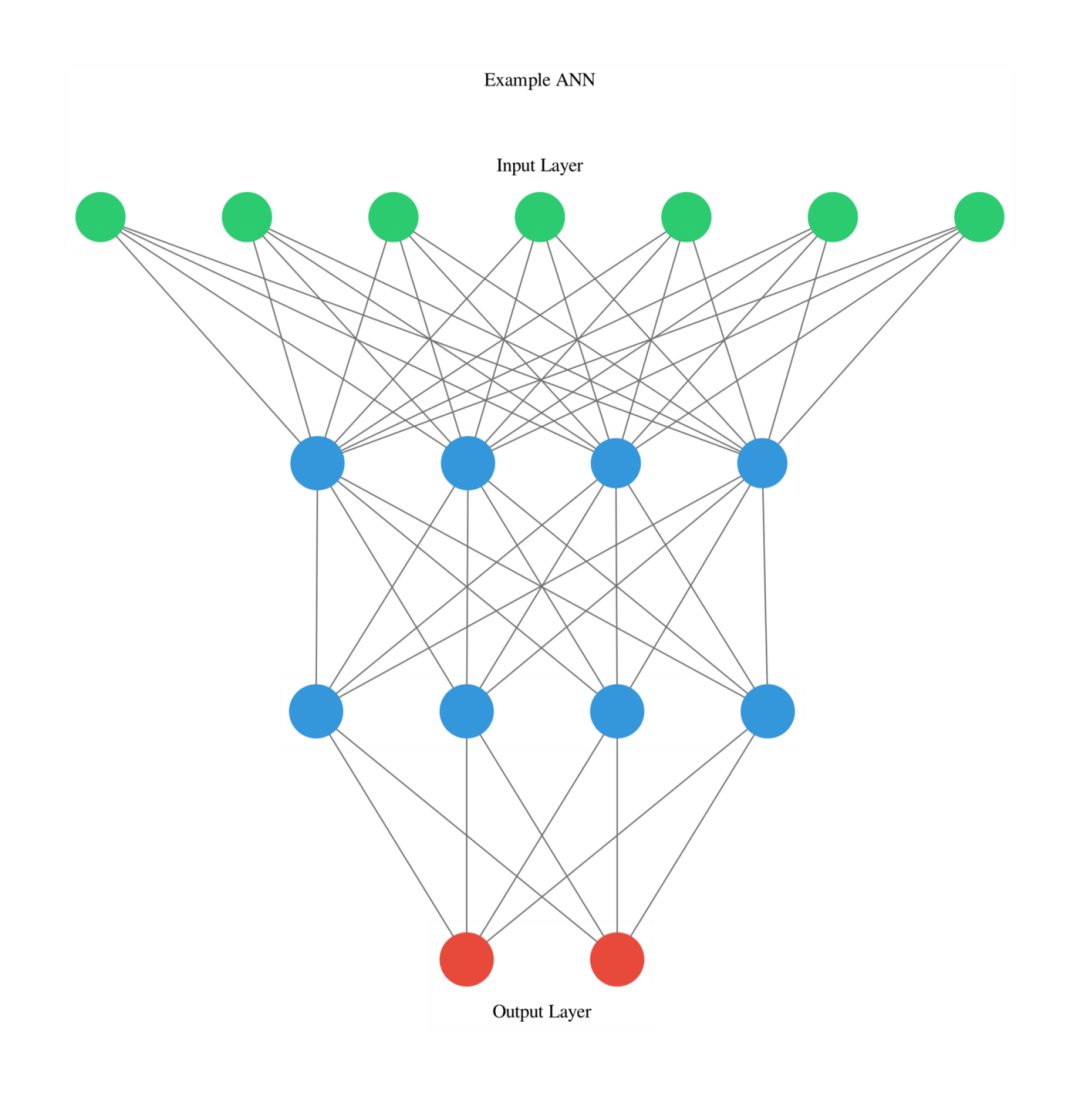
人工神经网络
from keras.models import Sequential
from keras.layers import Dense
from ann_visualizer.visualize import ann_viz
model = Sequential()
model.add(Dense(units=4,activation='relu',
input_dim=7))
model.add(Dense(units=4,activation='sigmoid'))
model.add(Dense(units=2,activation='relu'))
ann_viz(model, view=True, filename="example", title="Example ANN")
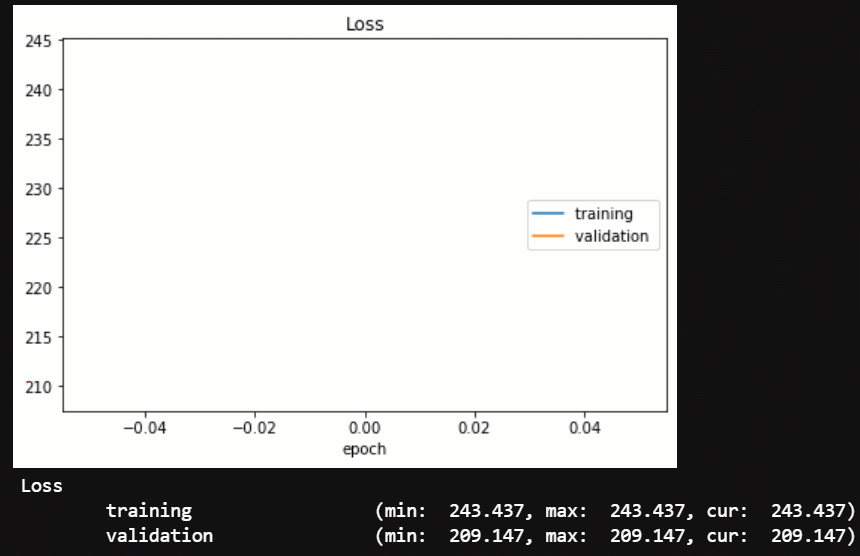
from livelossplot import PlotLosses
liveloss = PlotLosses()
for epoch in range(epochs):
logs = {}
for phase in ['train', 'val']:
losses = []
if phase == 'train':
model.train()
else:
model.eval()
for i, (inp, _) in enumerate(dataloaders[phase]):
out, z_mu, z_var = model(inp)
rec=F.binary_cross_entropy(out,inp,reduction='sum')/
