你的用户究竟值多少钱?
关注并将「人人都是产品经理」设为星标
每天早 07 : 45 按时送达

在和互联网人交流时,我们经常听到“我们的用户值多少钱”之类的话语,而且每个产品,每个行业的数据都不相同——多的一名用户高达数千元,少的也是几十块起步。
问题是,用户的价值,都是怎么计算出来的呢?这种算法是否合理呢?
题图来自Unsplash,基于CC0协议
全文共 7324 字,阅读需要 15 分钟
—————— BEGIN ——————
自从互联网时代来临,如何评估互联网商业项目的价值就成为一个最难破解的谜题。大量机构投资者实际是在用“大资金”赌“大赛道”,看的是宏观的产业趋势而非微观的项目逻辑。这在一方面造就了京东、唯品会等早期投资的神话,但也在另一方面导致了无数赛道内投资者的折戟。
在这样的不确定性里,大量研究者都希望能够构建一个模型,精准衡量互联网商业项目的价值。
但若干的努力之后,关于互联网商业项目的估值不仅没有越来越清晰,反而越来越模糊。甚至,“在早期投资就是投人(创业者)”的说法已经成为业界共识。
我无意否认这样的说法,但作为商业模式的研究者,似乎有必要去建立一些更加“逻辑性”的投资原则。
从另一个角度上讲,对于互联网商业项目价值的认知,应该来自对商业模式的深度理解。
也许,在这个方向上,我们还能做点什么。
2014年,我在《叠加体验:用互联网思维设计商业模式》一书中曾经提出过一个互联网商业模式的“水桶模型”,并认为用户资产、生态资产、转化能力(将生态内的资源配给给用户的能力)是互联网商业模式产生GMV的三大要素。
本期,我将深入探究“如何衡量用户资产”。
当然,这里是针对那种以“用户(C)”为中心的商业模式。对于那种以“商户(B)”为中心的商业模式,如B2B、S2B2C,虽然原理不变,但应该以关注“商户资产”为出发点。
01
失效的传统估值方式
互联网商业世界里,基于用户的主流的估值方式无非两种:一类是估算网络效应,另一类是估算GMV(成交总额)。
估算网络效应的原理主要来自以太网的发明者梅特卡夫在20世纪80年代销售自己创立的3Com公司的网卡时提出的一个营销观点。
他认为,在网络中接入的节点越多,可能形成的连接越多。如果节点数是N,则可能存在的连接数为N(N-1),即约等于N2这一数量级。
这一观点被《吉尔德科技月报》的出版人George Gilder在1993年总结为“梅特卡夫定律(Metcalfe’s Law)”,简要描述为“网络的价值与联网的设备数量的平方成正比”。
在考虑网络效应的基础上,互联网商业模式基于互联网信息技术,也会遵循摩尔定律。
摩尔定律由英特尔(Intel)创始人之一戈登·摩尔(Gordon Moore)提出,即当价格不变时,集成电路上可容纳的元器件的数目,每隔18~24个月便会增加一倍,性能也将提升一倍。
换言之,每一美元所能买到的电脑性能,将每隔18~24个月翻一倍以上。
这两种定律几乎构成了互联网商业的底层逻辑(还可以参考吉尔德定律)。
正是基于这两大定律,前任摩根士丹利首席分析家、著名的华尔街证券分析师与投资银行家玛丽·米克尔(Mary Meeker)和同事在1995年出版的《互联网报告》中提出了“DEVA模型(Discounted Equity Valuation Analysis,股票价值折现分析法)”,即:
E=MC2
其中,E是项目的经济价值,M是为单个客户投入的初始资本,C是单个客户的价值。
这一公式中的C²显然是遵循了梅特卡夫定律,而M则是表达了摩尔定律的含义。
