Datalore初体验:JetBrains的云端机器学习开发环境
如果说“古代”的编辑器圣战是Vi和Emacs,那当今时代的IDE圣战可能是Eclipse和Intellij了。大多数人都觉单Intellij是后出转精。不过,Eclipse其实有一个独特的优势,Eclipse Che,基于Eclipse的云端开发环境。Eclipse Che可以方便地统一开发环境,避免不同系统、不同硬件导致的各种兼容问题,同时节省开发人员配置环境的时间。Intellij乃至其他JetBrains系的IDE,则都只有本地版本。
不过,JetBrains今年倒是出了一个云端开发环境Datalore,不过并不针对Java开发者,而是面向机器学习。

经过三个多月的公测,Datalore的基本功能也比较完善了。所以今天我们将通过一个具体的例子(使用卷积网络分类服饰图像)来分享下基于Datalore开发机器学习项目的体验。
首先我们访问datalore.io,可以使用Google账号或JetBrains账号登录。如果没有的话,可以注册一个。
登录后,点击New workbook图标,新建一个workbook。
如果你接触过Jupyter Notebook,那么workbook可以看成是Jupyter Notebook的加强版。如果你没接触过,那么简单来说,workbook是内嵌代码的文档,其中的代码是可以直接运行的。
workbook是左右双栏,左边是源代码,右边显示结果。
我们注意到,左边默认提供了一些常用操作,包括load dataset(加载数据集)、standard imports(标准导入),等等。如果你接触过JetBrains家的IDE,那么你应该已经意识到,这是JetBrains系列IDE广受赞誉的意图行动(intention actions)功能。
我们首先要做的是引入相应的库,当把鼠标悬浮到standard imports(标准导入)后,会有悬浮提示,告诉我们所谓的标准导入包括numpy、pandas、matplotlib,还有datalore定制的一个绘图库。如果你打算做一点数据分析,或者数据可视化的工作,那这个标准导入就很方便。只需点击一下就可以自动生成导入语句,不用一行一行敲了。
不过我打算试下机器学习,所以就不用这个标准导入了。我将导入TensorFlow:
import tensorflow as tf
咦,我只输了i、m两个字母,workbook界面就出现了这个:
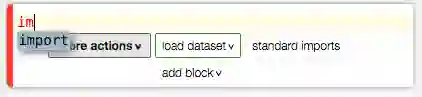
是啊,JetBrains出品的东西怎么少得了自动补全呀?按回车就好,不用一个一个字母敲了。
然后我输入tensorflow。咦?没有补全。感觉不太妙。

果然,tensorflow显示为红色,意味着出问题了。再看右边,是报错信息,提示没有tensorflow这个模块。
看来tensorflow没有预装。我们装一下。菜单选择Tools(工具)->Library Manager(库管理器),输入tensorflow搜索。
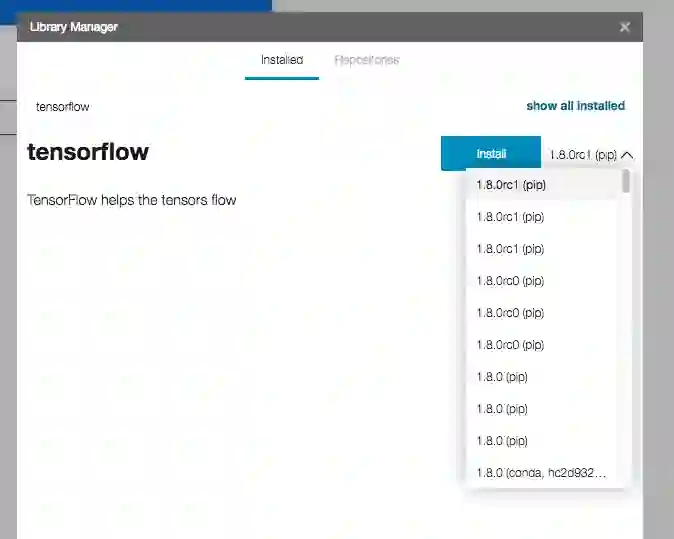
鼠标点下就可以装了,右边还有下拉菜单可以选版本。
稍等片刻就装好了,其间会弹出窗口显示安装信息,等看到绿色的Installation complete(安装完成)就说明安装成功了。可以点Close(关闭)把窗口关了。
由于安装了新的包,Datalore会提示你需要重启内核(restart kernel),确认就可以了。然后我们看到,报错信息消失了。我们可以接着键入as tf了。
然后我们需要加载数据集。点击load dataset,可以看到,其中包括了一些常用的数据集。
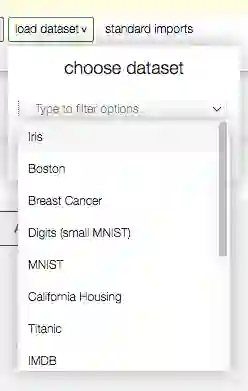
前面我已经说过,我打算试下机器学习。而且我刚安装了TensorFlow。那TensorFlow入门最经典的数据集就是MNIST,Datalore也提供了。
不过么……
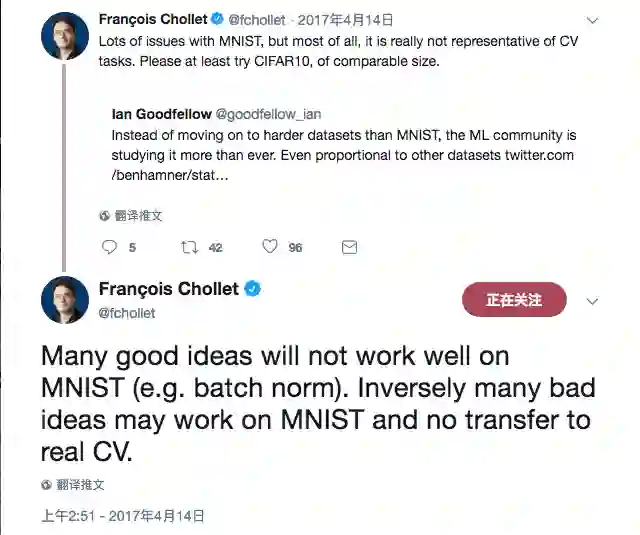
“花书”作者Ian Goodfellow、Keras作者François Chollet一起炮轰MNIST
上面的推特就不逐字逐句翻译了,大意就是MNIST不能代表现代的计算机视觉任务,学术界不应该老是用MNIST。
所以我也赶下时髦,换个数据集用用。好吧,我只是找了个借口,不管怎么说,MNIST用来入门还是不错的。其实我只是看了太多MNIST的入门教程,有点审美疲劳了。
手写数字看厌了,毕竟数字又不能当饭吃。不如换成衣服、鞋子吧,虽然也不能吃,好歹可以穿啊。
隆重介绍MNIST的时尚版,Fashion-MNIST。

