
更多相关文章阅读
GitLab 是如何用 Headless Chrome 测试的
本文由DevOps时代高翻院翻译发布
译者:CK星空
原文链接:https://about.gitlab.com/2017/12/19/moving-to-headless-chrome/
下面的例子介绍了GitLab如何切换到Headless Chrome
GitLab最近从PhantomJS转变为Headless Chrome,用于前端测试和RSpec功能测试(ruby测试框架)。在这篇文章中,我们会详细介绍这个变化的原因,面临的挑战,以及解决方案。我们希望这能帮助其他人也能进行类似的转变。
我们现在有一个真实可靠的方法在现代浏览器中测试GitLab。当直接运行在Chrome的时候,这个方法已经提高写测试和调试的能力。还迫使我们去面对和清理一些在测试中的hacks(技巧)。
背景
PhantomJS(http://phantomjs.org/)作为GitLab测试框架的一部分已经接近有五年(https://gitlab.com/gitlab-org/gitlab-ce/commit/ba25b2dc84cc25e66d6fa1450fee39c9bac002c5)了。它是一个非常有用的工具,在选择不多的无头(无UI)环境下运行浏览器集成测试。但是,有一些缺陷:
PhantomJS(v2.1.1)的最新版本是用三年前的QtWebKit(https://trac.webkit.org/wiki/QtWebKit)(Webkit V538.1的一个分支版本,user-agent string)编译的。就像Safari 7 运行在 macOS 10.9。貌似集成了一个现代浏览器,但事实又不是那样。它有一个不同的JavaScript引擎,一个老掉牙的渲染引擎,有怪癖,还缺失一些功能。
现在,GibLab支持Firefox, Chrome, Safari, 和Microsoft Edge/IE中新和旧的主要版本(https://docs.gitlab.com/ce/install/requirements.html#supported-web-browsers)。PhantomJS的能力接近或低于我们最低的标准。很多现代浏览器的功能不支持,或者需要供应商前缀(-webkit-),还有补丁也不符合浏览器的要求。我们可以在测试环境中选择性地增加这些补丁,前缀和解决方法。但是这么做会添加技术债,引起混乱,并使测试环境不能代表真实的生产环境。(PhantomJS是生活在远古时代吗?)在大多数情况下我们选择忽略它或绕过他们(下面会提到(https://about.gitlab.com/2017/12/19/moving-to-headless-chrome/#trigger-method))。
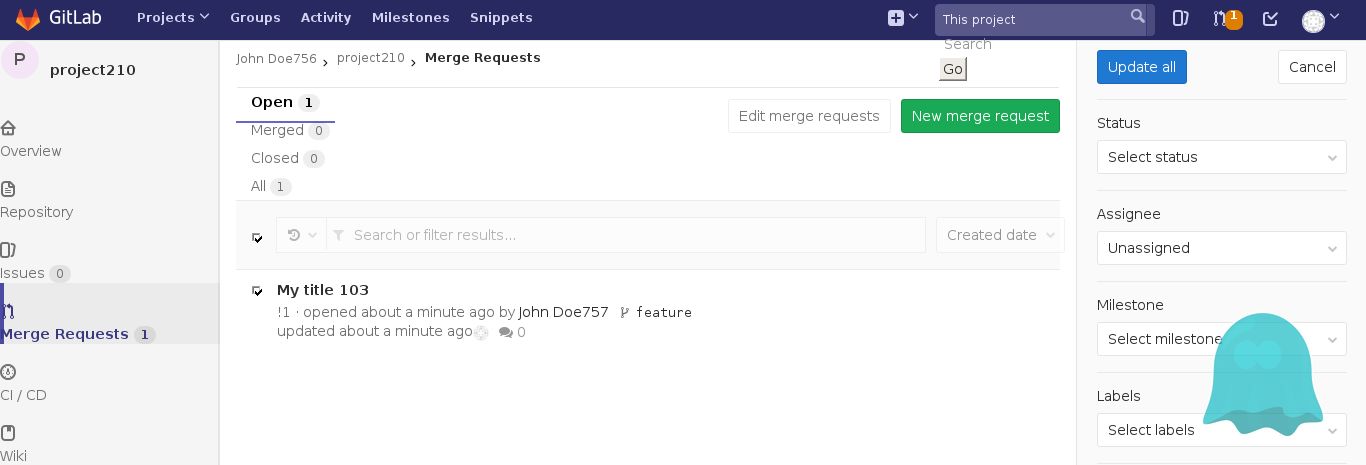
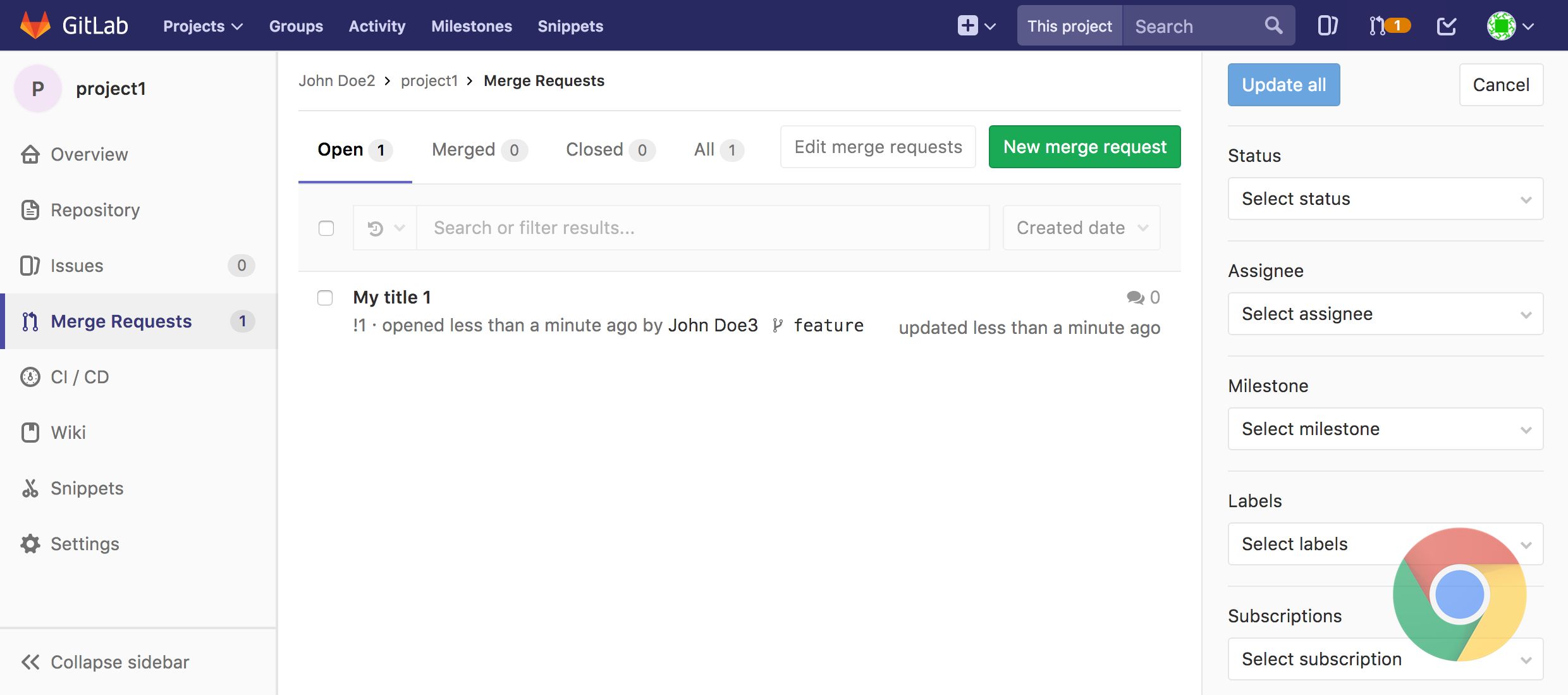
下面两张图,一张是用PhantomJS渲染的页面,第二张是用Google Chrome渲染的:
可以看到PhantomJS的过滤标签是水平渲染的,侧边栏的图标分开渲染,全局搜索区域从导航栏溢出等问题。
尽管看上去很丑,但是大部分情况下我们仍然用它运行功能测试。只要页面的元素还能看得见和能点击,只是GitLab在浏览器中的确会出现某些罕见的情况。
Headless Chrome