总体来看,一旦互联网商业项目的投资越过了固定成本线,后续的增长就将不再与固定成本的线性变动相关联,而是指数型增长。
例如,服务器、数据库、呼叫中心等基础设施的投入一旦超过了基线,项目价值就会随着用户增加带来的网络价值,进入指数型增长的轨道。
正是在这种理念的推动下,美国互联网企业理直气壮地堆积用户,并将用户数作为支撑高估值的最大筹码,尤其是对于SNS类项目更是如此——Facebook、Twitter、Google等互联企业在融资时获得的极高估值的背后,都是DEVA模型的逻辑。
最典型的例子是2014年2月Facebook以190亿美元收购 WhatsApp的案例:
WhatsApp作为一款通信类软件,成立于2009年,员工也只有50人左右。如果仅仅从市盈率、现金流贴现等方法,根本无法支撑这么高的估值。但从DEVA模型的角度看,其MAU(月活跃用户)达了4.5亿,Facebook还可以通过共享用户的方式获得更大的网络效应,这样的估值就有了理由。
但是,2000年网络泡沫破灭让狂热的投资者们警醒。
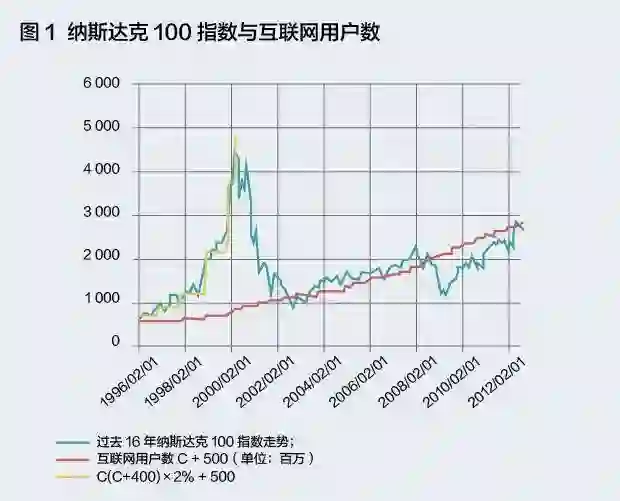
从统计数据上看:图1中红线部分代表的美国互联网用户数一直在增长,但纳斯达克100指数的走势(蓝线)却并未与用户数的平方(绿线)成正比。
2000年的断崖式下跌不禁让人怀疑——DEVA模型真的可靠吗?
此后,不断有研究者尝试去修正这个模型,但最后的应用效果也难说满意。
有意思的是:在国内,大量对于互联网企业(尤其是早期企业)的估值仍然在参考这种方式——也许是没有办法的办法吧。
在互联网商业项目走过了早期后,一些运营数据可能更准确地支撑投资者对于项目价值的判断。
于是,基于运营数据的估值方法开始逐渐成为主流。
总结起来,这类模型可以刻画为:
E=K·ARPU·MAU·LT
其中:K为常数,与所在行业有关系,ARPU为单客收入,MAU为月活跃用户,LT为用户生命周期,ARPU·MAU即每月的收入,而LT以月为单位,说明了可以获得多少个月的此类收入。
总结起来:这个模型衡量出了一个互联网商业模式在整个生命周期内可以获取的GMV。
当然,这样的估值方式也存在一定问题:除了K以外,另外的几个指标都是动态变化的,这种变化就让估值变得很飘摇不定。
举例来说:如果某个企业通过大量购买流量、补贴的方式,将MAU维持在一个较高水平,这就是一种典型的虚假繁荣。资本如果基于这个数据盲目进入,就会沦为“接盘侠”。
02
商业模式本质的估值
我们希望能够构筑一个更加贴近商业模式价值的估值模型,评估出用户资产的实际水平。
1. 导流×变现
DEVA模型的最大问题在于:它模糊了网络内不同节点的角色,假设其产生连接的价值是相当的。
盲目运用梅特卡夫定律的人们,忽略了区别不同的网络效应。
互联网企业在供需之间搭建平台(当然,也有通过自营的形式来实现连接供需的),存在同边网络正效应(same-side network effect)和跨边网络正效应(cross-side network effect)。
前者是指在用户或商户的一侧,每增加一个加入者,会带来同侧价值的爆发式增长;而后者是指在用户或商户一侧,每增加一个加入者,会带来另一侧价值的爆发式增长。
前一类商业模式(主要是SNS)尚且可以运用梅特卡夫定律,而后者如果用这种方式估算用户的价值,就显得非常牵强。
举例来说:微信用户会因为新用户的加入而增加连接的价值,而美团的用户之间极少互动,他们连接价值的增加主要来自另一侧的商户的增加。
再进一步看,如果获取了用户,是不是一定能够产生相应的价值?不同的用户的变现可能难道真的是一样的吗?
