如何基于Apache Pulsar和Spark进行批流一体的弹性数据处理?

在大规模并行数据分析领域,AMPLab 的『One stack to rule them all』提出用 Apache Spark 作为统一的引擎支持批处理、流处理、交互查询和机器学习等常见的数据处理场景。 2017 年 7 月,Spark 2.2.0 版本正式推出的 Spark structured streaming 将 Spark SQL 作为流处理、批处理底层统一的执行引擎,提供对无界表(无边界的源源不断到达的流数据)和有界表(静态历史数据)的优化查询,而向用户提供 Dataset/DataFrame API 对批流数据联合处理,进一步模糊了批流数据处理的边界。
另一方面,Apache Flink 在 2016 年左右进入大众视野,凭借其当时更优的流处理引擎,原生的 Watermark 支持『Exaclty Once』的数据一致性保证,和批流一体计算等各种场景的支持,成为 Spark 的有力挑战者。无论是使用 Spark 还是 Flink,用户真正关心的是如何更好地使用数据,更快地挖掘数据中的价值,流数据和静态数据不再是分离的个体,而是一份数据的两种不同表征方式。
然而在实践中,构建一个批流一体的数据平台并不只是计算引擎层的任务。因为在传统解决方案中,近实时的流、事件数据通常采用消息队列(例如 RabbitMQ)、实时数据管道(例如 Apache Kafka)存储,而批处理所需要的静态数据通常使用文件系统、对象存储进行保存。这就意味着,一方面,在数据分析过程中,为了保证结果的正确性和实时性,需要对分别存储在两类系统中数据进行联合查询;另一方面,在运维过程中,需要定期将流数据转存到文件 / 对象存储中,通过维持流形式的数据总量在阈值之下来保证消息队列、数据管道的性能(因为这类系统的以分区为主的架构设计紧耦合了消息服务和消息存储,而且多数都太过依赖文件系统,随着数据量的增加,系统性能会急剧下降),但人为的数据搬迁不但会提升系统的运维成本,而且搬迁过程中的数据清洗、读取、加载也是对集群资源的巨大消耗。
与此同时,从 Mesos 和 YARN 的流行、Docker 的兴起到现在的 Kubernetes 被广泛采用,整个基础架构正在全面地向容器化方向发展,传统紧耦合消息服务和消息计算的架构并不能很好地适应容器化的架构。以 Kafka 为例,其以分区为中心的架构紧耦合了消息服务和消息存储。Kafka 的分区与一台或者一组物理机强绑定,这带来的问题是在机器失效或集群扩容中,需要进行昂贵且漫长的分区数据重新均衡的过程;其以分区为粒度的存储设计也不能很好利用已有的云存储资源;此外,过于简单的设计导致其为了进行容器化需要解决多租户管理、IO 隔离等方面很多架构上的缺陷。
Apache Pulsar 是一个多租户、高性能的企业级消息发布订阅系统,最初由 Yahoo 研发, 2018 年 9 月从 Apache 孵化器毕业,成为 Apache 基金会的顶级开源项目。Pulsar 基于发布订阅模式(pub-sub)构建,生产者(producer)发布消息(message)到主题(topic),消费者可以订阅主题,处理收到的消息,并在消息处理完成后发送确认(Ack)。Pulsar 提供了四种订阅类型,它们可以共存在同一个主题上,以订阅名进行区分:
独享(exclusive)订阅——一个订阅名下同时只能有一个消费者。
共享(shared)订阅——可以由多个消费者订阅,每个消费者接收其中一部分消息。
