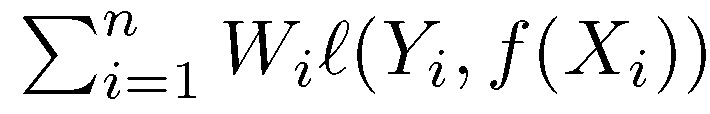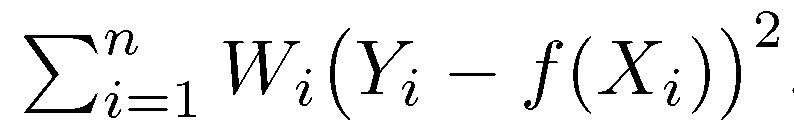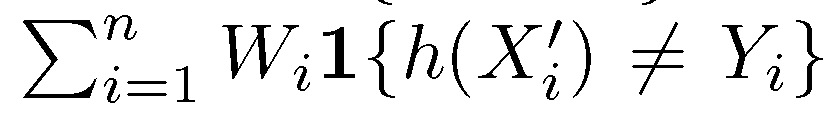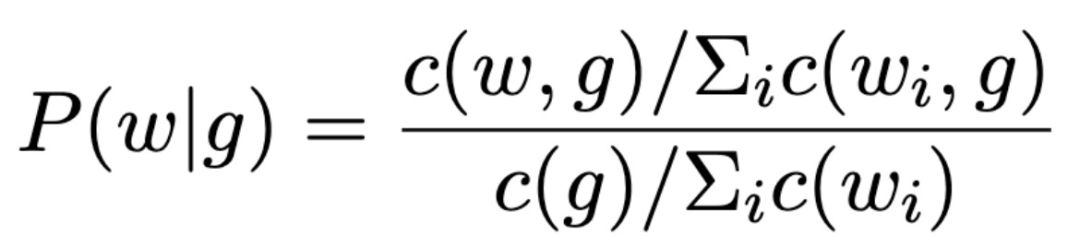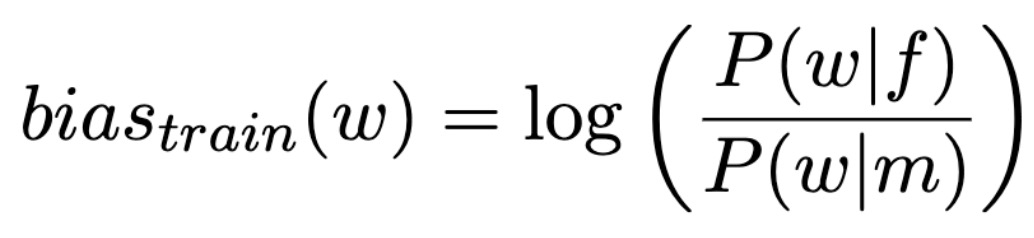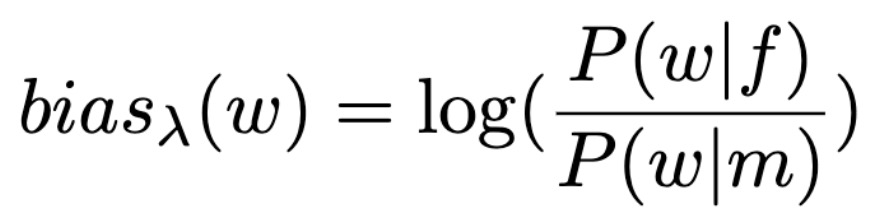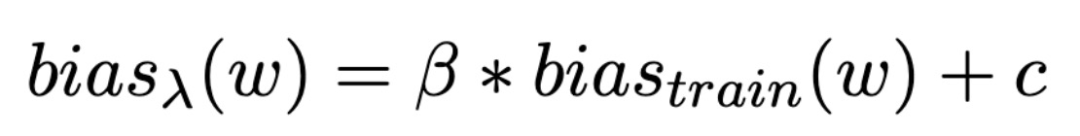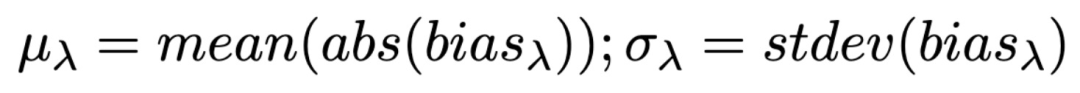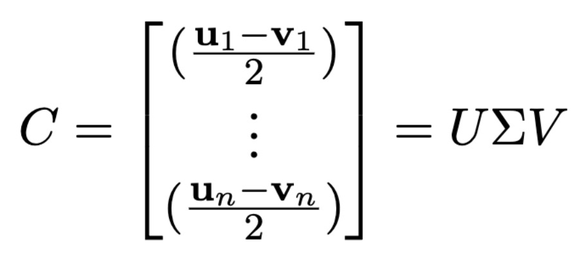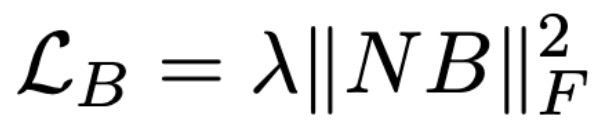机器之心分析师网络
分析师:仵冀颍
编辑: Joni Zhong
本文讨论的是机器学习中的公平公正问题(Bias and Fairness in Machine Learning),那么,究竟什么是机器学习中的公平公正呢?
随着人工智能系统和应用程序在我们日常生活中的广泛应用,人工智能已经成为了辅助人们决策的重要工具,例如,使用推荐系统算法做出电影推荐、购买产品推荐等,使用预测和分析系统用于贷款申请、约会和雇佣等高风险决策。美国法院使用了一款人工智能软件—「选择性制裁罪犯管理档案」(Correctional Offender Management Profiling for Alternative Sanctions,COMPAS),用于预测一个人再次犯罪的风险,辅助法官决定是释放罪犯,还是把罪犯关进监狱。对该软件的一项调查发现了对非洲裔美国人的一种偏见:相较于白人罪犯,COMPAS 更有可能给非洲裔美国人罪犯打出较高的潜在风险分数,从而不予以释放 [1]。
有偏的训练数据集一般被认为是影响机器学习公平公正的重要因素之一。大多数机器学习模型都是通过在大型有标记数据集上训练得到的。例如,在自然语言处理中,标准的算法是在包含数十亿单词的语料库上训练的。研究人员通常通过抓取网站 (如谷歌图像和谷歌新闻)、使用特定的查询术语,或通过聚合来自维基百科 (Wikipedia) 等来源的易于访问的信息来构建此类数据集。然后,由研究生或通过 Amazon Mechanical Turk 等众包平台对这些数据集进行注释和标记。
在医学领域,由于医疗数据的生成和标记成本非常高,机器学习特别容易受到有偏见训练数据集的影响。去年,研究人员利用深度学习从照片中识别皮肤癌。他们对 129,450 张图像的数据集进行训练,其中 60% 是从谷歌图像中提取的。在这个数据集中只有不到 5% 的图像是深肤色的个体,而且该算法没有在深肤色的人身上进行测试。因此,将该深度学习分类器应用在不同的种群中可能会存在巨大的差异。
用于图像分类的深度神经网络通常是在 ImageNet 上训练的,ImageNet 是一套包含 1400 多万张标记图像的集合。ImageNet 中 45% 以上的数据来自美国,而美国人口仅占世界人口的 4%。与此形成对比的是,尽管中国和印度的人口占世界人口的 36%,但两国在 ImageNet 的数据中只占 3%。在这样的数据集中训练得到的计算机视觉模型,把传统的美国新娘穿着白色衣服的照片标记为「新娘」、「服装」、「女人」、「婚礼」,而把印度北部新娘的照片标记为「行为艺术」和「服装」。图 1 是 Nature 上一篇报道中给出的一幅图片,在有偏数据集上训练的算法通常只将左侧的图片识别为新娘 [2]。
图 1. 在有偏数据集上训练的算法通常只将左手图像识别为新娘 [2]
影响机器学习公平公正的另外一个重要因素是机器学习算法本身。一个经典机器学习的算法总是试图最大限度地提高在训练数据集中的总体预测精度。如果一组特定的个体在训练数据集中出现的频率高于其他个体,那么算法将会针对这些个体进行优化,从而提高算法整体准确度。在实验环境下,研究人员使用测试数据集进行评估以验证算法的有效性,但是测试集通常是原始训练数据集的随机子样本,因此可能包含相同的偏见。
为了确保机器学习的公平公正,研究人员认为主要有三种途径:一是提高用于训练机器学习算法的数据质量,公平、广泛的收集不同来源的数据,使用标准化的元数据系统地标注训练数据集的内容。二是改进机器学习算法本身。整合约束条件,从本质上使得机器学习算法在不同的子群体和相似的个体之间实现公平的性能;改变学习算法,减少对敏感属性的依赖,比如种族、性别、收入——以及任何与这些属性相关的信息。三是使用机器学习本身来识别和量化算法和数据中的偏见,即开展人工智能审计,其中审计人员是一个系统地探测原始机器学习模型的算法,以识别模型和训练数据中的偏见。
本文重点谈论机器学习中算法的公平公正问题,我们选择了 ICML 2019 的三篇文章,分别针对机器学习领域中的图嵌入问题、回归问题,以及自然语言处理领域中的语言模型问题展开了讨论。
1、Compositional Fairness Constraints for Graph Embeddings
https://arxiv.org/pdf/1905.10674v1.pdf
本文是 Facebook 发表在 ICML 2019 中的一篇文章,针对现有的图嵌入(Graph Embedding)算法无法处理公平约束的问题,例如确保所学习的表示与某些属性 (如年龄或性别) 不相关,通过引入一个对抗框架来对图嵌入实施公平性约束。本文的研究内容属于 (社会) 图嵌入和算法公平性研究的交叉领域。
学习图中节点的低维嵌入是目前最先进的应用于预测和推荐系统的方法。在实际应用中,特别是涉及到社交图的应用中,需要有效控制学习到的节点嵌入中所包含的信息。以推荐系统为例,人们希望能够保证推荐是公平的而不依赖于用户的种族或性别,此外,也希望能够在不暴露自身属性的前提下学习节点嵌入表示以保证隐私。本文的工作聚焦于对社会图(Social Graph)加入不变性约束的可行性,即生成对特定敏感信息 (例如,年龄或性别) 不变的图嵌入。首先训练得到一组「过滤器」,以防止对抗式的甄别者将敏感信息与过滤后的嵌入信息进行分类。然后,将过滤器以不同的方式组合在一起,灵活生成对任何敏感属性子集不变的嵌入。方法的整体结构见图 2。
![]() 图 2. 方法整体结构
早期关于在社会类应用中增加强制不变性约束 (或「公平性」) 的工作通常只涉及一个敏感属性的情况,但是实际应用中通常社会图嵌入会涉及到多个属性。在极端情况下,可能希望不只是节点,甚至是图中的边(edge)也具备公平性,例如,一个社交网络平台上的用户可能希望该平台的推荐系统忽略他们与某个其他用户是朋友,或者他们参与了某个特定内容的事实。本文提出的方法通过学习得到一组对抗性过滤器,从而删除关于特定敏感属性的信息。
首先,考虑嵌入一个异质或多关系 (社会) 图 G = (V, e),G 包含有向边三元组 e= < u,r, v >,其中 u, v∈V 为节点,r∈R 表示节点间的关系。假定每个节点都属于一个特定的类别,节点间的关系受到节点类型的约束。基于图的关系预测任务描述如下:ξ_train 表示训练边集合,定义负边集合如下:
负边集合表示未在真实图 G 中出现的边的集合。给定ξ_train,目标是学习得到评分函数 s 以满足:
换句话说,学习得到的评分函数在理想情况下应该对任何真边缘评分高于任何假边缘。
图嵌入(Graph Embedding)的任务目标是通过学习一个映射函数 ENC 来完成关系预测任务,即将节点 v 映射为节点嵌入 z_v=ENC(v)。此时评分函数为:
评分函数的含义为:给定两个节点嵌入 z_u ∈ R.^d 和 z_v∈ R.^d,以及它们之间的关系 r ∈ R,评分函数 s 表示边 e=<u,r,v> 在图中存在的概率 ( s∈ R)。通常来讲,基于图嵌入模型的方法主要是认为两个节点嵌入间的距离能够表征两个节点间存在边的可能性。本文利用噪声对比估计等破坏分布的对比学习方法来优化评分函数,目的是最大化真实边(正样本)与虚假边(负样本)对比的概率。其中,边(e_batch ⊆ e_train)的损失函数计算为:
考虑公平性的处理,对一个节点类型,假设属于该类型的全部节点都包含有 K 组敏感属性,那么对图嵌入模型进行公平性处理的任务就是确保所学习的节点嵌入 (z_u) 在这些敏感属性方面不存在偏见或不公平。
本文给出了一个简单的以用户为中心的社会图嵌入场景。以性别为敏感属性、电影推荐为关系预测任务的例子,具体任务场景如下:如果给用户一个按钮,上面写着「推荐电影时请忽略我的性别」,那么按下这个按钮后,用户希望从系统中得到什么?很显然,用户 u 的目的是系统能够不考虑他们的性别公平地向他(她)推荐电影,即如下式:
其中 s(e) = s(<z_u, r, z_v>),a_u 为敏感属性。如果直接处理上式,我们能够发现一个明显的问题,即对于每一个节点都需要对它的全部边(可能是数以百万计)进行评分。假设认为 s(e) 仅由 u 决定(忽略掉节点 v 的影响),则可以通过实施表征不变性来保证上式对于所有边缘预测的独立性:
此时满足互信息(mutual Information):I(z_u,a_u)=0。推广到多个敏感属性 S⊆ {1,...,K}:
上式相当于对 S 个不同敏感属性的 S 独立不变性约束的假设。针对本文所讨论的应用场景,S 不是固定不变的。对于不同的用户来说,他们所认为的敏感属性可能不同(年龄,职业,性别等等)。基于上述分析,本文在上式中引入一种对抗性损失和一种「过滤」嵌入,从而对节点嵌入施加表征不变性约束。
首先,将 ENC 嵌入函数泛化,以选择性地「过滤」掉有关某些敏感属性的信息。对每一个敏感属性 k∈{1,...,K},定义一个过滤函数 f_k,通过训练 f_k 能够去除掉与敏感属性 k 有关系的信息。为了保证节点嵌入的不变性,本文使用复合编码器组合过滤后的嵌入:
在组合映射函数(C-ENC)的训练迭代过程中,每轮迭代都通过采样二进制掩码来确定集合 S。本文将二进制掩码采样为一个固定概率 p=0.5 的伯努利序列。在训练过程中,随机采样得到的二进制掩码能够使得模型产生不同敏感性属性组合的不变嵌入,从而实现在推理过程中推广到未知的组合。
本文引入对抗正则项训练复合编码器 Dk。为每个敏感属性 k 定义一个分类器 D_k,目的是通过节点嵌入预测第 k 个敏感属性 D_k : R^d × A_k → [0, 1],其中,D_k 的概率区间为 [0,1]。给定边预测损失函数 L_edge,对抗正则化损失函数为:
其中,λ控制对抗正则项的强度。为了在小批量设置的情况下优化该损失,本文定义两种交替执行的随机梯度下降更新方法:(1)T 小批量更新:基于 C-ENC(Dk 恒定不变)优化 L(e);(2)T』小批量更新:基于 Dk(C-ENC 恒定不变)优化 L(e)。
本文在三个数据库中进行实验,Freebase15k-237、MovieLens-1M,以及从 Reddit 中整理得到的边缘预测数据库。三个库的统计信息如表 1 所示(具体包括全部节点数量(|v|),带有敏感属性的节点数量(|T*|),敏感属性的数目及其类型和图中边缘的总数):
FREEBASE15K-237 是一个标准的知识基准库 [9],本文使用该库评估对抗正规化的影响,在完成标准的知识库任务的同时,保持实体嵌入与「敏感」属性标签的不变性。在本库中,确定三个常见的属性标签:/award/award_nominee,作为敏感属性。
在实验过程中,本文采用联合训练主模型和对抗框架的方式,但在测试不变性时,本文训练一个新分类器 (与鉴别器具有相同的能力) 从所学习的嵌入中预测敏感属性。此外,在这些实验中,本文依赖于两个基线:首先,对比不包含任何不变性约束的基线方法,即λ= 0。其次,与一种非复合对抗的基线方法进行对比,即分别训练 K 个不同的编码器和 K 个不同的对抗框架。使用 Relu 激活函数的多层感知机(Multi-layer perceptrons,MLP)作为分类器 Dk 和过滤器 f_k[7]。使用 TransD 方法计算编码器和边缘预测损失函数 [8]。在这个模型中,一个节点/实体的编码取决于预先决定的边缘关系,以及该实体是一个关系中的头还是尾。头节点的嵌入 (即边关系中的源节点) 由下式计算:
其中,u、u_p、r_p 为可训练的嵌入参数,I 为 d 维单位矩阵。编码函数对尾部节点进行了类比定义。评分函数定义为:
其中,r 为另外一个可训练的嵌入参数(每个关系)。最后,使用标准的最大边际损失函数如下:
MOVIELENS-1M 是一个标准的推荐系统数据库,其目标是预测用户对电影的评分,将用户年龄、性别和职业作为敏感属性。在本库中的任务可以做如下描述:将电影推荐任务视为用户和电影之间的边缘预测问题,将不同的可能评级视为不同的边缘关系。
在本库中的实验采用简单的「嵌入-查找(Embedding-Lookup)」编码器,将每个用户和电影与一个唯一的嵌入向量关联起来。评分阶段,使用对数似然法计算如下:
其中,a_r,1、P1、P2 均为可训练的参数。损失函数使用简单的负对数似然法。
本文最后使用的数据库是基于 REDDIT 获取的,REDDIT 是一个广受欢迎的、以讨论为基础的网站,用户可以在这里对不同话题社区的内容进行发布和评论。对于这个数据集,考虑一个传统的边缘预测任务,其目标是预测用户和网站社区之间的交互情况。通过检查 2017 年 11 月以来的所有情况,如果用户在这段时间内至少在某社区出现过一次,就会在该用户和该社区之间设置一个边。然后,将图中的低分数节点去掉,最终得到一个包含 366K 个用户、18K 个社区、7M 边缘的图。基于该图,实验的主要任务是构建边缘预测模型,基于 90% 的用户-社区边缘情况预测剩余的缺失边缘。
将某些社区节点看作是「敏感」节点,将是否与这些敏感社区有边缘连接看作是用户的敏感属性。所谓的公平性目标是指模型的预测结果不受用户是否访问过某特定社区的情况影响。
在本数据库中的实验采用的是简单的「嵌入-查找(Embedding-Lookup)」编码器,使用简单点积评分函数:
为了量化学习到的嵌入对敏感属性的不变性程度,冻结编码器 C-ENC、训练一个新的 MLP 分类器预测每个过滤后嵌入的敏感属性。此外,评估使用这些过滤嵌入对原始预测任务的性能。理想情况下,训练得到的新 MLP 应当能够在预测敏感属性时具有随机准确性,此外,这些嵌入能够较好地完成原有的边缘预测任务。
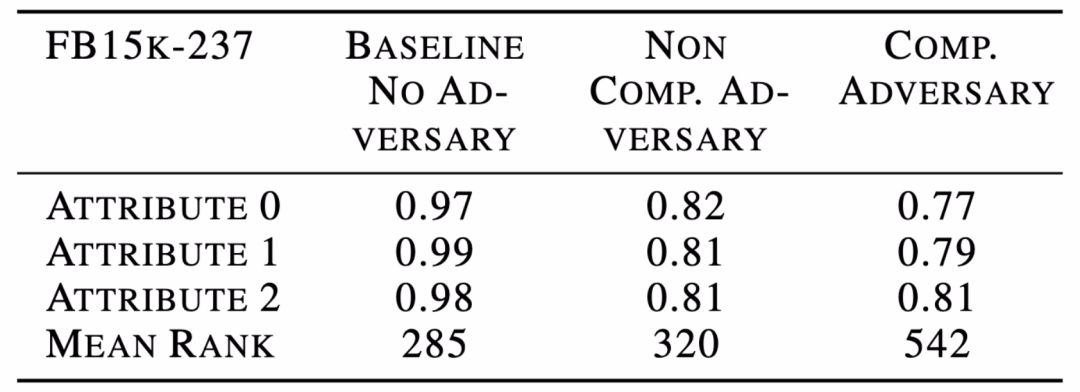
总的来说,本文实验结果表明,在社会推荐数据集上,包括 MovieLens-1M 和 REDDIT,本文的方法能够实现一个合理的折衷,即几乎完全删除敏感信息,同时保证边缘预测任务的相对误差只增加约 10%。表 2 给出在使用各种嵌入方法时,预测 MovieLens 数据上的敏感属性的情况。由表 2 结果可知,敏感属性的分类准确度与多数投票分类器的分类准确度相当,使用组合对抗框架的 RMSE 从 0.865 下降到 1.01。表 3 给出了使用不同方法完成 Freebase15k-237 库中预测敏感属性能力的实验结果。所有的敏感属性都是二进制的,表 3 给出了 AUC 分数以及完成主要边缘预测任务的平均秩。Freebase15k-237 库中的实验结果显示,如果想要消除敏感信息,必须以增加原始边缘预测任务成本为代价。这个结果是可接受的,因为对于这个数据集,「敏感」属性是由实体类型注释合成得到的,这些属性与边缘/关系预测主任务高度相关。这一实验结果也表明,基于图嵌入的方法进行去偏处理是存在潜在局限性的。
表 2. 预测 MovieLens 数据上的敏感属性的情况
表 3.Freebase15k-237 库中预测敏感属性的能力
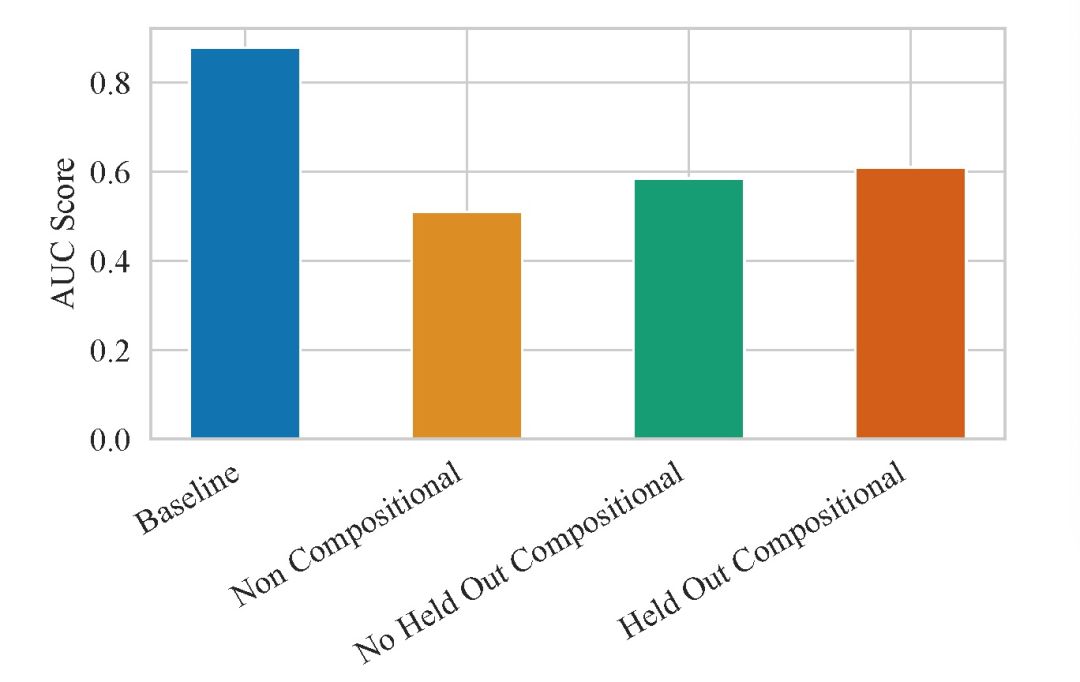
由表 2 中的实验结果可以看出,本文提出的复合框架效果优于单独对每一种属性进行去偏处理的效果。与单独基于每种敏感属性进行对抗正则化嵌入模型训练相比,使用复合框架能够去除掉更多的敏感信息,这是由于在数据库中不同的敏感属性,例如年龄、性别和职业,是相互关联的。图 3 给出预测 REDDIT 数据集中敏感属性的能力,其中条形图对应于 10 个二进制敏感属性的平均 AUC。与表 2 实验给出的结论不同,在 REDDIT 库中,复合框架的效果并不如单独处理每个敏感属性的好。这说明,本文提出的复合对抗性框架效果受到不同的数据库特性影响。