仅仅从用户这一侧来观察,用户特点、场景强弱等要素显然对于变现可能都有巨大影响。
所以,我认为,评估用户资产的基本逻辑应该是:
E=V·R
其中,V(Volume)代表流量池,R(Revenue)代表变现力(变现可能)。
这意味着互联网企业如果要主张自己的价值,应该一方面努力做出高质量的流量池,另一方面努力做大变现的可能性。
2. 标杆×点数比
基于运营数据的估值方式似乎也过于简单,且存在极大的不确定性。
另外,最大的问题在于:这种计算仅仅是一个滞后的结果,无法发现项目用户资产的早期价值。
就上述我们给出的模型来看,V和R两方面的现状数据是可以观测或估算的,但这却掩饰不了另外一个问题——基于现状数据的测算,会不会掩盖项目未来的可能性?
所以,我将模型扩展为两个部分:
E=V1·R1+ V2·R2
其中,V1·R1代表项目现在的价值,而V2·R2代表项目未来的价值。
显然:相对于前者的明确,后者是模糊的;而这个模糊的地方,可能就是互联网商业项目冰山之下的价值。
这种价值可能是基于现状的指数级增长,因此,无论是用何种传统的估值方式(PE、PB、DCF等),都很难推算。
这意味着,我们需要选择另一种估值方式,即:
A项目价值标杆项目价值 × A项目价值点数/标杆项目价值点数
通过模型,我们可以将A项目价值转化为点数,而后,通过市面上已经有明确估值的标杆项目,可以推算出A项目是被高估还是低估了。
我相信,对于互联网商业项目来说,这应该是相对合理的估值方式了。
也需要说明的是:这种利用点数估算项目价值的方式,更适合在同一行业赛道内的企业,越是赛道相同,结果越是准确。
当然,考虑到未来互联网商业范式都会走向“导流×变现”,场景趋同会导致赛道趋同,这种估值方式可能会有更广的适用范畴。
3. VR矩阵
考虑VR模型同时从现状和未来两个层面评估流量池和变现力,我们可以建立如下VR矩阵(表1):
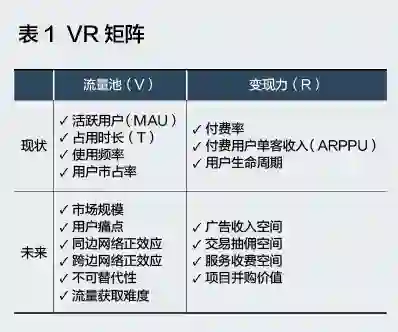
这个矩阵最大的创新就在于考虑了商业模式在未来的可能性。
现实操作中,我们一般会采用“李克特五点量表”的方式来进行计分,针对每一个指标的肯定陈述都会有“非常同意”“同意”“不一定”“不同意”“非常不同意”五种回答,分别计分5、4、3、2、1。
当然,对一些指标,我们会将刻度陈述得更加具象化。而后,在矩阵的每个模块内计算加权平均数,就可以得出四个模块的得分,并计算出该项目的价值点数。
03
流量池评估解析
对于流量池的评估,实际上反映了互联网项目端口的质量。
我在《叠加体验:用互联网思维设计商业模式》一书中提出过,互联网商业模式有两类端口,一类是功能出色的完美终端;另一类是价值观追随的价值群落。
也就是说:用户因为产品的出色功能或者基于情感依附,都有可能进入端口。
当然,这两类端口可能在某种程度上是重合的,在对于用户的吸引程度上,这就会产生1+1>2的效果,即使用户实现场景沉浸。一旦用户沉浸于场景中,就会产生非理性的消费冲动。
这里,需要解释一下“非理性的消费冲动”——这并不是指欺骗用户的导向;而是指在那样的场景下,用户脱离了单纯对于价格的斤斤计较,转而将自己在端口上接触到的产品或服务理解为“整体解决方案”,并愿意为之付出相应的高溢价。
例如,小红书是一个社群电商,它既具有电商的购物功能,又是一个拥有独特价值观的社群。它的用户会因为网红大V的带动而对于某些产品更加认可,更倾向于去欣赏品质,而不像在淘宝购物时对于价格异常敏感。
这里,用户体验到的就不仅仅是一款产品,而是一种生活方式。
现有流量池的评估主要从四个方面进行:活跃用户、占用时长、使用频率、用户市占率。