inp.shape[0]
kl=-0.5*torch.mean(1+z_var-z_mu.pow(2)-torch.exp(z_mu))
loss = rec + kl
losses.append(loss.item())
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
prefix = ''
if phase == 'val':
prefix = 'val_'
logs[prefix + 'loss'] = np.mean(losses)
liveloss.update(logs)
liveloss.send()
变分自动编码器
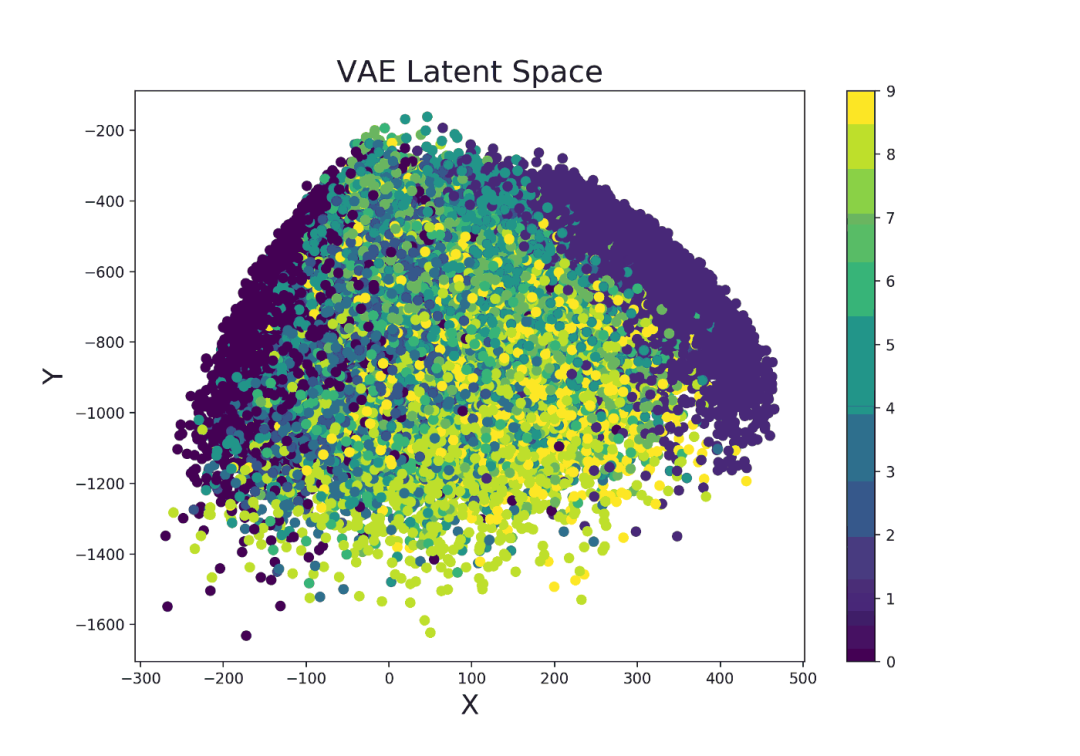
def latent_space(model, train_set, it=''):
x_latent = model.enc(train_set.data.float())
plt.figure(figsize=(10, 7))
plt.scatter(x_latent[0][:,0].detach().numpy(),
x_latent[1][:,1].detach().numpy(),
c=train_set.targets)
plt.colorbar()
plt.title("VAE Latent Space", fontsize=20)
plt.xlabel("X", fontsize=18)
plt.ylabel("Y", fontsize=18)
plt.savefig('VAE_space'+str(it)+'.png', format='png', dpi=200)
plt.show()