图 3. 使用不同嵌入方法时,预测 Reddit 数据集中敏感属性的能力
使用复合编码器的一个优势在于能够生成对不同敏感属性组合不变的嵌入。对于一个单独的节点,能够生成 2^K 个独立的嵌入。本文在 REDDIT 库中进行实验,这是由于与另外两个库相比 REDDIT 库的敏感属性数量最多。由图 3 中的实验可知,本文提出的方法对于未知组合的实验效果下降很小(0.025),表明该方法具有对未知敏感属性组合的不变性。
基于图节点嵌入的图表示学习是大规模推荐系统中广泛应用的一种重要方法,本文重点讨论的是基于图嵌入算法的去偏处理。该方法目前还存在很多局限性,一是,本文使用的对抗损失函数仅停留在理论分析层面,近期的研究中陆续提出了其他损失函数,包括非对抗的损失函数,这些损失函数是否更适合于本文所讨论的问题,还缺少进一步的分析;二是,本文讨论的是针对属性层面集合的公平性问题,对于一些子集合(由多个属性组成的集合)层面的公平性问题,并未涉及;三是,本文是在理想实验条件下对不同属性进行的组合,这种理想条件假定的是不同属性具有公平的组合机会。然而在实际应用场景中,用户本身就是有偏见的,例如与男性用户相比,女性用户搜索时会着重考虑搜索结果是否是性别公平的,这种用户接口的偏见是否会对本文提出的框架有所影响,本文并未做讨论。
2、Fair Regression: Quantitative Definitions and Reduction-Based Algorithms
https://arxiv.org/pdf/1905.12843.pdf
随着机器学习涉及到我们生活中越来越重要的方面,包括教育、医疗、刑事司法和贷款等,越来越多的人开始关注如何确保算法公平地对待不同的亚群体用户。这一问题,在「分类」这一机器学习应用领域中的研究和讨论最为广泛,近年来已经提出了一些衡量公平度的定量指标,由此产生了一系列旨在满足这些要求的算法。然而,这些算法主要适用于离线以及小的决策问题,例如招聘、学校录取、贷款接收/拒绝决策问题。在实际问题中,更多的分类算法是要求评估一个连续的问题,比如工作是否成功、大学一年级的平均绩点成绩,以及放贷的违约风险。因此,已有的关于公平分类的算法适用范围相当有限。
本文的研究目的是提出一种与原有算法相比适用范围更广泛的、回归任务和模型类的算法。本文将分类问题考虑为一个实值目标预测问题(Predicting a Real-Valued Target),同时使用一个任意 Lipschitz 连续损失函数来度量预测质量。每个样本中都包含有一个受保护的属性,例如种族、性别,算法的目标是保证这些属性的公平性。本文主要研究两类公平问题:统计奇偶性 (Statistical Parity,SP),预测结果在统计上依赖于受保护的属性;有界群体损失 (Bounded Group Loss,BGL),任何受保护群体的预测误差都低于某个预先指定的水平。本文将公平回归(Fair Regression)定义为在这些约束条件下最小化实值预测的预期损失任务。针对两类公平问题,本文提出了不同的算法:对于 BGL,本文提出在每个子种群中,受损失约束的损失最小化问题可以通过算法简化为一个加权损失最小化问题。对于 SP,如果我们将实值预测空间离散化,那么在一定的约束条件下,公平回归的任务可以简化为代价敏感的分类问题。
假定我们要解决的是一般的数据预测问题,模型输出值是实数。我们首先定义损失函数。假定训练样本为 (X,A,Y),其中,X 为特征向量,A 为受保护的属性(有限值),Y 为标记,X 为连续高维向量。A 可属于 X 也可不属于,Y 可为连续值也可为离散值。给定一个预测函数 f:X→[0,1],算法目标是给定 X,找到满足公平性原则(SP/BGL)的能够准确预测 Y 的预测函数 f。与之前算法讨论的问题不同,Y 和 f(X)都为实值函数。f(X) 预测 Y 的准确度由损失函数 l(Y,f(X)) 衡量。一般性地,损失函数要求满足 l1 范数的 1-Lipschitz 约束:
本文中进行公平性分类和回归过程,使用了两个基本的定量统计定义:
SP (Statistical parity)
:预测函数 f 如果独立于某个受保护的属性 A,即预测函数 f 满足 (X,A,Y) 上分布的统计奇偶性,与受保护属性无关,我们就说该函数满足 SP 要求。当 f(X)∈[0,1] 时,我们有:P[f(X)≥z|A=a]=P[f(x)≥z]。
BGL(Bounded group lost)
:如果对于每个受保护的属性 A 来说,预测损失都低于某一预先确定的值,这个函数 f 满足于 BGL。以语音或人脸识别任务为例,这一公平性要求表示所有的组别都能获得较好的识别效果。当 E[l(Y,f(X))|A=a]≤ζ,我们得到预测水平为ζ的预测函数 f。
公平回归的过程就是在满足 SP 或 BGL 的前提下最小化损失函数 E[l(Y),f(X)]。我们需要在该前提的约束下进行优化。
SP:本文设置一个可调值用于控制公平性的准确度,例如针对每个属性的松弛参数ε_a,此时公平回归任务为:
图 2. 方法整体结构
早期关于在社会类应用中增加强制不变性约束 (或「公平性」) 的工作通常只涉及一个敏感属性的情况,但是实际应用中通常社会图嵌入会涉及到多个属性。在极端情况下,可能希望不只是节点,甚至是图中的边(edge)也具备公平性,例如,一个社交网络平台上的用户可能希望该平台的推荐系统忽略他们与某个其他用户是朋友,或者他们参与了某个特定内容的事实。本文提出的方法通过学习得到一组对抗性过滤器,从而删除关于特定敏感属性的信息。
首先,考虑嵌入一个异质或多关系 (社会) 图 G = (V, e),G 包含有向边三元组 e= < u,r, v >,其中 u, v∈V 为节点,r∈R 表示节点间的关系。假定每个节点都属于一个特定的类别,节点间的关系受到节点类型的约束。基于图的关系预测任务描述如下:ξ_train 表示训练边集合,定义负边集合如下:
负边集合表示未在真实图 G 中出现的边的集合。给定ξ_train,目标是学习得到评分函数 s 以满足:
换句话说,学习得到的评分函数在理想情况下应该对任何真边缘评分高于任何假边缘。
图嵌入(Graph Embedding)的任务目标是通过学习一个映射函数 ENC 来完成关系预测任务,即将节点 v 映射为节点嵌入 z_v=ENC(v)。此时评分函数为:
评分函数的含义为:给定两个节点嵌入 z_u ∈ R.^d 和 z_v∈ R.^d,以及它们之间的关系 r ∈ R,评分函数 s 表示边 e=<u,r,v> 在图中存在的概率 ( s∈ R)。通常来讲,基于图嵌入模型的方法主要是认为两个节点嵌入间的距离能够表征两个节点间存在边的可能性。本文利用噪声对比估计等破坏分布的对比学习方法来优化评分函数,目的是最大化真实边(正样本)与虚假边(负样本)对比的概率。其中,边(e_batch ⊆ e_train)的损失函数计算为:
考虑公平性的处理,对一个节点类型,假设属于该类型的全部节点都包含有 K 组敏感属性,那么对图嵌入模型进行公平性处理的任务就是确保所学习的节点嵌入 (z_u) 在这些敏感属性方面不存在偏见或不公平。
本文给出了一个简单的以用户为中心的社会图嵌入场景。以性别为敏感属性、电影推荐为关系预测任务的例子,具体任务场景如下:如果给用户一个按钮,上面写着「推荐电影时请忽略我的性别」,那么按下这个按钮后,用户希望从系统中得到什么?很显然,用户 u 的目的是系统能够不考虑他们的性别公平地向他(她)推荐电影,即如下式:
其中 s(e) = s(<z_u, r, z_v>),a_u 为敏感属性。如果直接处理上式,我们能够发现一个明显的问题,即对于每一个节点都需要对它的全部边(可能是数以百万计)进行评分。假设认为 s(e) 仅由 u 决定(忽略掉节点 v 的影响),则可以通过实施表征不变性来保证上式对于所有边缘预测的独立性:
此时满足互信息(mutual Information):I(z_u,a_u)=0。推广到多个敏感属性 S⊆ {1,...,K}:
上式相当于对 S 个不同敏感属性的 S 独立不变性约束的假设。针对本文所讨论的应用场景,S 不是固定不变的。对于不同的用户来说,他们所认为的敏感属性可能不同(年龄,职业,性别等等)。基于上述分析,本文在上式中引入一种对抗性损失和一种「过滤」嵌入,从而对节点嵌入施加表征不变性约束。
首先,将 ENC 嵌入函数泛化,以选择性地「过滤」掉有关某些敏感属性的信息。对每一个敏感属性 k∈{1,...,K},定义一个过滤函数 f_k,通过训练 f_k 能够去除掉与敏感属性 k 有关系的信息。为了保证节点嵌入的不变性,本文使用复合编码器组合过滤后的嵌入:
在组合映射函数(C-ENC)的训练迭代过程中,每轮迭代都通过采样二进制掩码来确定集合 S。本文将二进制掩码采样为一个固定概率 p=0.5 的伯努利序列。在训练过程中,随机采样得到的二进制掩码能够使得模型产生不同敏感性属性组合的不变嵌入,从而实现在推理过程中推广到未知的组合。
本文引入对抗正则项训练复合编码器 Dk。为每个敏感属性 k 定义一个分类器 D_k,目的是通过节点嵌入预测第 k 个敏感属性 D_k : R^d × A_k → [0, 1],其中,D_k 的概率区间为 [0,1]。给定边预测损失函数 L_edge,对抗正则化损失函数为:
其中,λ控制对抗正则项的强度。为了在小批量设置的情况下优化该损失,本文定义两种交替执行的随机梯度下降更新方法:(1)T 小批量更新:基于 C-ENC(Dk 恒定不变)优化 L(e);(2)T』小批量更新:基于 Dk(C-ENC 恒定不变)优化 L(e)。
本文在三个数据库中进行实验,Freebase15k-237、MovieLens-1M,以及从 Reddit 中整理得到的边缘预测数据库。三个库的统计信息如表 1 所示(具体包括全部节点数量(|v|),带有敏感属性的节点数量(|T*|),敏感属性的数目及其类型和图中边缘的总数):
FREEBASE15K-237 是一个标准的知识基准库 [9],本文使用该库评估对抗正规化的影响,在完成标准的知识库任务的同时,保持实体嵌入与「敏感」属性标签的不变性。在本库中,确定三个常见的属性标签:/award/award_nominee,作为敏感属性。
在实验过程中,本文采用联合训练主模型和对抗框架的方式,但在测试不变性时,本文训练一个新分类器 (与鉴别器具有相同的能力) 从所学习的嵌入中预测敏感属性。此外,在这些实验中,本文依赖于两个基线:首先,对比不包含任何不变性约束的基线方法,即λ= 0。其次,与一种非复合对抗的基线方法进行对比,即分别训练 K 个不同的编码器和 K 个不同的对抗框架。使用 Relu 激活函数的多层感知机(Multi-layer perceptrons,MLP)作为分类器 Dk 和过滤器 f_k[7]。使用 TransD 方法计算编码器和边缘预测损失函数 [8]。在这个模型中,一个节点/实体的编码取决于预先决定的边缘关系,以及该实体是一个关系中的头还是尾。头节点的嵌入 (即边关系中的源节点) 由下式计算:
其中,u、u_p、r_p 为可训练的嵌入参数,I 为 d 维单位矩阵。编码函数对尾部节点进行了类比定义。评分函数定义为:
其中,r 为另外一个可训练的嵌入参数(每个关系)。最后,使用标准的最大边际损失函数如下:
MOVIELENS-1M 是一个标准的推荐系统数据库,其目标是预测用户对电影的评分,将用户年龄、性别和职业作为敏感属性。在本库中的任务可以做如下描述:将电影推荐任务视为用户和电影之间的边缘预测问题,将不同的可能评级视为不同的边缘关系。
在本库中的实验采用简单的「嵌入-查找(Embedding-Lookup)」编码器,将每个用户和电影与一个唯一的嵌入向量关联起来。评分阶段,使用对数似然法计算如下:
其中,a_r,1、P1、P2 均为可训练的参数。损失函数使用简单的负对数似然法。
本文最后使用的数据库是基于 REDDIT 获取的,REDDIT 是一个广受欢迎的、以讨论为基础的网站,用户可以在这里对不同话题社区的内容进行发布和评论。对于这个数据集,考虑一个传统的边缘预测任务,其目标是预测用户和网站社区之间的交互情况。通过检查 2017 年 11 月以来的所有情况,如果用户在这段时间内至少在某社区出现过一次,就会在该用户和该社区之间设置一个边。然后,将图中的低分数节点去掉,最终得到一个包含 366K 个用户、18K 个社区、7M 边缘的图。基于该图,实验的主要任务是构建边缘预测模型,基于 90% 的用户-社区边缘情况预测剩余的缺失边缘。
将某些社区节点看作是「敏感」节点,将是否与这些敏感社区有边缘连接看作是用户的敏感属性。所谓的公平性目标是指模型的预测结果不受用户是否访问过某特定社区的情况影响。
在本数据库中的实验采用的是简单的「嵌入-查找(Embedding-Lookup)」编码器,使用简单点积评分函数:
为了量化学习到的嵌入对敏感属性的不变性程度,冻结编码器 C-ENC、训练一个新的 MLP 分类器预测每个过滤后嵌入的敏感属性。此外,评估使用这些过滤嵌入对原始预测任务的性能。理想情况下,训练得到的新 MLP 应当能够在预测敏感属性时具有随机准确性,此外,这些嵌入能够较好地完成原有的边缘预测任务。
总的来说,本文实验结果表明,在社会推荐数据集上,包括 MovieLens-1M 和 REDDIT,本文的方法能够实现一个合理的折衷,即几乎完全删除敏感信息,同时保证边缘预测任务的相对误差只增加约 10%。表 2 给出在使用各种嵌入方法时,预测 MovieLens 数据上的敏感属性的情况。由表 2 结果可知,敏感属性的分类准确度与多数投票分类器的分类准确度相当,使用组合对抗框架的 RMSE 从 0.865 下降到 1.01。表 3 给出了使用不同方法完成 Freebase15k-237 库中预测敏感属性能力的实验结果。所有的敏感属性都是二进制的,表 3 给出了 AUC 分数以及完成主要边缘预测任务的平均秩。Freebase15k-237 库中的实验结果显示,如果想要消除敏感信息,必须以增加原始边缘预测任务成本为代价。这个结果是可接受的,因为对于这个数据集,「敏感」属性是由实体类型注释合成得到的,这些属性与边缘/关系预测主任务高度相关。这一实验结果也表明,基于图嵌入的方法进行去偏处理是存在潜在局限性的。
表 2. 预测 MovieLens 数据上的敏感属性的情况
表 3.Freebase15k-237 库中预测敏感属性的能力
由表 2 中的实验结果可以看出,本文提出的复合框架效果优于单独对每一种属性进行去偏处理的效果。与单独基于每种敏感属性进行对抗正则化嵌入模型训练相比,使用复合框架能够去除掉更多的敏感信息,这是由于在数据库中不同的敏感属性,例如年龄、性别和职业,是相互关联的。图 3 给出预测 REDDIT 数据集中敏感属性的能力,其中条形图对应于 10 个二进制敏感属性的平均 AUC。与表 2 实验给出的结论不同,在 REDDIT 库中,复合框架的效果并不如单独处理每个敏感属性的好。这说明,本文提出的复合对抗性框架效果受到不同的数据库特性影响。
图 3. 使用不同嵌入方法时,预测 Reddit 数据集中敏感属性的能力
使用复合编码器的一个优势在于能够生成对不同敏感属性组合不变的嵌入。对于一个单独的节点,能够生成 2^K 个独立的嵌入。本文在 REDDIT 库中进行实验,这是由于与另外两个库相比 REDDIT 库的敏感属性数量最多。由图 3 中的实验可知,本文提出的方法对于未知组合的实验效果下降很小(0.025),表明该方法具有对未知敏感属性组合的不变性。
基于图节点嵌入的图表示学习是大规模推荐系统中广泛应用的一种重要方法,本文重点讨论的是基于图嵌入算法的去偏处理。该方法目前还存在很多局限性,一是,本文使用的对抗损失函数仅停留在理论分析层面,近期的研究中陆续提出了其他损失函数,包括非对抗的损失函数,这些损失函数是否更适合于本文所讨论的问题,还缺少进一步的分析;二是,本文讨论的是针对属性层面集合的公平性问题,对于一些子集合(由多个属性组成的集合)层面的公平性问题,并未涉及;三是,本文是在理想实验条件下对不同属性进行的组合,这种理想条件假定的是不同属性具有公平的组合机会。然而在实际应用场景中,用户本身就是有偏见的,例如与男性用户相比,女性用户搜索时会着重考虑搜索结果是否是性别公平的,这种用户接口的偏见是否会对本文提出的框架有所影响,本文并未做讨论。