活跃用户是评估流量池规模的有效指标,其重要性不言而喻;而占用时长和使用频率则是体现出用户对于端口的场景沉浸程度,这两个指标往往是容易被忽略的;用户市占率则关注了互联网商业世界中的马太效应,高占有的端口会引发其他端口的羊群效应。
除了现有流量池,我们还应该关注未来的空间。
首先,不同的行业有不同的市场规模,天然用户基数都是不一样的。
当然,做重度垂直领域的生意也不是坏事,毕竟中国是个大市场,一个很小的相对数也是一个很大的绝对数;而且,选择重度垂直的赛道,可能会让后续的流量获取难度降低。
其次,用户的痛点也不同。这可能是最重要的指标,如果整个矩阵只能留下一个指标,那就是它。
这里,不用采取李克特五点量表,而是如下原创分级量表来确认痛点:
5分:没了这个产品完全无法想象,无法承担;
4分:没了这个产品局部会有极大损失,可承担,但很痛;
3分:没了这个产品会不太方便;
2分:没了这个产品会有点想念;
1分:没了这个产品毫无影响。
这里,3分是黄金分割点;3分以上,项目有很大成功可能性,而3分以下,项目就不用做了,根本不可能成功。
最纠结的是落在3分——这种项目如果要做,就必须要投入大量资本,做好长期不盈利的准备,养成用户的习惯,把他们娇惯得不适应失去这个产品(进入到4级)!
所以,从这个角度上说,滴滴出行的起点实际上是3分:没有这个产品之前,人们照样出行;只不过,他们用了大量的资本,“烧”出了用户的使用习惯。
再次,基于用户痛点,我们需要观察项目端口对于用户的吸引程度,这里面当然也包括与竞争对手的比对。
同边网络正效应是指用户能不能出现自交互,而跨边网络正效应是指用户能不能被项目提供的解决方案所吸引。后者是用户进入端口的理由,但即使项目不断迭代自己的解决方案,用户还是有可能出现倦怠。
例如,在一些综合电商平台购物多年后,用户可能会转向一些垂直电商平台。
所以,SNS才会受到投资者的热烈欢迎,因为这类产品可以稳定用户流量,降低留存成本,甚至让用户跨越生命周期。
这也是为何马云一直觊觎社交蛋糕的原因。
从最开始阿里亲自做来往,到后来投资微博、陌陌,再后来亲自做钉钉……每一步都是在尝试用各种方式切入社交。
除了两种网络效应外,还要考虑的是不可替代性——同质性产品意味着并不拥有核心竞争力,即使流量池再大,也是昙花一现。
从这个角度上说,滴滴出行需要经受严峻挑战:尽管多年占据市场老大的地位,但在美团跨界打劫后,其在局部市场上一度被撕开了一个不小的口子,不禁让人对其核心竞争力产生疑问。
最后是流量获取难度。
在前几年,一个业界的误解是:只要能够接上互联网,就有大量的流量红利可以获取。
但现在,线上流量已经见顶,获客成本异常高昂,有的企业甚至反向走到线下去获取流量,获客成本反而更低。
所以,这也是决定未来流量池优劣的关键因素,这也是拼多多被美国一级市场上的投资机构看好的原因。
不考虑其商业伦理上的瑕疵,腾讯注入的流量绝对是其成功的关键。
根据招股说明书,拼多多2017年的获客成本仅为11元/人,在电商行业中,低到难以想象,甚至低于流量大户京东和阿里。
04
变现力评估解析
对于变现力的评估,有可能不仅仅是在评估用户资产,所以,我们坚持将其限制在一个有限的范畴,即流量池中究竟有多大的变现可能。
现有变现力主要是从三个方面进行:付费率、单个付费用户收入、用户生命周期。
其中
MAU·付费率·ARPPU=MAU·ARPU
等式右边是大家常用的计算方法。但如果不观测付费率,就会模糊掉对于用户转化基本面的观察:一个仅有塔尖部分的付费用户的项目和一个付费用户全覆盖的项目,性感程度显然是不同的。
最理想的状态是:“用户分类分级,付费从高到低”,达到经济学中“一级价格歧视”的状态。