失效备援(failover)订阅——允许多个消费者连接到同一个主题,但只有一个消费者能够接收消息。只有在当前消费者发生失效时,其他消费者才开始接收消息。
键划分(key-shared)订阅(测试版功能)——多个消费者连接到同一主题,相同 Key 总会发送给同一个消费者。
Pulsar 从设计之初就支持多租户(multi-tenancy)的概念,租户(tenant)可以横跨多个集群(clusters),每个租户都有其认证和鉴权方式,租户也是存储配额、消息生存时间(TTL)和隔离策略的管理单元。Pulsar 多租户的特性可以在 topic URL 上得到充分体现,其结构是 persistent://tenant/namespace/topic。命名空间(namespace)是 Pulsar 中最基本的管理单元,我们可以设置权限、调整复制选项、管理跨集群的数据复制、控制消息的过期时间或执行其他关键任务。
Pulsar 和其他消息系统的最根本区别在于其采用计算和存储分离的分层架构。Pulsar 集群由两层组成:无状态服务层,它由一组接受和传递消息的 broker 组成;分布式存储层,它由一组名为 bookies 的 Apache BookKeeper 存储节点组成,具备高可用、强一致、低延时的特点。
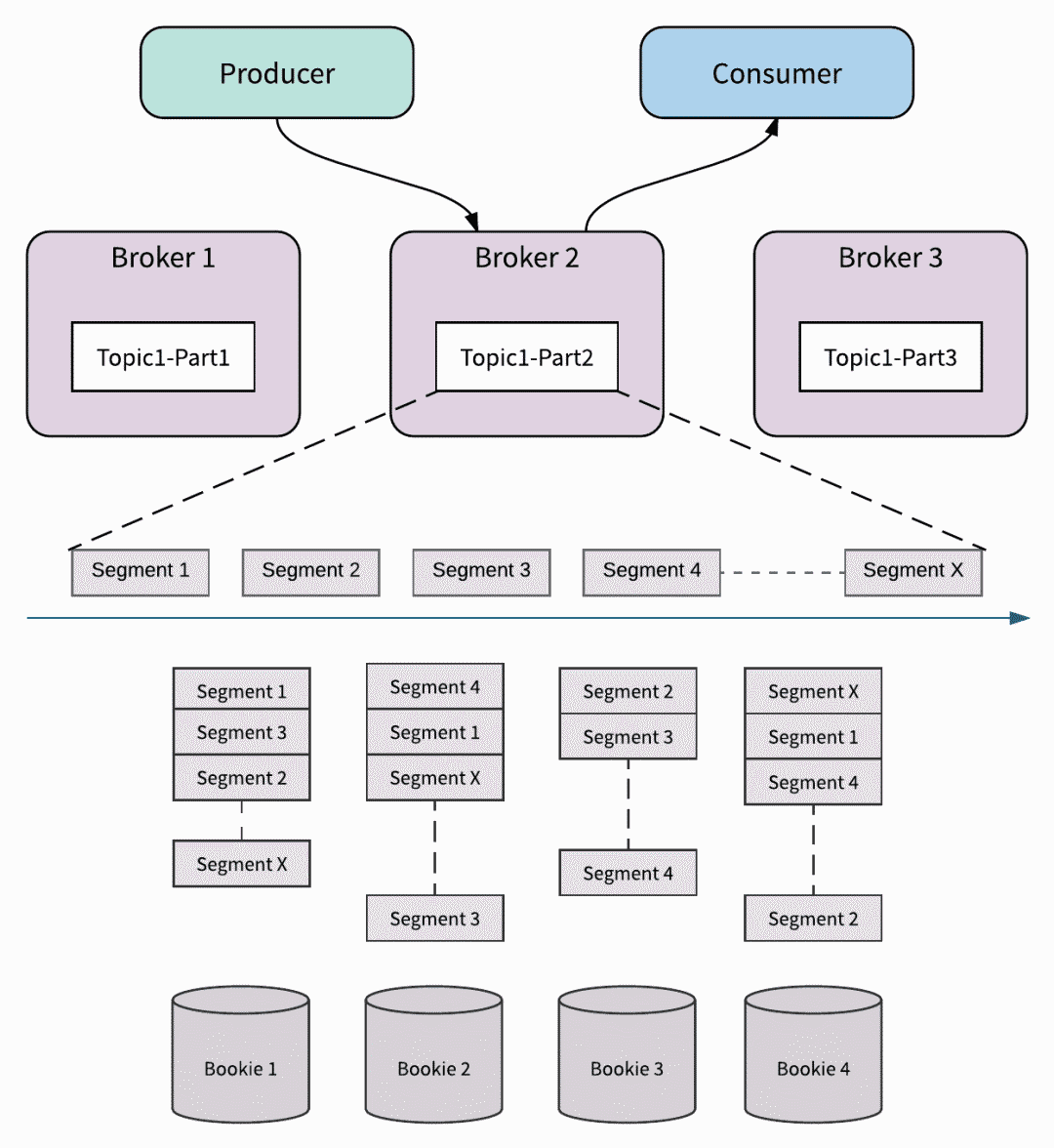
和 Kafka 一样,Pulsar 也是基于主题分区(Topic partition)的逻辑概念进行主题数据的存储。不同的是,Kafka 的物理存储也是以分区为单位,每个 partition 必须作为一个整体(一个目录)被存储在一个 broker 上,而 Pulsar 的每个主题分区本质上都是存储在 BookKeeper 上的分布式日志,每个日志又被分成分段(Segment)。每个 Segment 作为 BookKeeper 上的一个 Ledger,均匀分布并存储在多个 bookie 中。存储分层的架构和以 Segment 为中心的分片存储是 Pulsar 的两个关键设计理念。以此为基础为 Pulsar 提供了很多重要的优势:无限制的主题分区、存储即时扩展,无需数据迁移 、无缝 broker 故障恢复、无缝集群扩展、无缝的存储(Bookie)故障恢复和独立的可扩展性。
消息系统解耦了生产者与消费者,但实际的消息本质上仍是有结构的,因此生产者和消费者之间需要一种协调机制,达到生产、消费过程中对消息结构的共识,以达到类型安全的目的。Pulsar 有内置的 Schema 注册方式在消息系统端提供传输消息类型约定的方式,客户端可以通过上传 Schema 来约定主题级别的消息类型信息,而由 Pulsar 负责消息的类型检查和有类型消息的自动序列化、反序列化,从而降低多应用间的消息解析代码反复开发、维护的成本。当然,Schema 定义与类型安全是一种可选的机制,并不会给非类型化消息的发布、消费产生任何性能开销。
自 Spark 2.2 版本 Structured Streaming 正式发布,Spark 只保留了 SparkSession 作为主程序入口,你只需编写 DataSet/DataFrame API 程序,以声明形式对数据的操作,而将具体的查询优化与批流处理执行的细节交由 Spark SQL 引擎进行处理。对于一个数据处理作业,需要定义 DataFrame 的产生、变换和写出三个部分,而将 Pulsar 作为流数据平台与 Spark 进行集成正是要解决如何从 Pulsar 中读取数据(Source)和如何向 Pulsar 写出运算结果(Sink)两个问题。