2、Fair Regression: Quantitative Definitions and Reduction-Based Algorithms
https://arxiv.org/pdf/1905.12843.pdf
随着机器学习涉及到我们生活中越来越重要的方面,包括教育、医疗、刑事司法和贷款等,越来越多的人开始关注如何确保算法公平地对待不同的亚群体用户。这一问题,在「分类」这一机器学习应用领域中的研究和讨论最为广泛,近年来已经提出了一些衡量公平度的定量指标,由此产生了一系列旨在满足这些要求的算法。然而,这些算法主要适用于离线以及小的决策问题,例如招聘、学校录取、贷款接收/拒绝决策问题。在实际问题中,更多的分类算法是要求评估一个连续的问题,比如工作是否成功、大学一年级的平均绩点成绩,以及放贷的违约风险。因此,已有的关于公平分类的算法适用范围相当有限。
本文的研究目的是提出一种与原有算法相比适用范围更广泛的、回归任务和模型类的算法。本文将分类问题考虑为一个实值目标预测问题(Predicting a Real-Valued Target),同时使用一个任意 Lipschitz 连续损失函数来度量预测质量。每个样本中都包含有一个受保护的属性,例如种族、性别,算法的目标是保证这些属性的公平性。本文主要研究两类公平问题:统计奇偶性 (Statistical Parity,SP),预测结果在统计上依赖于受保护的属性;有界群体损失 (Bounded Group Loss,BGL),任何受保护群体的预测误差都低于某个预先指定的水平。本文将公平回归(Fair Regression)定义为在这些约束条件下最小化实值预测的预期损失任务。针对两类公平问题,本文提出了不同的算法:对于 BGL,本文提出在每个子种群中,受损失约束的损失最小化问题可以通过算法简化为一个加权损失最小化问题。对于 SP,如果我们将实值预测空间离散化,那么在一定的约束条件下,公平回归的任务可以简化为代价敏感的分类问题。
假定我们要解决的是一般的数据预测问题,模型输出值是实数。我们首先定义损失函数。假定训练样本为 (X,A,Y),其中,X 为特征向量,A 为受保护的属性(有限值),Y 为标记,X 为连续高维向量。A 可属于 X 也可不属于,Y 可为连续值也可为离散值。给定一个预测函数 f:X→[0,1],算法目标是给定 X,找到满足公平性原则(SP/BGL)的能够准确预测 Y 的预测函数 f。与之前算法讨论的问题不同,Y 和 f(X)都为实值函数。f(X) 预测 Y 的准确度由损失函数 l(Y,f(X)) 衡量。一般性地,损失函数要求满足 l1 范数的 1-Lipschitz 约束:
本文中进行公平性分类和回归过程,使用了两个基本的定量统计定义:
SP (Statistical parity)
:预测函数 f 如果独立于某个受保护的属性 A,即预测函数 f 满足 (X,A,Y) 上分布的统计奇偶性,与受保护属性无关,我们就说该函数满足 SP 要求。当 f(X)∈[0,1] 时,我们有:P[f(X)≥z|A=a]=P[f(x)≥z]。
BGL(Bounded group lost)
:如果对于每个受保护的属性 A 来说,预测损失都低于某一预先确定的值,这个函数 f 满足于 BGL。以语音或人脸识别任务为例,这一公平性要求表示所有的组别都能获得较好的识别效果。当 E[l(Y,f(X))|A=a]≤ζ,我们得到预测水平为ζ的预测函数 f。
公平回归的过程就是在满足 SP 或 BGL 的前提下最小化损失函数 E[l(Y),f(X)]。我们需要在该前提的约束下进行优化。
SP:本文设置一个可调值用于控制公平性的准确度,例如针对每个属性的松弛参数ε_a,此时公平回归任务为:
![]() (1)
BGL:针对每个属性,设定一个约束参数ζ_a,此时公平回归问题为:
(1)
BGL:针对每个属性,设定一个约束参数ζ_a,此时公平回归问题为:
![]() (2)
与第一篇论文提到的公平分类相似,为了实现更好的公平性-准确性权衡,这篇论文的作者在公平回归问题中引入一个随机预测因子(Randomized predictors):首先根据分布 Q 选取 f,然后基于 f 进行预测。基于公式(1)和(2)给出下述符号:
(2)
与第一篇论文提到的公平分类相似,为了实现更好的公平性-准确性权衡,这篇论文的作者在公平回归问题中引入一个随机预测因子(Randomized predictors):首先根据分布 Q 选取 f,然后基于 f 进行预测。基于公式(1)和(2)给出下述符号:
![]() (3)
(3)
![]() (4)
本文作者展示了如何将公平回归问题转化为三个标准的学习问题:加权最小二乘回归、在不公平约束下的加权风险最小化(无公平性约束)、成本敏感分类问题。
加权最小二乘回归的风险优化问题:给定数据集 {(Wi,Xi,Yi)},Wi 为非负权重,f 最优化权重经验风险:
在不公平约束下的加权风险最小化:使用 l 衡量准确度,能够得到针对相同类别 F 的加权最小二乘学习者。损失函数为:
成本敏感分类:给定数据集 {(X^i,,Ci)},其中 X『i,, 为特征向量,Ci 为表征成本(例如损失函数)区别。正值 Ci 表示 0 为最佳,负值 Ci 则表示 1 为最佳。成本敏感分类的最终目标为找到能够最优化经验成本的分类器 h。给定数据集 {(Wi,X^i,Yi)},当 Yi=1{Ci≤0},以及 Wi=|Ci|,目标函数为:
根据以上,作者就可以做出有 SP 或者 BGL 约束的公平回归算法。
本文使用如下数据库进行实验比对:成人库(Adult)、法学院(Law School)、社区和犯罪(Communities&Crime)。由于前两个库较大,本文也在其子库上进行了实验。对比基线算法包括不受任何公平约束的回归,以及来自公平分类和公平回归领域的两个基线算法。两个基线算法具体为:在任务为最小二乘回归的三个数据集上,本文使用完全实质性机会均等(full Substantive Equality of Opportunity, SEO)[10] 算法作为基线;在两个任务为 logistic 回归的数据集上,本文运行公平分类(Fair Classification,FC)[11] 算法作为基线。
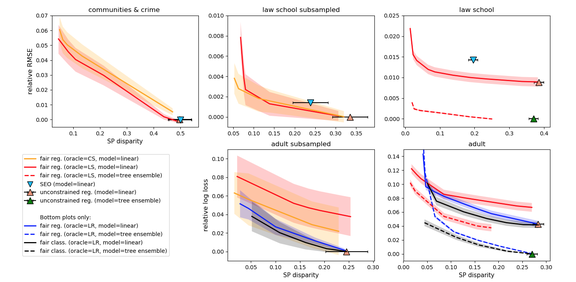
图 4 给出了 SP 约束下的相对测试损失与最坏约束冲突对比实验结果,该实验通过从实际损失中减去最小基线损失来计算相对损失。图 4 给出了 95% 的置信区间来表示本文方法和公平分类(FC)的相对损失,也给出了 95% 的置信区间来表示约束违反(对所有方法都一样)。除了 Adult 库中公平分类(FC)效果更好,在其他数据库中本文提出的方法效果都为最优。此外,本文所提出的方法在减小差距(不公平)的同时,并不会对总体损失造成严重影响。本文所提出的方法在全部最小二乘任务中效果都为最优,但在 logistic 回归任务中,效果低于公平分类(FC)。
图 4. SP 约束下的相对测试损失与最坏约束冲突对比
本文所提的算法能够有效处理一系列损失和回归问题,同时在保持总体准确度的同时减小了偏见(差异)。在本文给出的实验中,公平分类 (FC) 作为 logistic 回归的一个强大基线算法展现出了良好的性能,在一些实验条件下效果甚至优于本文提出的算法。这表明本文所提出的基于回归的归约启发式方法还存在一些缺陷,这也为以后的研究留下了改进空间。
3、Identifying and Reducing Gender Bias in Word-Level Language Models
https://arxiv.org/pdf/1904.03035.pdf
(4)
本文作者展示了如何将公平回归问题转化为三个标准的学习问题:加权最小二乘回归、在不公平约束下的加权风险最小化(无公平性约束)、成本敏感分类问题。
加权最小二乘回归的风险优化问题:给定数据集 {(Wi,Xi,Yi)},Wi 为非负权重,f 最优化权重经验风险:
在不公平约束下的加权风险最小化:使用 l 衡量准确度,能够得到针对相同类别 F 的加权最小二乘学习者。损失函数为:
成本敏感分类:给定数据集 {(X^i,,Ci)},其中 X『i,, 为特征向量,Ci 为表征成本(例如损失函数)区别。正值 Ci 表示 0 为最佳,负值 Ci 则表示 1 为最佳。成本敏感分类的最终目标为找到能够最优化经验成本的分类器 h。给定数据集 {(Wi,X^i,Yi)},当 Yi=1{Ci≤0},以及 Wi=|Ci|,目标函数为:
根据以上,作者就可以做出有 SP 或者 BGL 约束的公平回归算法。
本文使用如下数据库进行实验比对:成人库(Adult)、法学院(Law School)、社区和犯罪(Communities&Crime)。由于前两个库较大,本文也在其子库上进行了实验。对比基线算法包括不受任何公平约束的回归,以及来自公平分类和公平回归领域的两个基线算法。两个基线算法具体为:在任务为最小二乘回归的三个数据集上,本文使用完全实质性机会均等(full Substantive Equality of Opportunity, SEO)[10] 算法作为基线;在两个任务为 logistic 回归的数据集上,本文运行公平分类(Fair Classification,FC)[11] 算法作为基线。
图 4 给出了 SP 约束下的相对测试损失与最坏约束冲突对比实验结果,该实验通过从实际损失中减去最小基线损失来计算相对损失。图 4 给出了 95% 的置信区间来表示本文方法和公平分类(FC)的相对损失,也给出了 95% 的置信区间来表示约束违反(对所有方法都一样)。除了 Adult 库中公平分类(FC)效果更好,在其他数据库中本文提出的方法效果都为最优。此外,本文所提出的方法在减小差距(不公平)的同时,并不会对总体损失造成严重影响。本文所提出的方法在全部最小二乘任务中效果都为最优,但在 logistic 回归任务中,效果低于公平分类(FC)。
图 4. SP 约束下的相对测试损失与最坏约束冲突对比
本文所提的算法能够有效处理一系列损失和回归问题,同时在保持总体准确度的同时减小了偏见(差异)。在本文给出的实验中,公平分类 (FC) 作为 logistic 回归的一个强大基线算法展现出了良好的性能,在一些实验条件下效果甚至优于本文提出的算法。这表明本文所提出的基于回归的归约启发式方法还存在一些缺陷,这也为以后的研究留下了改进空间。
3、Identifying and Reducing Gender Bias in Word-Level Language Models
https://arxiv.org/pdf/1904.03035.pdf
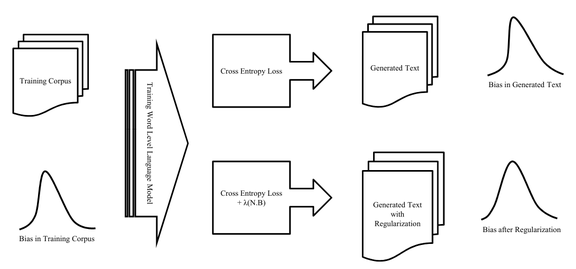
语言建模(Language Model)是一项非常容易受到性别偏见(Gender Bias)影响的自然语言处理任务,同时也非常具有实际应用价值,例如屏幕键盘中的单词预测。本文的研究目的是识别用于语言建模的训练数据集中的性别偏见,以及减少其对模型行为的影响。具体来讲,本文的工作是评估性别偏见对于在文本语料库中训练的单词级别的语言模型的性能影响。
本文首先通过对训练得到的嵌入特征和共现模式进行定性和定量分析,从而检查数据集中存在的偏见。然后,在数据集上训练 LSTM 单词级别的语言模型,并测量生成输出的偏见(如图 5 所示)。第三,应用一个正则化过程,目的是使得模型学习到的嵌入特征最小程度依赖于性别,同时进行独立的对输入和输出嵌入特征的去偏处理。
分析用于建立最新语言模型的公开数据集所显示的性别偏见
本文选择了三个公开数据集进行验证,包括:Penn Treebank (PTB)、WikiText-2 和 CNN/Daily Mail。PTB 由科学摘要、计算机手册、新闻文章等不同类型的文章组成,其中男性单词的计数高于女性单词。WikiText-2 由维基百科的文章组成,它比 PTB 更加多样化,因此男女性别词的比例更加平衡。CNN/Daily Mail 是从体育、健康、商业、生活方式、旅游等主题的各种新闻文章中整理出来的。这个数据集的男女性别比例更加平衡,相较于前两个数据集来说,存在的性别偏见最小。
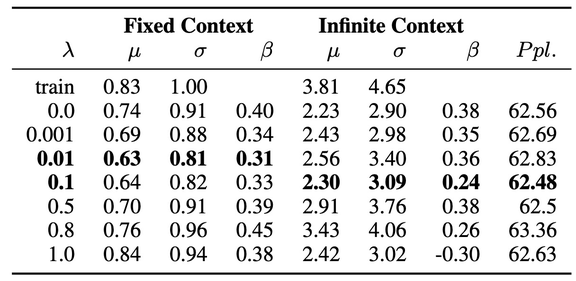
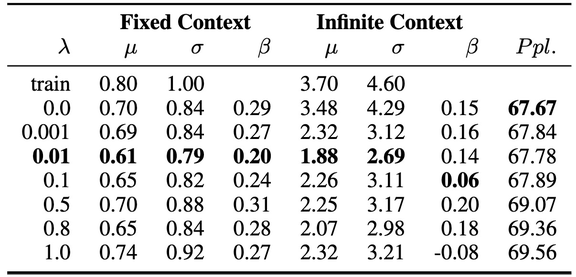
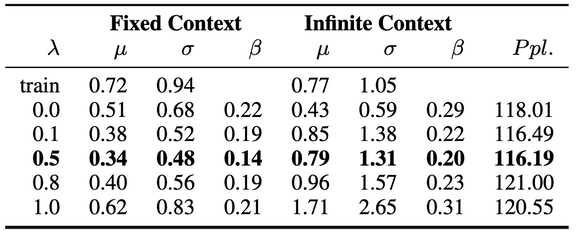
本文使用包含 1150 个隐藏单元的三层 LSTM 单词级语言模型 (AWD-LSTM) 测量生成输出的偏见程度[3],使用复杂度(Perplexity)作为衡量标准。在对三个公开数据集的验证过程中都得到了合理的复杂度,分别为 PTB 62.56、Wikitext-2 67.67、CNN/Daily Mail 118.01。
复杂度(Perplexity)是一种常用的语言模型评价标准,可以理解为,如果每个时间步长内都根据语言模型计算的概率分布随机挑词,那么平均情况下,挑多少个词才能挑到正确的那个。即复杂度(Perplexity)刻画的是语言模型预测一个语言样本的能力,通过语言模型得到一条语言样本的概率越高,语言模型对数据集的拟合程度越好,建模效果越好。
分析性别偏见对基于递归神经网络 (RNNs) 的单词级语言模型的影响
使用能够表征性别的单词来表示一个单词在上下文中出现的概率:
其中 c(w,g) 是上下文窗口,g 是一组性别词汇,例如,当 g=f,这样的词包括 he,her,woman 等,w 是语料库中的任何单词,不包括停止词汇和性别相关词汇。关于 c(w,g) 的选择,本文采用了固定长度和权重以指数方式递减(0.95)的有限长度窗口大小两种方式进行实验。
要对从训练语料库和语言模型生成的文本语料库中采样得到的文本中的每个单词测量这个偏见分数,其中,正偏分数意味着该词与女性词汇的搭配频率高于与男性词汇的搭配频率。在假设无限的语境中,偏见分数应当接近于 0,例如,「doctor」和「nurse」在对话过程中与男性和女性单词搭配出现的频率应当一样多。
为了评估每个模型的去偏性,测量生成的语料库的偏见分数计算如下:
此外,为了估计偏见放大或缩小的改变程度,本文拟合了一个单变量线性回归模型,该模型对上下文单词的偏见评分如下:
其中,β为与训练数据集相关的比例放大测量值,减小β意味着对模型去偏,c 为上文定义的 context。本文利用评估语料库中每个上下文单词的绝对平均值μ和标准偏差σ来量化偏见的分布:
前期的研究表明,机器学习技术通过捕捉数据模式来做出连贯的预测,可能能够捕获甚至放大数据中的偏见 [4]。本文分别对输入嵌入、输出嵌入和同时两种嵌入这三种情况进行了去偏处理。本文使用的方法为:使用 [5] 中的方法从学习到的输出嵌入中提取一个性别子空间。然后,根据 [6] 中的方法在单词级别(word level)的语言模型上训练这些嵌入,而不是使用无偏预训练的嵌入 [6]。
使用 w∈Sw 表示单词嵌入,Di,...,Dn⊂Sw 表示定义集,包括性别词汇对,例如男人和女人。定义集是为每个语料库单独设计的,因为某些词并不会出现在所有语料库中。对于一个训练语料库,同时出现的与性别相关的相反的词汇,则将它们认定为一个定义集,{ui,vi}=Di。矩阵 C 是定义集中词汇对之间的差异向量的集合,词汇对的差异情况表征了性别信息。对 C 进行奇异值分解处理:
将 V 的前 k 列定义为性别子空间 B=V_1:k。矩阵 N 由无偏嵌入组成。如果想让嵌入的偏见最小,那么将其映射到 B 中时,令其 Frobenius 范数的平方值也是最小。为了减少模型中嵌入层学习到的偏见,在训练损失中加入以下正则化项:
其中,λ控制最小化嵌入矩阵 W(N 和 B 推导得到的矩阵)的权重,N 和 C 在模型训练期间迭代更新。
在语言模型中随机输入 2000 个种子作为开始生成单词的起点。使用前面的单词作为语言模型的输入,并执行多项选择以生成下一个单词,重复该步骤 500 次,最终得到三个数据集对应每个λ的 10^6 个 token。