TensorFlow的API写起来还是有点啰嗦,所以我决定使用Keras。而且,Keras的datasets模块自带获取和加载Fashion-MNIST的方法。
按照之前描述的方法,通过Library Manager安装Keras后,加载Fashion-MNIST数据集:
from keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
好吧,这行代码看着稍微有点长,其实在Datalore里打起来非常快,因为很多地方稍微敲一两个字母就可以一路补全下去。与此同时,我们能在右边看到,Datalore会自动帮我们下载数据集,并在下载完成后自动加载数据集。
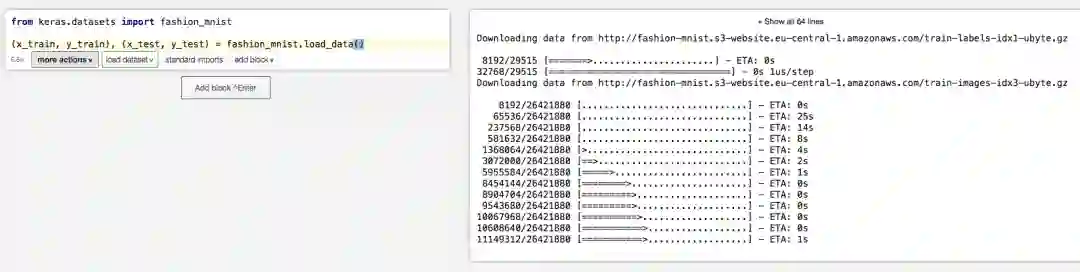
好了。数据集加载好了,下面我们将构建一个模型分类服饰。分类图像最常用的是卷积神经网络,这也是我们的选择。图像的每个像素是由整数表示的(0-255的亮度值),为了提高训练的效率,我们需要首先将其归一化:
x_train = x_train.astype('float32') / 255
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
除了归一化外,我们还顺便重整了一下数据的形状为28, 28, 1(Fashion-MNIST中的图像为28x28的灰度图像)。
和MNIST一样,Fashion-MNIST中的图像分属10类:

图片来源:Margaret Maynard-Reid
在数据集中,标签(y_train)是类别变量,具体而言,是取值范围为0-9的整数。一般而言,为了便于模型利用,我们需要将其转成one hot编码。y_test同理。
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
这里有一个提高效率的小技巧。在输完y_train这行后,按Ctrl + D(Mac OS X下是Command + D),可以复制当前行。之后将复制行中的两个y_train改成y_test就可以了。
设计预处理完毕,接着就是设计模型了。由于本文的主题不是关于如何设计卷积网络,因此我这里就偷个懒,直接使用Keras自带的MNIST分类器样例(examples/mnist_cnn.py),看看这个为MNIST设计的CNN分类器在Fashion-MNIST上的效果如何。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(28, 28, 1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
这个CNN网络模型还是比较简单的。我们有两个卷积层(均使用3x3的卷积核和ReLU激活),之后加上最大池化层,然后是Dropout层和全连接层,最后,因为需要预测10个分类,所以顺理成章地在输出层中使用了softmax激活。
接下来我们编译模型,因为是分类问题,所以损失函数很自然地使用了交叉熵。优化使用了Adadelta,这是Matthew D. Zeiler在2012年底提出的一种优化算法,使用自适应的学习率。
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
然后就是训练和评估,并输出结果:
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=128,
epochs=20,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('测试损失', score[0])
print('测试精确度', score[1])
由于Datalore目前为免费公测阶段,只有t2.medium规格的AWS主机可用(2核、4 GB内存),因此,大约需要等1小时完成训练。等以后正式上线了,会有GPU主机可用(p2.xlarge,4 cpu核心、1 gpu核心、61GB 内存,12 GB显存)。当然,你也可以尝试去Datalore官方论坛申请GPU主机。
结果:
测试损失 0.22063894088864328
测试精确度 0.9295
20个epoch后精确度超过90%,比我预料中的表现要好。
看到这个结果,我有点好奇这个模型在MNIST上的表现有多好。Keras文档告诉我精确度超过99%,不过,俗话说得好,耳听为虚,眼见为实。我想亲自试一试。
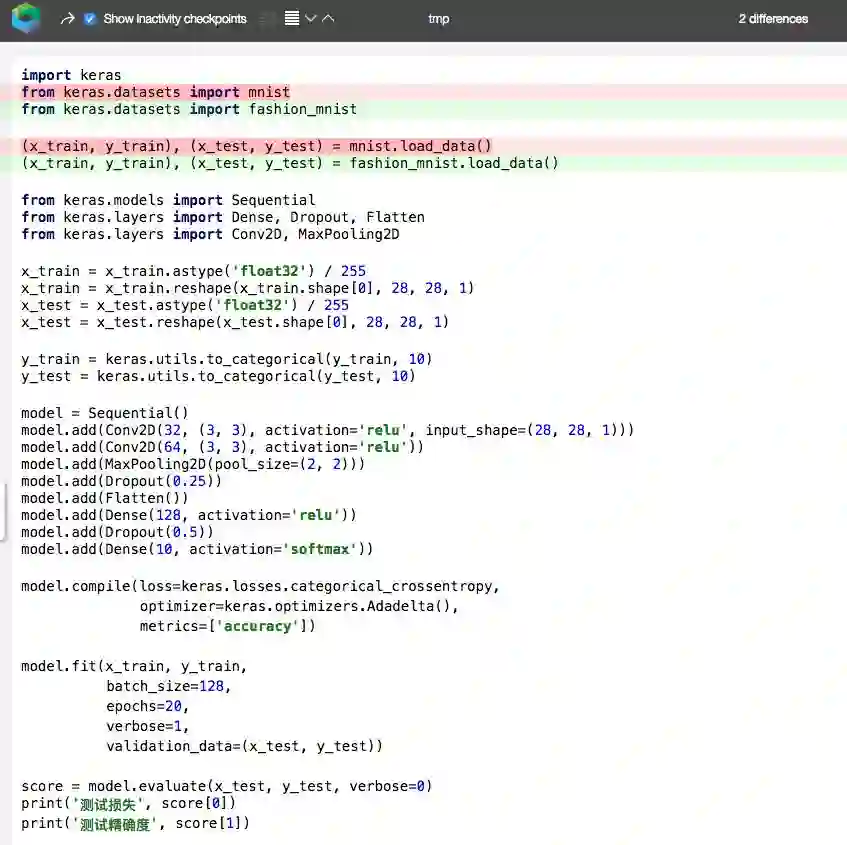
实际上,上面的代码只需改动两处,就可以变为分类MNIST。
将开头两行中的fashion_mnist替换为mnist:
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
其他的都不用动。就这么简单!
不过,在此之前,先让我们保存一下当前的版本,以备以后继续使用。
通过菜单Tools ->Add history checkpoint,我们可以添加一个checkpoint,比如说,起名为keras-mnist-cnn.
然后,通过菜单Tools ->History,我们可以查看workbook的历史。其中,第一个checkpoint是创建workbook时的状态。除此之外,勾选左上角的Show inactivity checkpoints之后,我们能看到很多Datalore自动保存的checkpoint,你再也不用担心不小心丢失代码了。没错,如果你接触过JetBrain系的IDE,这就是其历史功能。
你不仅可以查看不同的checkpoint,还可以比较不同checkpoint之间的区别:
这个功能在调bug的时候是非常方便的。说到调bug,在Datalore下调bug还是比较方便的。比如,假设我们把模型的输入形状改一下,故意改成错误的:

这虽然是一个故意编造的简单错误,但确实是可能出现的错误。因为有的情况下,频道是放在最前的。有的时候不小心,就会出现这种失误。
一旦我们做了这个改动后,Datalore几乎立刻反应过来。
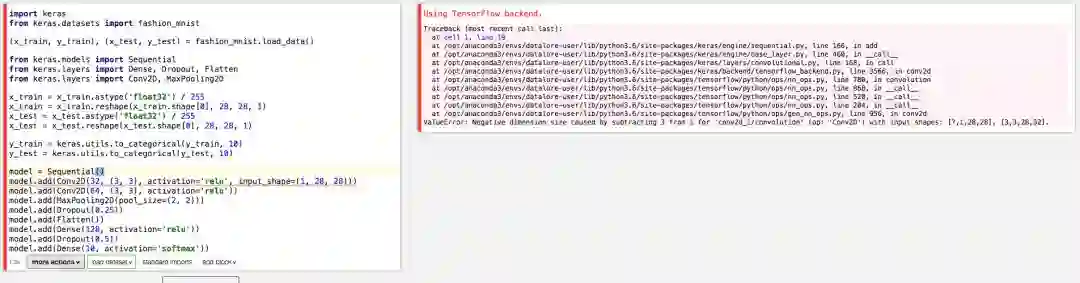
从上图我们可以看到:
代码单元左边框为红色,提示我们这里有误。正常情况下,左边框为闪烁的绿色(提示正在进行运算)或黄色(提示运算完成)。
右侧结果为报错的Trackback.
左侧代码的出错行有红色波浪线标识。悬浮鼠标于其上,我们能看到报错信息,如下图所示。

其实很多地方,悬浮鼠标都能给出相应的提示,比如悬浮到y_train后,会提示这是一个变量(而不是函数),甚至Datalore能推断其类型numpy.ndarray。
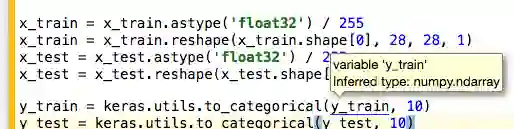
而单击一个变量后,Datalore会高亮这一变量的所有用例:
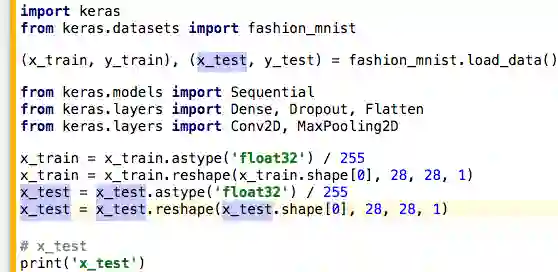
从上图我们可以看到,Datalore没有直接简单粗暴地匹配字符串,最后两行中,注释和字符串里的x_test并没有高亮。
好了,说了这么多。让我们回到之前的MNIST数据集训练上来。如前所述将两处fashion_mnist替换为mnist后,我们在MNIST数据集上训练模型,并评估其表现。
最终训练了一个多小时(和Fashion-MNIST时间差不多,毕竟这两个数据集的图像规格是一样的,都是28x28的灰度图像),20个epoch后精确度为0.9918,看来Keras文档所言不虚。
当然,除了代码之外,workbook里还能写文档。文档使用Markdown格式,加上了LaTeX公式扩展。

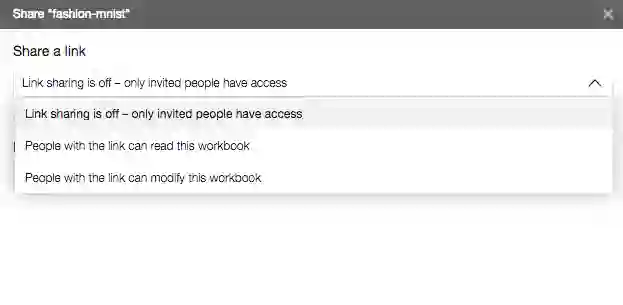
另外,线上开发环境的一大优势就是方便协作。Datalore也不例外。通过菜单File ->Share即可邀请别人协作,一起开发。
分享共有3种方式:
输入Datalore用户名或邮箱,邀请对方协作开发。
分享一个链接,通过这个链接访问的用户可以协作开发。
同样是分享一个链接,只不过这是一个只读链接,通过这个链接访问的用户只能查看,无法修改。
最后,附上快捷键列表(有些已经在前文中介绍过):
C-空格(C在mac os x上是Command键,其他平台上是ctrl键)可以触发自动补全。C-d重复当前行在Markdown单元中,按alt + 左右方向键可以在单词间跳转。