为了实现以 Pulsar 为源读取批流数据与支持批流数据向 Pulsar 的写入,我们构建了 Spark Pulsar Connector。
对 Structured Streaming 的支持
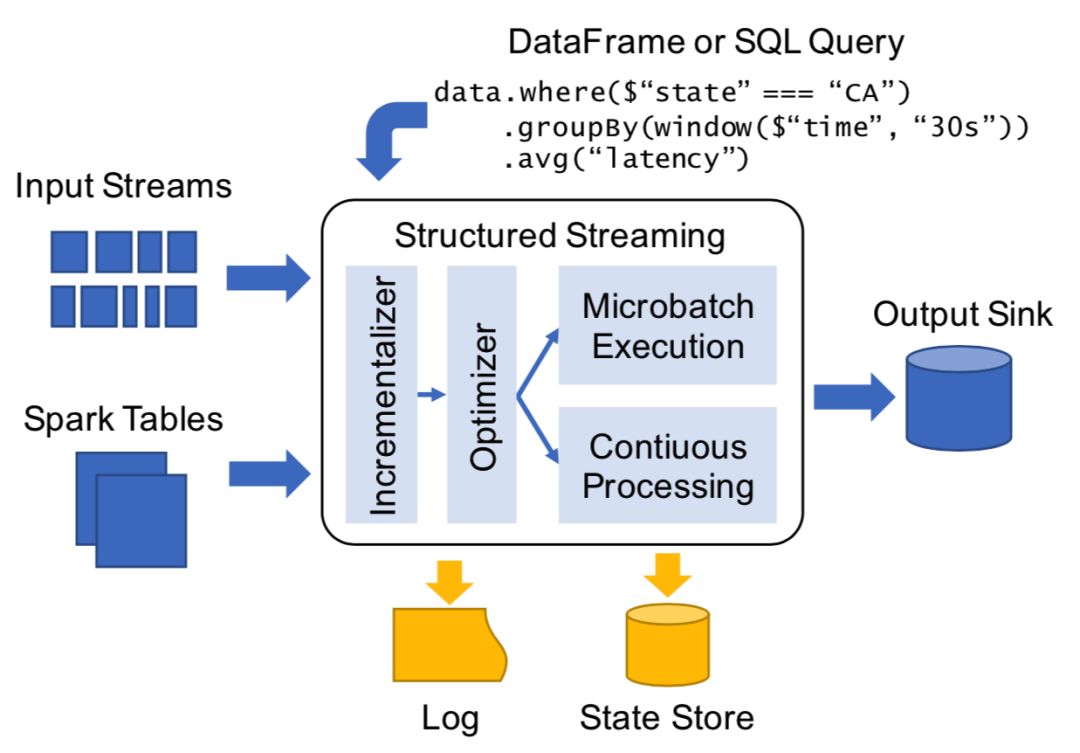
上图展示了 Structured Streaming(以下简称 SS )的主要组件:
输入和输出——为了提供细粒度的容错,SS 要求输入数据源(Source)是可重放(replayable)的;为了提供端到端的 Exactly-Once 的语义,需要输出(Sink)支持幂等写出(一条消息被多次写入与一次写入效果一致,可由 DBMS、KV 系统通过键约束的方式支持)。
API——用户通过编写 Spark SQL 的 batch API(SQL 或 DataFrame)指定对一个或多个流、表的查询,并定义一个输出表保存所有的输出结果,而引擎内部决定如何将结果增量地写到 Sink 中。为了支持流处理,SS 在原有的 Spark SQL API 上添加了一些接口:
触发器(Trigger)——控制引擎触发流处理执行、在 Sink 中更新结果的频率。
水印机制(Watermark policy)——用户通过指定字段做 event time,来决定对晚到数据的处理。
有状态算子(Stateful operator)——用户可以根据 Key 跟踪和更新算子内部的可变状态,完成复杂的业务需求(例如,基于会话的窗口)。
执行层——当收到一个查询时,SS 决定它的增量执行方式,进行优化、并开始执行。SS 有两种可选的执行模型:
Microbatch model(微批处理模式)——默认的执行方式,与 Spark Streaming 的 DStream 类似,将流切成 micro batch,对每个 batch 分别处理。这种模式支持动态负载均衡、故障恢复等机制,适合将吞吐率作为主要性能指标的应用。
Continuous mode(持续模式)——在集群上启动长时间运行的算子,适合处理较为简单、延迟敏感类应用。
Log 和 State Store —— SS 利用两种持久化存储来提供容错保障:一个 Write-ahead-Log(WAL),记录被成功消费且持久化写出的每个数据源中的位置;一个大规模的 state store, 存储长期运行的聚集算子内部的状态快照。当故障发生时,SS 会根据快照的位置,通过重放之后的消息完成流处理状态的恢复。
具体到源码层面,Source 接口定义了可重放数据源需要提供的功能。
trait Source {
def schema: StructType
def getOffset: Option[Offset]
def getBatch(start: Option[Offset], end: Offset): DataFrame
def commit(end: Offset): Unit
def stop(): Unit
}
trait Sink {
def addBatch(batchId: Long, data: DataFrame): Unit
}以 microbatch 执行模式为例:
在每个 microbatch 的最开始,SS 会向 source 询问当前的最新进度(
getOffset),并将其持久化到 WAL 中。随后,source 根据 SS 提供的
startend偏移量,提供区间范围的数据(getBatch)。SS 触发计算逻辑的优化和编译,把计算结果写出给 sink(addBatch),这时才触发实际的取数据操作以及计算过程。