本文使用 RNN 进行模型训练。结果见表 4。数据集的整体偏见可由μ表征,较大的μ表示语料库存在较大的性别偏见。由表 4 中的实验结果可知,随着λ值增大,μ逐渐减小直至稳定,因此λ的优化存在一个区间。本文还对单个单词的偏差分数进行了对比以评估去偏的效果。β的倾斜程度表示了模型相对于训练语料库的放大或减弱效果,β值的大幅下降表示减弱偏差,反之亦然。β的负值则假定损失项没有产生其它影响。本文给出的实验结果中,λ较大时β也会增大,作者认为这可能是因为模型不稳定所造成的。此外,对于去偏处理参数μ和σ的影响很小,作者认为它们无法捕获单次级别的改进。基于上述实验结果,作者推荐使用单词级别的评估项,例如β,来评估语料库级别的去偏处理效果的鲁棒性。
表 4. PTB、WikiText-2、CNN/Daily Mail 中的实验结果
表 5 为从 CNN/Daily Mail 的生成语料中选择的目标词汇。特别强调与女性相关的词 crying 和 fragile,而一般认为与男性相关的词汇 Leadership 和 prisoners。当λ=0 时,这些偏见非常明显。对于 fragile,当λ=1.0 时,生成文本中几乎没有对女性的词汇提及,从而得到大量的中立文本。对于 prisoners,λ=0.5 时情况也类似。
表 5. 不同λ值时 CNN/Daily Mail 中的生成文本比较
本文使用了两个不同的指标量化语料级别的性别偏见:绝对平均值μ和标准偏差σ。此外,提出了一个用于评估去偏效果的相关矩阵β,作者通过对训练语料库生成的文本语料库中的单词级别的性别偏见进行回归分析来计算β。
本文提出的方法可以处理语言模型中单词级别的词分布问题。该方法的目标是测量性别偏差,但并不能检测在去偏模型和数据中仍然存在的显著的偏见。此外,作者也提出,本文的方法在传统的语言模型中增加了一个去偏正则化项,这可能会带来复杂度与偏见处理权衡的问题,例如,在一个无偏的模型中,男性和女性的语言被预测的概率几乎相等,减小性别偏见会导致语言模型的复杂度增高。
随着经合组织的《经合组织人工智能原则》、欧盟《人工智能伦理指南》和《人工智能政策与投资建议》、20 国集团《人工智能原则》以及《北京人工智能原则》等一系列文件的发布,人工智能治理成为了 2020 年广泛关注的议题,本文所探讨的「机器学习中的公平公正」,就是人工智能治理中最关键的问题。
本文对机器学习中的公平公正问题进行了简要回顾,包括数据偏见和算法偏见两类。在此基础上,本文结合 ICML 2019 中的三篇文章,针对算法偏见分别对机器学习领域中的图嵌入问题、回归问题,以及自然语言处理领域中的语言模型问题进行了详细分析。目前,关于算法去偏的处理还停留在理论分析和实验的阶段,主要通过引入不同的损失函数、约束矩阵等约束项弱化模型结果中的偏见,包括第一篇文章中的对抗损失函数、第二篇文章中的统计奇偶性和有界群体损失函数,以及第三篇文章中的去偏正则化项等。算法优化的最终目的是希望加入这些约束项去除偏见的同时,不会严重影响原有机器学习模型的主要任务性能。
由本文的分析可知,通过使用去偏算法或模型,能够在一定的实验环境下去除偏见,但并不能保证对所有数据有效。此外,本文(包括现在已经发表的其他文献)探讨的去偏主要还是集中于性别偏见、种族偏见这一类常见的、容易区分的偏见属性,对于真实应用场景下的复杂去偏问题,研究之路还很漫长,需要更多的挖掘与探索。
分析师介绍:仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
[1] Saxena, Nripsuta, Huang, Karen, DeFilippis, Evan,et al. How Do Fairness Definitions Fare? Examining Public Attitudes Towards Algorithmic Definitions of Fairness. https://arxiv.org/pdf/1908.09635.pdf.
[2] James Zou, Londa Schiebinger, AI can be sexist and racist—it』s time to make it fair. https://www.nature.com/articles/d41586-018-05707-8.
[3] Stephen Merity, Nitish Shirish Keskar, and Richard Socher. 2018. Regularizing and optimizing LSTM language models. In International Conference on Learning Representations.
[4] Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Or-donez, and Kai-Wei Chang. 2017. Men also likeshopping: Reducing gender bias amplification usingcorpus-level constraints. InEMNLP, pages 2979–2989. Association for Computational Linguistics.
[5] Tolga Bolukbasi, Kai-Wei Chang, James Y Zou,Venkatesh Saligrama, and Adam T Kalai. 2016.Man is to computer programmer as woman is tohomemaker? Debiasing word embeddings. In D. D.Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, andR. Garnett, editors,Advances in Neural InformationProcessing Systems 29, pages 4349–4357. CurranAssociates, Inc.
[6] Joel Escud ́e Font and Marta R. Costa-Juss`a. 2019.Equalizing gender biases in neural machine trans-lation with word embeddings techniques.CoRR,abs/1901.03116.
[7] Xu, B., Wang, N., Chen, T., and Li, M. Empirical evaluationof rectified activations in convolutional network.DeepLearning Workshop, ICML 2015, 2015.
[8] Ji, G., He, S., Xu, L., Liu, K., and Zhao, J. Knowledgegraph embedding via dynamic mapping matrix. InACL,2015.
[9] Toutanova, K., Chen, D., Pantel, P., Poon, H., Choudhury,P., and Gamon, M. Representing text for joint embeddingof text and knowledge bases. InEMNLP, 2015.
[10] Johnson, K. D., Foster, D. P., and Stine, R. A. Impartial predictive modeling: Ensuring fairness in arbitrary models. arXiv:1608.00528, 2016.
[11] Agarwal, A., Beygelzimer, A., Dud´ık, M., Langford, J., and Wallach, H. A reductions approach to fair classification. In ICML , 2018.