今年四月份,新闻报道(https://news.ycombinator.com/item?id=14101233)称Chrome 59会支持原生跨平台的无头模式(headless mode)。Chrome之前是有可能在CI/CD的环境下运行虚拟帧缓冲器(https://gist.github.com/addyosmani/5336747)来模拟Headless Chrome的,但需要大量的内存,而且额外复杂。一个原生的无头浏览器会改变测试的风云变幻格局。(我没头,不怕砍头!)开发者竟然能在现代浏览器的无头环境下进行集成测试!
说时迟,那时快,PhantomJS的首席开发者Vitaly Slobodin就宣布新项目不会再发布:
This is the end - https://t.co/GVmimAyRB5#phantomjs 2.5 will not be released. Sorry, guys!
— Vitaly Slobodin (@Vitalliumm) April 13, 2017
显然,我们需要逐渐放弃PhantomJS。所以我们提交了一个issue(https://gitlab.com/gitlab-org/gitlab-ce/issues/30876),并下载了Chrome 59 beta 版本,开始了实验。
前端测试(Karma)
我们的前端测试套件是结合Karma测试运行器和Google Chrome配合使用,意外的简单(merge request(https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/12036))。从2.1.0版本开始, Karma-chrome-launcher插件非常快速地支持无头模式,而且能大部分代替掉PhantomJS launcher。一旦我们重新构建了 CI/CD build images(https://gitlab.com/gitlab-org/gitlab-build-images/merge_requests/41) 并包含Google Chrome 59(减少一些繁琐的超时设置),成功了!我们还删除了一些相当丑陋且特殊的PhantomJS hacks,Jasmine需要内嵌浏览器的功能。
后端功能测试(RSpec + Capybara)
我们的功能测试是使用RSpec+Capybara(https://github.com/teamcapybara/capybara),进行完整的数据库,后端和前端交互的端到端集成测试。在转换到headless Chrome之前,我们使用的是Poltergeist(https://github.com/teampoltergeist/poltergeist),它是一个作为Capybara的PhantomJS驱动器(driver)。它会启动一个PhantomJS浏览器实例并指导它浏览,填写表格,并在网页上点击验证等所有应该有的行为。
从PhantomJS转变到Google Chrome需要替换Poltergeist为Selenium 和 ChromeDriver, 安装简单。在macOS中,你可以用命令brew install chromedriver,在Linux中是相似的。之后添加selenium-webdrivergem 到测试依赖和配置Capybara:
require 'selenium-webdriver' Capybara.register_driver :chrome do |app| options = Selenium::WebDriver::Chrome::Options.new( args: %w[headless disable-gpu no-sandbox] ) Capybara::Selenium::Driver.new(app, browser: :chrome, options: options) end Capybara.javascript_driver = :chrome