在数据完整写出到 sink 后,SS 通知 source 可以废弃数据(
commit),并将成功执行的batchId写入内部维护的 commitLog 中。
具体到 Pulsar 的 connector 实现中:
在所有批次开始执行前,SS 会调用 schema 方法返回消息的结构信息,在 schema 方法内部,我们从 Pulsar 的 Schema Registry 提取出所有主题的 Schema,并进行一致性检查。
随后,我们为每个主题分区创建一个消费者,按照 (start, end] 返回主题分区中的数据。
当收到 SS 的 commit 通知时,通过
topics中的resetCursor向 Pulsar 标志消息消费的完成。Sink 中构建的生产者则将 addBatch 中获取的实际数据以消息形式追加写入相应的主题中。对批处理作业的支持
在某个时间点执行的批作业,可以看作是对 Pulsar 平台中的流数据在一个时间点的快照进行的数据分析。Spark 对历史数据的查询是以 Relation 为单位,Spark Pulsar Connector 提供 createRelation 方法的实现根据用户指定的多个主题分区构建表,并返回包含 Schema 信息的 DataSet。在查询计划阶段,Connector 的功能分成两步:首先,根据用户提供的一个或多个主题,在 Pulsar Schema Registry 中查找主题 Schema,并检查多个主题 Schema 的一致性;其次,将用户指定的所有主题分区进行任务划分(Partition),得到的分片即是 Spark source task 的执行粒度。
Pulsar 提供了两层的接口对其中的数据进行访问,基于主题分区的 Consumer/Reader 接口,以传统消息接收为语义的顺序数据读取;Segment 级的读接口,提供对 Segment 数据的直接读取。因此,相应地从 Pulsar 读数据执行批作业可以分成两种粒度(即读取数据的并行度)进行:以主题分区为粒度(每个主题分区作为一个分片);以 Segment 为粒度(将一个主题分区的多个 Segment 组织成一个分片,因此一个主题分区会有多个对应的分片)。你可以按照批作业的并行度需求和可分配计算资源选择合适的消息读取的并行粒度。另一方面,将批作业的执行存储到 Pulsar 也很直观,你只需指定写入的主题和消息路由规则(RoundRobin 或者按 Key 划分),在 Sink task 中创建的每个生产者会将待写出的消息送至对应的主题分区。
根据一个或多个主题创建流处理 Source。
val df = spark
.readStream
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("admin.url", "http://localhost:8080")
.option("topicsPattern", "topic.*") // Subscribe to a pattern
// .option("topics", "topic1,topic2") // Subscribe to multiple topics
// .option("topic", "topic1"). //subscribe to a single topic
.option("startingOffsets", startingOffsets)
.load()
