76分钟训练BERT!谷歌大脑新型优化器LAMB加速大批量训练
选自arXiv
作者:Yang You、Jing Li等
机器之心编辑部
去年,谷歌发布了基于双向 Transformer 的大规模预训练语言模型 BERT 并开源。该模型参数量非常大——3 亿,训练时间也很长。近日,来自谷歌大脑的研究者提出了一种新型优化器 LAMB,有效降低 BERT 预训练时间,76 分钟即可完成 BERT 预训练!
尽管 BERT效果惊人,但它所需的计算量非常大,原作者在论文中也表示每次只能预测 15% 的词,因此模型收敛得非常慢。如果我们想保留这种 Mask 机制,那么就需要寻找另一种加速方法了。
当时,BERT 的作者在 Reddit 上也表示预训练的计算量非常大,Jacob 说:「OpenAI 的 Transformer 有 12 层、768 个隐藏单元,他们使用 8 块 P100 在 8 亿词量的数据集上训练 40 个 Epoch 需要一个月,而 BERT-Large 模型有 24 层、2014 个隐藏单元,它们在有 33 亿词量的数据集上需要训练 40 个 Epoch,因此在 8 块 P100 上可能需要 1 年?16 Cloud TPU 已经是非常大的计算力了。」
而在谷歌大脑的这篇新论文中,研究者提出新型优化器 LAMB,通过使用 65536/32768 的批量大小,他们只需要 8599 次迭代、76 分钟就能完成 BERT 预训练。总体而言,相比基线 BERT-Large 用 16 块 TPU 芯片,LAMB 训练 BERT-Large 用了一个 TPU v3 Pod(1024 块 TPU 芯片),因此时间也由 3 天降低为 76 分钟。
不过在 BERT 原论文中,训练 BERT-Large 使用了 64 块 TPU 芯片(16 Cloud TPU),它需要花四天时间完成训练。
论文:Reducing BERT Pre-Training Time from 3 Days to 76 Minutes

论文地址:https://arxiv.org/abs/1904.00962
摘要:大批量训练是加速大型分布式系统中深度神经网络训练的关键。但是,大批量训练难度很大,因为它会产生泛化差距(generalization gap),直接优化通常会导致测试集准确率受损。BERT [4] 是当前最优的深度学习模型,它基于用于语言理解的深度双向 transformer 而构建。当我们扩展批量大小时(比如批量大小超过 8192),之前的大批量训练技术在 BERT 上的执行性能并不好。BERT 预训练需要大量时间(使用 16 个 TPUv3 训练 3 天)。
为了解决这个问题,来自谷歌大脑的研究者提出了一种新型优化器 LAMB,可在不损害准确率的情况下将批量大小扩展至 65536。LAMB 是一款通用优化器,它适用于小批量和大批量,且除了学习率以外其他超参数均无需调整。基线 BERT-Large 模型的预训练需要 100 万次迭代,而 LAMB 使用 65536/32768 的批量大小,仅需 8599 次迭代。研究者将批量大小扩展到 TPUv3 pod 的内存极限,在 76 分钟内完成了 BERT 的训练。
具体来讲,LAMB 优化器支持自适应元素级更新(adaptive element-wise updating)和准确的逐层修正(layer-wise correction)。LAMB 可将 BERT 预训练的批量大小扩展到 64K,且不会造成准确率损失。BERT 预训练包括两个阶段:1)前 9/10 的训练 epoch 使用 128 的序列长度,2)最后 1/10 的训练 epoch 使用 512 的序列长度。
基线 BERT-Large 模型的预训练需要 100 万次迭代,研究者仅使用 8599 次迭代就完成了预训练,将训练时间从 3 天缩短到 76 分钟。该研究使用的训练批量大小接近 TPUv3 pod 的内存极限。LAMB 优化器可以将批量大小扩展到 128k 甚至更大,由于硬件限制,研究者在序列长度为 512 时使用的批量大小为 32768,在序列长度为 128 时使用的批量大小为 65536。该论文中的 BERT 模型均指 BERT-Large。为公平起见,研究中所有实验均运行同样数量的 epoch(即固定数量的浮点运算)。实验结果见下表。
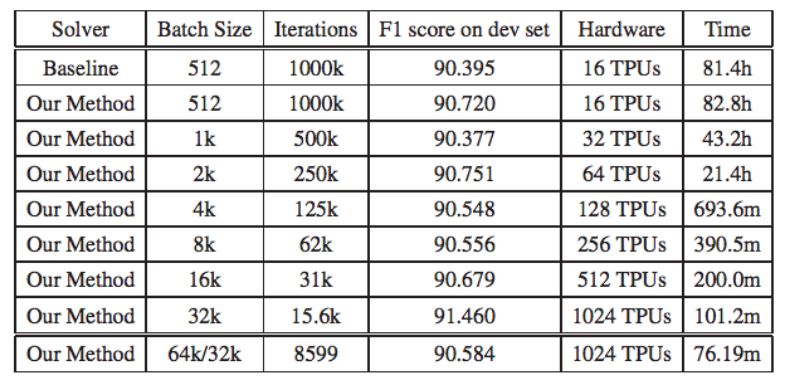
表 1:该研究使用 SQuAD-v1 的 F1 分数作为准确率度量。