说直白点,就是让能够付费的用户都付费。
除此之外,用户生命周期也是一个非常关键的指标,也是一个互联网公司大多不愿意披露的指标。
但遗憾的是:除了凤毛麟角的项目外,大多数产品的用户都有一定的生命周期。
用户的生命周期过短,需要进行又一轮的“拉新”和“留存”来维持流量池规模,这对于企业是有极大成本损耗的。更重要的是,这会导致企业去变现流量池的空间被挤压。
某些时候,这让企业不得不快速收割,进一步造成用户满意度下降,生命周期变短,进入恶性循环。
其实,不管是哪类项目,用户的生命周期都是可以相对控制的。
需要说明的是:我并没有将“留存”放到“流量池”里进行评估,这是考虑它会与活跃用户的指标有交叉。
上述现状指标都是可以明确观测到的,而对于未来的空间,则需要通过商业模式的逻辑来推算。
一般来说,互联网项目存在三类收费模式:
其一是广告收入。项目通过累积流量,成为广告投放地或流量分发者。
其二是交易抽佣。这包括平台通过撮合成交,收取一定的过手费、进场费等;也包括京东这类自营模式赚取贸易差的情况。
其三是服务收费。这包括用SaaS、PaaS等手段提升交易效率而向交易两端赚取的服务费。
从互联网行业的传统来看,SaaS类的项目估值是不高的,但这只是昨日的偏见。
在美国,Salesforce这个SaaS鼻祖已经逼近千亿美元的估值,后市一片看好。道理很简单——在大量企业都涌入前两类收费的战场时,服务收费成为一片新的蓝海。
其实,SaaS、PaaS等服务的是企业的数据能力,而这块可能是未来互联网项目增值的巨大空间,也可能会冒出若干独角兽级别,甚至BAT级别的“头部项目”。
在短暂的流量红利之后,数据红利可能是互联网商业基业长青的根本(这个部分在后续衡量互联网商业项目“转化能力”的文章里会重点介绍)。
总体来看,上述三个领域里,哪个做好了都会有前途。
三类收费空间会影响企业的损益表,而另一样指标则会影响企业的资产负债表,即项目的并购价值。
一个项目如果对于投资主体具有战略价值,它必然能够获得更高的估值溢价。
这里的溢价来自并购主体看好的1+1>2的协同效应。
典型的例子是2018年4月3日美团收购摩拜,这次收购既是美团发展路径的必然,也是对抗阿里、滴滴等强敌的考虑。
阿里的新零售战略曾提出“三公里理想生活圈”的概念,旨在通过互联网技术满足用户在三公里生活圈内的“吃、喝、玩、乐、穿、住、行,甚至教育、医疗服务”。
这次收购发生的前一天(4月2日),阿里用95亿美元全资收购了饿了么。
显然,阿里是希望用其来补充自己的短途运输能力,开展新的外卖业态,实现三公里半小时达,为用户提供更加丰富的解决方案。
在阿里系持续补强线下的时候,美团选择收购摩拜就可以将三公里生活圈的共享出行生活场景囊括其中,进一步提高其估值。
进一步看,通过收购摩拜,不仅可以将流量池扩容,也可以实现这类出行场景与新开的网约车业务进行无缝联动,拓展其在出行行业的更多业务,加大与滴滴对抗的筹码。
这里,虽然在不少业内人士看来,并购对价并不惊艳,但考虑摩拜这类项目的经营状况,这种收购也是万幸。
总体来看,站住了一个较好的位置,足以吸引巨头的收购,也是变现力的一种表现。
但不得不说的是:互联网商业项目从一开始就应该打造自己“能变现的流量池”。
这意味着:要夯实广告收入、交易抽佣、服务收费上的基础,这才是用户资产价值的真正体现。
要谨记,不赚钱的项目不是好项目。否则,如果一味将目标对准资本(机构资本VC或企业资本CVC),等待接盘,商业模式本身就失去了立根之本。
—————— / END / ——————

每个「在看」,都是一次鼓励 ▼





