使用 TensorFlow Lite 快速构建移动端声音分类应用
文 / Khanh LeViet,TensorFlow 技术推广工程师
声音分类是机器学习任务中的一项,您向机器学习模型输入一些声音将其分类成预定义的类别,例如犬吠声、汽车鸣笛声等。目前,已有许多声音分类应用,检测非法砍伐活动、检测座头鲸的声音以更好地了解它们的自然行为。
测非法砍伐活动
https://v.youku.com/v_show/id_XMzQ4MTUxOTIxNg==.html?spm=a2hzp.8253869.0.0检测座头鲸的声音
https://ai.googleblog.com/2018/10/acoustic-detection-of-humpback-whales.html
我们很高兴地宣布,现在 Teachable Machine 可用于训练您自己的声音分类模型,并可导出 TensorFlow Lite (TFLite) 格式模型。然后,您可以将 TFLite 模型集成到移动应用或物联网设备。这是快速运行声音分类的简便方式,分类之后,您可以在 Python 中探索构建生产模型,再将其导出到 TFLite。
Teachable Machine
https://teachablemachine.withgoogle.com/
模型架构
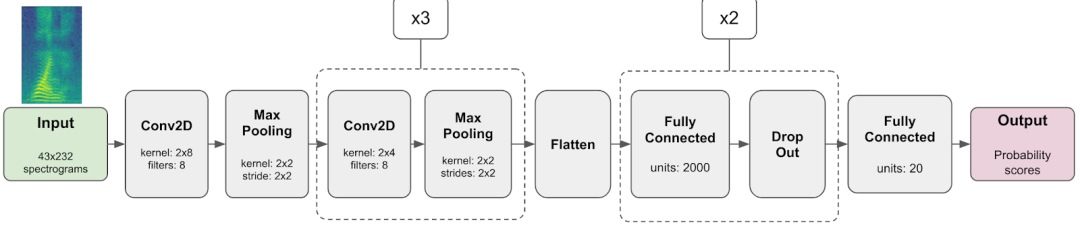
Teachable Machine 使用小型卷积模型对 1 秒音频样本进行分类。如上图所示,模型接收声谱图(通过傅里叶变换获取的声音的 2D 时频表示形式)。它首先会处理具有连续二维卷积层和最大池化层的声谱图。模型以多个全连接层结束,这些层与随机 dropout 层交错,用于减少训练过程中的过拟合。模型的最终输出是一个概率分数数组,要训练模型识别的每个声音类都有一个概率分数。
在 Python 中使用此方式训练您自己的声音分类模型,请查看此教程。
教程
https://tensorflow.google.cn/tutorials/audio/simple_audio
使用您自己的数据集训练模型
-
简单方式:连一行代码都不需要写,使用 Teachable Machine 收集训练数据,并且全部在浏览器中训练模型。这种方式适用于想通过交互方式快速构建原型的用户。 稳健方式:提前录制要用作训练数据集的声音,然后使用 Python 训练并认真地评估模型。当然,这种方法的自动化以及可重复性也高于简单方式。
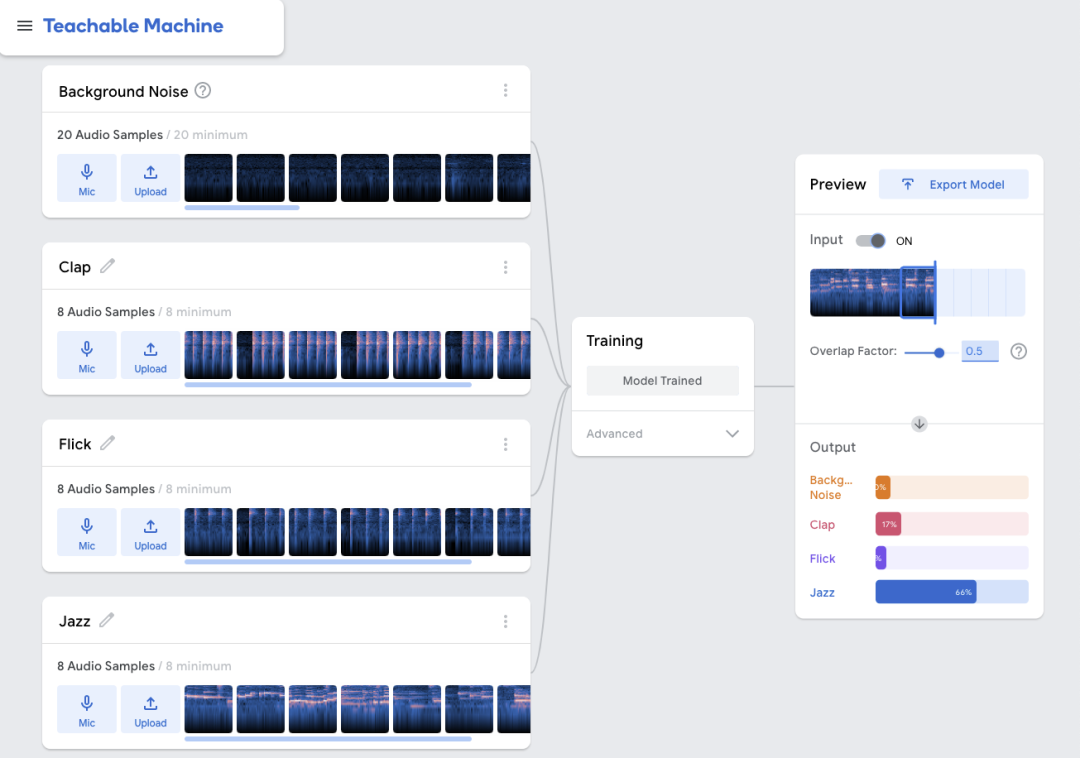
使用 Teachable Machine 训练模型
Teachable Machine 是一款可用于创建训练数据集和训练多种机器学习模型的 GUI 工具,包括图像分类、姿态分类和声音分类。Teachable Machine 底层使用 TensorFlow.js 训练机器学习模型。您可以将训练的模型导出为 TensorFlow.js 格式,以在网络浏览器中使用,或者导出为 TensorFlow Lite 格式,以在移动应用或物联网设备中使用。
-
前往 Teachable Machine (https://teachablemachine.withgoogle.com) 网站 -
创建一个音频项目 -
为您想要识别的每个类别录制一些声音片段。每个类别只需要 8 秒的声音 -
开始训练。完成后,您就可以在实时音频源上测试您的模型 以 TFLite 格式导出模型