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]构建批处理 Source。
val df = spark
.read
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("admin.url", "http://localhost:8080")
.option("topicsPattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]使用数据中本身的 topic 字段向多个主题进行持续 Sink。
val ds = df
.selectExpr("topic", "CAST(__key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.start()将批处理结果写回 Pulsar。
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.write
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("topic", "topic1")
.save()注意
由于 Spark Pulsar Connector 支持结构化消息的消费和写入,为了避免消息负载中字段和消息元数据(event time、publish time、key 和 messageId)的潜在命名冲突,消息元数据字段在 Spark schema 中以双下划线做为前缀(例如,__eventTime)。
参考资料
Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark
https://cs.stanford.edu/~matei/papers/2018/sigmod_structured_streaming.pdf
Structured Streaming 源码解析系列
https://github.com/lw-lin/CoolplaySpark
Pulsar 官网 https://pulsar.apache.org/
Spark Pulsar Connector 即将开源,对 Spark 集成感兴趣的同学可以关注 Pulsar Shenzhen Meetup 和 StreamNative 公众号。
Apache Pulsar 是下一代云原生分布式流数据平台,它源于 Yahoo,2016 年 12 月开源,2018 年 9 月正式成为 Apache 顶级项目,逐渐从单一的消息系统演化成集消息、存储和函数式轻量化计算的流数据平台。在 Apache Pulsar 快速发展的过程中,社区的伙伴们也致力于硅谷以外的布道之旅,在中国社区开始了不平凡的历程。6 月 29 日,来自腾讯和 Pulsar 社区的开源爱好者们将齐聚一堂,共同探讨 Pulsar 最新动态,包括:
Apache Pulsar 发展历史和用户案例。
Apache Pulsar 2.4.0 新功能。
Flink 在腾讯的实践,Flink 和 Pulsar 的集成应用。
Pulsar 和 Spark 批流融合的数据存储和分析平台。
Pulsar IO 运行原理与周边生态。
Go Functions 的设计与实现。
访问以下链接或点击【阅读原文】,报名参加 Pulsar Shenzhen Meetup。
https://www.huodongxing.com/event/9495713659500


你也「在看」吗?👇