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击
阅读原文
,提交申请。


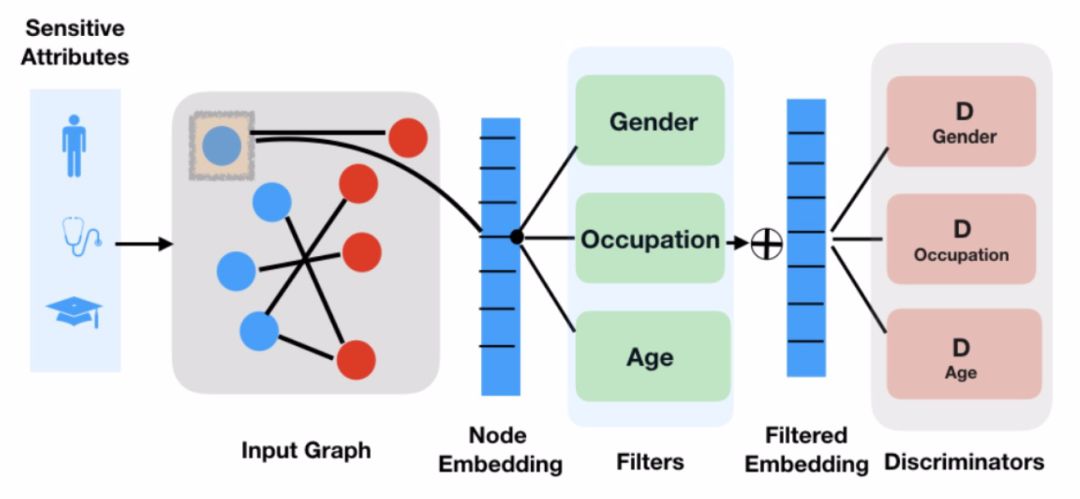 图 2. 方法整体结构
图 2. 方法整体结构
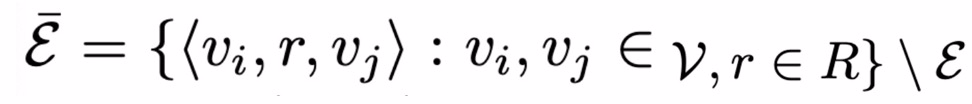
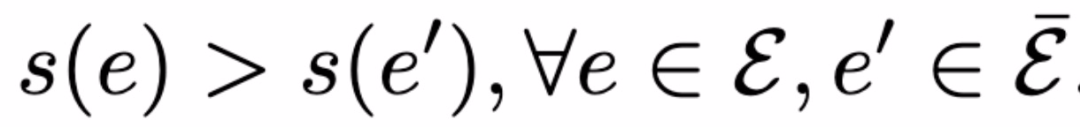
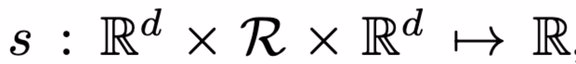
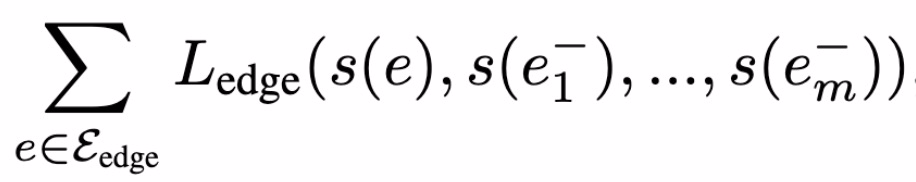
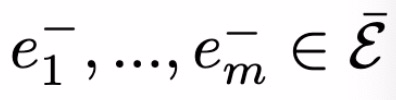
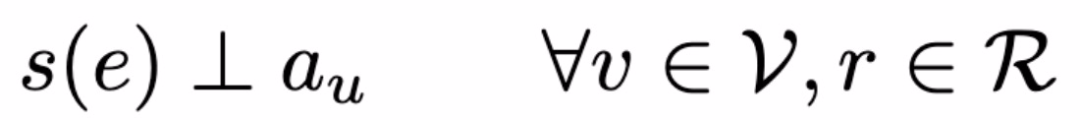
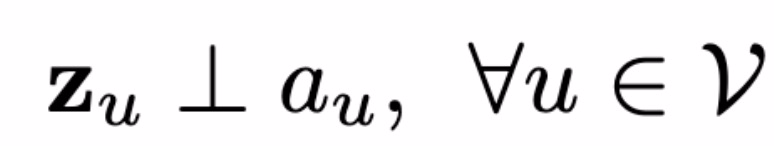
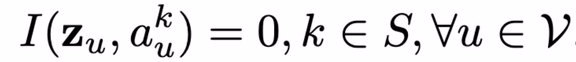
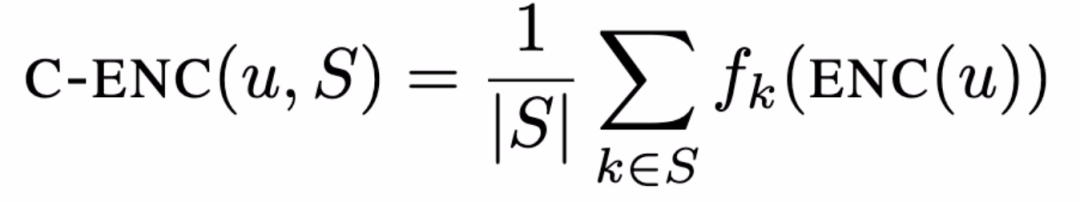
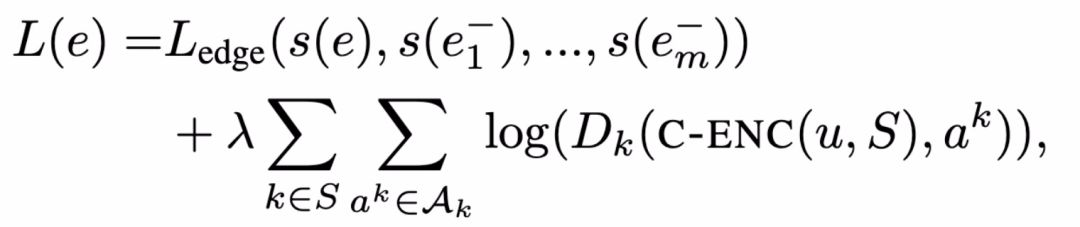

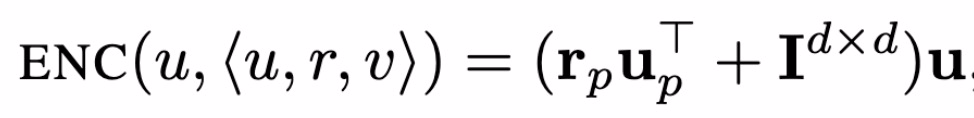
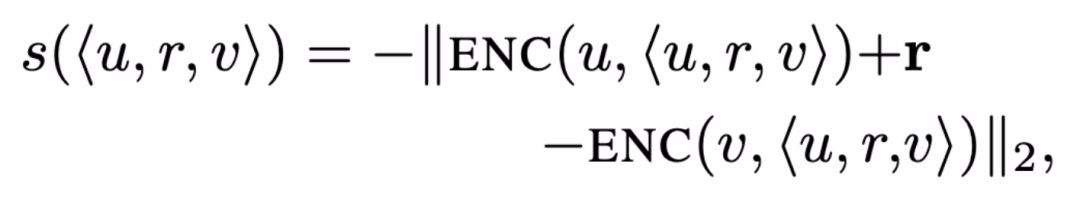
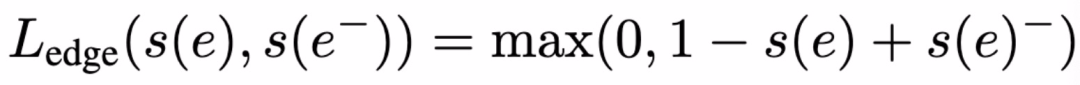
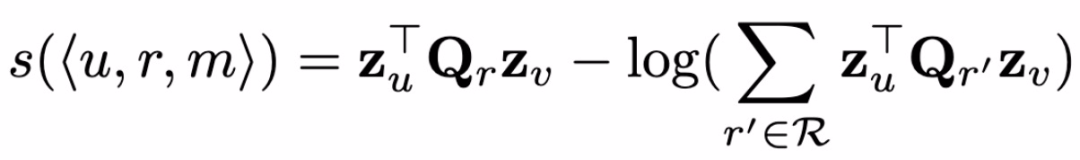

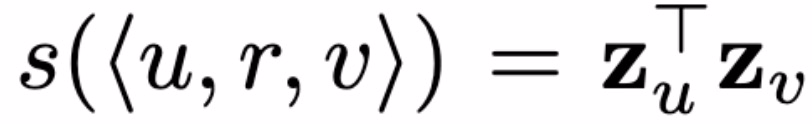
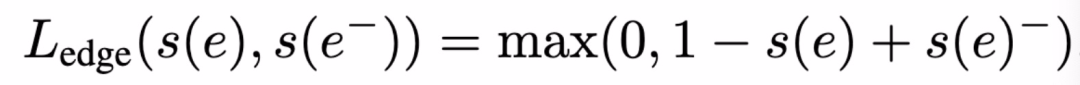


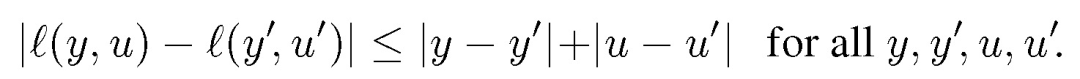
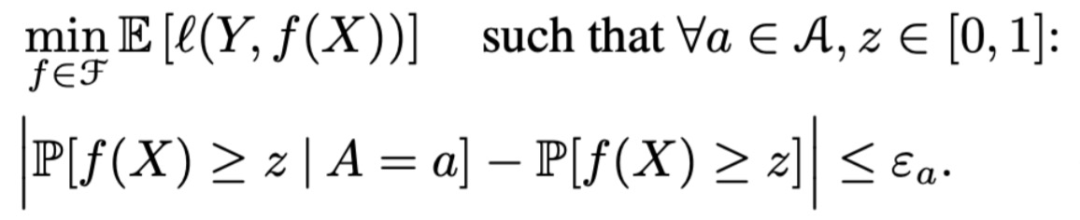 (1)
(1)
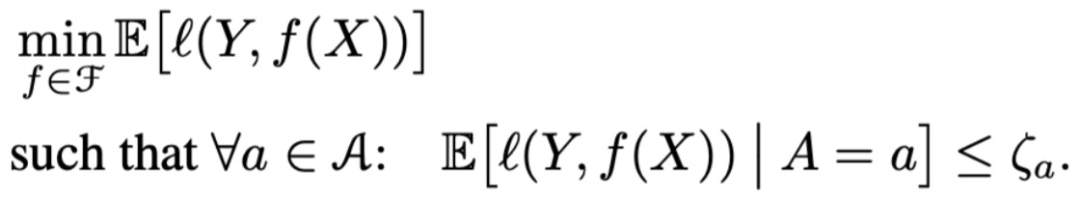 (2)
(2)
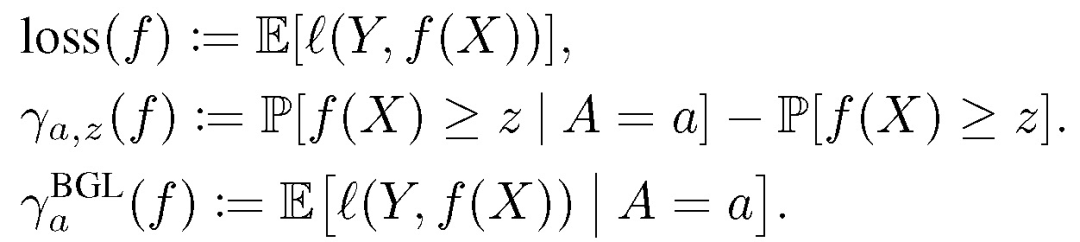
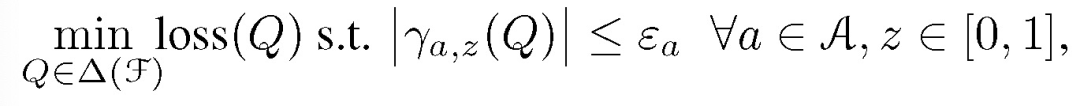 (3)
(3)
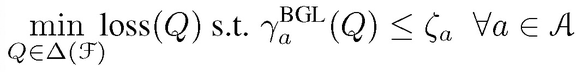 (4)
(4)