Google表示disable-gpu选项是必要的(https://developers.google.com/web/updates/2017/04/headless-chrome#cli),直到一些bugs被修复。在GitLabs的CI/CD 环境下,no-sandbox选项对于Chrome运行在Docker容器也是有必要的。Google提供了headless Chrome和Selenium一起配合使用的指引(https://developers.google.com/web/updates/2017/04/headless-chrome)。
在我们最终的实施过程中,我们有条件地添加了headless选项,除非你设置了CHROME_HEADLESS=false。这样很容易在调试或写测试的时候取消无头模式。看到自己写的测试在浏览器自动运行也是很有趣的。
export CHROME_HEADLESS=false bundle exec rspec spec/features/merge_requests/filter_merage_requests_spec.rb
Poltergeist和Selenium的区别
更换驱动的过程并不像更换前端测试套件那么简单。一旦我们改变了Capybara的设置,很多测试(脚本)会失效。产生这些差异的原因是Selenium/ChromeDriver使用了Capybara driver的API,而Poltergeist/PhantomJS却没有。以下是我们遇到的挑战:
1.JavasScript的模态框不再接受自动化测试
我们经常写JavaScriptconfirm("Are you sure you want to do X?");在执行破坏性操作(如删除分支或从组中删除用户)时单击事件。在Poltergeist下,一个.click动作会自动点击alert()和confirm()的模态框。但在Selenium下,你需要输入accept_alert,accept_confirm,或者dismiss_confirm中的其中一个。例如:
# Before page.within('.some_selector') do click_link 'Delete' end # After page.within('.some-selector') do accept_confirm { click_link 'Delete' } end
2.Selenium的Element.visible?对于空元素返回false
如果你想测试一个空的div或者span,Selenium不会认为这个是”visible”的。在我们的功能测试中,如果设置Capybara.ignore_hidden_elements = true了,就不会有太严重的问题。在Poltergeist中使用find('.empty-div')是没问题的,需要用 visible: :any去选择元素。
# Before find('.empty-div') # After find('.empty-div', visible: :any) # or find('.empty-div', visible: false)
更多在Capybara and Hidden elements(https://makandracards.com/makandra/7617-change-how-capybara-sees-or-ignores-hidden-elements)。
3.Poltergeist的Element.trigger('click')在Selenium是不可用的