在上表中,基线 F1 分数来自于 BERT 开源 GitHub 中 BERT-Large 预训练模型的对应分数。实验所用硬件为 TPUv3,实验设置与基线 BERT-Large 相同:前 9/10 的训练 epoch 使用 128 的序列长度,最后 1/10 的训练 epoch 使用 512 的序列长度。所有实验均运行同样数量的 epoch。
LAMB (Layer-wise Adaptive Moments optimizer for Batch training)
BERT 基线模型的训练使用 Adam with weight decay(Adam 优化器的变体)作为优化器 [15]。另一个成功用于大批量卷积神经网络训练的自适应优化器是 LARS [21]。这些优化器启发了研究者提出用于大批量 BERT 训练的新型优化器 LAMB。LAMB 优化器详见算法 1。

实验
常规训练
TPU 是强大的浮点运算计算硬件。研究者在所有实验中均使用 TPUv3。每个 TPUv3 pod 拥有 1024 个芯片,可提供超过 100 petaflops 的混合精度计算。实验结果见表 1。基线模型预训练过程中使用了 Wikipedia 和 BooksCorpus 数据集。研究者使用与开源 BERT 模型相同的数据集进行预训练,即包含 2.5B 单词的 Wikipedia 数据集和包含 800M 单词的 BooksCorpus 数据集。
BERT 作者首先以 128 的序列长度进行 900k 次迭代,然后以 512 的序列长度进行 100k 次迭代。在 16 块 TPUv3 上训练的总时间大约为 3 天。该研究使用 SQuAD-v1 的 F1 分数作为准确率度量。较高的 F1 分数意味着较好的准确率。研究者下载了 BERT 开源项目中提供的预训练模型。使用 BERT 作者提供的脚本,基线模型得到了 90.395 的 F1 分数。
该研究中,研究者使用 BERT 作者提供的数据集和基线模型,仅改变了优化器。使用新型优化器 LAMB 后,研究者以 32768 的批量大小进行了 15625 次迭代,得到了 91.460 的 F1 分数(用于序列长度 128 的迭代有 14063 次,用于序列长度 512 的迭代有 1562 次)。研究者将 BERT 训练时间从 3 天缩短到大约 100 分钟。
该研究取得了 76.7% 的弱可扩展性效率(weak scaling efficiency)。研究者在 TPU Pod 上使用了分布式训练的同步数据并行化,因此梯度迁移会产生通信开销。这些梯度与训练后的模型大小一样。在 ImageNet 数据集上训练 ResNet-50 时的弱可扩展性效率可达到 90+%,因为 ResNet-50 比 BERT 的参数少得多(25 million vs 300 million)。LAMB 优化器无需用户调整超参数,用户只需输入学习率即可。
混合批次训练(Mixed-Batch Training)
如前所述,BERT 预训练主要分为两部分,1)前面 9/10 的 Epoch 使用 128 的序列长度;2)最后 1/10 的 Epoch 使用 512 的序列长度进行训练。对于第二阶段而言,因为内存限制,TPUv3 Pod 上最大的批量大小为 32768,因此第二阶段使用的批大小为 32768。对于第一阶段,受限于内存,TPUv3 Pod 上最大的批量大小为 131072。然而,研究者将批大小从 65536 增加到 131072 时,并没有发现明显的加速,因此研究者将阶段 1 的批大小定为 65536。
此前,也有其它研究者讨论了混合批次训练,然而他们是在训练中增大批量大小;而本研究是降低批大小,这样他们能从开始到结束充分利用硬件资源。增大批大小能起到 warm-up 初始训练和稳定最优化过程的效果,但是降低批大小可能会带来最优化过程的紊乱,并导致训练的不收敛。
在研究者的实验中,他们发现有一些技术能稳定第二阶段的最优化过程。因为这两阶段会切换到不同的最优化问题,因此有必要重新 warm-up 最优化过程。研究者没有在第二阶段进行学习率衰减,而是将学习率从零开始增加(re-warm-up)。和第一阶段一样,研究者在 re-warm-up 之后执行学习率衰减。因此,研究者能够以 8599 次迭代完成 BERT 训练,且仅用时 76 分钟,达到了 101.8% 的弱可扩展性效率。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