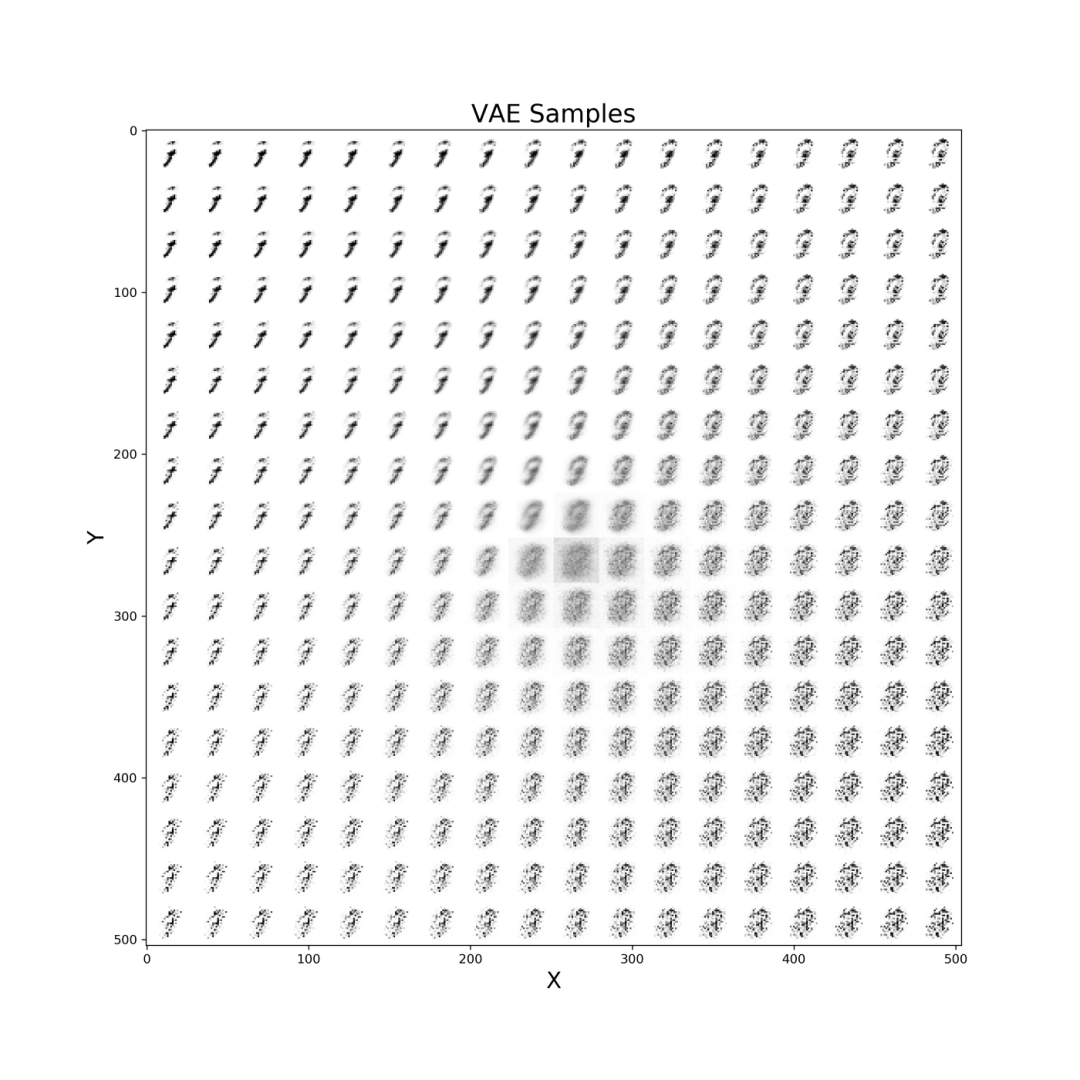
def manifold(model, it='', n=18, size=28):
result = torch.zeros((size * n, size * n))
s, s2 = torch.linspace(-7, 7, n), torch.linspace(7, -7, n)
grid_x, grid_y = torch.std(s)*s, torch.std(s2)*s2
for i, y_ex in enumerate(grid_x):
for j, x_ex in enumerate(grid_y):
z_sample = torch.repeat_interleave(torch.tensor([
[]]),repeats=batch_size, dim=0)
x_dec = model.dec(z_sample)
element = x_dec[0].reshape(size, size).detach()
result[i * size: (i + 1) * size,
j * size: (j + 1) * size] = element
plt.figure(figsize=(12, 12))
plt.title("VAE Samples", fontsize=20)
plt.xlabel("X", fontsize=18)
plt.ylabel("Y", fontsize=18)
plt.imshow(result, cmap='Greys')
plt.savefig('VAE'+str(it)+'.png', format='png', dpi=300)
plt.show()
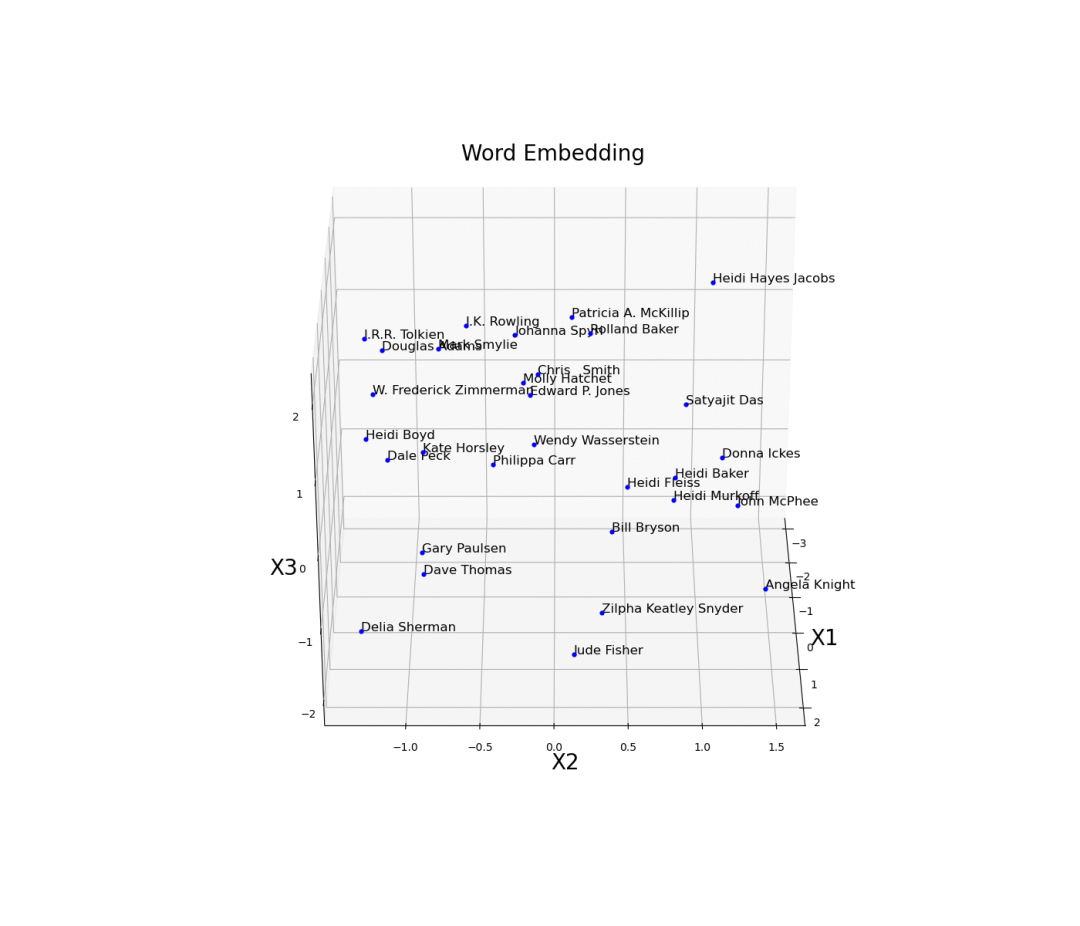