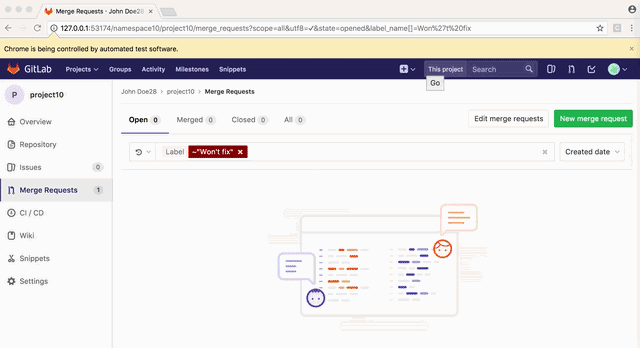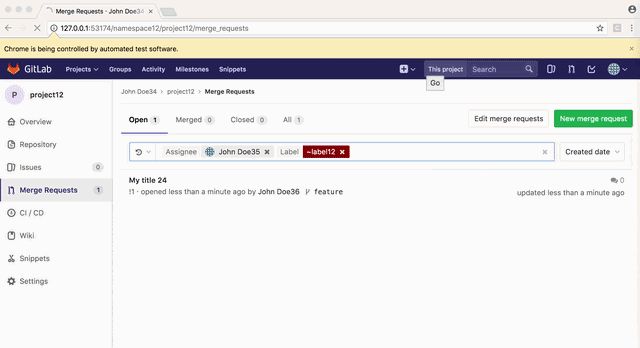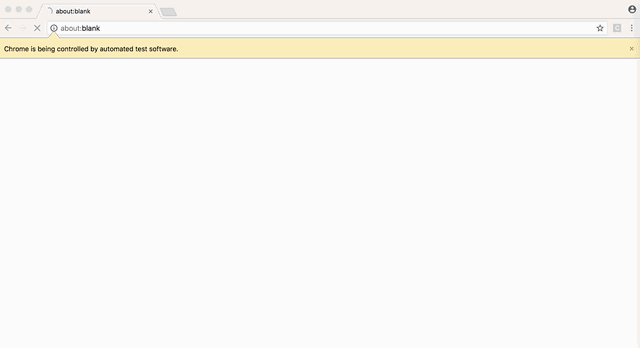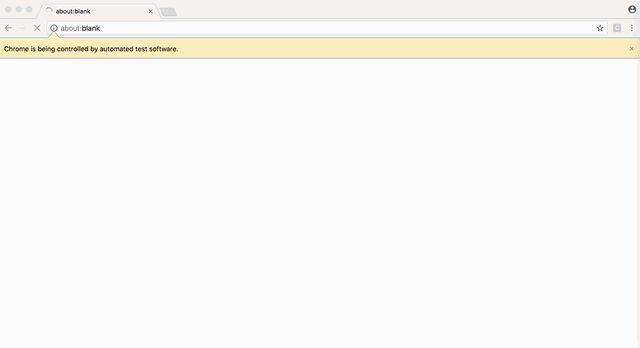
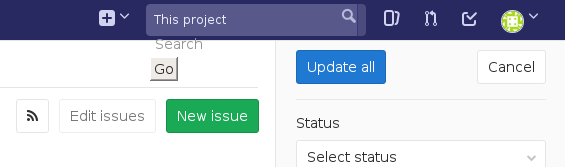
在Capybara中,当你使用find('.some-selector').click时,您所点击的元素必须是可见的,并且不能被任何重叠的元素所遮盖。链接不能被点击的情况有时会出现在Poltergeist/PhantomJS中,因为它的CSS对sans-prefixes支持很弱。例如下面这个例子:
这搜索表单的布局被破坏,实际上是在“Update all”按钮的顶部放置了一个不可见的元素,使其无法点击。Poltergeist提供了一个.trigger('click')的方法来解决这个问题。这个方法时触发一个DOM事件来模拟点击,而不是实际点击元素。这并不是一个好的做法,但是我们经常会遇到类似的问题,很多开发者都习惯这样解决。这会导致一些懒惰和草率的测试用例。例如,有些人可能会使用.trigger作为快捷方式,点击一个下拉菜单后面的链接,当一个正确的书面测试应该。点击某处关闭下拉,然后点击它后面的项目。
Selenium不支持.trigger方法。现在我们使用更准确的渲染引擎不会破坏布局,许多这些实例可以通过用.click替换.trigger('click')来解决。但是由于上面提到的一些不好的用法,并不一定能解决问题。
当然会有一些技巧来代替.trigger。你可以通过聚焦元素来模拟点击和按下”return”键,或者使用JavaScript去触发点击事件。我们决定花时间纠正这些错误的测试,这样正常的.click可以再次使用。最后,如果我们的测试是为了模拟一个真正的用户与页面交互,那我们应该做出真实的用户那样的行为。
# Before find('.obscured-link').trigger('click') # After # bad find('.obscured-link').send_keys(:return) # bad execute_script("document.querySelector('.obscured-link').click();") # good # do something to make link accessible, then find('.link').click
4.Element.send_keys只适用于可聚焦元素
在代码中,我们会用find('.boards-list').native.send_keys('i')来测试快捷键。事实证明,Chrome不会允许你将send_keys(关键字)发送给任何无法“聚焦”的元素,例如链接,表单元素,document body,或者是带有tab index的元素。
我们经历过的情况下,在页面元素触发send_keys在会起作用,因为事件处理器正在监听:
# Before find('.some-div').native.send_keys('i') # After find('body').native.send_keys('i')
5.Element.send_keys不支持non-BMP 字符(例如emoji)
在一些测试中,需要填写表情符号字符。在Poltergeist会这么做:
# Before find('#note-body').native.send_keys('@💃username💃')
在Selenium中会得到下面的错误信息:
Selenium::WebDriver::Error::UnknownError: unknown error: ChromeDriver only supports characters in the BMP
为了解决这个问题,我们添加了JavaScript方法进测试套件,可以模拟输入和触发相同的DOM事件(https://gitlab.com/gitlab-org/gitlab-ce/blob/a8b9852837/app/assets/javascripts/test_utils/simulate_input.js),每次点击键盘都会产生真实的点击。然后结合ruby helper(https://gitlab.com/gitlab-org/gitlab-ce/blob/a8b9852837/spec/support/input_helper.rb)方法一起使用:
# After include InputHelper simulate_input('#note-body', "@💃username💃")
6.设置cookies变得更复杂
在你打算测试页面之前,想要设置一些cookie是相当常见的,无论是模拟用户会话或者是切换设置。用Poltergeist的话是很简单的。你可以用page.driver.set_cookie,提供一对简单的key/value,用正确的域和权限设置一个cookie。
Selenium就麻烦一点。方法是page.driver.browser.manage.add_cookie,它有两个注意事项:
你不能设置cookies除非你的cookies和你访问的页面的域是同一个。
麻烦的是,你不能改变路径(
path)参数(否则的话永远不起作用),所以最好在根路径设置cookies。在你访问你的页面前,Chrome的url一般是显示
about:blank;的。当你试图在那设置cookie,它会拒绝。因为没有主机名,你也不能通过提供一个域作为参数来改变主机名。Selenium documentation(http://docs.seleniumhq.org/docs/03_webdriver.jsp#cookies)建议这么做:
If you are trying to preset cookies before you start interacting with a site and your homepage is large / takes a while to load, an alternative is to find a smaller page on the site (typically the 404 page is small, e.g. http://example.com/some404page).
# Before before do page.driver.set_cookie('name', 'value') end # After before do visit '/some-root-path' page.driver.browser.manage.add_cookie(name: 'name', value: 'value') end
7.检查页面请求/响应方法丢失
Poltergeist非常方便是因为有page.status_code和page.response_headers,这些方法也出现在Capybara默认的RackTest驱动程序中,使检查服务器的原始响应变得容易。除了浏览器呈现响应的方式之外。它也允许你在向服务器发出的请求中注入头文件,例如:
# Before before do page.driver.add_header('Accept', '*/*') end it 'returns a 404 page' visit some_path expect(page.status_code).to eq(404) expect(page).to have_css('.some-selector') end
Selenium没有采用这种方法,作者也没打算这么做(https://github.com/seleniumhq/selenium-google-code-issue-archive/issues/141#issuecomment-191404986),所以我们自己开发一个解决方案。有些人建议用代理服务器运行ChromeDriver,拦截所有来往于服务器的数据,但这似乎过度了。相反,我们选择创建一个轻量级的Rack中间件(https://gitlab.com/gitlab-org/gitlab-ce/blob/a8b9852837/lib/gitlab/testing/request_inspector_middleware.rb)和响应助手类(https://gitlab.com/gitlab-org/gitlab-ce/blob/a8b9852837/spec/support/inspect_requests.rb),以拦截数据来进行检查。这与我们已经使用的RequestBlockerMiddleware(https://gitlab.com/gitlab-org/gitlab-ce/blob/master/lib/gitlab/testing/request_blocker_middleware.rb)类似,可以智能地完成`wait_for_requests`测试。就像这样:
# After it 'returns a 404 page' requests = inspect_requests do visit some_path end expect(requests.first.status_code).to eq(404) expect(page).to have_css('.some-selector') end
在inspect_requests块中,Rack中间件将记录所有请求和响应,并将它们作为数组返回以供检查。这包括正在访问的页面以及随后的XHR和资源请求,但是初始路径请求将是数组中的第一个。
你也可以使用相同的助手函数注入标头,如下所示:
# After inspect_requests(inject_headers: { 'Accept' => '*/*' }) do visit some_path end
这个中间件应该在堆栈的早期注入,以确保其它中间件拦截或修改请求/响应都会被我们的测试监测到。我们在测试环境配置中包含这一行:
config.middleware.insert_before('ActionDispatch::Static', 'Gitlab::Testing::RequestInspectorMiddleware')
8.浏览器控制台不再输出到终端
当测试运行时,Poltergeist会自动将控制台(console)的所有消息直接输出到终端。如果你的前端代码中有一个导致测试失败的bug,这个功能将使调试更容易,因为你可以检查测试的终端输出的错误消息或堆栈跟踪,或者将console.log()注入到JavaScript以查看正在运行的代码。很遗憾,Selenium不再支持这样操作了。
但是,通过配置Capybara可以收集浏览器日志,如下所示:
capabilities = Selenium::WebDriver::Remote::Capabilities.chrome( loggingPrefs: { browser: "ALL", client: "ALL", driver: "ALL", server: "ALL" } ) # ... Capybara::Selenium::Driver.new( app, browser: :chrome, desired_capabilities: capabilities, options: options )
这将允许你使用以下方式访问日志,例如在测试失败的情况下:
page.driver.manage.get_log(:browser)
这样比Poltergeist笨重得多,但这是我们目前最好的方案了。谢谢Larry Reid(http://technopragmatica.blogspot.com/2017/10/switching-to-headless-chrome-for-rails_31.html)在博客中的提示!
结果
关于性能,改变之前通过对10个RSpec测试集进行非科学分析来衡量变化,改变后也通过10个测试。分解在这些管道之间添加或删除的任何测试。结果是:
Before:5h 18m 52s
After:5h 12m 34s
缩短了大概六分钟,或2%的总运行时间。统计的意义不大,所以我也没打算声称我们提高了测试速度。
我们提升的是测试准确率,还有极大地改进了测试和调试工具。现在,当一个 CI/CD job 失败的时候所有生成的Capybara截图,看起来是与你的浏览器是完全一样的,而不是像上面那张破碎的PhantomJS截图。现在可以通过关闭无头模式来交互式地检查失败的测试,将一个byebug行放入测试用例,并在提示中键入命令时观看浏览器窗口。这项技术在项目中非常有用。你可以在GitLab.com的原始合并请求页面(https://gitlab.com/gitlab-org/gitlab-ce/merge_requests/12244)中找到我们的所有更改。
Headless Chrome的更多用途
我们也一直在用headless Chrome来分析前端的性能,并发现它在检测问题时非常有用。作为GitLab即将发布的10.3版本的一部分,我们正在发布浏览器性能测试(https://docs.gitlab.com/ee/user/project/merge_requests/browser_performance_testing.html),希望让其他公司更容易使用。利用GitLab的CI / CD,headless Chrome是针对一组页面发起的,并计算总体性能分数。然后,对于每个合并请求,在源分支和目标分支之间比较分数,使合并之前更容易检测性能回归。
致谢
我衷心希望这些信息对想从PhantomJS切换到headless Chrome,并使用Rails应用程序的团队有用。感谢Google团队提供了非常有用的文档,感谢许多博客作者,他们分享了自己在headless Chrome早期的探索经验,并特别感谢Vitaly Slobodin和PhantomJS的其他贡献者,他们为我们提供了一个非常有用的工具,并服务了多年。🙇
登录查看更多
相关内容

Google Chrome,又称谷歌浏览器,是由谷歌(Google)公司开发的网页浏览器。基于开放源码的Chromium项目。
http://www.google.com/chrome/
http://www.chromium.org/...
专知会员服务
22+阅读 · 2020年3月18日
专知会员服务
41+阅读 · 2019年12月15日
Arxiv
6+阅读 · 2018年3月8日



相关VIP内容
专知会员服务
22+阅读 · 2020年3月18日
专知会员服务
41+阅读 · 2019年12月15日
相关资讯