使用 Python 训练模型
如果录音长达几个小时或者有数十个类别,则在网络浏览器上训练声音分类可能耗时很长。在这种情况下,您可以提前收集训练数据集,将它们转换成 WAV 格式,然后使用此 Colab Notebook(包括将模型转换成 TFLite 格式的步骤)训练声音分类。Google Colab 提供免费的 GPU,帮助您大幅提升模型训练的速度。
Notebook
https://colab.research.google.com/github/tensorflow/tfjs-models/blob/master/speech-commands/training/browser-fft/training_custom_audio_model_in_python.ipynb
通过 TF Lite 将模型部署到 Android
git clone https://github.com/tensorflow/examples.git
lite/examples/sound_classification/android 文件夹中找到它。
soundclassifier.tflite 和
labels.txt)添加到
src/main/assets 文件夹中,替换其中已有的示例模型。
4. 构建应用并将其部署到 Android 设备上。现在,您就可以实时对声音分类啦!
要将该模型集成到您自己的应用中,您可以将 SoundClassifier.kt 类从示例应用和已经训练的 TFLite 复制到您的应用。然后,您可以按如下方式使用该模型:
1. 从 Activity 或 Fragment 类初始化 SoundClassifier 实例。
var soundClassifier: SoundClassifier
soundClassifier = SoundClassifier(context).also {
it.lifecycleOwner = context
}
2. 开始从设备的麦克风捕获实时音频,并实时分类:
soundClassifier.start()
3. 作为可读类名称的映射接收实时分类结果,以及当前声音属于每个特定类别的概率。
let labelName = soundClassifier.labelList[0] // e.g. "Clap"
soundClassifier.probabilities.observe(this) { resultMap ->
let probability = result[labelName] // e.g. 0.7
}
未来计划
我们正在开发 iOS 版本的示例应用,它将于几周后发布。我们还会扩展 TensorFlow Lite Model Maker 以简化 Python 中声音分类的训练。敬请期待!
Model Maker
https://tensorflow.google.cn/lite/guide/model_maker
致谢
-
Google Research:Shanqing Cai、Lisie Lillianfeld -
TensorFlow 团队:Tian Lin -
Teachable Machine 团队:Gautam Bose、Jonas Jongejan Android 团队:Saryong Kang、Daniel Galpin、Jean-Michel Trivi、Don Turner



了解更多请点击 “阅读原文” 访问官网。