Word Embeddings
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import axes3d, Axes3D
embedding_weights=pd.DataFrame(model.embed.weight.detach().numpy())
embedding_weights.columns = ['X1','X2','X3']
fig = plt.figure(num=None, figsize=(14, 12), dpi=80,
facecolor='w', edgecolor='k')
ax = plt.axes(projection='3d')
for index, (x, y, z) in enumerate(zip(embedding_weights['X1'],
embedding_weights['X2'],
embedding_weights['X3'])):
ax.scatter(x, y, z, color='b', s=12)
ax.text(x, y, z, str(df.authors[index]), size=12,
zorder=2.5, color='k')
ax.set_title("Word Embedding", fontsize=20)
ax.set_xlabel("X1", fontsize=20)
ax.set_ylabel("X2", fontsize=20)
ax.set_zlabel("X3", fontsize=20)
plt.show()
from wordcloud import WordCloud
d = {}
for x, a in zip(df.authors.value_counts(),
df.authors.value_counts().index):
d[a] = x
wordcloud = WordCloud()
wordcloud.generate_from_frequencies(frequencies=d)
plt.figure(num=None, figsize=(12, 10), dpi=80, facecolor='w',
edgecolor='k')
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.title("Word Cloud", fontsize=20)
plt.show()

可解释的人工智能
卷积神经网络滤波器和特征图的研究
图网络
基于贝叶斯的模型
因果推理应用于机器学习
本地/全局代理模型
引入局部可解释模型-无关解释(LIME)和 Shapley 值
总结
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!




登录查看更多
相关内容
Arxiv
0+阅读 · 2020年11月30日
Arxiv
0+阅读 · 2020年11月30日
Arxiv
0+阅读 · 2020年11月29日
Arxiv
0+阅读 · 2020年11月28日
Arxiv
0+阅读 · 2020年11月28日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年11月30日
Arxiv
0+阅读 · 2020年11月30日
Arxiv
0+阅读 · 2020年11月29日
Arxiv
0+阅读 · 2020年11月28日
Arxiv
0+阅读 · 2020年11月28日